Transformer 모델의 등장 배경
기존 Seq2Seq 모델의 한계점
❗ RNN 기반 :
RNN 레이어를 거치며 순차적 데이터를 인코더/디코더 hidden state에 쌓음
이후 인코더 + 디코더의 hidden state를 사용하여 시퀀스 출력을 생성
-
장기 의존성 문제-
시퀀스 내 전역 의존성 학습 어려움
시퀀스가 길어질수록 초반부 정보가 후반부 hidden state에서 소실되거나 변질되기 쉬움 -
고정된 크기의 Context Vector
초기에는 인코더가 입력 시퀀스의 정보를 고정된 크기의 벡터로 압축해 디코더에 전달하여, 입력/출력 시퀀스 간 장기 의존성을 잘 포착하지 못함
✅ Attention은 입력/출력 시퀀스 내 토큰 간 거리에 상관없이 의존성을 학습할 수 있는 메커니즘
-
-
연산 효율- 순차적 계산 방식
RNN은 각 시점마다 이전 시점의 계산 결과에 의존하므로, 계산이 순차적으로 진행되어야 함
→ 이로 인해 GPU와 같은 병렬 연산 장치의 효율적 사용이 어려움 (시퀀스가 길수록 치명적)
- 순차적 계산 방식
❗ CNN 기반 :
CNN(1D Conv) 레이어를 사용해 시퀀스 데이터를 병렬로 처리.
각 시점마다 컨볼루션 필터를 적용해 입력을 hidden representation으로 변환.
이후 여러 층(=시퀀스 길이)의 Conv layer를 쌓아 넓은 receptive field를 확보.
-
장기 의존성 문제- 시퀀스 내 전역 의존성 학습 어려움
Conv layer는 로컬 정보(토큰 하나)를 처리하므로, 멀리 떨어진 위치 간의 관계를 포착하려면 여러 Conv layer를 거쳐야 함
→ Gradient Vanishing 및 학습 효율 저하 가능성 증가
- 시퀀스 내 전역 의존성 학습 어려움
-
연산 효율-
연산 병렬화가 가능해 GPU 활용도가 높음
-
그러나 장기 의존성 학습을 위해 깊은 Conv Layer가 필요하고, Conv 연산 자체도 상대적으로 연산량이 큼
-
Transformer의 문제 접근법
- Attention을 변형하면 다 해결 할 수 있을 것 같은데?
-
처리해야 하는 시퀀스 길이는 점점 길어지고, GPU는 날이 갈수록 발전하고 있어.
-
그렇다면 이제는 병렬 처리가 가능한 구조의 Seq2Seq를 만드는 것이 디폴트야.
이를 위해서는 RNN의 태생적인 한계인 순차적 구조를 탈피해야해겠네? -
또, CNN기반 모델에서 배운 점은 시퀀스 내 전역 의존성을 학습할 때 레이어를 깊게 쌓는 것은 불리하다는 것이야.
-
-
그러면, 하나의 레이어에 시퀀스 전체를 입력해서 전역 의존성을 학습하는 것이 좋을 것 같아.
- RNN에서 입력/출력 시퀀스의 전역 의존성을 학습할 수 있는 매커니즘인 Attention을 변형하여, 하나의 시퀀스 내부에 적용하면 어떨까? →
Self Attention
- RNN에서 입력/출력 시퀀스의 전역 의존성을 학습할 수 있는 매커니즘인 Attention을 변형하여, 하나의 시퀀스 내부에 적용하면 어떨까? →
- 처음에도 언급했지만, 병렬 처리는 필수야.
- 시퀀스를 여러개의 Head로 나눠 병렬로 처리하고, 결과를 합쳐주면 될 것 같아.
이러면 다양한 관점에서 시퀀스 내 의존성을 학습할수도 있겠네 →Multi-Head Attention
- 시퀀스를 여러개의 Head로 나눠 병렬로 처리하고, 결과를 합쳐주면 될 것 같아.
Transformer
- All you need is Attention
- 전역 의존성을 평가할 때 시간 축을 꼭 따를 필요는 없다
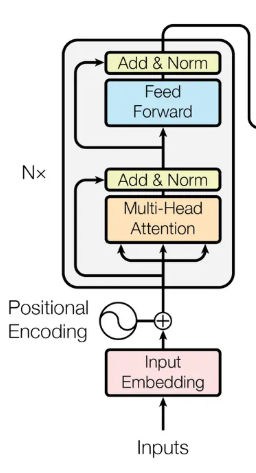
전체 구조
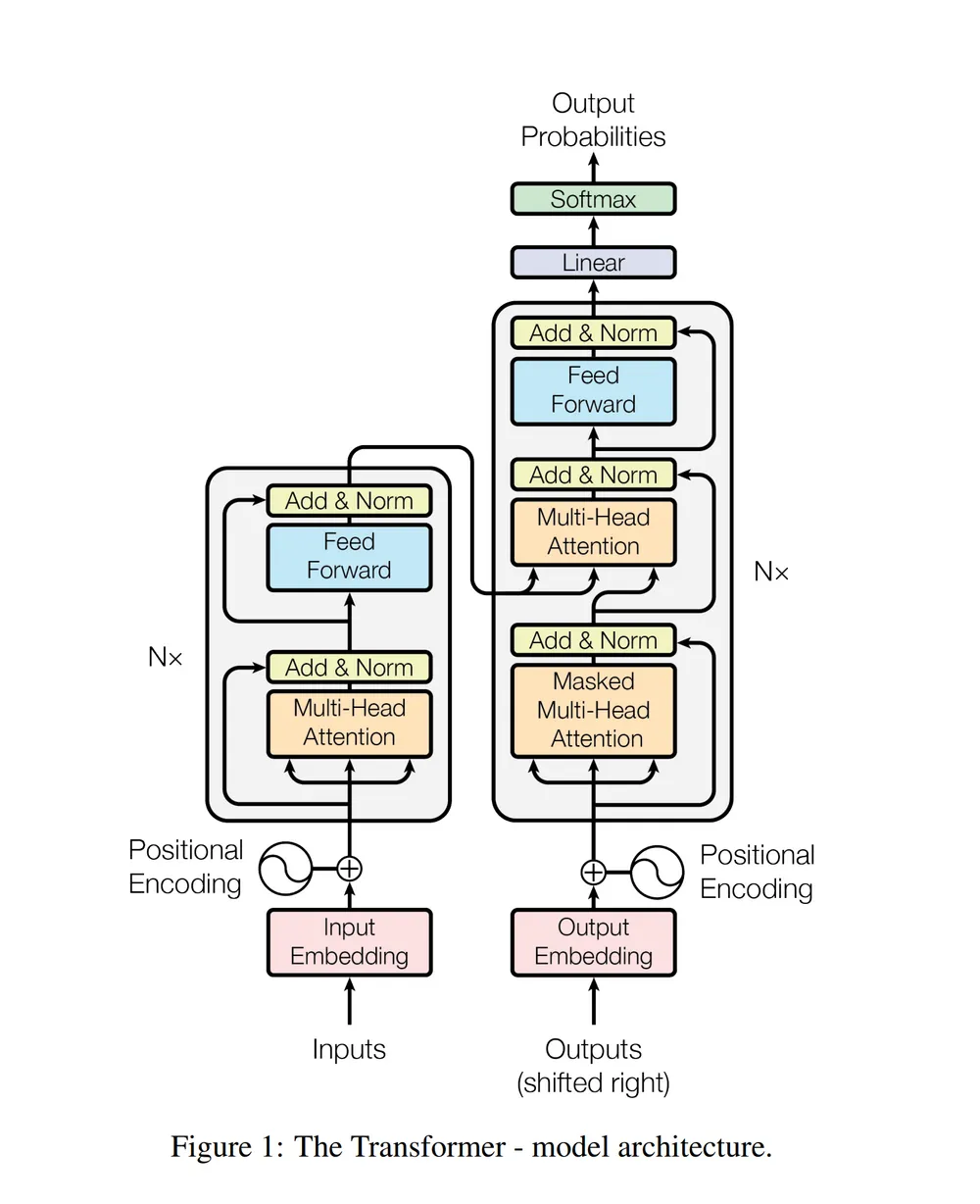
-
Encoder-Decoder 구조를 기반으로 하지만, 입력을 순차적으로 처리하지 않고 전체 토큰을 한 번에 입력
-
크게보면 Encoder Block N개, Decoder Block N개를 각각 쌓은 형태 (꼭 같을 필요는 없음)
-
Encoder는 입력 시퀀스(Inputs)의 문맥 정보를 인코딩하고,
Decoder는 입력 시퀀스(Outputs)의 인코딩 정보와 Encoder의 출력 일부를 바탕으로 출력 시퀀스를 생성
Positional Encoding
- 전체 토큰에 순서를 추가
- Transformer는 RNN과 달리 입력을 순차적으로 받지 않으므로, 토큰의 위치 정보를 다른 방식으로 반영할 필요가 있다

-
논문에서는 토큰 임베딩(embedding)에 위치 정보(Positional Encoding)를 더하는 방식을 사용한다
(sin과 cos 함수를 이용한 주기함수로, 각 위치마다 고유한 벡터를 생성)
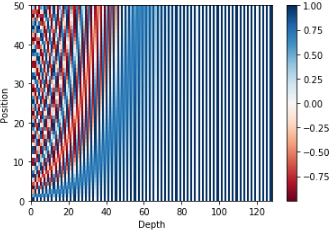
-
같은 토큰이라도 위치에 따라 Transformer 입력 임베딩 벡터 값이 달라지며,
토큰 간 상대적 위치 정보가 학습에 반영된다
Self Attention (Scaled Dot-Product Attention)
- 하나의 문장을 구성하는 모든 단어를 전역 문맥 안에서 표현하는 고급 워드 임베딩
-
RNN Seq2Seq에서 Attention은 입력과 출력 시퀀스 간 상호작용의 중요도를 평가했다.
-
Transformer에서는 Encoder/Decoder 내부에서 토큰 자신과 다른 토큰들을 모두 참조하며 학습하는 방식으로 변형되었고, 이를 Self Attention이라 부른다
Query:
현재 토큰은 어떤 의미인지 질문 RNN Decoder의 현재 시점Key:
각 토큰이 가진 고유 정보의 정체성 RNN Encoder의 모든 시점Value:
Key에 해당하는 토큰의 실제 임베딩 값
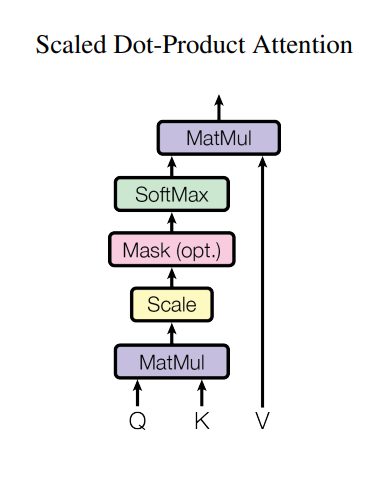
1단계: 각 토큰의 임베딩을 세 가지 역할(Query(Q), Key(K), Value(V))로 변환2단계: Query와 Key의 내적(dot product)으로 토큰 간 유사도 계산 (==Attention Score)3단계: Softmax로 유사도를 확률로 변환하고, 이를 Value에 곱해 토큰별로 가중합된 정보를 생성 (==Attention Weight)
-
Q, K, V에 독립적인 학습가중치를 사용하여 각자의 역할을 잘 수행하도록 학습
-
인풋 임베딩()을 기반으로 만드는 값이기 때문에 그 품질에 영향을 받음
-
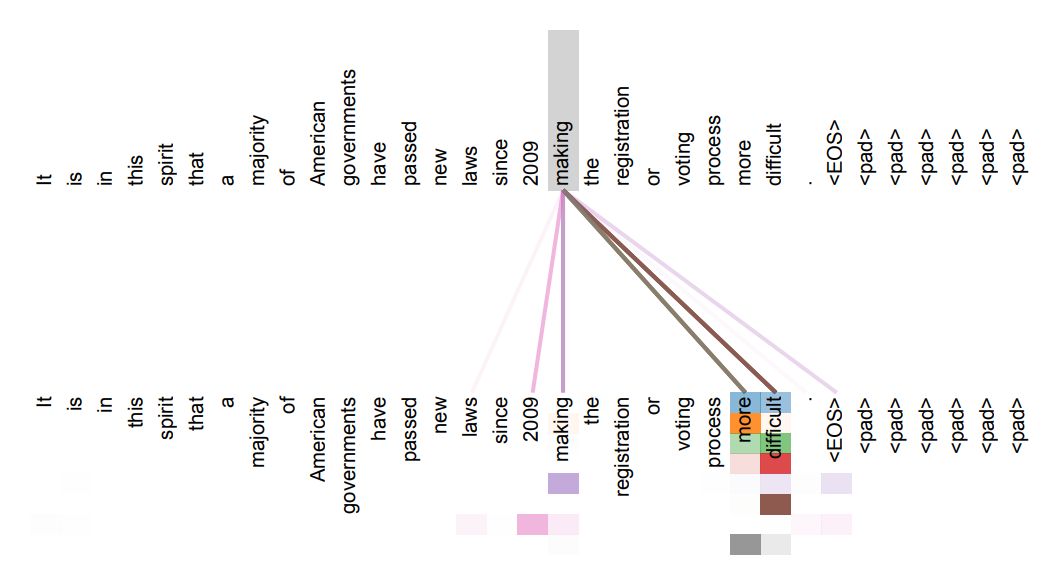
각 토큰은 입력 시퀀스의 모든 다른 토큰과 관계를 학습하므로, 멀리 떨어진 단어 간의 관계(장기 의존성)도 학습 가능
-
시퀀스 전체의 Query, Key, Value를 (Q, K, V)로 묶어 효율적인 행렬 연산 가능
+) 스케일링은 왜 하는 건가요?
- 를 계산하는 과정에서 임베딩 차원()에 따라 스케일링()을 적용하는 것은, 국소적 학습 안정성을 위해 작은 비용을 추가하는 것이다
- 에 비례하여 의 분산이 증가하며, 가 커질 가능성이 높다
To illustrate why the dot products get large, assume that the components of
q and k are independent random variables with mean 0 and variance 1.
Then their dot product has mean 0 and variance d_k.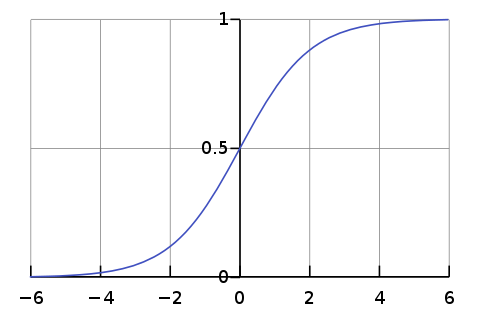
-
가 커지면, Softmax의 미분값이 0에 가까운 영역으로 이동하여 GV문제가 발생할 수 있다
- 물론, SubLayer 내부에서 gradient가 사라지더라도 Residual Connection을 통해 전역적인 Gradient Flow는 유지된다
-
하지만 Subspace 내부의 Attention Layer가 제대로 학습되지 않으면, 이 Layer의 기여도가 약해지고 Transformer의 학습 품질이 떨어질 수 있다
- 스케일링은 작은 연산 비용으로 Attention Layer의 국소적 학습 안정성을 보장하며, 모델 전체의 품질을 유지해주는 장치이다.
-
또한, Multi-Head Attention에서 "다양한 관점"을 확보할 때 스케일링의 역할에 대해 생각해 볼 수 있다.
-
하나의 head에서 특정 토큰의 Softmax 결과값이 0.9라고 가정하자. 이때 나머지 토큰들은 0.1을 나눠 가지게 된다 (스케일링을 진행하지 않으면 꽤 빈번할 수 있음)
-
이런 상황이 모든 Head에서 반복되면, Head별로 다른 subspace라도 결국 유사한 토큰 분포를 학습할 가능성이 있음
-
스케일링은 Softmax의 출력을 안정화시켜 Head별로 서로 다른 관계를 포착할 여지를 주는 역할을 함
→ Head 간 "다양성 확보"를 간접적으로 도울 수 있음
Multi-Head Attention
- 병렬 처리를 하면서 다양한 관점에서의 상호작용을 반영하자
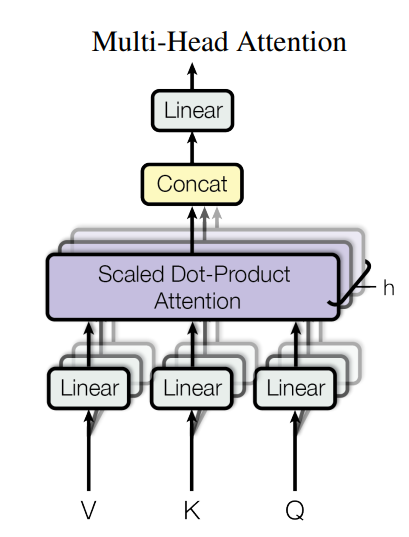
-
한 번의 Scaled Dot-Product Attention으로 전체 임베딩을 처리하지 않고 :
1단계: 전체 임베딩에서 Q, K, V의 임베딩 차원을 로 축소2단계: head 각각에 대해 다른 가중치 행렬()로 선형 변환3단계: head마다 Scaled Dot-Product Attention 연산하고 결과를 연결4단계: 학습 가능한 선형 변환 가중치()를 거쳐 최종 출력을 생성
-
특징 :
다양한 관점 학습 가능 : 여러 head(subspace)에서 관계를 탐색해 더 풍부한 표현력 확보
병렬 처리 : 각 Head를 독립적으로 연산 가능(GPU 효율적)
효율성: Head별 차원을 나눠 연산량은 단일 Head Attention과 유사하며, 메모리 친화적
Position Wise Feed-Forward Networks (FFN)
- Feature Engineering
-
FFN은 임베딩된 벡터에 비선형 변환(ReLU)와 선형 변환을 더해, 더욱 복잡한 표현 공간으로 매핑한다
-
이때, 토큰마다 동일한 네트워크 구조가 적용되지만, 토큰별 입력값(문맥)이 다르므로 출력은 다르게 변환된다
-
또한, Encoder/Decoder 블록마다 서로 다른 학습 가중치()가 적용되어 블록별 독립적 학습이 가능하다
-
Residual Connection & Layer Normalization (Add & Norm)
- 학습 안정성 확보
- Residual Connection :
Multi-Head Attention, FNN 마다 입력()과 변환된 출력()을 더한다
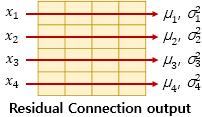
-
Layer Normalization : Residual Connection 후 토큰() 단위로 정규화
-
Batch 단위의 정규화(BN)의 경우 다른 맥락의 토큰이 섞여 통계량이 불안정해질 수 있음
-
LayerNorm은 "SubLayer 단위의 토큰"이라는 작은 표본을 사용하는 정규화.
시점마다 시퀀스의 순차적 맥락을 유지하며 안정적이고 일관된 정규화 진행 -
또한, 각 토큰마다 독립적으로 정규화를 적용하여 병렬 처리가 가능하여 병렬 연산가능
-
| 구분 | BN | LN |
|---|---|---|
| 철학 | 집단적 평균을 기준으로 전체 정규화 | 각 샘플 내부 기준으로 개별 정규화 |
| 통계학 비유 | 큰 수의 법칙, 중심극한정리 | 조건부 표본 정규화, 국소 통계 기반 해석 |
| 전제 | 충분한 batch 크기와 동질적 분포 | 각 샘플이 독립적이고, feature 간 문맥이 존재 |
| 특징 | 평균적이고 안정된 학습 | 문맥 보존에 강하며 순차 구조에 적합 |
Transformer 세부 구조
Encoder
- 전체 구성을 표로 요약하면 다음과 같다
| 단계 | 설명 |
|---|---|
Input Embedding | QKV변환 및 Self-Attention의 기반이 되는 기본 임베딩 |
Positional Encoding | Input Embedding에 위치 정보 반영 |
Multi-Head Attention | 모든 토큰을 전역 문맥 속에서 상호작용하며 표현 (다양한 관점의 Attention) |
Feed Foward | 임베딩된 벡터를 비선형 변환 및 선형 변환으로 고차원 특성 학습 |
Add & Norm | Residual Connection 및 LayerNorm을 통해 학습 안정성과 정보 흐름 유지 |
Decoder
- Decoder에서 등장하는 Mulit-Head Attention의 두 변형에 대해서 알아보자
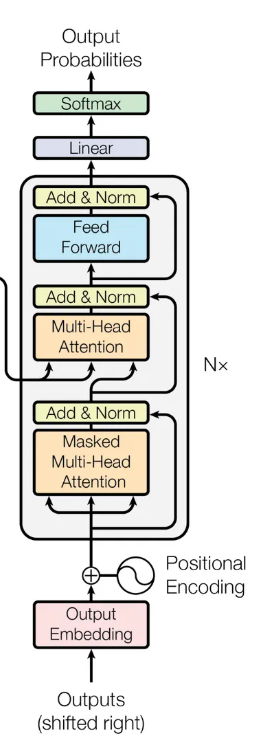
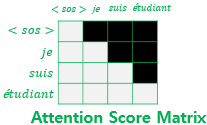
Masked Multi-Head Attention
- 미리보기 방지 적용
-
Decoder에서도 입력된 출력 시퀀스에 Multi-Head Attention을 사용해 문맥 반영 임베딩을 진행해야 함
-
하지만, Decoder의 입력은 곧 정답 시퀀스()이므로, Self-Attention을 적용하면 각 토큰이 전체 출력 시퀀스를 참조하게 됨
→ 학습 데이터에서만 높은 성능(Overfitting) 발생 -
따라서, Decoder의 Multi-Head Attention 학습 과정에서 현재 시점과 그 이전 토큰까지만 참조하도록 나머지 토큰은 보지 못하게 마스킹(Look-ahead Mask)을 적용해야 함
Encoder-Decoder Attention
- RNN Seq2Seq 모델의 Attention과 구조적/개념적으로 동일한 역할
-
마지막 Encoder Block에서 인코딩된 입력 정보와 Decoder의 출력 시퀀스를 연결하는 역할
: Decoder의 중간 결과 (출력 시퀀스의 현재 위치)
: Encoder에서 생성된 입력 시퀀스의 Contextual Embedding -
입력 시퀀스의 정보와 출력 시퀀스의 관련성을 학습하고, 특정 입력 토큰에 집중하도록 함
참고
