깊은 네트워크와 ResNet
성능 저하 문제 (Degradation Problem)
- 불필요한 학습은 개선이 아니라 퇴보다
-
일반적으로 딥러닝 네트워크는 더 깊어질수록 표현력이 증가하여 성능이 좋아질 것으로 기대된다.
-
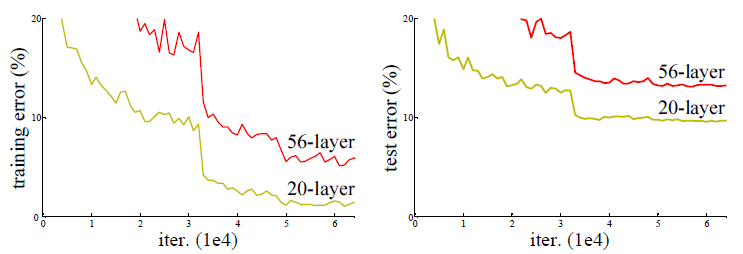
그러나 네트워크가 너무 깊어지면 훈련 오차(training error)조차 증가하는 현상이 발생한다.
→ 예: 56-layer 모델이 20-layer 모델보다 더 높은 오차를 가지는 실험 결과
📍 직관적인 원인 A) Identity Mapping의 학습 어려움
-
경우에 따라, 어떤 레이어는 입력을 그대로 출력하는 것이 최선일 수 있음 (Identity Mapping, )
-
기존 딥러닝 구조에서는 이조차도 Weight와 Bias를 잘 조정해서 "우연히" 학습해야 했고,
이 과정은 최적화하기 매우 어렵고 비효율적이다.
The degradation problem suggests that the solvers might have difficulties in approximating
identity mappings by multiple nonlinear layers.
With the residual learning reformulation, if identity mappings are optimal,
the solvers may simply drive the weights of the multiple nonlinear layers
toward zero to approach identity mappings.
- From 3.1. Residual Learning📍 직관적인 원인 B) 정보 전달 문제
-
LSTM에서 등장하는 장기 의존성 문제(Long-Term Dependency Problem)과 유사함.
-
순전파 단계에서 입력(앞쪽)의 정보가 깊은 네트워크를 따라 고차원적으로 변형되면서 왜곡·희석
→ 출력(말단)까지 중요한 정보가 전달되지 않음
✅ ResNet의 해결책: 필요 없는 학습은 생략할 수 있는 구조
-
ResNet은 아래와 같은 Residual Block 구조를 통해 문제를 해결함:
-
이 되면, 블록 전체는 자동으로 Identity Mapping이 됨.
-
즉, 네트워크가 필요 없는 변환을 학습하지 않아도 되며, 학습이 필요한 경우에만 작동하게 됨.
🎯 그 결과…
-
깊은 네트워크가 얕은 네트워크보다 더 나빠질 이유가 사라짐 → 성능 하한선 보장
-
필요한 블록만 학습하도록 하여, 효율적인 최적화가 가능
-
중요한 정보는 그대로 우회 경로(shortcut)를 통해 손실 없이 전달 가능
ResNet 구조
- ResNet은 CNN의 기본 구조를 기반으로 한다
- 작성한 내용은 입력과 출력의 차원이 같은 경우를 가정한다
Residual Block (기본 단위)
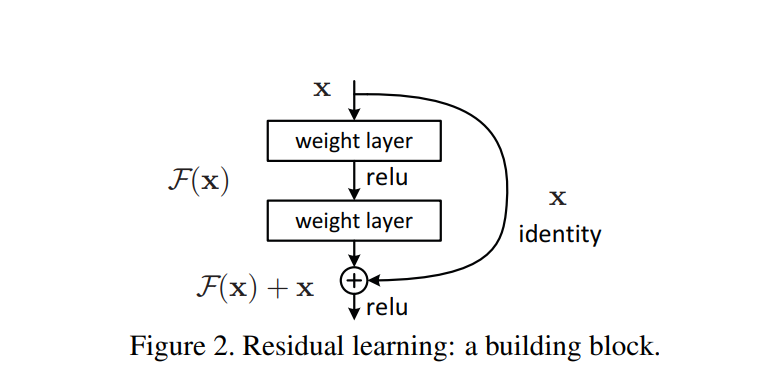
-
-
: 블록의 입력 (identity mapping, skip connection)
-
: 최소 2개의 weight layer를 포함한 변환함수
- Residual Block이 단순한 구조로 되지 않기 위해 의 비선형성과 가중치 연산을 보장
-
: 블록의 최종 출력
-
-
ResNet은 단순히 이러한 Residual Block을 쌓은 네트워크 구조를 의미한다.
Residual Block의 효과 : Residual Learning
- 깊이 𝑛인 DNN에서 Residual Block을 사용할 경우 어떤 구조 변화가 생기는지 살펴보자
- 단순화를 위해, 각 CNN 레이어의 입력–출력 관계를 다음과 같이 정의한다:
- Residual Block은 2개의 CNN 레이어로 구성된 단위 블록이라고 가정하고,
전체 네트워크는 개의 Residual Block으로 구성된다고 가정한다.
✅ 일반 CNN 구조
-
출력은 다음과 같은 중첩된 복합함수로 표현된다:
-
이 경우, 모델은 복잡한 전체 함수를 직접 학습해야 하며,
역전파 시 chain rule로 인해 gradient가 약화될 수 있음
✅ Residual Block 구조
-
각 Residual Block은 다음과 같은 구조로 정의된다:
이 구조를 순차적으로 전개하면:
출력을 귀납적으로 정리하면:
-
Residual 구조에서는 출력이 다음과 같이 표현되므로:
-
학습 대상이 전체 함수가 아니라, 입력과 출력의 차이인 잔차(=residual learning)
- 즉, Residual Block 단위의 입/출력간 변화량이 학습 대상이며,
“잔차”는 정답과의 차이가 아닌 "입력을 기준으로 모델이 학습해야 할 추가 변화량"을 의미한다.
- 즉, Residual Block 단위의 입/출력간 변화량이 학습 대상이며,
-
ResNet 역전파 경로
✅ Residual Block 내부
-
각 Residual Block 내부는 일반적으로 2~3개의 Conv layer로 구성
-
이 안에서는 일반적인 CNN처럼 chain rule을 통한 역전파가 적용됨
✔️ 얕고 구조가 단순하므로 Residual Block 내부에서는 GV 문제가 거의 발생하지 않음
✅ Residual Block 간의 연결
-
전체 네트워크는 𝑘개의 Residual Block으로 구성됨
(예: ResNet-50이면 block 16개 → 𝑘 = 16) -
Block 간에는 skip connection이 존재하며, 역전파 시 gradient가 로 전달됨
- 즉, 가장 긴 경로는 전체 residual chain의 길이 (=𝑘)
⚠️ Residual Block 간의 연결은 GV문제에 취약할 수 있다
- 즉, 가장 긴 경로는 전체 residual chain의 길이 (=𝑘)
-
하지만, Residual Block 간에는 항상 skip connection이 존재하므로,
이 되어도 gradient는 항상 skip connection()을 통해 전달될 경로를 확보✔️ ResNet은 구조적으로 GV 문제를 방지함
⚠️ 그러나 흐르는 gradient가 학습에 적절한 크기와 분포로 유지되는지는 별개의 문제
→ Batch Normalization을 적용해야 함
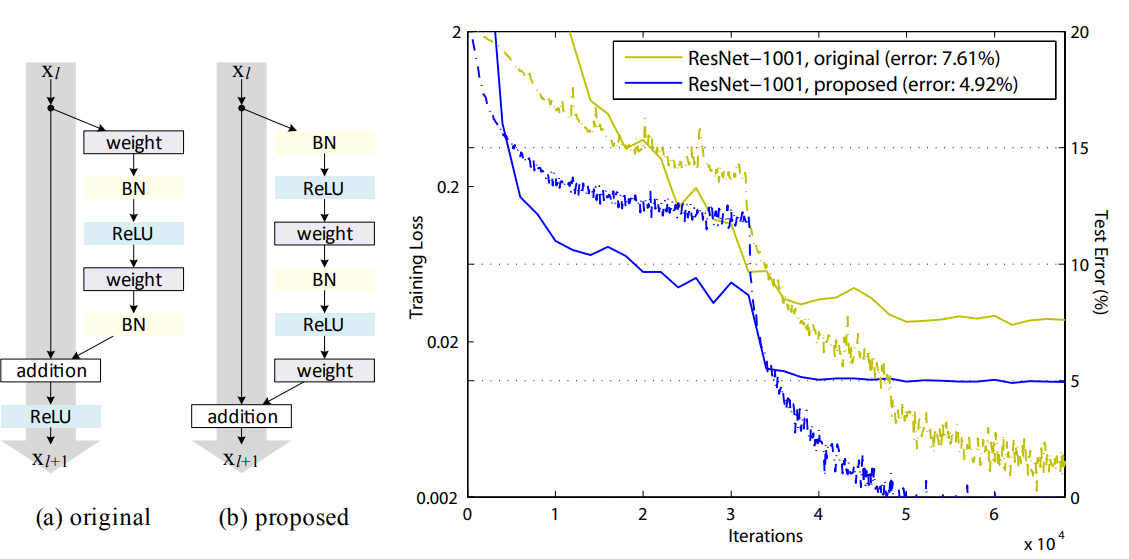
Pre-activation
- Task 1 : 실질적인 Identity Mapping 구조를 구현
- Task 2 : 학습 안정성 보장
-
Deep Residual Learning for Image Recognition의
(a) original구조는 Residual Block 출력 전체에 ReLU가 적용되어, shortcut에 비선형 왜곡이 생겨 실질적인 identity mapping이 보장되지 않았다 -
후속 논문인 Identity Mappings in Deep Residual Networks을 살펴보면 정보전달 및 최적화 관점에서 Identity Mapping의 중요성과 함께 이를 제대로 구현하기 위한 구조에 대한 실험 내용이 있다 :
... the shortcut connections are the most direct paths for the information to propagate.
Multiplicative manipulations (scaling, gating, 1×1 convolutions, and dropout) on the shortcuts
can hamper information propagation and lead to optimization problems...
- 3.2 Discussions
Experiments in the above section support the analysis in Eqn.(5) and Eqn.(8), both being
derived under the assumption that the after-addition activation f is the identity mapping.
But in the above experiments f is ReLU as designed in [1],
so Eqn.(5) and (8) are approximate in the above experiments.
Next we investigate the impact of f.
We want to make f an identity mapping, which is done by re-arranging the activation functions...
- 4 On the Usage of Activation Functions4.1 Experiments on Activation의 실험 결과를 요약하여 확인하면 다음과 같다 :
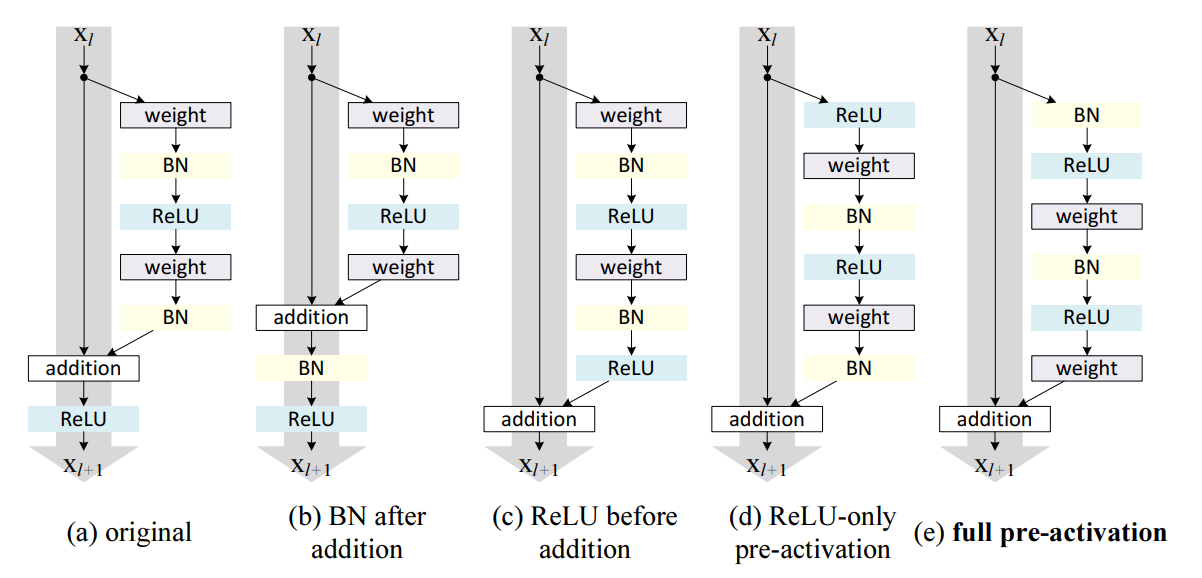
| 항목 | CIFAR-10 오류율, ResNet-164 | 주요 문제점 / 해석 |
|---|---|---|
(a) original | 5.93% | 기존 구조. ReLU가 전체 출력에 적용되어 identity mapping 손상 |
(b) BN after addition | 6.50% | BN이 skip path까지 왜곡시켜 정보 흐름 방해 → 학습 초기에 loss 감소 어려움 |
(c) ReLU before addition | 6.14% | 출력이 non-negative → residual이 단조 증가 → 표현력 저하 (성능 감소) |
(d) ReLU-only pre-activation | 5.91% | BN이 ReLU와 결합(conjunction)되지 않아 정규화 효과 제한적 → BN 효과가 약해져 성능 개선 미미 |
(e) full pre-activation | 5.46% | identity mapping 보존 + 모든 경로에 정규화 적용 → 좋은 성능 |
✅ 결론적으로, ResNet에서는 전통적인 Conv → BN → ReLU 순서(Post-activation)가 아닌,
모든 weight layer 앞에 BN과 ReLU를 적용하는 full pre-activation 구조가
identity mapping을 보존하고, 정규화 효과를 극대화하여 최적의 성능을 보인다
-
논문에서 제시한 full pre-activation 구조의 장점은 다음과 같다 :
-
Identity Mapping 구조 → Ease of optimization
-
극대화된 BN의 정규화 효과 → Reducing overfitting
-
ResNet의 이론적 타당성
- 위 논문들은 경험적인 근거를 통해 ResNet의 성능을 증명했다.
ResNet의 성능을 이론적으로 보완하는 후속 연구들에 대해 간단하게 알아보자
| 논문 | 기여 | 핵심 아이디어 |
|---|---|---|
| Li et al., 2016 "Demystifying ResNet" | 해시안(Hessian)의 안정성 분석 | 잔차 연결이 손실 함수의 곡률을 낮춰서 SGD가 빠르고 안정적으로 수렴할 수 있도록 도와줌 |
| Hardt & Ma, 2017 "Identity Matters in Deep Learning" | Identity mapping의 중요성 분석 | ResNet은 정보 손실 없이 gradient 흐름을 유지할 수 있도록 도와줌 |
| Kawaguchi et al., 2018 "Depth with Nonlinearity..." | 나쁜 지역 최소점이 없다는 이론적 증명 | ResNet은 깊어져도 최적화 landscape가 나빠지지 않음 |
| Zhang et al., 2021 "Convergence of Deep ReLU Networks" | 수렴 조건 제시 | 가중치가 항등 행렬로, 바이어스가 0으로 수렴하면 안정적인 학습 가능 |
-
ResNet을 이론적으로 보완하는 후속 연구 중 하나가 Convergence of Deep ReLU Networks이다.
-
이 논문의
5 Sufficient Conditions for Convergence of ReLU Networks에서는 깊은 ReLU 네트워크가 안정적으로 수렴하기 위한 충분 조건을 제시하며, 이는 ResNet 구조의 설계 철학과 일치함을 확인할 수 있다.-
1) 모든 레이어의 가중치가 항등 행렬로 수렴
-
2) 모든 레이어의 바이어스 벡터가 0으로 수렴
→ ResNet에서 강조하는 Identity Mapping과 동일
-
Bottleneck
- Identity Mapping 구조 덕분에 Degradation Problem 없이 네트워크의 깊이를 자유롭게 확장할 수 있게 되었다.
- 하지만, 레이어를 깊게 쌓을때 다른 문제는 ‘효율’(FLOPs)이 나오지 않는 게 문제다
Bottleneck 구조
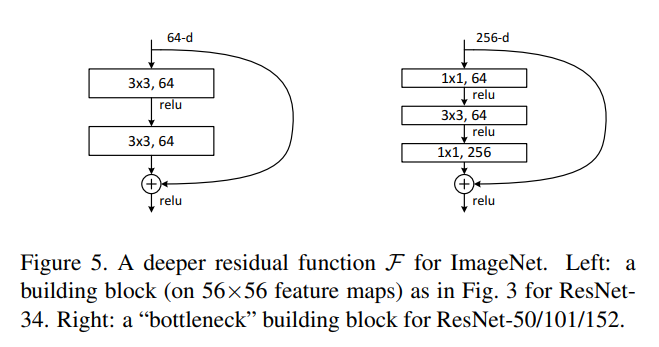
-
ResNet-50 (50-layer) 이상의 깊은 네트워크에서 기존 Residual Block을 그대로 사용할 경우
연산량이 급격히 증가하므로,
연산 효율을 높이기 위해 Residual Block을 Bottleneck 구조로 변형하였다.- 기존 Residual Block : (3 × 3) Conv → (3 × 3) Conv
- Bottleneck Block : (1 × 1) Conv → (3 × 3) Conv → (1 × 1) Conv
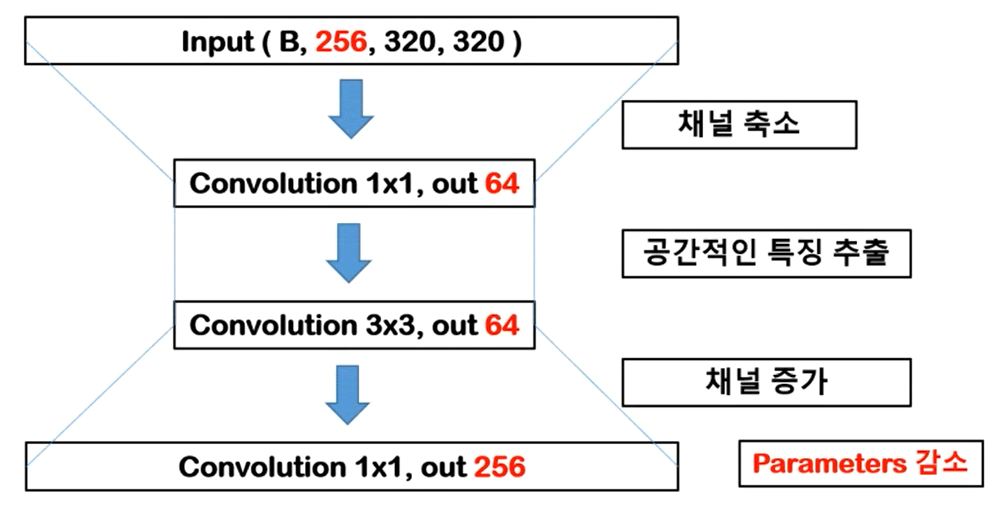
✅ 첫 (1 × 1) Conv : 학습 가능한 채널 압축기
-
고차원의 채널(feature map)들을 조합하여 선형 projection으로 압축하는 방법을 학습
-
연산량의 핵심인 (3 × 3) Conv에서 사용할 채널의 수를 줄여줌
✅ 중간 (3 × 3) Conv : 핵심 특징 추출기
-
압축된 표현에서 의미 있는 spatial pattern을 뽑아냄
-
즉, CNN의 본질적 기능을 수행하는 레이어
✅ 마지막 (1 × 1) Conv : 학습 가능한 채널 확장기
-
뽑아낸 feature들을 고차원으로 복원하면서 정보 손실을 최소화
-
skip connection에 맞추기 위한 shape alignment 및 특징 간 조합을 다시 학습
블록 당 FLOPs 비교
- 기본 Residual Block과 Bottleneck Block의 FLOPs를 비교해보자
- 입력 채널 수 = 출력 채널 수 = 64, 축소 비율 𝑟=4로 가정한다
| 항 | 설명 |
|---|---|
| 커널 높이 | |
| 커널 너비 | |
| 입력 채널(Feature Map) 수 | |
| 출력 채널(Feature Map) 수 | |
| 출력 Feature Map 높이 | |
| 출력 Feature Map 너비 |
🔹 기본 Residual Block (구성: 2 × [3×3 Conv])
🔹 Bottleneck Block (구성: 1×1 Conv → 3×3 Conv → 1×1 Conv)
✅ 90%에 가까운 연산량 감소 효과!
Pooling과의 차이점 + Bottleneck에서의 정보 손실
- CNN의 Pooling Layer 역시 연산량을 줄이기 위한 구조적 장치이다
그렇다면, Bottleneck의 (1×1) Conv는 Pooling과 어떤 차이가 있을까?
| 비교 항목 | Pooling Layer | Bottleneck 1×1 Conv |
|---|---|---|
| 목적 | 연산량 감소(공간 크기 축소) | 연산량 감소(채널 수 축소) |
| 연산 방식 | 비학습 (Max, Average) | ✅학습 가능 (가중치 존재) |
| 정보 손실 | 구조적으로 발생 | ❗ 최소화 (학습 기반 표현 압축) |
| skip connection | 크기 변화로 직접 연결 어려움 | ✅shape 유지 or 복원 가능 |
🔷 왜 Bottleneck은 '손실'이 아닌 '효율'인가? : Skip Connection
-
Bottleneck이 아무리 잘 학습돼도, 차원 축소라는 행위는 표현력을 제한할 수 있다.
-
하지만, ResNet에서는 이 정보 손실을 skip connection으로 보완할 수 있다
- Bottleneck Block에서 손실된 정보가 있더라도,
skip path가 원본을 그대로 전달해주기 때문에
정보 손실 없이 깊은 네트워크를 효율적으로 학습할 수 있다
- Bottleneck Block에서 손실된 정보가 있더라도,
-
ResNet의 Skip Connection을 통해 Bottleneck은
Cons(정보손실)보다 Pros(연산량 감소)가 큰 구조로 거듭날 수 있다
ResNet의 깊은 네트워크 문제 대응 정리
| 문제 | ResNet의 기여 | 완전한 해결? | 병행 기법 |
|---|---|---|---|
| 성능 저하 | Identity Mapping을 쉽게 학습할 수 있는 구조 | ✅ (구조적 해결) | – |
| 기울기 소실 | 잔차 연결로 기울기 흐름 경로를 구조적 보장 | ❗ (구조적 완화, 안정성 보완 필요) | ReLU, BatchNorm, He Initialization |
| 과적합 | 불필요한 블록은 학습하지 않아도 되며, BN을 효과적으로 활용하여 일반화 유리 | ❗ (파라미터 수는 여전히 많음) | Dropout, L2 정규화, Data Augmentation |
| 계산 비용 및 메모리 증가 | 깊은 구조를 효율적으로 학습하지만, 파라미터 수 자체는 많아지는 구조 | ❗ (경량화 구조 아님) | Bottleneck 구조, Layer 공유, Knowledge Distillation |
