GAN (적대적 생성 신경망)
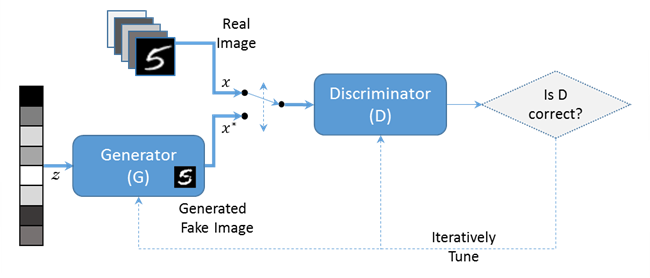
- GAN(Generative Adversarial Network)은 생성 모델 중 하나로, "Generator"와 "Discriminator"라는 두 개의 신경망이 서로 경쟁하며 학습하는 방식으로 동작한다.
핵심 철학
- 데이터를 "잘" 생성한다는 것은, 단순히 기존 데이터를 복제하는 것이 아니라 실제 데이터의 고유한 특징을 유지하면서도 새로운 변형을 만들어내는 것이다.
1️⃣ 노이즈를 활용한 데이터 생성
"좋은 데이터를 만들려면 단순한 복사보다는 창조적 변형이 필요하다."

source : NLP with Deep Learning
-
간단하게 데이터를 증강하는 방법 중, 실제 데이터()에 표준 정규 분포()에서 샘플링한 노이즈를 추가하는 방식이 있다(Gaussian / salt and pepper)
-
이는 기존 데이터에 변화를 주어 새로운 데이터를 생성하는 방식이다.
-
GAN에서는 이러한 개념을 반대로 적용하여, 노이즈() 자체를 입력값으로 사용한다.
-
Generator()는 를 입력으로 받아 의 핵심 특징들을 학습하고, 이를 기반으로 새로운 데이터를 생성한다
-
즉, GAN은 기존 데이터를 변형하는 것이 아니라, 노이즈에서 시작하여 점진적으로 실제 데이터와 닮아가도록 학습하는 구조를 가진다.
-
-
이를 통해 새로운 데이터 샘플을 생성할 수 있으며, 학습이 진행될수록 Latent Space(잠재 공간)에서 의미 있는 데이터 패턴이 형성된다.
2️⃣ 적대적 학습(Adversarial Learning)
"진짜와 가짜가 경쟁하면, 결국 더 진짜 같은 가짜가 만들어진다"
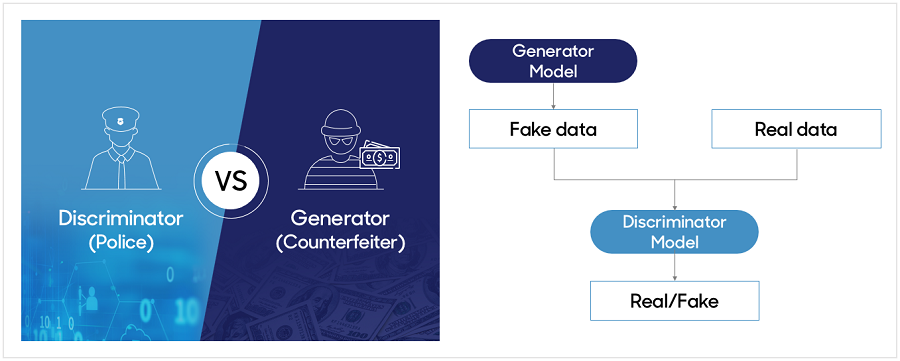
-
GAN은 "지폐 위조범 vs 경찰"의 관계로 비유할 수 있다
-
Generator(G)는 지폐 위조범으로, 경찰을 속이기 위해 점점 더 정교한 가짜 지폐를 만들어야 한다.
-
Discriminator(D)는 경찰로, 위조된 지폐를 정확히 구별할 수 있도록 지속적으로 학습해야 한다.
-
둘은 서로를 속이고 구별하는 경쟁을 통해 발전하며, 가짜 지폐(생성된 데이터)가 실제 지폐(실제 데이터)와 구별되지 않을 때까지 이 과정이 반복된다.
-
-
이처럼 GAN은 기존 데이터를 단순히 모방하는 것이 아니라, "경쟁을 통한 창조"를 목표로 한다.
작동방식
Building a Simple Python-Based GAN in 5 minutes를 기반으로 GAN의 기본 작동방식을 알아보자
📌 parameters (이미지 생성 기준)
| parameter | Generator | Discriminator |
|---|---|---|
input_size | 입력 노이즈 벡터의 크기 | 입력 이미지의 크기 (n × m 벡터) |
hidden_size | hidden vector 크기 (Feature 표현력 결정) | hidden vector 크기 (판별 능력 결정) |
output_size | 생성된 이미지의 크기 (n × m 벡터) | Real(1) vs Fake(0) 판별값 |
📌 Generator
class Generator(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Generator, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.tanh(self.fc2(x))
return x| Variables | 설명 | 차원 |
|---|---|---|
| Latent Space에서 샘플링된 랜덤 노이즈 | (batch_size, input_size) | |
| Generator의 hidden vector 학습 가중치 | (hidden_size, input_size) | |
| Generator의 output vector 학습 가중치 | (output_size, hidden_size) |
-
fc1 (first fully connected layer) :
-
가중치 행렬 적용 → Hidden Vector
- (
batch_size,input_size) → (batch_size,hidden_size)
- (
-
-
fc2 (second fully connected layer) :
-
가중치 행렬 적용 → 이미지 생성
-
(
batch_size,hidden_size) → (batch_size,output_size) -
Tanh 적용 → [-1 ~ 1] 범위로 정규화하여 이미지 데이터 형태로 변환.
-
-
📌 Latent Space의 의미
| 단계 | 설명 |
|---|---|
| 학습 전 | 표준 정규 분포(𝒩(0,1))에서 샘플링된 랜덤 노이즈 저장소로 작동한다. |
| 학습 진행 | Generator의 가중치(W)가 업데이트되면서, Latent Space가 의미 있는 데이터 특징을 가지도록 구조화됨. |
| 학습 종료 | Latent Space의 특정 위치가 원본 데이터의 특징을 의미하는 방식으로 정리됨.→ Latent Space의 위치는 원본 데이터의 다양한 특징을 저장하는 인덱스 역할을 하게 됨. |
-
GAN이 잘 학습되면, Latent Space에서 벡터 연산을 활용해 특징을 조작할 수도 있다.
-
예시 : {'' : 웃는 얼굴, '' : 무표정 얼굴}
- → "무표정에서 웃는 얼굴로 변화"하는 효과를 얻을 수 있음!
-
📌 Discriminator
class Discriminator(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Discriminator, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.sigmoid(self.fc2(x))
return x| Variables | 설명 | 차원 |
|---|---|---|
| 실제 이미지/Generator가 생성한 가짜 이미지 | (batch_size, input_size) | |
| Discriminator의 hidden vector 학습 가중치 | (hidden_size, input_size) | |
| Discriminator의 output vector 학습 가중치 | (output_size, hidden_size) |
-
fc1 (first fully connected layer) :
-
가중치 행렬 적용 → Hidden Vector
- (
batch_size,input_size) → (batch_size,hidden_size)
- (
-
-
fc2 (second fully connected layer) :
-
가중치 행렬 적용 → 최종 출력
-
(
batch_size,hidden_size) → (batch_size,output_size) -
Sigmoid 적용 → 출력값을 0~1 범위로 변환하여 진짜(1) vs 가짜(0) 판별 수행
-
-
📌 Training
-
데이터셋(MNIST)에서 진짜 이미지(
real_images)를 가져오기 -
noise_size 크기의 랜덤 노이즈 생성
-
Generator에 랜덤 노이즈를 전달하여 학습용 가짜 이미지(
fake_images) 생성
for i, (real_images, _) in enumerate(dataloader):
# Get the batch size
batch_size = real_images.size(0)
# Reshape real images to match Discriminator input (Flatten MNIST images)
real_images = real_images.view(batch_size, -1).to(device) # (batch_size, 784)
# Generate fake images
noise = torch.randn(batch_size, noise_size).to(device)
fake_images = generator(noise)-
Discriminator의 손실 함수 (Binary Cross Entropy) :
요소 설명 Discriminator는 손실 함수를 최대화하려고 학습. 즉, D(x)를 높이고 D(G(z))를 낮추는 것이 목표 real_images에 대해 Discriminator는 이를 1(진짜)로 예측해야 함fake_images()에 대해 Discriminator는 이를 0(가짜)로 예측해야 함
# Train the discriminator on real and fake images
d_real = discriminator(real_images) # 진짜 이미지 판별
d_fake = discriminator(fake_images) # 가짜 이미지 판별
# Calculate the loss
real_loss = loss_fn(d_real, torch.ones_like(d_real)) # 진짜 이미지는 1로 예측해야 함
fake_loss = loss_fn(d_fake, torch.zeros_like(d_fake)) # 가짜 이미지는 0으로 예측해야 함
d_loss = real_loss + fake_loss # 두 손실을 더함
# Backpropagate and optimize Discriminator
d_optimizer.zero_grad() # 기존 기울기(Gradient) 초기화
d_loss.backward() # 역전파 수행 (Discriminator의 가중치 업데이트)
d_optimizer.step() # 가중치 업데이트-
Generator의 손실 함수 :
요소 설명 Generator는 손실 함수를 최소화하려고 학습. 즉, D(G(z))를 높이는 것이 목표 fake_images()에 대해 Discriminator는 이를 1(진짜)로 예측해야 함
fake_images = generator(noise) # Regenerate fake images after Discriminator update
d_fake = discriminator(fake_images) # Test updated discriminator
g_loss = loss_fn(d_fake, torch.ones_like(d_fake)) # Generator wants Discriminator to output 1
# Backpropagate and optimize Generator
g_optimizer.zero_grad() # 기존 기울기(Gradient) 초기화
g_loss.backward() # 역전파 수행 (Generator의 가중치 업데이트)
g_optimizer.step() # 가중치 업데이트-
GAN의 경쟁 구조 (Minmax Game)
-
초반에는 Discriminator가 쉽게 진짜와 가짜를 구별함 -> 값이 0에 가까움
-
Generator가 점점 더 정교한 데이터를 생성하면서 Discriminator를 속임 -> 값이 커짐
-
학습이 충분히 진행되면 Discriminator는 50:50 확률로 예측하게 됨
-
한계
| 단점 | 설명 | 해결책 |
|---|---|---|
| Generator의 확률 분포 를 명시적으로 표현할 수 없음 | Generator가 어떤 특징을 학습했는지 명확하게 분석하기 어려움 | GAN 해석을 위한 Latent Space 분석 기법 활용 |
| Discriminator와 Generator의 학습 균형 유지 필요 | Discriminator가 너무 강하면 Generator가 학습하지 못하고, 반대로 Generator가 너무 강하면 Discriminator가 학습하지 못함 | 학습률 조절, Discriminator 학습을 충분히 한 후 Generator 학습, 학습 비율 조정(1:5 등) |
| Mode Collapse (Helvetica Scenario) | Generator가 다양한 데이터를 생성하지 못하고 특정한 패턴만 반복해서 생성하는 문제 | Discriminator를 정기적으로 업데이트, Noise Regularization, Minibatch Discrimination |
변형모델
-
DCGAN (Deep Convolutional GAN) : CNN을 활용하여 이미지 데이터를 더 효과적으로 생성하는 모델
-
WGAN (Wasserstein GAN) : Wasserstein Distance를 사용하여 학습 안정성을 높인 모델.
-
cGAN (Conditional GAN) : 특정 조건(label)을 추가하여 원하는 데이터를 생성하는 모델.
