
Introduction
Machine Learning(머신러닝)이란? Machine Learning의 역할은?
통계, 머신러닝(Machine Learning), 딥러닝(Deep Learning), 데이터 마이닝(Data Mining), Computer Science, 그로스해킹(Growth Hacking) 등등... 이 쪽 분야에서 흔히, 자주 등장하는 단어입니다.
저는 통계학을 전공지만, 위 분야들의 영역을 짓고 포함관계니, 어쩌니 저쩌니(Ex. 머신러닝 = 통계 + 데이터 마이닝 + Computer Science 이런식) 장황하게, 멋지게, 왈가왈부하는 것을 좋아하지 않습니다.
복잡한게 어려운 저에겐, 위의 많은 단어들은 결국 한 단어로 다음과 같이 표현할 수 있습니다.
"Data Driven Approaches"
예를 들어보자면, "A의 사람은 고양이를 좋아하고, B의 사람은 강아지를 좋아한다." 라는 문장을 아래의 그림을 보고 A/B에 어떤 말을 쓸 수 있을까요??

대부분의 사람들은 다음과 같이 대답합니다.
- "어른(A)은 고양이를 좋아하고, 아이(B)는 강아지를 좋아합니다."
- "여자(A)는 고양이를 좋아하고, 남자(B)는 강아지를 좋아합니다."
- "자연이 아닌 곳의 사람(A)은 고양이를 좋아하고, 자연이나 들판에 있는 사람(B)은 강아지를 좋아합니다."
하지만, Data Driven Approaches는 다음과 같이도 말할 수 있습니다. (물론, 눈치채신 분들도 계시겠지만..!!)
- "하얀옷을 입은 사람(A)은 고양이를 좋아하고, 색깔의 옷을 입은 사람(B)은 강아지를 좋아합니다"
머신러닝과 같이 데이터로부터 인사이트를 얻고자 하는 분야는, 우리가 생각하고 있는 관점 외에도 순수하게 데이터로만 볼 수 있는 새로운 관점을 제공할 때 가장 빛을 발하는 순간이라고 생각합니다.
Machine Learning 종류
본론으로 들어와, 머신러닝은 크게 3가지로 분류할 수 있습니다. 간혹, Semi-suprevised Learning을 포함할 때도 있지만 이번 포스팅에서는 소개하지 않겠습니다. 이번 포스팅에서는 간략한 설명만하고, 이 후 포스팅에서는 각각 자세한 내용과 논문을 통해 소개할 예정입니다.
- Supervised Learning (지도학습)
- Unsupervised Learning (비지도학습)
- Reinforcement Learning (강화학습)
1. Supervised Learning (지도학습)
데이터에 Labeling이 되어 있는 상태로, 다시 말해 정답을 알려주며 학습시키는 것을 말합니다.
크게 종속변수가 연속형인 회귀(Regression)과 범주형인 분류(Classification)으로 나눌 수 있습니다.
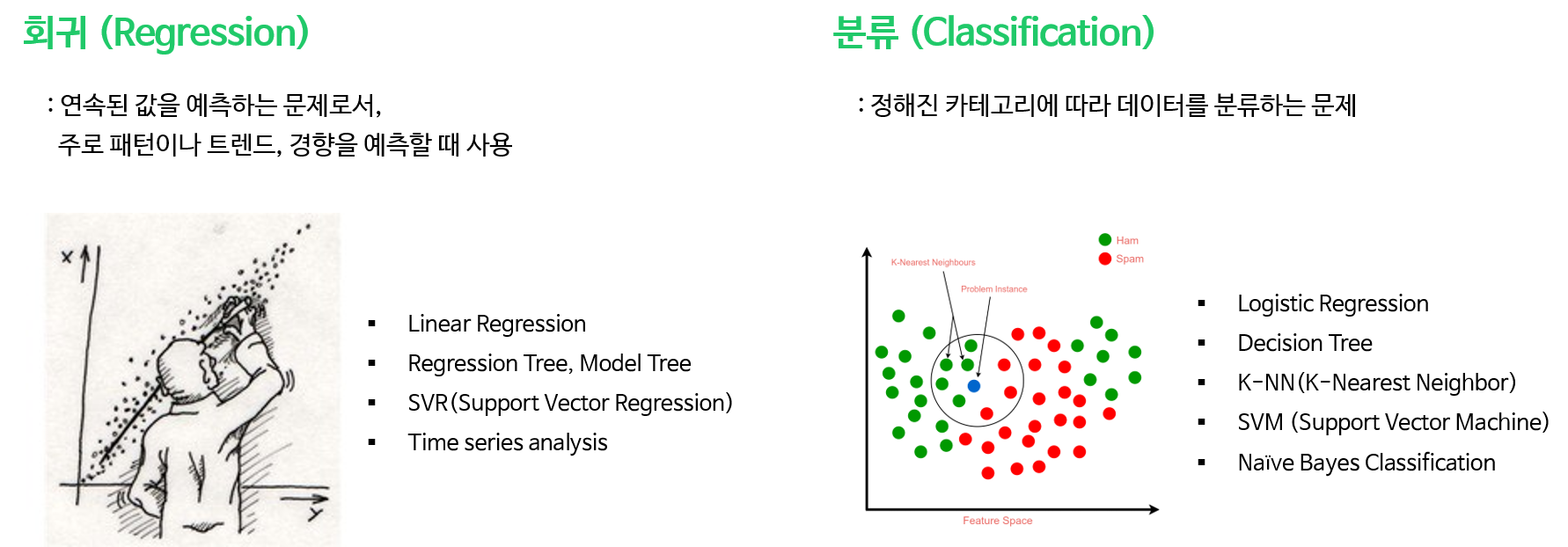
2. Unsupervised Learing (비지도학습)
지도학습과는 달리 정답을 알려주지 않고 학습을 시키는 것으로, 데이터의 패턴이나 형태를 찾는 것을 말합니다.
비지도학습 중 가장 대표적인 분야는 유사한 데이터끼리 그룹핑을 하는 군집화(Clustering)과 고차원의 데이터를 저차원으로 줄이는 차원 축소(Dimension Reduction)이 있습니다.

3. Reinforcement Learning (강화학습)
강화학습은 시행착오를 통해 반복적으로 환경(environment)과 상호작용함으로써, 스스로 과제를 수행하는 방법을 배우는 것을 말합니다. 보상(Reward)이라는 개념을 최대화하는 방향으로 정책을 수정하고 행동하면서, 최적의 정책을 찾을 때 까지 반복 학습을 하는 것입니다.
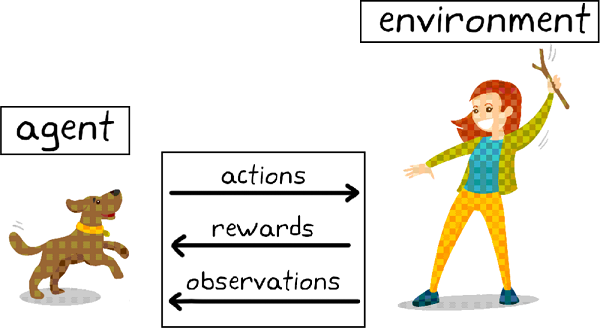
머신러닝을 위의 3가지로 분류했지만, 각각의 방법론은 독립적이지만은 않습니다. 비지도학습이 지도학습의 중간 과정으로 활용될 수도 있고, 지도학습 문제를 군집화로도 풀 수 있습니다.
