RNN seq2seq 모델
- 비동기/동기를 기준으로 나누어 특징을 살펴보자
비동기적 Seq2Seq
- 시퀀스의 입력, 출력 길이가 다른 경우 비동기적 Seq2Seq(Encoder-Decoder) 모델을 사용한다.
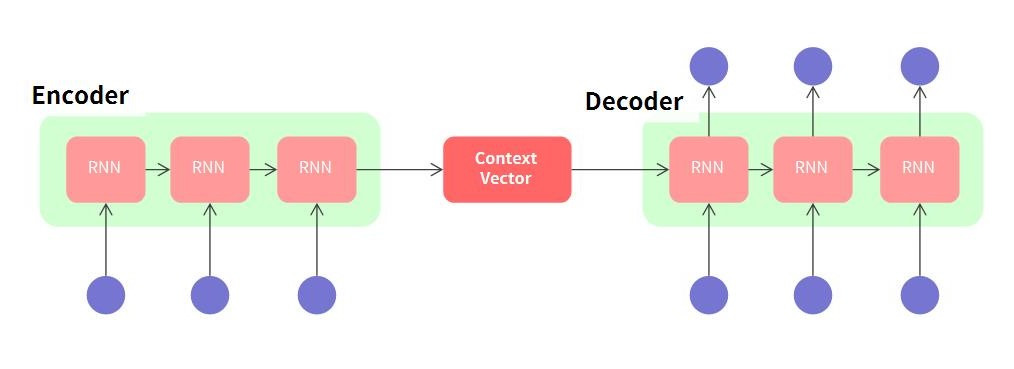
source : RNN 개념과 Encoder-Decoder 구조
-
비동기적 Seq2Seq의 기본 구조는 다음과 같다 (단, )
- Encoder : 길이 의 입력 시퀀스 정보를 압축하여 Context Vector에 저장
- Decoder : Context Vector를 통해 길이 의 시퀀스를 출력
-
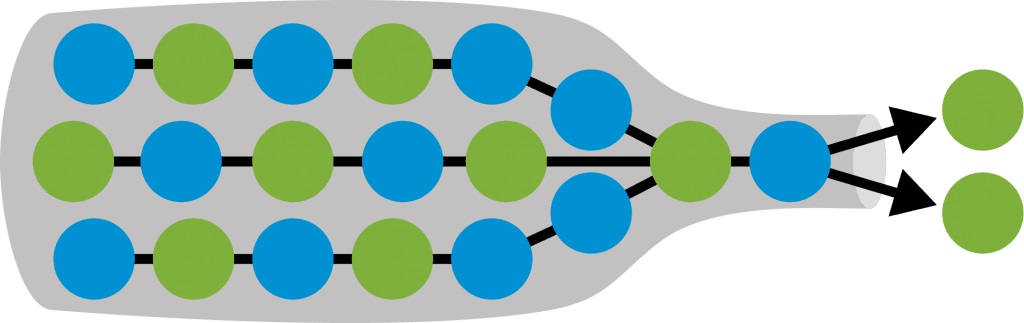
비동기적 Seq2Seq에서 발생하는 문제는 크게 두가지이다.
-
1️⃣ 정보의 병목 현상(Bottleneck Issue)
- 모든 입력 시퀀스 정보를 하나의 고정 크기 Context Vector로 압축해야 하므로, 정보의 손실이 필연적으로 발생한다.
- 즉, Decoder가 필요한 모든 정보를 Encoder에서 충분히 받아오지 못할 가능성이 커진다.
- 이러한 병목 현상은 특히 입력 시퀀스가 길어질수록 더 심각해지며, 결과적으로 출력 품질(성능)이 저하될 수 있다.
-
2️⃣ 기울기 소실 (Gradient Vanish)
- 모든 RNN 구조에서는 시퀀스가 길어질수록 초기 입력에 대한 기울기가 급격히 감소한다.
- 특히, [Encoder → Context Vector → Decoder]의 직렬 구조를 통해 역전파 경로가 길어지면서 GV 문제가 심화된다.
동기적 Seq2Seq
- 시퀀스의 입력, 출력 길이가 같은 경우 동기적 Seq2Seq 모델을 사용한다.
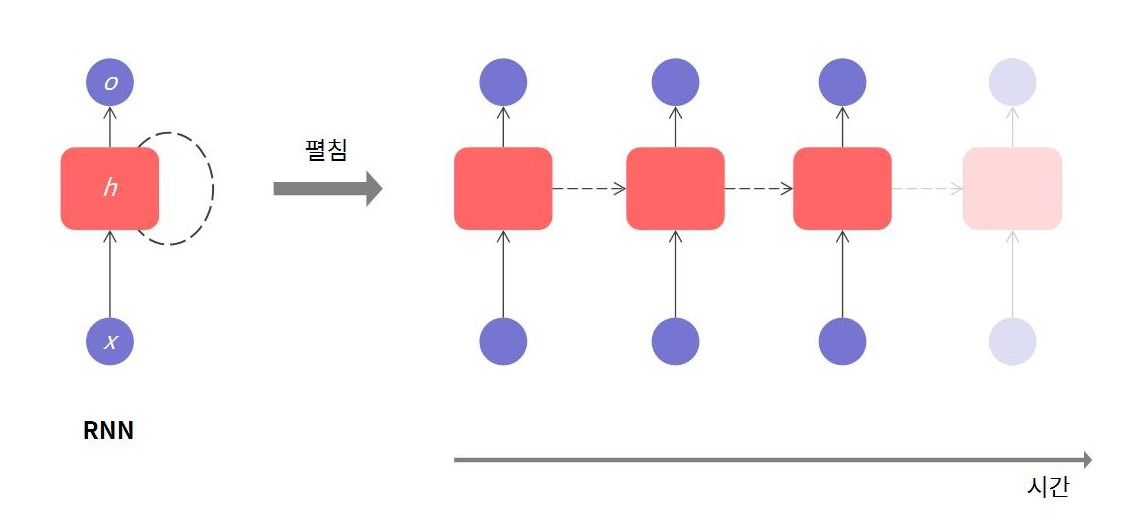
source : RNN 개념과 Encoder-Decoder 구조
-
동기적 Seq2Seq 모델에서는 입력과 동시에 출력이 나오므로, 정보가 지속적으로 갱신되며 정보의 병목 현상(Bottleneck Issue)이 발생하지 않는다.
- 출력이 곧바로 생성되기 때문에 추가적인 정보 압축 과정(Context Vector)이 필요하지 않지만, 은닉 상태의 차원 크기에 따른 정보 손실은 존재할 수 있다.
Attention Mechanism
"다음 중 주성분분석에 대한 설명으로 적절하지 않은 것을 모두 고르시오"
- 위 문제를 읽은 후 머리에 남아있는 주요 단어는 [주성분분석, 않은, 모두] 일 것이다.
- Attention은 이러한 인간의 매커니즘을 모방하여 모든 정보를 똑같이 중요하게 처리하지 않고, 핵심적인 정보에 집중하는 원리를 적용한다.
기본 특징
-
✅ 정보의 연결(connection)
-
Attention은 Encoder-Decoder를 직렬 연결 방식이 아닌, "네트워크(Network)" 방식으로 연결한다.
-
즉, Decoder가 Encoder의 모든 타임스텝과 직접 연결될 수 있도록 허용한다.
-
이를 통해 기계 번역처럼 입력과 출력의 위치가 1:1로 매칭되지 않는 경우에도 유연하게 대응할 수 있다.
-
-
✅ 정보의 선별(selection)
-
Attention은 입력 전체를 참고하되, 특정 순간에 더 중요한 정보에 집중하는 방식을 취한다
-
Encoder의 모든 Hidden State를 참고하되, 중요도에 따라 가중치를 다르게 부여하여 주의(attention)의 정도를 학습한다.
-
비동기 Seq2Seq 모델처럼 하나의 Context Vector에 모든 정보를 압축하는 방식과 달리, 중요한 정보를 동적으로 선택하여 활용할 수 있도록 한다.
-
작동원리
- 가장 기본적인
Additive기반으로 작동 원리를 살펴보자
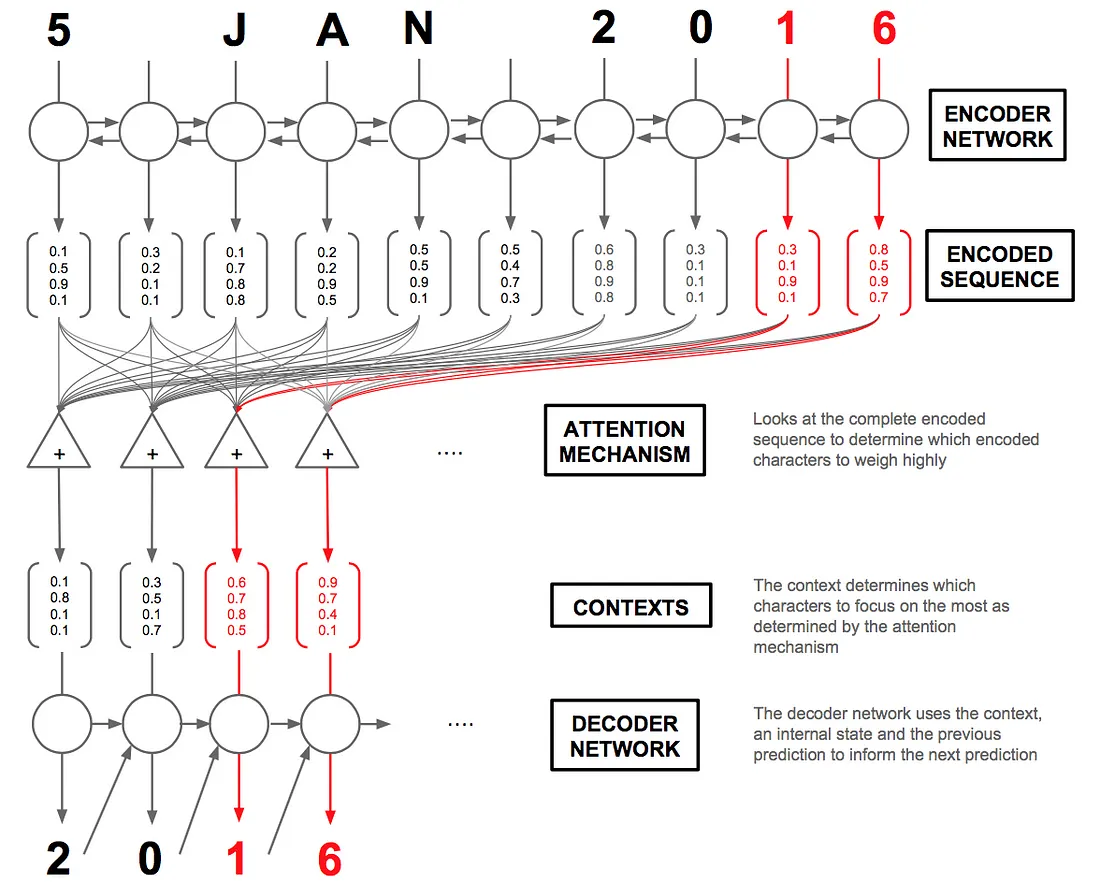
1️⃣ Encoding
- Encoder 단계에서는 Attention이 적용되지 않고, 기존 비동기적 Seq2Seq 모델과 동일하게 동작한다. 즉, 입력 시퀀스를 처리하며 각 시점의 Hidden State를 업데이트하는 과정까지만 수행된다.
2️⃣ Attention Score 계산
- : Encoder의 시점 에서 Hidden State
- : Decoder의 시점 에서 Hidden State
-
Decoder의 시점(timestep)에 따라 어떤 가 중요한지가 달라지므로, 각 가 에게 얼마나 중요한지를 표현할 가중치(Attention Score)를 계산해야 한다.
-
Attention Score를 구하는 기본 유사도 함수(Alignment Score Function)는 다음과 같다
방식 함수 설명 Additive두 벡터를 가중합하여 비선형 변환 후 점수를 계산 Dot Product와 의 내적을 계산
3️⃣ Attention Weight 계산
-
Attention Score를 확률적으로 변환(Softmax)하여, 입력의 어느 부분에 집중할지를 결정하는 가중치(Attention Weight)를 만든다.
4️⃣ Context Vector 생성
-
각 입력 Hidden State 에 가중치 를 곱한 후 가중합하여 Context Vector()를 생성한다.
5️⃣ Decoder 예측
-
Decoder는 Context Vector와 자신의 이전 상태를 이용하여 다음 출력을 생성한다.
-
새로운 Decoder 상태 :
-
출력 값 :
-
Attention Mechanism의 역전파 흐름
| 과정 | 수식 | 설명 |
|---|---|---|
| Decoder의 역전파 | Loss가 Context Vector를 통해 Encoder로 역전파 | |
| Context Vector의 역전파 | Context Vector가 Encoder Hidden State로 분배 | |
| Attention Weight의 역전파 | Softmax 역전파를 통해 Attention Weight가 학습됨 | |
| Attention Score의 역전파 | 가 업데이트되며 최적화됨 |
Attention을 적용한 역전파 경로 변화
✅ 기존 Seq2Seq 모델의 역전파 경로
-
Forward Pass:
-
Backward Pass (역전파 경로 길이):
-
문제점:
- Decoder의 마지막 Hidden State에서만 Encoder로 역전파되므로 경로가 길어지고, GV 문제가 심화됨.
✅ Attention 적용
-
Forward Pass:
-
Backward Pass (역전파 경로 길이):
-
변화점:
-
각 Decoder 시점()에서 개의 Attention Weight가 한 번에 업데이트됨.
-
기울기가 Encoder의 모든 Hidden State로 직접 전파되어 GV 문제가 완화됨.
-
Flow of Tensor in Attention
- Bahdanau Attention 구현 코드를 기반으로 tensor의 흐름을 알아보자
| 변수명 | 설명 |
|---|---|
batch_size | 배치 크기 |
input_seq | 입력 시퀀스 길이 |
output_seq | 출력 시퀀스 길이 |
enc_units | 인코더 유닛 개수 |
dec_units | 디코더 유닛 개수 |
att_units | Attention Layer 유닛 개수 |
embedding_dim | 임베딩 차원 |
✅ Encoder
-
반환값 :
-
: 모든 timestep의 Encoder hidden state
(batch_size, input_seq, enc_units) -
: 마지막 timestep의 Encoder hidden state
(batch_size, enc_units)- 해당 반환값은 Decoder의 첫 hidden state로 사용
-
✅ Attention
-
입력값 :
-
: 특정 timestep의 Decoder hidden state ()
(batch_size, dec_units) -
: Encoder 반환값
(batch_size, input_seq, enc_units)
-
-
확장 :
(batch_size, 1, dec_units)hidden_with_time_axis = tf.expand_dims(query, 1) -
Attention Score 계산
-
:
(batch_size, input_seq, att_units)로 broadcasting -
: 차원 변화 없음
-
:
(batch_size, input_seq, 1)
가중치 차원 (enc_units, att_units)(dec_units, att_units)(att_units, 1) -
-
Attention Weight 계산
- : 차원 변화 없음
(batch_size, input_seq, 1)
- : 차원 변화 없음
-
반환값 :
-
: context vector
(batch_size, enc_units)-
:
(batch_size, input_seq, enc_units)로 broadcasting -
reduce sum :
(batch_size, enc_units)
context_vector = tf.reduce_sum(context_vector, axis=1) -
-
✅ Decoder
-
: 정답 단어 임베딩
(batch_size, embedding_dim) -
Context Vector와 Embedding 벡터를 결합
(batch_size, embedding_dim + enc_units)x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1) -
GRU의 특정 시점()의 입력으로 전달
- GRU 출력 :
(batch_size, 1, dec_units) - 새로운 Hidden State () :
(batch_size, dec_units)
- GRU 출력 :
✅ Dense Layer
-
Dense Layer에 입력할 수 있도록 변환 :
(batch_size, 1, dec_units)→(batch_size, dec_units)output = tf.reshape(gru_output, (-1, gru_output.shape[2])) # (batch_size, dec_units) -
최종 단어 예측 :
(batch_size, vocab_size)
