[Paper Review] OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER
[Paper Review] Seminar
본 Paper Review는 고려대학교 스마트생산시스템 연구실 2024년 하계 논문 세미나 활동입니다.
논문의 전문은 여기에서 확인 가능합니다
Abstract
- 신경망이 정보를 흡수할 수 있는 용량은 파라미터 수에 의해 제한 됨
- 조건부 계산은 네트워크의 일부가 예제마다 활성화 되는 방식으로 계산량을 모델 용량에 따라 증가됨
- 조건부 계산을 실현
- GPU에서 계산 효율성의 미미한 손실로 모델 용량을 1000배 이상 향상시키는 성과를 달성
- 최대 수천 개의 피드포워드 서브네트워크로 구성된 MIXTURE-OF-EXPERTS(MoE) LAYER 소개
- 학습 가능한 Gating network가 각 예제에 대하여 Experts의 희소한 조함을 결정함
- MoE를 언어 모델링과 기계 번역 과제에 적용하여 낮은 계산 비용으로 SOTA를 달성함
1 INTRODUCTION AND RELATED WORK
1.1 CONDITIONAL COMPUTATION
대규모 신경망 학습의 성공은 학습 데이터와 모델 크기의 확장을 활용하는 데 있으며, 데이터셋이 충분히 크면 신경망의 용량(파라미터 수)을 늘리면 훨씬 더 나은 예측 정확도를 얻을 수 있음
- 텍스트 (Sutskever et al., 2014; Bahdanau et al., 2014; Jozefowicz et al., 2016; Wu et al., 2016)
- 이미지 (Krizhevsky et al., 2012; Le et al., 2012)
- 오디오 (Hinton et al., 2012; Amodei et al., 2015)
위 3가지 외 여러 분야에서 증명됨
일반적인 심층 학습 모델에서는 모든 예제에 대해 전체 모델이 활성화되므로, 모델 크기와 학습 예제 수가 증가함에 따라 학습 비용이 대략적으로 제곱으로 증가함
불행히도, 컴퓨팅 성능과 분산 계산의 발전은 이러한 수요를 충족시키지 못했음
다양한 형태의 조건부 계산이 비례적인 계산 비용 증가 없이 모델 용량을 늘리는 방법으로 제안됨
이러한 체계에서는 네트워크의 큰 부분이 예제별로 활성화 또는 비활성화되며, Gating 결정은 이진적이거나 희소하고 연속적일 수 있으며, 확률적 또는 결정론적일 수 있음
강화 학습 및 역전파의 다양한 형태가 Gating 결정을 훈련시키는 데 제안됨
1.2 OUR APPROACH: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER
Sparsely-Gated Mixture-of-Experts Layer (MoE): 조건부 계산에 대한 우리의 접근법은 새로운 유형의 범용 신경망 구성 요소를 도입하는 것
MoE는 여러 전문가들(feed-forward neural network)과 학습 가능한 게이팅 네트워크로 구성됨
이 게이팅 네트워크는 각 입력을 처리하기 위해 전문가들의 희소한 조합을 선택함(아래 그림 참고)
네트워크의 모든 부분은 역전파에 의해 공동으로 학습됨
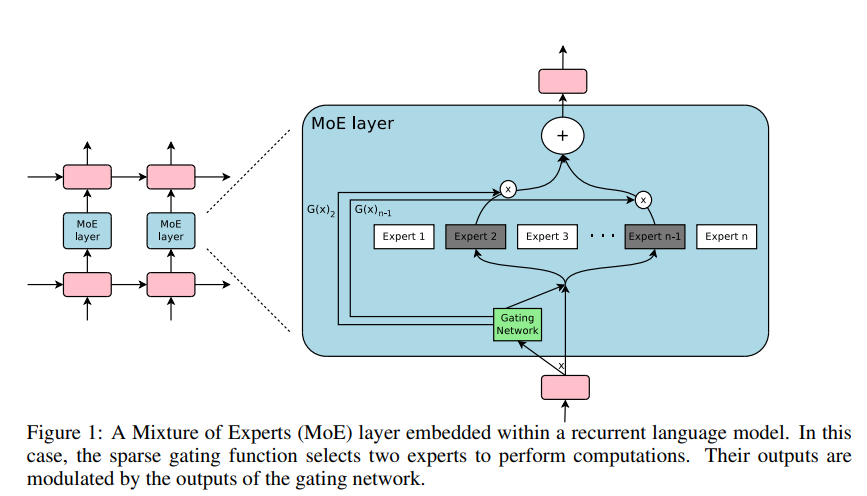
도입된 기술은 일반적이지만, 이 논문에서는 매우 큰 모델로부터 이익을 얻는 것으로 알려진 언어 모델링 및 기계 번역 작업에 중점을 둠
특히, 우리는 MoE를 쌓인 LSTM 레이어 사이에 컨볼루션 방식으로 적용
MoE는 텍스트의 각 위치마다 한 번씩 호출되며, 각 위치에서 잠재적으로 다른 전문가 조합을 선택함
1.3 RELATED WORK ON MIXTURES OF EXPERTS
전문가 혼합(MoE) 접근법은 두 세기 전 처음 도입된 이후로 많은 연구의 주제가 되어 왔음
다양한 유형의 전문가 아키텍처가 제안되었으며, 여기에는 SVMs, 가우시안 프로세스, 디리클레 프로세스, 심층 신경망 등이 포함됨
다른 연구들은 계층 구조, 무한 전문가 수, 전문가 순차 추가 등 다양한 전문가 구성에 초점을 맞춤
Garmash & Monz는 기계 번역을 위한 전문가 혼합 형식의 앙상블 모델을 제안했으며, 게이팅 네트워크는 사전 훈련된 앙상블 NMT 모델에서 학습됨
Eigen et al.은 심층 모델의 일부로 여러 MoE를 자체 게이팅 네트워크와 함께 사용하는 아이디어를 도입하였으며, 이 후자의 접근법이 더 강력하다는 것은 직관적으로 나타남
복잡한 문제는 각기 다른 전문가를 요구하는 많은 하위 문제를 포함할 수 있기 때문이며, 희소성을 도입할 가능성을 언급하면서 MoE를 계산의 수단으로 전환함
MoE를 범용 신경망 구성 요소로 사용하는 이 접근법을 기반으로 함
Eigen et al.은 두 개의 MoE를 쌓아 두 세트의 게이팅 결정을 허용하는 반면, 논문에서 제안된 방법론은 컨볼루션 MoE 적용은 텍스트의 각 위치에서 다른 게이팅 결정을 허용함
또한 희소 게이팅을 실현하고 모델 용량을 대폭 증가시키는 실용적인 방법으로서의 사용을 입증함
2 THE STRUCTURE OF THE MIXTURE-OF-EXPERTS LAYER*
MoE레이어는 여러 개의 expert networks 와 gating network 로 구성됨
- 게이팅 네트워크의 출력은 희소한 n차원 벡터임
- 전문가들은 각자 자신만의 파라미터를 가진 신경망
이론적으로 전문가들이 동일한 크기의 입력을 받고 동일한 크기의 출력을 생성하기만 하면 되지만, 본 연구에서는 동일한 아키텍처의 피드포워드 네트워크를 사용하되, 파라미터는 분리된 모델을 사용함
주어진 입력 에 대해 게이팅 네트워크의 출력을 로, 번째 전문가 네트워크의 출력을 로 나타내면, MoE 모듈의 출력 는 다음과 같이 쓸 수 있음
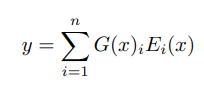
계산은 의 희소성에 기반하여 절약되며, 인 경우 를 계산할 필요가 없음
우리의 실험에서는 수천 명의 전문가를 보유할 수 있지만, 예제마다 소수의 전문가만 평가하면 됨
전문가 수가 매우 많을 경우, 2단계 계층형 MoE를 사용하여 분기 계수를 줄일 수 있음
계층형 MoE에서는 기본 게이팅 네트워크가 "전문가"의 희소 가중 조합을 선택하고, 각 전문가가 자체 게이팅 네트워크를 가진 2차 전문가를 혼합함
본 연구에서는 일반 MoE에 초점을 맞춤
2.1 GATING NETWORK
-
Softmax Gating
Softmax 게이팅은 비희소 게이팅 함수로, 학습 가능한 가중치 행렬 를 입력 에 곱한 후 함수를 적용함
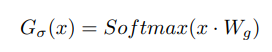
-
Noisy Top-K Gating
Softmax 게이팅 네트워크에 두 가지(1.희소성과 2.노이즈) 구성 요소를 추가함
Softmax 함수를 적용하기 전에, 조정 가능한 가우시안 노이즈를 추가하고, 상위 k개의 값만 남기고 나머지는 -∞로 설정
이는 계산을 절약하기 위한 희소성을 제공함
이 형태의 희소성은 이론적으로 게이팅 함수 출력에 불연속성을 유발할 수 있으나, 실용적으로는 문제가 되지 않음
노이즈 항은 로드 밸런싱에 도움을 주며, 노이즈 양은 두 번째 학습 가능한 가중치 행렬 에 의해 제어됨

-
Training the Gating Network
게이팅 네트워크는 모델의 나머지 부분과 함께 간단한 역전파를 통해 훈련됨
인 경우, 상위 k개의 전문가에 대한 게이트 값은 게이팅 네트워크의 가중치에 대해 미분 가능하며, 이는 Bengio et al. (2013)에서 설명된 대로 노이즈 정류기와 관련이 있음
게이팅 네트워크의 입력에 대한 그라디언트도 역전파되며, 이 방법은 boolean 게이트와 REINFORCE 스타일 접근 방식을 사용하는 Bengio et al. (2015)과는 다름
3 ADDRESSING PERFORMANCE CHALLENGES
대규모 신경망 학습에서 발생하는 성능 문제를 해결하는 방법을 설명
주요 문제로는 축소되는 배치 크기와 네트워크 대역폭이 있음
3.1 THE SHRINKING BATCH PROBLEM
축소되는 배치 크기와 같은 문제를 해결하기 위해 데이터 병렬성과 모델 병렬성을 혼합하고, 배치 크기를 증가시키는 기술을 제안함
- Mixing Data Parallelism and Model Parallelism
계층형 MoE의 경우, 주요 게이팅 네트워크는 데이터 병렬성을 사용하고, 2차 MoE는 모델 병렬성을 사용함
각 2차 MoE는 하나의 장치에 상주함 - Taking Advantage of Convolutionality
언어 모델에서는 이전 레이어의 각 타임 스텝에 동일한 MoE를 적용함
이전 레이어가 완료될 때까지 기다리면, 모든 타임 스텝을 하나의 큰 배치로 적용할 수 있음
이렇게 하면 MoE 레이어의 입력 배치 크기를 언롤된 타임 스텝 수만큼 늘릴 수 있음 - Increasing Batch Size for a Recurrent MoE
더 강력한 모델은 MoE를 순환적으로 적용할 수 있음
예를 들어, LSTM 또는 다른 RNN의 가중치 행렬이 MoE로 대체될 수 있으며, 불행히도 이러한 모델은 이전 단락의 컨볼루셔널 트릭을 깨뜨림
Gruslys et al.(2016)은 순차적인 RNN에서 저장된 활성화 수를 크게 줄이는 기술을 설명하고, 이는 배치 크기를 크게 늘릴 수 있음
3.2 NETWORK BANDWIDTH
네트워크 대역폭 문제를 해결하기 위해 전문가의 계산과 입력/출력 비율을 최적화하는 방법을 설명함
분산 컴퓨팅의 또 다른 주요 성능 문제는 네트워크 대역폭임
전문가가 고정되어 있고 게이팅 파라미터의 수가 적기 때문에 대부분의 통신은 네트워크를 통해 전문가의 입력과 출력을 전송하는 것
계산 효율성을 유지하기 위해 전문가의 계산과 입력/출력 크기의 비율은 계산 장치의 네트워크 용량 비율을 초과해야 함
본 논문의 실험에서 전문가들은 수천 개의 ReLU 활성화 유닛을 포함하는 한 개의 숨겨진 레이어를 가지며, 전문가의 가중치 행렬 크기는 및 이며, 계산과 입력/출력의 비율은 숨겨진 레이어의 크기와 동일함
더 큰 숨겨진 레이어를 사용하거나 여러 숨겨진 레이어를 사용하면 계산 효율성을 높일 수 있음
4 BALANCING EXPERT UTILIZATION
전문가 활용의 균형을 맞추기 위한 접근법을 설명함
- 게이팅 네트워크의 편향 문제를 해결하기 위해, 우리는 전문가의 중요도를 균형 있게 유지하기 위한 소프트 제약과 추가 손실 함수 를 도입함
- 분산 하드웨어에서 메모리와 성능 문제를 해결하기 위해 부하 균형을 맞추는 두 번째 손실 함수 를 도입함
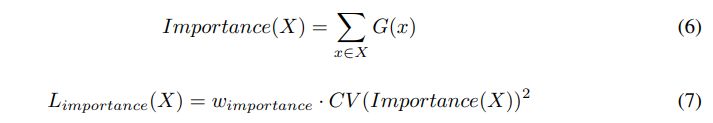
6 CONCLUSION
본 연구는 조건부 계산이 심층 신경망에서 주요 성과를 가져올 수 있음을 처음으로 입증한 사례임
우리는 조건부 계산의 설계 고려 사항과 도전 과제를 신중하게 식별하고, 이를 알고리즘적 및 엔지니어링 솔루션의 조합으로 해결함
본 연구는 텍스트에 초점을 맞추었지만, 조건부 계산은 충분히 큰 훈련 세트가 제공된다면 다른 분야에서도 유용할 수 있음
