혼합 분포 (Mixture Distribution)
- 복잡한 데이터는 우리가 알고 있는 하나의 분포 모양으로 설명할 수 없다
-
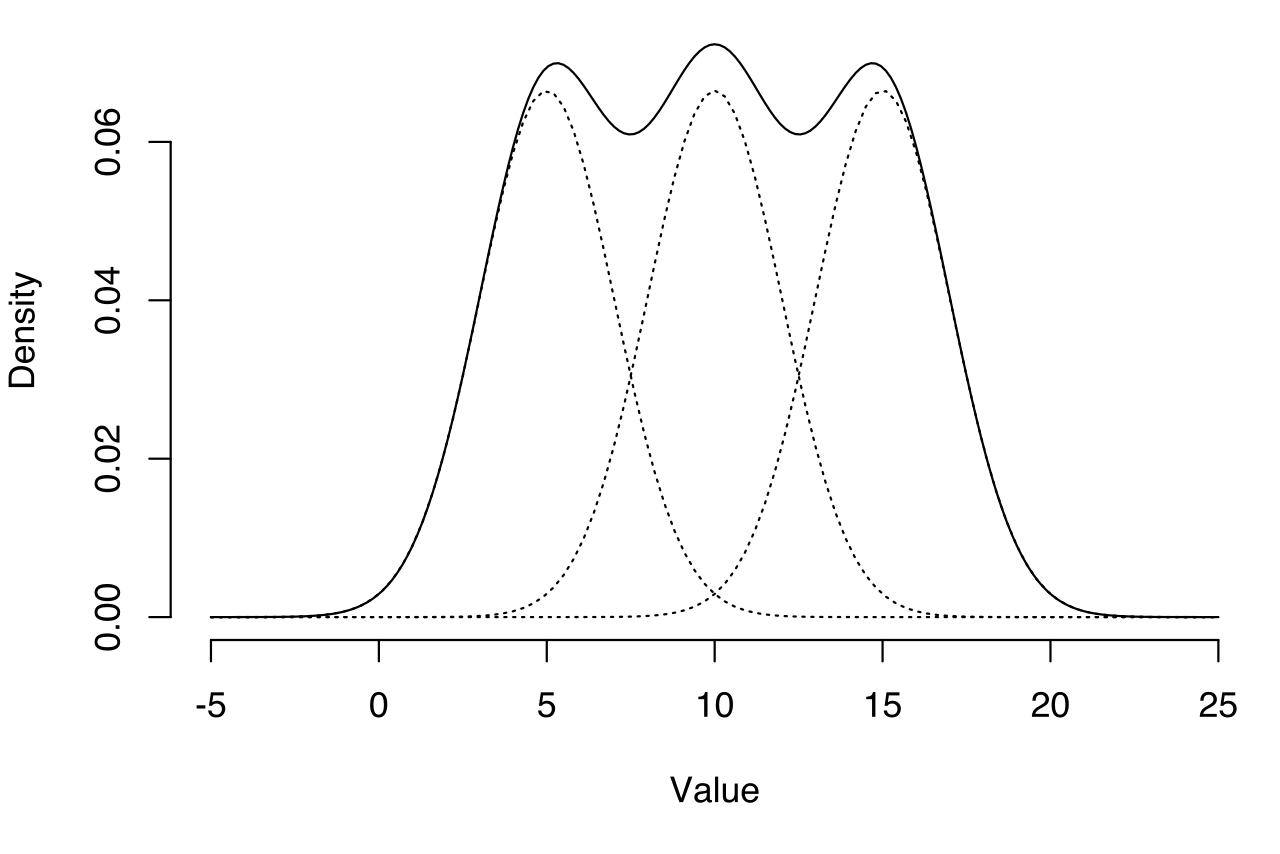
데이터는 단일한 분포 하나로는 설명되지 않는 경우가 많다. 예를 들어, 사람들의 키 분포에서 남성과 여성 집단이 섞여 있다면 전체 분포는 두 개의 정규분포가 합쳐진 모양을 보일 것이다.
-
이처럼 하나의 모집단이 여러 하위 집단(subpopulation)으로 이루어져 있고, 각 집단이 특정 분포를 따른다고 가정할 때, 우리는 이를 혼합 분포라고 부른다.
- 전통 통계학 관점에서 혼합 분포도 결국 “동일한 모집단에서 추출된 표본"이다. 따라서 하위 집단들은 모두 같은 분포를 따른다고 가정한다.
-
- : 하위 분포(성분, component)의 개수
- : 각 분포가 차지하는 비율(혼합계수, )
- : 각 분포족(distribution family)에 따른 확률 밀도 함수(정규, 포아송, ...)
혼합 분포 추정 : 최대 우도 추정 (Maximum Likelihood Estimation, MLE)
- 분포의 추정은 기본적으로 를 포함한다. 혼합 모델의 경우 혼합계수()가 추가된다.
-
혼합 분포에서 단일 데이터 포인트 가 관측될 확률(우도) :
- 가 어느 성분에서 나온 관측값인지 모르기 때문에, 모든 성분의 우도를 사전확률()로 가중합한 것이 혼합 분포에서 의 우도가 된다.
-
각 데이터는 모든 분포에 동시에 속할 확률을 가지므로, 전체 데이터의 우도는:
계산 편의성을 위해 로그를 씌우면(로그 우도):
-
이제 로그 우도를 최대화하는 파라미터()를 찾아내면 성분과 혼합 분포를 추정할 수 있을 것이다!
단일 분포 MLE에서 사용한 방식대로, 로그 우도를 미분하여 0이 되는 파라미터를 찾아보자:
뭔가 이상하다. 기대한 결과는 (단일 정규 분포의 평균 추정식)처럼 파라미터들이 선형 분리되어 서로 얽혀있지 않은 형태이다 한다.
-
혼합 분포의 MLE에서는 구조로 인해 특정 파라미터의 최적해에 다른 파라미터가 섞여 들어온다. 즉, 독립적으로 고립시킨 해석적 공식(닫힌 해, closed-form solution)을 구할 수 없다.
-
혼합분포에서도 최적해는 분명히 존재한다.
다만, MLE를 통해 한번에 최적해를 계산할 수 없음을 의미한다.
혼합 분포 추정 : EM(Expectation Maximization) 알고리즘
- 한번에 파라미터를 계산할 수 없으므로, 반복적 최적화 알고리즘을 통해 최적해를 구하자
-
닫힌 해 문제가 발생하는 이유는 구조가 등장하기 때문이다. 이는 "각 데이터의 성분 가 관측되지 않아, 모든 성분의 우도를 혼합계수로 가중합해야 하기 때문"에 등장한다.
-
그렇다면 우리가 가 어떤 성분에서 왔는지 알고 있다고 가정해보자. 그렇다면 혼합 분포의 추정은 개의 성분에 대한 개별 MLE 문제로 전환할 수 있다.
- 초기 파라미터 설정
-
추정해야 하는 파라미터의 초기값을 부여한다
- EM은 local optimum에 수렴할 수 있으므로, 초기값 설정이 매우 중요하다
- E-step
- 주어진 데이터에서 가장 근접한 확률분포모델은 무엇인가?
-
특정 성분()에 데이터 포인트 가 포함될 확률 :
- 이는 베이즈 정리로 해석할 수 있으며, 가 성분 에서 생성되었을 사후 확률(Posterior)이다
-
잠재변수(latent variable) 를 확률적으로 추정하는 과정이다
- M-step
- 오차가 최소가 되는 확률분포모델은 무엇인가?
-
정규분포 가정시:
-
이는 "책임도로 가중된 데이터"에 대해 단일 분포 MLE를 수행하는 것과 같다 (파라미터 업데이트)
- Iteration
-
E-M 단계를 반복하면서 책임도와 파라미터를 갱신하고, 로그우도를 계산한다
-
로그우도는 단조 증가하며, 증가량이 일정 기준 이하가 되면 수렴했다고 판단하고 종료한다.
혼합 모델 (Mixture Model)
- 혼합 분포는 여러 하위 분포가 결합된 전체 분포를 설명하는 개념으로, 주로 전체 모집단의 파라미터를 추정하는 데 초점이 있다
- 혼합 모델은 이 정의를 데이터 분석에 적용한 것으로, 주어진 전체 집단으로부터 하위 집단의 특징을 추론하여 각 데이터의 소속(군집)을 확률적으로 추정하는 데 초점이 있다
- 대표적인 군집화 방식(k-means, DBSCAN, 계층적 군집화)은 데이터의 구조(거리/밀도) 기반으로 군집을 형성하며, 분포를 가정하지 않는 비모수적(Non-parametric) 접근법이다.
- 반면, 혼합 모델(Mixture Model)은 데이터가 특정 분포의 혼합으로 생성되었다고 가정하고, 파라미터를 추정하여 군집을 형성하는 모수적(Parametric) 접근법이다.
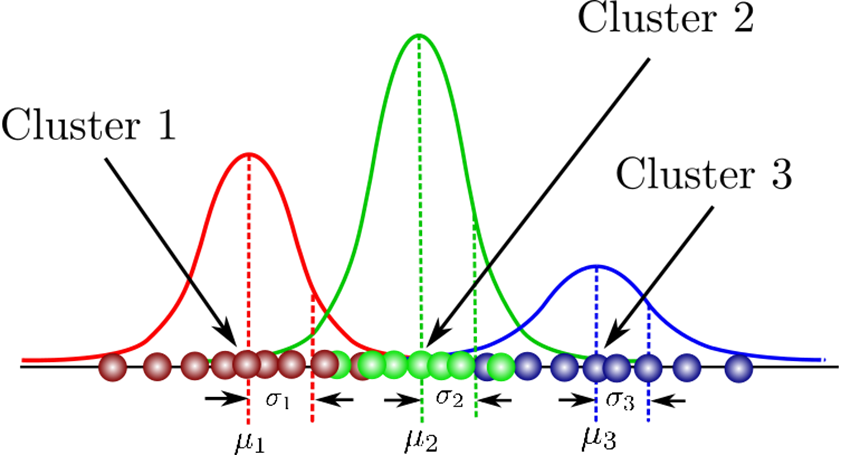
GMM(Gaussian Mixture Model)
- 가장 보편적으로 사용하는 정규 분포 기반 혼합 모델
-
GMM 역시 혼합 분포 추정에서 사용했던 EM 알고리즘 절차(E-step, M-step)를 그대로 따른다.
-
이때, 책임도는 "가 (==cluster)에 속할 확률"을 의미한다. 따라서, 로그 우도 수렴시 책임도가 가장 큰 를 의 소속으로 결정한다.
-
이때, 각 데이터는 여러 군집에 속할 수 있는 확률이 있다. 따라서 GMM은 확률 기반 클러스터링, 즉 Soft Clustering에 해당한다. ↔ Hard Clustering (각 데이터가 하나의 클러스터에만 소속)
최적 K 개수
- 최적의 를 모른다면 EM 알고리즘으로 파라미터를 아무리 잘 추정해도 의미가 없다.
그렇다면, 최적 는 어떻게 찾아낼 수 있을까?
-
전체 로그 우도는 에 따라 단조 증가한다. 극단적으로 인 경우(데이터 포인트마다 성분을 하나씩 배정) 로그우도가 무한대로 발산할 수 있다.
- 이는 복잡도 증가에 따라 데이터에 과도하게 적합하는 overfitting 현상이다
-
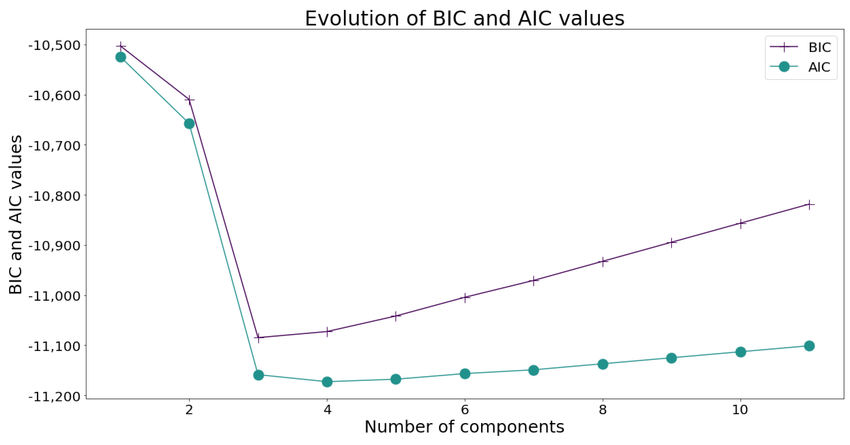
따라서 "복잡도를 고려한 적합도" 지표인 AIC/BIC를 사용한다:
: 파라미터 개수()로 패널티
: 파라미터 & 데이터 개수로 패널티 -
로그우도는 단조 증가하지만, AIC/BIC는 패널티가 함께 작용하기 때문에 어느 지점 이후 다시 증가한다.
- 따라서 AIC/BIC가 최솟값을 갖는 지점이 최적의 로 선택된다.
- 이는 k-means에서 elbow method로 “더 늘려도 개선이 크지 않은 지점”을 찾는 것과 유사하다.
+) 로그 우도는 inertia 그래프와 같이 Elbow Method를 적용해 최적 K를 구할 수도 있지만, 명확성이 떨어질 수 있다