**2019.12.23 Pandas Second Class
Pandas
Series
인덱스를 이용하여서 데이터를 나타낼수있다
리스트를 사용하여서 나타낼때에

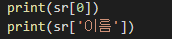
리스트를 이름으로 지정하여서 구분이 가능하다
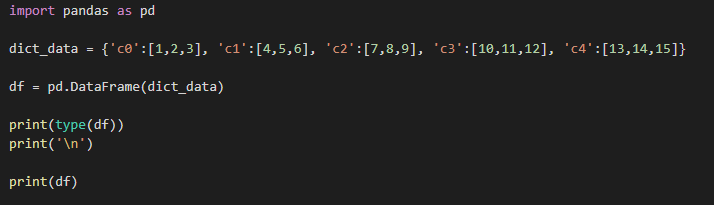
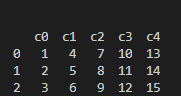
DateFrame
행인덱스와 열이름으로 구성되어지는 DataFrame,
Dictionary 형태로 구성되어있으며, 키가 columns이되고 리스트가 Value형으로 만들어지게된다
index가 가로, columns가 세로로 나타내어진다.

-
다시 새롭게 컬럼이나 index를 바꾸어줄때에는 rename이라는 메소드를 사용하여서 새로운 변수에다가 입력을 해준다
df1 = df.rename(columns={'나이':'연령', '성별':'남녀', '학교':'소속'}) -
원본의 내용을 바꾸어주는 inplace
직접 입력을 하던지 아니면 rename이라는 메소드를 사용하던지 둘중에 하나를 사용하여야한다
df.rename(columns={'나이':'연령', '성별':'남녀', '학교':'소속'}, inplace=True) -
drop이라는 메소드로 데이터의 행자체를 지워줄수있다
df2 = df[:]
df2.drop('우현', inplace=True) -
axis = 의 값이 1이면 열, 0이면 행
df4.drop('수학', axis=1, inplace=True)
data를 가지고왔을때에 그 값을 사용하기위해서는 변수에 저장을 해야한다
-
데이터 프레임 df를 전치(메소드 활용)
df = df.transpose()
print(df)
print('\n') -
데이터 프레임 df를 다시 전치
df = df.T
print(df) -
특정 열을 행 인덱스로 설정하는 set_index
df.set_index('이름', inplace=True) -
행 인덱스 재배열 reset_index()
new_index = ['r0', 'r1', 'r2', 'r3', 'r4']
ndf = df.reindex(new_index)
new_index의 값으로 index를 다시 만들어준다
없는값은 NaN으로 넣어줌
new_index = ['r0', 'r1', 'r2', 'r3', 'r4']
ndf2 = df.reindex(new_index, fill_value=0)
new_index의 값으로 index를 만들어주는데
없는값들은 NaN이 아니라 0으로 대체해준다 -
행 인덱스 초기화 reset_index()
ndf = df.reset_index()
print(ndf)
index를 원래대로 숫자로 나타내준다
ndf = df.sort_index(ascending=False)
print(ndf)
오름차순으로 정렬해준다 -
df의 모양과 크기 확인 튜플로 변환
print(df.shape)
print('\n') -
데이터 프레임 df의 내용 확인
print(df.info())
print('\n') -
데이터 프레임 df의 자료형 확인
print(df.dtypes)
print('\n') -
시리즈(열의) 자료형 확인
print(df.mpg.dtypes)
print('\n') -
기술통계 정보 확인
print(df.describe())
print('\n')
print(df.describe(include='all')) -
데이터 프레임 df의 각 열이 가지고있는 원소 개수 확인
print(df.count())
print('\n') -
df.count()가 반환하는 객체 타입 출력
print(type(df.count()))
print('\n') -
데이터프레임 df의 특정 열이 가지고 잇는 고유값 확인
unique_values = df['origin'].value_counts()
print(unique_values)
print('\n') -
value_counts 메소드가 반호나하는 객체 타입 출력
print(type(unique_values)) -
평균값
print(df.mean())
print('\n')
print(df['mpg'].mean())
print(df.mpg.mean())
print('\n')
print(df[['mpg', 'weight']].mean()) -
중간값
print(df.median())
print('\n')
print(df['mpg'].median()) -
최대값
print(df.max())
print('\n')
print(df['mpg'].max()) -
최소값
print(df.min())
print('\n')
print(df['mpg'].min()) -
표준편차
print(df.std())
print('\n')
print(df['mpg'].std()) -
상관계수
print(df.corr())
print('\n')
print(df[['mpg','weight']].corr())
CSV 파일
pandas.read_csv('파일경로')
데이터 값을 쉼표로 구분하고 있다는 의미를 가지는 텍스트 파일
- to_csv 메소드를 사용하여서 dataframe을 csv파일로 내보내기 파일명은 df_sample.csv로 저장
df.set_index('name', inplace=True)
df.to_csv('./df_sample.csv')
Excel 파일
HTML 파일
