
교차 검증이란?
-
검증 : 모델의 학습이 잘 진행되었는지, 즉 일반화 능력이 좋은지를 판단하는 평가 과정
-
검증 데이터를 선택 할 때 아래와 같은 문제가 발생 가능
- 쉬운 데이터로의 편향
- 전체적인 데이터 양의 부족
-
교차 검증 (Cross Validation) : 전체 데이터를 여러 개의 하위 데이터로 나누고, 하위 데이터 세트들의 조합을 서로 다른 방법으로 훈련과 검증에 사용하여 모델의 일반화 능력을 측정하는 방법
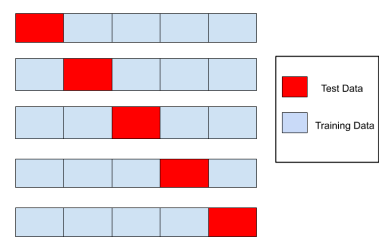
K-Fold CV -> 기본
- 전체 데이터를 총 K개의 덩어리(Fold)로 나누고, 각 덩어리를 순차적으로 검증 데이터로 사용하고 나머지는 훈련 데이터로 사용하는 방법
- 모든 데이터가 학습 / 평가에 사용된다
- overfitting을 방지해준다
- 논리적인 일반화 평가를 진행한다
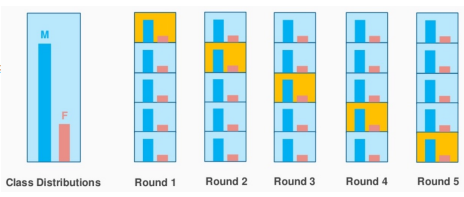
계층적 교차 검증 (Stratified Cross-Validation) -> 비율을 맞춘 K-Fold
- K-Fold CV와 유사하지만, 각 폴드에서 클래스의 비율을 원본 데이터셋의 그것과 비슷하게 유지한다.
- K-Fold의 장점과 더불어 클래스 사이의 불균형(편향)까지 고려한다
LOOCV (Leave-One-Out CV) -> 극단적 K-Fold
-
한 번에 하나의 데이터 포인트만을 검증 데이터로 사용
- 데이터 셋의 row가 총 N개라고 할 때, K = N인 K-Fold CV와 같다
-
매우 정확한 검증 방식이지만, 거의 데이터셋의 크기가 작은 경우에만 사용 가능하다
성능평가
-
머신 러닝 모델의 성능을 객관적으로 측정하고 비교하는 지표 (metric)
-
metric에는 다양한 종류가 있으며, 목적에 맞는 올바른 metric을 선택해야한다.
추가적인 분류 Metric
-
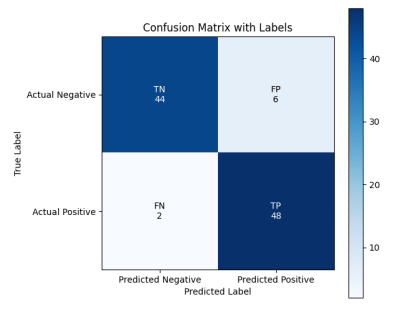
Confusion Matrix : 분류 문제에서 모델의 성능을 이해하고 해석하기 위한 중요한 도구
-
4가지 요소로 구성되어 있다
- 진짜 양성 : TP
- 거짓 양성 : FP
- 진짜 음성 : TN
- 가짜 음성 : FN
- 분류 문제의 기본적인 metric은 아래와 같다
- Accurancy : 진짜 예측한 거 / 전체
- Precision : 양성인거를 올바르게 분류 / 양성으로 예측한거 전체
- Recall : 양성인거를 올바르게 분류 / 진짜 양성인거

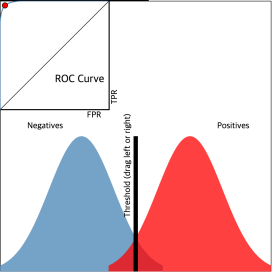
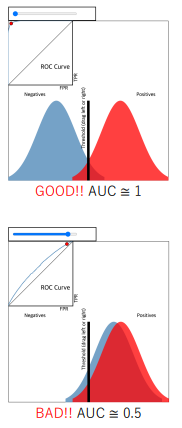
- ROC(Receiver Operating Characteristic) curve
- 이진 분류 문제에서 적절한 threshold 값을 찾을때 사용하는 모델 성능 측정 도구
- 양성과 음성을 나누는 threshold 값을 변화할 때 성능의 변화(Confusion Matrix)를 시각화한 그래프
- X축 : 거짓 양성률 (False Positive Rate, FPR) = FP / TN + FP
- Y축 : 진짜 양성률 (True Positive Rate , TPR) = TP / FN + TP
- 왼쪽 위에 있는 포인트 (FPR 값은 작고, TPR 값은 큰)를 선택하는 것이 좋다
-
AUC(Area Under the Curve) 점수
- 분류기의 성능 (음성과 양성을 분류하는 것)을 평가하는 metric
- 음성과 양성을 잘 나눈 경우 ROC Curve가 왼쪽 위 방향으로 치우쳐진다
- 그렇지 못한 경우 y = x그래프에 수렴한다
- 즉, 좋은 분류기인지 아닌지에 따라 ROC 커브의 모양이 바뀌고, 해당 모양을 수치로 나타낸 것이 AUC score이다
- 0.5 <= AUC score <= 1
- AUC score가 클 수록 성능이 좋은 분류기이다
- 분류기의 성능 (음성과 양성을 분류하는 것)을 평가하는 metric
추가적인 회귀 Metric
-
R square (결정 계수, Coefficient of Determination)
-
회귀 모델의 성능을 평가하는 통계적 지표
-
데이터의 변동성을 얼마나 잘 설명하는지를 나타낸다
-
R square = 1 : 모델이 데이터의 변동성을 완벅하게 설명한다 (모든 데이터 포인트가 회귀선에 정확하게 놓여 있음)
-
R square = 0 : 변동성을 설명하지 못함
-
0 < R square < 1 : 일부 변동성을 설명한다
-

- R square 값이 클수록 설명력이 크다고 볼 수 있지만, 과적합의 위험성을 주의해야 한다.

개인 공부용 블로그입니다