1070. Product Sales Analysis III
- 제출 쿼리 (1145ms)
WITH firstCTE as (
SELECT product_id, MIN(year) as first_year
FROM Sales
GROUP BY product_id
)
SELECT fC.product_id, fc.first_year, S.quantity, S.price
FROM firstCTE as fC
INNER JOIN Sales S ON fC.product_id = S.product_id
AND fC.first_year = S.year- EXPLAIN 결과
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | S | null | ALL | null | null | null | null | 3 | 100 | Using where |
| 1 | PRIMARY | null | ref | <auto_key0> | <auto_key0> | 10 | test.S.product_id,test.S.year | 2 | 100 | Using index | |
| 2 | DERIVED | Sales | null | ALL | null | null | null | null | 3 | 100 | Using temporary |
- 상위 성능 쿼리 (813ms)
select product_id, year as first_year, quantity, price
from
(
select *, RANK() OVER(Partition by product_id order by year asc) as rn
from sales) A
where rn = 1- 서브 쿼리 분석
- RANK() OVER : 윈도우 함수를 사용하여 각 행에 대해 순위를 계산한다
- PARTITION BY product_id : 각 product_id를 기준으로 행을 그룹화 한다
- ORDER BY year ASC : 각 그룹 내에서 year를 기준으로 오름차순으로 정렬한다
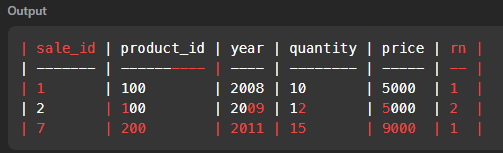
- 서브 쿼리만 실행 시 결과는 아래와 같다
-
서브쿼리에서 만들어낸 rn을 기준으로 제품마다 first year에 해당하는 행을 찾을 수 있다
-
EXLPAIN 결과
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | PRIMARY | null | ref | <auto_key0> | <auto_key0> | 8 | const | 1 | 100 | null | |
| 2 | DERIVED | sales | null | ALL | null | null | null | null | 3 | 100 | Using filesort |
PARTITION BY col
-
기준 컬럼을 사용하여 데이터셋을 그룹화하고, 각 그룹(파티션) 내에서 독립적으로 작업(윈도우 함수)을 수행할 수 있게 하는 절
-
파티셔닝 된 각 행은 원래 행과 함께 반환된다
-
GROUP BY와의 차이점
- GROUP BY의 경우 데이터셋을 그룹화 한 후 각 그룹에 대해 집계 함수를 적용한다
- 그룹화 된 결과는 하나의 행으로 반환된다
윈도우 함수
-
RANKING
- RANK() : 동일한 순위가 있을 경우 다음 순위를 건너뛰어 랭킹을 부여
- DENSE_RANK() : 동일한 순위가 있어도 다음 순위를 건너뛰지 않고 랭킹을 부여
- ROW_NUMBER() : 각 행에 대해 고유한 순위를 부여
-
AGGREGATE
- SUM() : 각 파티션의 합계를 계산한다
- AVG() : 각 파티션의 평균을 계산한다
- MIN() : 각 파티션의 최소값을 반환한다
- MAX() : 각 파티션의 최대값을 반환한다
- COUNT() : 각 파티션의 행 수를 반환한다
-
OFFSET
- LAG() : 현재 행에서 지정된 오프셋 이전의 행 값을 반환한다
- LEAD() : 현재 행에서 지정된 오프셋 이후의 행 값을 반환한다

개인 공부용 블로그입니다