
비지도학습이란?
-
정답 레이블이 지정되지 않은 데이터로부터 패턴을 찾아내는 학습 방법론
-
주어진 데이터의 구조나 패턴을 자동으로 탐색하는 목적을 가지고 있다
대표적인 해결 문제들
-
군집화 (Clustering) : 데이터를 유사한 특성을 공유하는 군집으로 분할하는 과정
-
차원 축소 (Dimensionality Reduction) : 고차원 데이터를 보다 낮은 차원으로 표현하여 데이터의 핵심적인 특성을 유지하는 기법
- 데이터의 시각화, 노이즈 감소, 계산 효율성 증가, 데이터 해석 등의 목적으로 진행한다
-
이상 탐지 (Anomaly Detection) : 데이터에서 비정상적인 패턴, 이상치, 또는 예외적인 사례를 탐지하는 과정
- 데이터에서 일반적으로 볼 수 있는 특성에서 많이 벗어난 데이터를 식별하는 과정에서 사용
군집화 종류
-
K-means Clustering
- 데이터를 K개의 cluster로 그룹화
- 각 클러스터의 중심을 계산하고, 각 데이터 포인트를 가장 가까운 클러스터 중심에 할당하는 방식으로 작동
- 반복적인 과정을 통해 클러스터 중심을 업데이트하며 최적화
-
Hierarchical Clustering
- 데이터 포인트를 개별 클러스터로 가정하여 시작
- 점차 유사한 클러스터를 병합하거나, 큰 클러스터를 세분화하는 방식으로 진행
-
DBSCAN (Density-Based Sparital Clustering of Applications with Noise)
- 데이터가 모여있는 밀도를 기반으로 클러스터를 형성
- 이상치 탐지에서 좋은 성능을 보여준다
차원 축소의 종류
- 주성분 분석 (PCA)
- 데이터의 분산을 최대한 보존하는 방향의 축을 찾고, 해당 축을 기준으로 고차원 데이터를 저차원으로 변환
- 데이터의 주요 측성을 추출하고 시각화하는 과정에서 사용
- t-SNE
- 고차원 데이터의 구조를 보존하면서 저차원으로 매핑하는 기법
- 시각화 과정에서 유용하게 사용한다
- Autoencoder
- 신경망을 이용한 차원 축소 기법
- 입력 데이터를 저차원으로 압축 후, 다시 원래 차원으로 복원하는 방식으로 핵심 특징을 만들어냄
이상 탐지의 종류
- Iosaltion Forest
- Tree를 기반으로 특정 데이터 포인트를 격리시키는 데 필요한 분할 수를 기준으로 이상치를 탐지
- One-Class SVM
- 정상 데이터만을 활용해 "정상" 이라는 class로 SVM을 학습하고, SVM이 정상 패턴에서 벗어나는 데이터를 보고 출력하는 결과를 보고 이상치를 판단
- LOF (Local Outlier Factor)
- 주어진 데이터 주변의 데이터 밀도를 계산. 정상 데이터는 주변에 높은 데이터 밀도를 갖고 있고, 이상치 데이터는 주변에 데이터가 적어 낮은 밀도를 갖고 있음을 활용
K-means Clustering
-
로이드 알고리즘
- 1) 초기화 : K개의 클러스터 중심점을 임의로 선택
- 2) 할당 : 각 데이터 포인트를 가장 가까운(유클리드 거리) 클러스터 중심에 할당
- 3) 업데이트 : 각 클러스터에 속한 데이터들의 평균점 위치로 클러스터 중심을 업데이트
- 4) 반복 : 1~3까지의 과정을 중심점의 위치가 변하지 않을 때 까지 반복
-
엘칸 알고리즘
- 데이터 포인트와 클러스터 중심 거리를 계산하는 과정에서 삼각 부등식을 사용
- |a + b| <= |a| + |b|
-
엘보우 방법 (Elbow Method) : 실제 Clustering을 진행해야 할 때는 K의 값을 알 수 없다. 그래서 클러스터 수를 늘려가며 각각에 클러스터링 성능을 측정하여 최적의 K값을 설정
-
SSE(Sum of Squared Error) 값을 사용하여 클러스터링 성능을 측정한다
- SSE의 감소율이 급격히 줄어드는 지점이 최적의 K값으로 간주한다 (최소의 SSE가 최적의 K는 아니다!)
-
실루엣 계수 (Silhouette Coefficient) : 클러스터의 응집도와 서로 다른 클러스터 간의 분리도를 고려하여 Clustering의 품질을 평가하는 방법
- s(i) = b(i) - a(i) / max(a(i), b(i))
- -1 <= s(i) <= 1인데, 클수록 좋은 군집화라고 볼 수 있다. -> 보통 양수 / 음수 정도로도 간단하게 판단 가능하다
-
응집도 (Cohesion, a(i)) : 특정 데이터 포인트 i에 대해 동일한 클러스터 안에 들어있는 다른 데이터들과의 평균 거리
- 클러스터 내부의 데이터가 얼마나 모여있는지를 나타낸다
-
분리도 (Separation, b(i)) : 특정 데이터 포인트 i에 대해, i가 포함되어있지 않은 클러스터 중 가장 가까운 클러스터의 중심까지의 거리
- 다른 클러스터와 얼마나 떨어져 있는지를 나타냄
이상탐지
- 전통적인 통계 기반 방법은 아래와 같다. 해당 방식들은 정규분포에서 적용하는 것이 가장 좋다
- IQR : Q1과 Q3간의 차이로 Q1 - 1.5IQR 미만, 혹은 Q3 + 1.5IQR 초과 데이터를 이상치로 간주
- Z-Score : 데이터 포인트가 평균으로부터 표준편차의 몇 배만큼 떨어져 있는지를 나타내는 수치. 3 이상인 데이터 포인트를 이상치로 간주한다.
- Isolation Forest
- 정상 데이터는 그와 비슷한 특성 패턴을 갖는 비슷한 데이터와 밀도 있게 모여있을 것이다. 반면, 이상치 데이터는 밀도가 낮은 공간에 존재할 것이다
- 이때, 하나의 데이터를 고립시키기 위해 어떤 특성과 그것의 분할 값을 기준으로 나눌 때,
- 정상 데이터의 경우 밀도가 높은 구역에 있기 때문에 많은 분할 과정을 지나야 고립된다.
- 이상치 데이터는 적은 분할 과정으로도 고립된다.
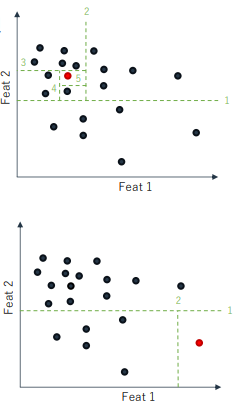
- 만약 이상 데이터의 정답을 알고 있다면 이진 분류 형태의 문제로 해결할수도 있다.
