MTL
- 같이 학습하는 과제들에 대한 시너지를 기대
-
둘 이상의 과제를 동시에 학습하여 일반화 성능을 증진하는 머신러닝 기법
-
비유 :
관점 1) 사람의 학습을 모방. 새롭게 배우는 task A에 대해,
- 이미 알고 있는 유사한 task A'의 지식을 통해 학습 난이도를 완화
- 단계를 나눠 task A1, A2, A3를 배우기
어떤 Task들을 Multi-Task로 묶어서 사용하면 좋을까?
-
가장 중요한 포인트는 Shared Representation에서의 변화에 대해 여러 task에 일관된 효과를 가져오느냐
- task 1의 역전파로 인한 Shared Encoder에서의 파라미터 변화가 task 2에서 Loss를 감소 → positive transfer
- 반대로, 서로를 상쇄하거나 방해하면, negative transfer
기본 구조
- 일반적으로 아래와 같은 시각화로 표현한다
- Hybrid 형태도 가능한 만큼, 구조를 이분법적으로 나누기보다는, 특정 횡단면(layer)에서 공유되는 parameter 집합이 단일한가, 아니면 분리되어 있는가를 기준으로 해석하는 것이 더 바람직하다.
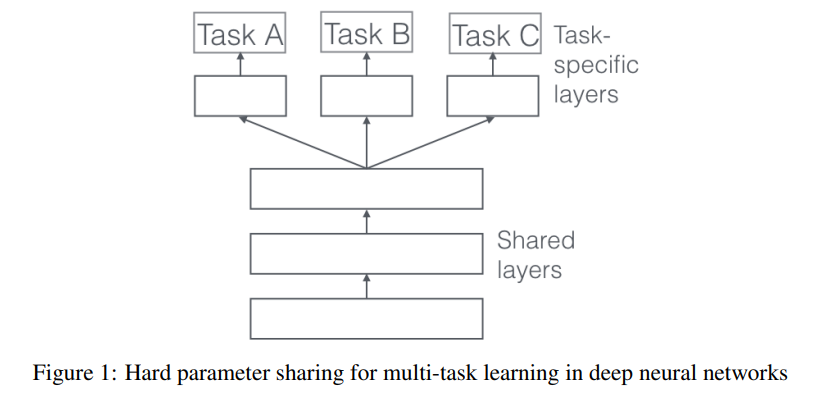
Hard Parameter Sharing
- 가장 일반적인 MTL 방식으로, 모든 Task에 대해 공통의 hidden layer representation을 거친 후 task-specific output layer로 전달된다
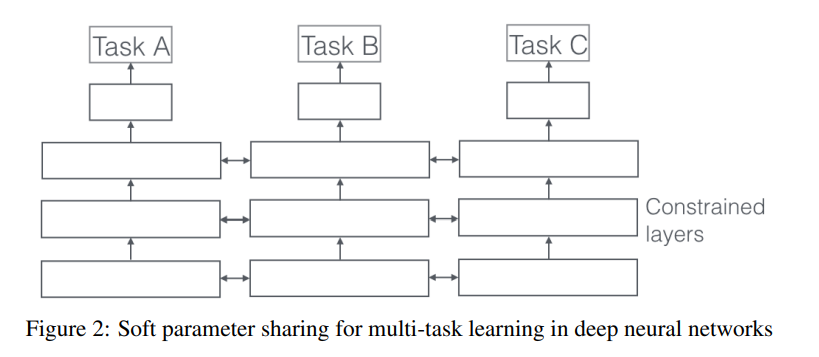
Soft Parameter Sharing
- task별로 각자의 모델과 파라미터를 가지며, 파라미터끼리 비슷한 값을 갖도록 정규화를 진행해야 한다.
Why MTL?
- MTL은 사실상 정규화 기법으로 작용하며, 일반화 성능을 올리는 데 큰 의미가 있다
| 항목 | 대상 | 설명 |
|---|---|---|
| Implicit Data Augmentation | 노이즈 패턴 | 다양한 task의 서로 다른 노이즈 패턴을 평균화하여 robust한 표현을 학습 |
| Representation Bias | shared parameters | 공통적으로 유용한 representation을 선호하게끔 학습 |
| Attention Focusing | feature | 고차원 feature space에서의 불필요한 feature 억제 |
| Eavesdropping | feature | B를 통해 A가 feature G를 ‘몰래 듣고’(eavesdrop) 학습 |
한계점과 해결책
| 기법 | 초점 | 해결 대상 | 조정 대상 | 특징 |
|---|---|---|---|---|
| GradNorm | gradient 크기 | dominance (과도한 task 집중) | task별 loss weight | 균형 있는 학습 속도 유지 |
| PCGrad | gradient 방향 | task 간 conflict | gradient 자체 | 충돌 제거로 안정적 업데이트 |
| Uncertainty Weighting | 예측의 불확실성 | noisy / ambiguous task | loss 가중치 (σ) | 자동 학습 기반 loss 조절 |
| Task Affinity | task 간 기울기 유사도 | negative transfer 방지 | task 선택 / 구조 설계 | 사전/동적 구조 판단 기준 |
참고

개인 공부용 블로그입니다