
SQL 성능을 결정하는 결정적인 요소 중 하나는 JOIN이다.
기준이 되는 Data(FROM)를 만드는 과정이기 때문에 Table 스캔이 빈번하게 일어나고
관련 Table간의 연결도 만들어야 하기 때문에 많은 자원이 소요된다.

조인에 주로 사용되는 알고리즘은 위의 세가지이지만
MySQL의 경우 Nested Loops와 이에 파생되는 방식만을 지원하고
Hash와 Sort Merge는 지원하지 않는다고 한다.
이와 같이 가장 많이 사용되는 것은 Nested Loops이라고 할 수 있으며
이후 Hash와 Sort Merge 순으로 사용된다.
그럼 먼저 가장 잘 알아둬야 할 Nested Loops 알고리즘을 살펴보고자 한다!
이미지 출처 : https://hoon93.tistory.com/46
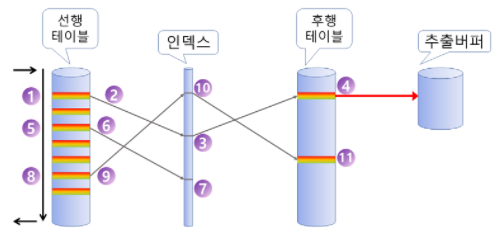
Nested Loops의 동작 방식은 이중 for문의 동작과 매우 유사하다.
먼저 바깥쪽 for문이라고 할 수 있는 외부 테이블(Driving Table)을 먼저 하나 스캔하고
이후 안쪽 for문이라고 할 수 있는 내부 테이블(Inner Table)에서
외부 테이블에서 스캔한 정보와 연결할 수 있는 정보가 있는지를 하나하나 비교하며 확인한다.
(구구단 코딩 방식과 유사하다 - 2x1, 2x2, 2x3...)
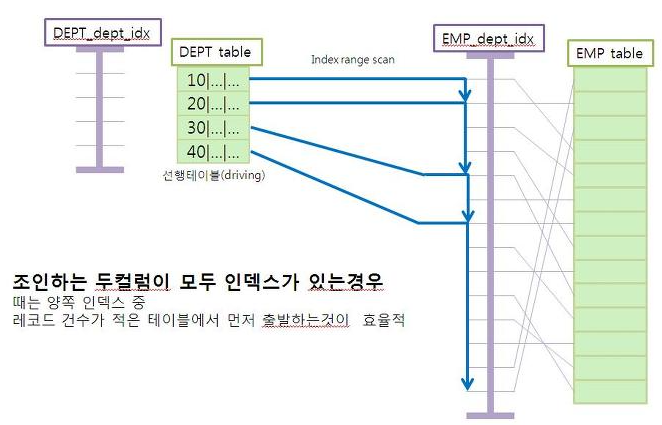
여기에서 외부 테이블을 무엇으로 설정할 것인가는 Nested Loops 알고리즘에서
핵심중에 하나가 된다. 보통 외부 테이블이 작을 수록 성능이 좋아진다는 것이 많이 알려진 내용이지만 여기에는 하나의 전제 조건이 있다.
내부 테이블의 결합 키 필드에 인덱스가 존재할 것!
사실 내부 테이블(A)과 외부 테이블(B) 간의 연산 횟수는 row 수를 기반으로 하기 때문에
A x B = B x A가 같을 수 밖에 없다.
고로 인덱스를 거치지 않는 연산은 둘의 위치를 바꿔도 큰 의미가 없다.

위와 같이 인덱스가 존재할 경우에는 내부테이블을 스캔하는 과정의 반복이 줄어들어
JOIN 성능이 개선되는 것인데 이를 통해 더 정확히 말하자면 다음과 같다.
외부 테이블이 작은게 중요한게 아니라,
인덱스가 있는 내부 테이블이 클수록 인덱스의 효율성이 올라가 반복 생략 효과 커진다!
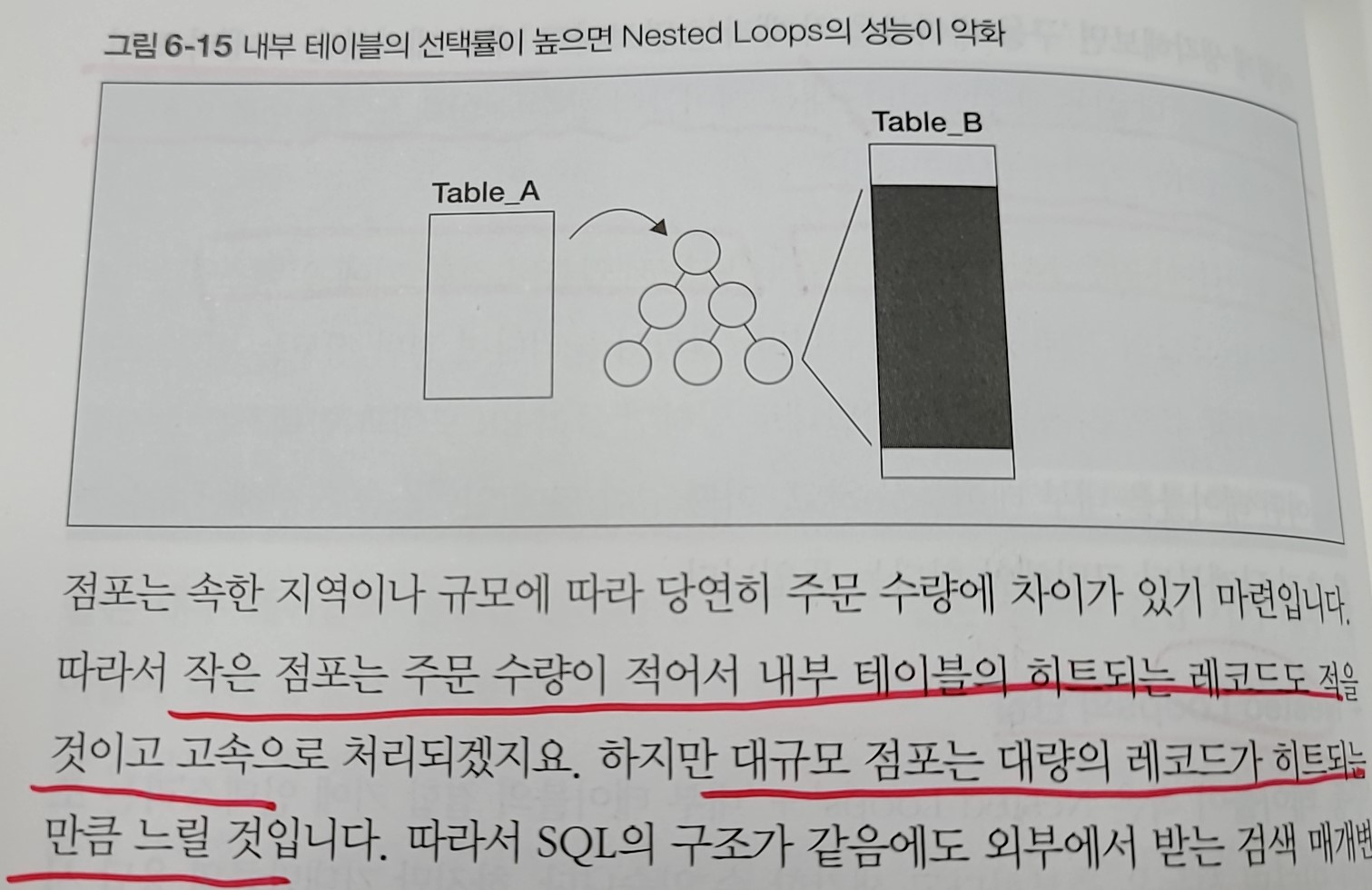
하지만 '작은 외부 테이블 + 인덱스를 가진 내부 테이블'만으로
모든 문제를 해결할 수 있었다면 다른 알고리즘들은 나오지 않았을 것이다.
위의 경우(A : 점포 / B : 주문)처럼 인덱스에 의해 해당되는 row가 여러개라면
결국 여기서도 반복이 발생하여 성능이 떨어지게 되고 이에 대한 해결책은 다음과 같다.
- 외부 테이블을 큰테이블(주문)으로 선택한다.
- Hash 알고리즘을 사용한다.
1번 방법의 경우는 점포에서 주문의 관계는 1:N이지만, 주문에서 점포의 관계는 1:1이라는 점을 활용하는 것이다. 이는 주문 테이블에 대한 접근 비용이 현실적인 수준이라면 가능하다.
2번째 방법은 다음으로 설명할 Hash 알고리즘이다.
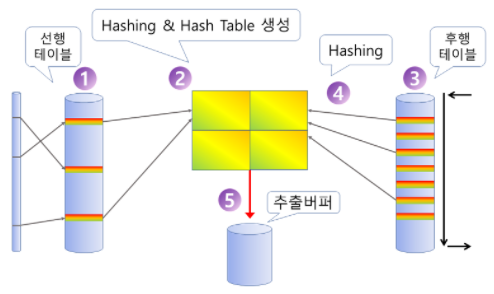
위와 같이 두 테이블을 해시함수를 통해 변환하고 이후 해시값을 매칭하는 방식이다.
개인적으로 해시함수의 내부동작을 잘 알지는 못해 오히려 복잡하지 않을까 싶지만
아래 3가지 경우에는 Hash 방식을 추천한다고 한다.
- 두 테이블의 크기가 비슷한 경우
- 내부 테이블에서 선택되는 레코드 수가 너무 많은 경우
- 내부 테이블에 인덱스가 존재하지 않는 경우
실사용의 경우에서는 아무래도 해싱을 하는데 메모리 소요가 있으므로
실시간 처리를 중시하는 OLTP(실시간 온라인 서비스)에서는 추천되지 않고
부담이 적은 야간의 배치 작업이나 BI/DWH와 같은 백그라운드 정보 가공에 활용할 것이 추천된다.(결국은 Nested Loops의 차선책!)
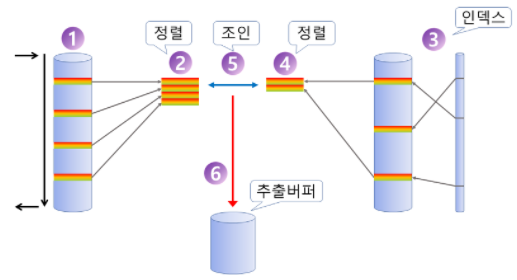
마지막으로 Sort Merge 방식의 경우 결합 대상이 되는 테이블들을
각각 결합키를 기준으로 정렬하고 이후 일치하는 결합키들끼리 Join하는 방식이다.
정렬은 많은 자원을 소모하는 작업이므로 기존의 Data가 정렬되어 있다는 정보가 있어
정렬을 생략 할 수 있는 예외적인 상황에서 사용하는 것이 좋다.
(Nested Loops > Hash > Sort Merge 순으로 고려!)

각 알고리즘의 장단점 정리

상황별 알고리즘 선택 가이드
SELECT /*+ USE_NL(d) */
count(d.dname)
FROM emp e, dept d
WHERE e.deptno = d.deptno;JOIN 알고리즘에 대해서만 알고 실제로 JOIN 알고리즘을 변경 할 수 없다면
의미가 크게 줄어든다고 생각한다.
위의 SQL은 오라클 기준 HINT를 통해 JOIN 알고리즘을 변경하는 방법으로
USE_NL, USE_HASH, USE_MERGE 등의 구문으로 알고리즘을 선택 할 수 있다.

이러한 튜닝 방식은 DBMS마다 다른데 MySQL의 경우 결합 알고리즘이
Nested Loops 계열 밖에 없기 때문에 선택의 여지가 없다고 한다...ㅠㅜ
이러한 인위적인 튜닝 방식은 데이터의 변화에 따른 옵티마이저의 유동적 선택에 우선하기 때문에
변경 당시에는 효과적일 수 있으나 데이터 양과 구조 변화에 따라 유동적으로 대처하지 못하므로
급격한 성능 하락을 가져올 수 있기에 알고리즘 선택과 관리에 있어 신중할 필요가 있다.
