
Introduction
Tabular Data(정형 데이터)에서 Noise를 줄 수 있는 방법 중 하나인 Swap Noise에 대해 알아보도록 하겠습니다.
Challenges
데이터를 다루다 보면, Denoising AutoEncoder와 같이 Noise(노이즈)를 필요로 하는 경우가 종종 있습니다.
비정형 데이터(Ex. 이미지, 텍스트, 음성)에서는 범용적으로 사용되고 잘 짜여진 라이브러리 툴로 노이즈를 줄 수 있는 방법이 많습니다. 반면, 정형 데이터에 노이즈를 만들려고 하면 선뜻 와닿는 방법이 생각나지 않습니다.
가장 큰 이유는 "변수별로 갖는 범위 및 분포가 다르기 때문"이라고 생각합니다.
예를 들면, Gaussian Noise(정규분포의 랜덤값을 각 변수별로 주는 방법)을 주기 위해 각 변수별 적당한 분산값을 정하기도 힘들며, 데이터 중 횟수와 같이 정수값만 갖는 변수가 있을 때 Gaussian Noise로 생성된 소숫점의 노이즈를 추가하는 것은 원래 데이터를 정수가 아닌 값으로 변형하기 때문에 데이터가 왜곡될 수 있습니다.
Denoising AutoEncoder(DAE)
원본 데이터에 임의의 노이즈를 추가한 입력 데이터(Input)를 노이즈가 없는 깨끗한 원본 데이터(Output)로 복원하도록 학습하는 AutoEncoder.
깨끗한 원본 데이터만을 학습하면 Inference에서 노이즈가 있는 데이터를 잘 복구하지 못하는 과적합(Overfitting)을 방지하는 일반화(Regularization)효과를 줄 수 있음.
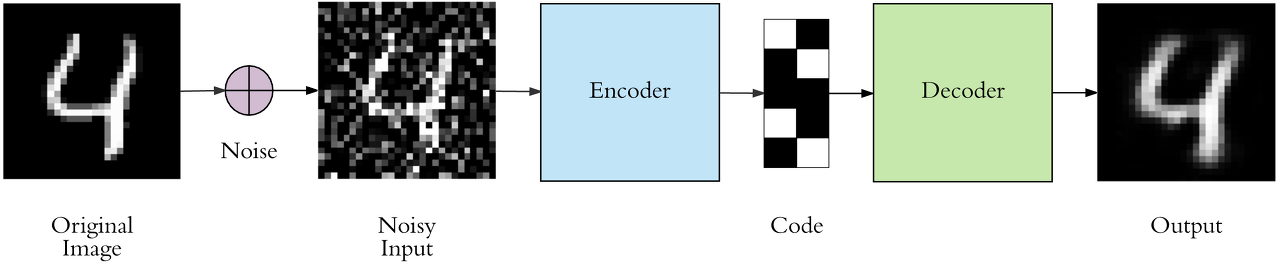
비정형 데이터에서의 Noise
- Gaussian Noise : 정규분포의 랜덤 노이즈
- Salt&Pepper Noise : 마치 사진에 소금과 후추가 떨어진 듯한 랜덤의 하얀색과 검은색 노이즈

Swap Noise
Swap Noise는 Kaggle 1등 솔루션을 통해 더욱이 알려졌습니다.
방법은 매우 간단합니다. 각 변수별로 임의의 관측치를 다른 관측치의 값으로 대체하는 것입니다. (1등 솔루션은 15%의 확률로 Swap이 이루어 지도록 하였습니다.)
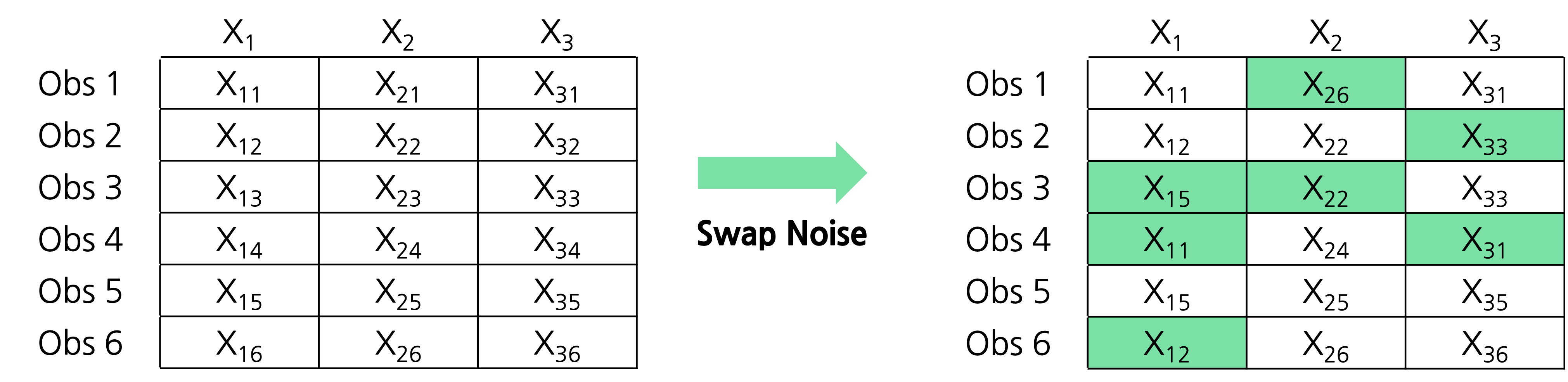
이렇게 생긴 노이즈는 이미 갖고 있는 변수 공간에서의 다른 값으로 대체하는 것이기 때문에 이상한 값이 생성되지 않을것이며, 각 변수별로 따로 지정해야할 하이퍼파라메터(Ex. Gaussian Noise - 평균, 분산)도 없기 때문에 손쉽게 사용할 수 있습니다. 또한, 어떠한 분포의 변수에도 적용이 가능합니다.
정형 데이터에서 노이즈가 필요하다면, Swap Noise를 고려해보시기를 추천드립니다.
Reference
