한동안은 DB에 관한 마지막 글이 될 것 같다.
DB를 정리하기 전에 INDEX를 빼먹고 가면 뭔가 찜찜해서 짚고 넘어가고자 한다.
사실 index에 관해서는 깊이있게 잘 정리된 글들이 이미 존재해서
링크로 대신하는 것이 쓰는 사람의 시간과 읽는 사람의 시간
모두를 아낄 수 있을 것이라고 생각한다.(링크 개꿀...)
정말 잘 쓰신 글들...
https://mangkyu.tistory.com/96 (index에 대한 기본 내용(사용시 고려요소, 장단))
https://helloinyong.tistory.com/296 (왜 B+Tree가 index에서 활용되는가?)

내가 쓸 글은 내가 책에서 읽은 부분 중
위 링크와 최대한 중복되지 않는 부분을 요약하고자 한다.
<인덱스 사용시에 고려할 Point!>
1. 카디널리티는 높고, 선택률은 낮은 Data에서 사용할 것
카디널리티는 값의 균형을 나타내는 개념으로 말이 좀 어려운데 내가 쉽게 이해하기로는
한 컬럼의 값들이 각 row에서 중복되지 않고 unique 할 수록 높다고 이해했다.
선택률은 결국 이와 연결되는 맥락이라고도 할 수 있는데 카디널리티가 높을수록
조건에 의해 선택되는 컬럼의 수는 적을 것이고(전체의 10%가 넘어가면 index 사용재고)
이러한 Data구조와 컬럼에 index를 사용하라는 것이다.
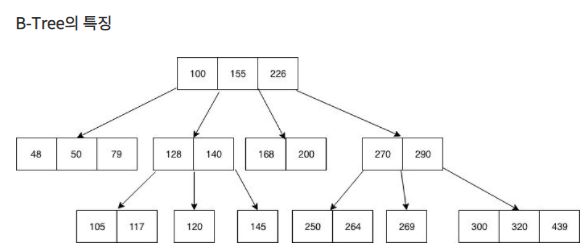
내가 생각하는 위의 이유는 index는 B+Tree를 사용하기 때문에
선택해야하는 Data가 많게 되면 반복해서 트리구조를 타며
그냥 처음부터 주욱 읽어내려가는 Full Scan에 비해 반복이 늘어나기 때문으로 이해했다.
<인덱스 사용시에 고려할 Point!>
2. index는 전체/전방일치에는 적용 가능하나, 중간/후방일치에는 적용되지 않는다.
예를 들어 설명하자면 전체(백엔드개발자)/전방(개발자%) 검색조건과
중간(%개발자%)/후방(%개발자) 검색조건이라고 할 수 있다.
책에는 이유까지는 설명되어 있지 않지만 전체와 전방은 앞쪽 키워드만을 가지고
트리를 태울 수 잇지만 중간이나 후방은 키워드를 뽑아낼 수 없어
FullScan이 사용되는 것으로 유추했다.
<인덱스 사용시에 고려할 Point!>
3. index 필드에 연산/함수/IS NULL/부정형을 사용하는 경우 적용되지 않는다.
연산의 경우를 예로 들면 다음과 같은 경우 index를 활용하지 못한다.
SELECT *
FROM table
WHERE indexField*1.1 > 100반면에 비교되는 우항의 연산은 관련이 없으므로 다음과 같이는 가능하다.
SELECT *
FROM table
WHERE indexField > 100*1.1함수의 경우는 다음과 같다.
(trim() 같은 함수로 의도적으로 FullScan을 태우는 경우도 있다고 한다.)
SELECT *
FROM table
WHERE LENGTH(indexField) = 10IS NULL의 경우는 다음과 같은데 index필드의 경우
보통 NULL 값이 들어간 경우가 없기 때문이라 한다.
SELECT *
FROM table
WHERE indexField IS NULL마지막으로 부정형(!=, <>, NOT IN)의 경우는 다음과 같다.
SELECT *
FROM table
WHERE indexField != 100
만약 위와 같은 이유들로 index 활용이 어려워졌다면
어떻게 해야하는지에 대한 대처가 책에 나와있다.
- UI에서 검색조건을 강제하여 Data 압축률을 높인다.

만약 위와 같은 UI가 있다고 했을때 주문일 입력을 강제한다면
주문ID만을 가지고 검색하는 것에 비해 선택 data의 범위를 좁힐 수 있을 것이다.
- 데이터 마트를 만들어 통계처리등의 결과를 미리 만들어뒀다 사용한다.
데이터 마트는 간단하게 만든다면 DB 서버내부에 통계결과 테이블을 만들고
특정시간(사용자 이용이 적은 새벽)에 해당 테이블에 통계로직의 결과 Data를
저장하는 형식으로 사용할 수도 있다.
(통계결과 Data를 필요할 때마다 로직을 통해 만드는 것은 부하가 심할 수 있다!)
데이터 마트의 경우 데이터의 동기화(실시간 raw data와의 차이), 마트 관리 등에서
문제가 될 수 있으므로 신중할 필요는 있다.
- index only scan 방식을 활용한다
SELECT field1, field2
FROM dataTable;
CREATE INDEX coveringIndex ON dataTable(field1, field2);index only scan 방식은 쉽게 말하면 필요한 필드를 모두 index로 감싸서 보관해두는 것이다.
table안에 작은 table을 만드는 방식으로 이해했는데
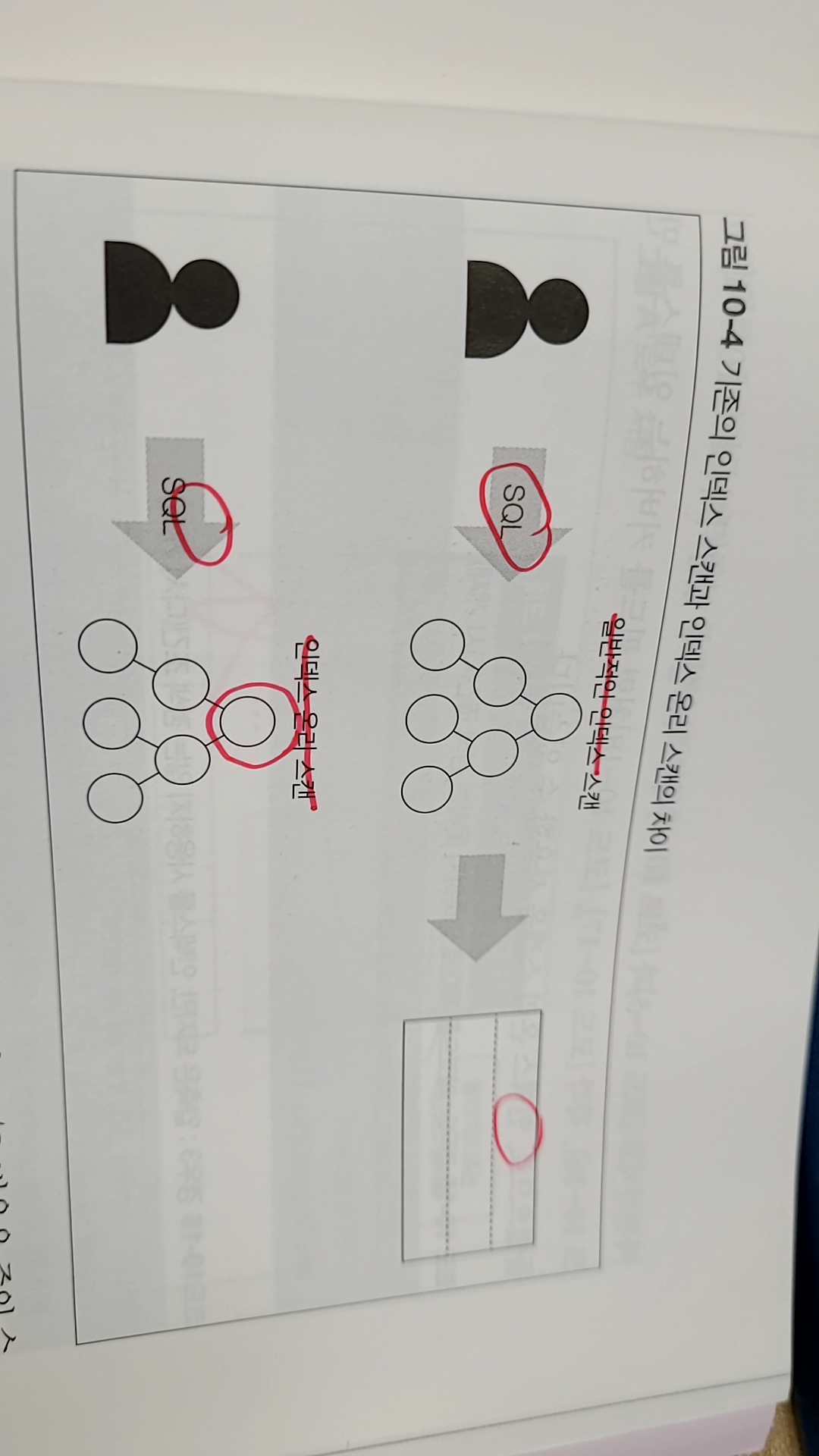
이렇게 되면 table을 스캔할 필요도 없이 바로 index에 접근하여
필요한 필드값들을 가져올 수 있게된다.
물론 이러한 방식도 인덱스 필드수의 제한, 필요 필드 변경시 대응 등의
한계가 있으므로 상황에 따라 활용하는 것이 중요하다.

이 책을 통해 새로운 많은 것을 배워 한번쯤 읽어보시길 추천하고 싶다.
하지만 무엇보다 중요한 것은 실무에서의 적용이므로 종종 다시 이 글을 읽어보며
아는 것을 Code에 자연스럽게 적용 할 줄 아는 그런 개발자가 되고 싶다!
