본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다
Abstract
희소하게 활성화된 전문가 혼합(MoE) 모델은 주어진 토큰이나 샘플에 대한 계산량을 유지하면서 파라미터 수를 크게 증가시킬 수 있음
하지만 부적절한 전문가 라우팅 전략은 특정 전문가가 과도하게 훈련되거나 훈련이 부족해지는 문제를 초래할 수 있음
이전 연구에서는 다른 토큰의 상대적 중요도와 관계없이 고정된 수의 전문가를 각 토큰에 할당하는 top-k 함수를 사용함
이를 해결하기 위해, 본 연구에서는 전문가 선택 방법을 적용한 이질적인 전문가 혼합 모델을 제안함
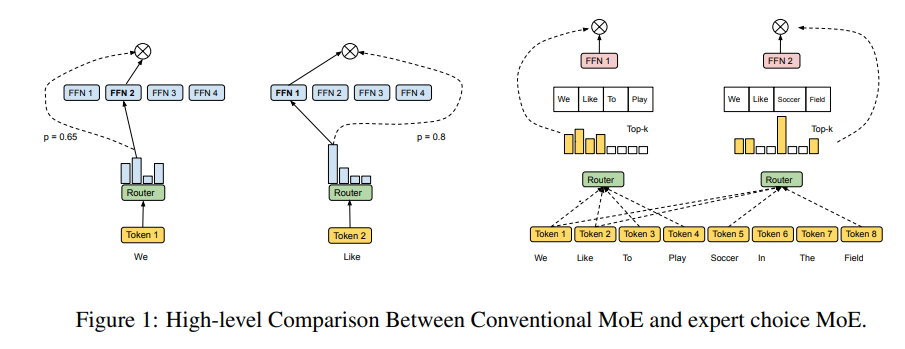
토큰이 top-k 전문가를 선택하는 대신, 전문가들이 top-k 토큰을 선택하며, 그 결과, 각 토큰은 가변적인 수의 전문가에게 라우팅될 수 있으며, 각 전문가는 고정된 버킷 크기를 가질 수 있음
제안하는 방법은 Switch Transformer top-1과 GShard top-2 게이팅의 계산 자원을 사용하여 사전 훈련 속도를 체계적으로 연구했으며, 해당 방법이 훈련 수렴 시간을 2배 이상 향상시킨다는 것을 발견함
동일한 계산 비용으로, GLUE 및 SuperGLUE 벤치마크에서 선택된 11개의 작업에서 더 높은 성능을 보여줌
또한 더 작은 활성화 비용으로, 11개의 작업 중 7개에서 T5 밀집 모델보다 뛰어난 성능을 발휘함
1 Introduction
전문가 선택 라우팅을 통한 새로운 MoE 모델의 필요성과 중요성을 설명
기존 MoE 모델의 부하 불균형 문제를 해결하고, 훈련 효율성과 다운스트림 성능을 크게 향상시키기 위한 새로운 접근법을 제안함
- 기존 MoE의 일반적인 문제점 식별: 로드 밸런싱과 같은 문제를 식별하고, 학습된 토큰-전문가 중요도에 기반한 이질적인 전문가 선택 방법을 제안함
이 방법은 보조 손실을 부과하지 않고도 본질적으로 부하 균형을 보장함 - 훈련 수렴 속도 향상: 우리의 방법은 8B/64E 모델에서 top-1 및 top-2 게이팅과 비교하여 훈련 수렴 시간을 2배 이상 향상시킴
- 스케일링 성능 입증: 전문가 수를 16에서 128로 늘릴 때 훈련 퍼플렉시티를 평가한 결과, 제안 방법이 강력한 스케일링 성능을 보임을 확인함
- 다운스트림 작업에서 강력한 성능: GLUE 및 SuperGLUE에서 선택된 작업에서 제안 방법이 강력한 성능을 발휘했으며, 8B/64E 모델은 평가된 11개의 작업 중 7개에서 T5 11B 밀집 모델을 능가함
2 Related Work
- Scaling
다양한 접근법이 신경망 용량을 확장하여 성능을 향상시키기 위해 제안됨
최근 연구들은 모델 병렬성의 다양한 형태를 통해 수십억 개의 파라미터를 가진 모델을 성공적으로 확장함
모델 병렬성은 가중치와 텐서를 여러 코어에 걸쳐 분할하는 방식이며, 파이프라인 병렬성은 다른 장치를 통해 여러 레이어를 분할하여 마이크로 배치를 파이프라인으로 처리함
신경망의 지속적인 확장을 가능하게 하려면 모델 훈련과 제공 효율성을 향상시키는 것이 중요한 연구 분야가 됨 - Conditional Computation
조건부 계산은 입력에 따라 동적으로 계산 결정을 내릴 수 있음
조건부 계산은 특정 파라미터를 활성화하고 필요에 따라 계산을 수행함으로써 고정된 계산 비용으로 심층 신경망의 용량을 증가시키는 방법으로 제안됨
특정 작업에 대한 게이팅을 통해 학습 문제를 최적화할 때 발생할 수 있는 망각 문제를 방지하는 데 사용됨
게이팅 결정은 이진적일 수도 있고, 희소하거나 연속적, 확률적이거나 결정적일 수도 있음 - Mixture of Experts
희소하게 게이트된 MoE는 게이팅을 통해 모델 용량, 훈련 시간 또는 모델 품질에서 큰 향상을 보여준 첫 번째 모델임
Switch Transformer는 숨겨진 상태에서 소프트맥스를 사용하여 각 토큰에 대해 최고 전문가만 선택함으로써 게이팅을 단순화하고 이전 연구보다 더 나은 확장성을 보여줌
이전 모든 연구는 부하 균형을 명시적으로 장려하기 위해 보조 손실이 필요함
손실 항목은 주 손실을 압도하지 않도록 신중하게 가중되어야 하나 보조 손실은 균형을 보장하지 못하고, 강력한 용량 인자가 부과되어야 함
결과적으로 많은 토큰이 여전히 MoE 레이어에 의해 처리되지 않을 수 있음
3 Method
기존의 MoE 모델의 라우팅 방법에서 몇 가지 문제점을 식별하고, 1)로드 밸런싱, 2)과소 특화, 3)모든 토큰에 대한 동일한 계산 문제를 지적함
이러한 문제를 해결하기 위해 전문가 선택 라우팅을 사용하는 방법을 제시
3.1 Pitfalls of Token-Choice Routing
MoE는 밀집 모델에 비해 계산적으로 유리할 수 있지만, 라우팅 전략을 사용하여 각 토큰을 가장 적합한 전문가에게 할당해야 함
기존의 MoE 모델은 토큰 선택 라우팅을 사용하여 각 토큰에 대해 top-k 전문가를 독립적으로 선택함
우리는 이 전략이 최적화되지 않은 훈련으로 이어지는 몇 가지 문제점을 가지고 있다고 주장함
- 1) Load Imbalance
토큰 선택 라우팅은 전문가 간의 로드 밸런싱을 초래할 수 있음
일부 전문가는 많은 토큰을 가지고 훈련되지만, 나머지 전문가는 과소 활용됨
과소 활용된 전문가에 많은 모델 용량이 낭비될 수 있음
반면, 일부 토큰은 과잉 활용된 전문가가 각 단계에서 처리할 수 있는 최대 토큰 수를 초과하여 처리되지 않을 수 있음
이는 단계 지연 시간에 영향을 미쳐 추론 시간에도 영향을 미침
이전 방법은 로드 밸런싱을 맞추기 위해 보조 손실을 추가하지만, 보조 손실은 밸런싱을 보장하지 않으며 특히 초기 훈련 단계에서 중요한 로드 밸런싱을 맞추기 어려움
실험적으로 우리는 과잉 용량 비율이 일부 전문가에 대해 20%~40%에 이를 수 있음을 관찰함
이는 라우팅된 토큰의 상당 부분이 처리되지 않음을 나타냄 - 2) Under Specialization
각 MoE 레이어는 토큰-전문가 친화도를 학습하기 위해 게이팅 네트워크를 사용됨
이상적으로는 학습된 게이팅 네트워크가 유사하거나 관련된 토큰을 동일한 전문가에게 라우팅하도록 해야함
비최적화 전략은 중복 전문가를 생성하거나 충분히 특화되지 않은 전문가를 생성할 수 있음
과소 특화는 더 많은 부하 균형을 맞추지만, 라우팅 효율성은 떨어지는 큰 보조 손실을 부과하여 발생할 수 있음
보조 손실에서 로드 밸런싱과 특화 사이의 적절한 균형을 찾는 것은 토큰 선택 라우팅에서 도전 과제임 - 3) Same Compute for Every Token
토큰 선택 전략에서는 각 토큰이 정확히 k 명의 전문가를 받으며, 이는 동일한 계산량을 차지함
우리는 이것이 필요하지 않으며 바람직하지 않다고 가정함
대신, MoE 모델은 계산 자원을 유연하게 조정하여 전문가 선택에 기반한 균형 잡힌 할당을 생성하는 간단하지만 효과적인 방법을 설명함
3.2 Heterogeneous MoE via Expert Choice
전문가 선택 방법을 사용하여 기존의 토큰 선택 라우팅의 문제를 해결하는 방법을 설명
기존 라우팅과 달리, 전문가 선택 방법은 각 전문가가 top-k 토큰을 독립적으로 선택함, k는 고정된 전문가 용량(각 전문가가 처리할 수 있는 토큰 수)
실험 설정
실험에서 우리는 k를 다음과 같이 설정

여기서 n은 입력 배치의 총 토큰 수(batch size × sequence length)이고, c는 용량 인자이며, e는 전문가의 수
용량 인자는 평균적으로 얼마나 많은 전문가가 하나의 토큰에 의해 활용되는지를 나타냄
입력 토큰 표현 을 사용하여 토큰-전문가 할당을 나타내는 세 개의 출력 행렬 을 생성함 (는 모델 숨겨진 차원)
행렬 는 인덱스 행렬로, 는 번째 선택된 전문가의 번째 토큰을 지정함
게이팅 행렬 는 선택된 토큰의 전문가 가중치를 나타내며, 는 각 전문가에 대해 선택된 토큰을 게이트하기 위해 사용되는 원-핫 버전의 를 나타냄
위 행렬들은 다음 게이팅 함수에 의해 계산됨:
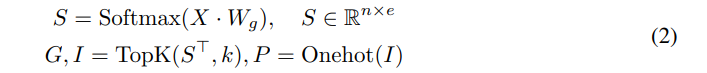
여기서 는 토큰-전문가 친화도 점수를 나타내고, 는 전문가 임베딩을 나타냄
함수는 각 행에서 k개의 가장 큰 항목을 선택함
Switch Transformer 및 GShard와 유사하게, 우리는 전문가 혼합과 게이팅 기능을 Transformer 기반 네트워크의 가장 계산 비용이 많이 드는 부분인 밀집 피드포워드(FFN) 레이어에 적용함
게이팅된 FFN의 입력 은 순열 행렬 를 사용하여 생성됨
여기서 는 번째 전문가의 입력을 나타냄
마찬가지로, 및 는 게이팅된 FFN의 파라미터로, 및 는 번째 전문가의 파라미터를 나타냄
각 전문가 의 출력을 다음과 같이 계산함:
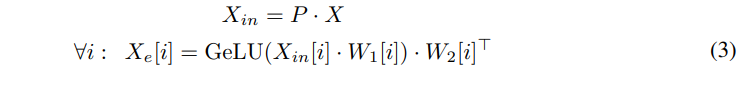
게이팅된 FFN 레이어의 최종 출력 은 다음과 같이 계산:
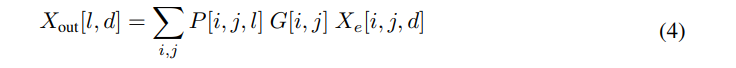
둘 다 와 는 Einstein summation(아인슈타인 합) 연산을 사용하여 효율적으로 계산할 수 있음
이 방법은 설계상 완벽한 부하 균형을 달성하며, 또한, 토큰이 가변적인 수의 전문가로부터 수신될 수 있기 때문에 모델 계산의 유연한 할당을 가능하게 함
3.3 Expert Choice with Additional Constraint
추가 제약을 통한 전문가 선택 라우팅을 정규화하는 방법을 설명하며, 각 토큰에 대해 최대 전문가 수를 제한하여 모델 성능을 분석하고, 효율적이고 균형 잡힌 할당을 생성함
각 토큰에 대한 최대 전문가 수를 제한하여 전문가 선택 라우팅을 정규화하는 것을 고려함
이 제약 조건을 추가하는 것이 사전 훈련 및 미세 조정 결과를 개선하는지, 더 나아가 토큰당 가변적인 수의 전문가를 사용하는 것이 모델 성능에 어떤 영향을 미치는지 분석
행렬 를 정의하고, 여기서 는 번째 전문가가 번째 토큰을 선택하는지를 나타냄
본 연구에서는 다음과 같은 엔트로피 정규화 선형 프로그래밍 문제를 해결함:
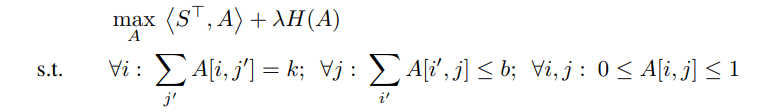
해결 공간은 각 선형 제약 조건을 만족하는 세 개의 볼록 집합의 교차점
우리는 중간 솔루션을 한 볼록 집합으로 투영하는 Dykstra 알고리즘을 사용함
가 계산된 후에는 라우팅 인덱스 가 대신 를 사용하여 선택
3.4 Model Architecture
고수준에서 우리는 희소하게 활성화된 전문가 혼합(MoE) 아이디어를 채택하고, Transformer 아키텍처를 사용하며 최근의 관행에 따라 모든 Transformer 레이어의 피드포워드 구성 요소를 MoE 레이어로 대체함
- 전문가 혼합 레이어 구성: 각 MoE 레이어는 독립적인 피드포워드 네트워크 그룹으로 구성되며, 게이팅 함수는 소프트맥스 활성화 함수를 사용하여 전문가에 대한 확률 분포를 모델링함
- 기존 MoE 방법과의 비교: 우리는 기존의 MoE 방법과 비교하여, 전문가 선택 방법이 부하 균형과 효율적인 계산 자원 사용에서 더 나은 성능을 제공함을 실험적으로 확인함
본 연구에서는 모델의 확장 효과를 이해하기 위해 전문가의 수를 증가시켜 100M 규모의 아키텍처(즉, 100M 전문가 크기)에서 여러 변형을 훈련시킴
또한 8B 규모 설정도 사용하여 GSPMD 알고리즘을 통해 2D 셰어딩 알고리즘으로 큰 MoE 모델을 분할하여 TPU 클러스터의 2D 토폴로지를 완전히 활용함
다양한 크기와 설정에서 우리의 방법은 관련 연구를 능가하며 GLUE와 SuperGLUE의 다운스트림 작업에서 우수한 성능을 보임
5 Conclusion
희소 활성화 Mixture-of-Experts (MoE) 모델을 위한 새로운 라우팅 방법을 제안함
이 방법은 기존 MoE 방법의 로드 불균형과 전문가의 활용 부족 문제를 해결하고, 각 토큰에 대해 다양한 수의 전문가를 선택할 수 있게 함
본 모델은 최첨단 GShard 및 Switch Transformer 모델과 비교하여 2배 이상의 훈련 효율성을 향상시키며, GLUE 및 SuperGLUE 벤치마크의 11개 데이터셋에서 파인튜닝할 때도 강력한 성능 향상을 보임
6 Limitations
Expert Choice 방법은 현재 구현이 과거와 미래의 토큰을 사용하여 top-k 선택을 수행하기 때문에 자동 회귀 텍스트 생성에 즉시 적용되지 않을 수 있음
하나의 가능한 해결책은 큰 입력 시퀀스 배치를 수집하여 동일한 시퀀스의 토큰을 별도의 그룹으로 디스패치하고, 각 그룹에 대해 전문가 선택 라우팅을 수행하는 것임
또 다른 경우는 서빙 또는 추론 중 배치 크기가 매우 작아질 때 이 방법이 즉시 적용되지 않는 것
대신 글로벌 top-k를 선택할 수 있으며, 각 전문가 또는 토큰이 선택되는 횟수를 제한할 수 있으며, 이러한 가능성 있는 개선 사항은 향후 작업으로 남겨둠
MoE의 또 다른 오랜 문제는 큰 메모리 발자국임
희소 게이트 네트워크를 사용하면 계산 비용은 줄일 수 있지만, 총 파라미터 수는 전문가 수와 함께 선형 또는 초선형으로 증가함
전문가 수를 늘리면 많은 하드웨어 장치의 예약(사용되지 않는) 전력을 요구하게 됨
따라서 동적(사용된) 전력은 절약되지만, 정적(예약된) 전력은 절약되지 않음
사용하지 않을 때 하드웨어 장치를 저전력 상태로 전환할 수 있는 기능과 같은 전력 절약 기술이 도움이 될 수 있음
