Machine Learning
-
아서 사무엘의 정의 : 기계가 일일이 코드로 명시하지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 하는 알고리즘을 개발하는 연구 분야
-
머신러닝의 목표는 관측된 데이터를 기반으로 현실을 가장 잘 설명할 수 있는(일반화 성능이 좋은) 함수(시스템)을 찾는 것이다.
-
우리가 볼 수 있는 데이터는 시스템에 의해 관측된 것이며, 데이터의 왜곡, 노이즈, outlier가 있을 수 있다.
동굴의 비유(Alloegory of the Cave)와 머신러닝

지하의 동굴에 살고 있는 사람들을 상상해 보자.
빛으로 향한 동굴의 좁은 통로가 입구까지 달하고 있다.
사람들은 어릴 적부터 손과 발, 목이 속박되고 있어 움직이지도 못하고,
쭉 동굴의 안쪽을 보면서,되돌아 보는 것도 할 수 없다.
입구의 아득한 위쪽에 불이 불타고 있고, 사람들을 뒤로부터 비추고 있다.
불과 사람들의 사이에 길이 있어, 길을 따라서 낮은 벽이 만들어져 있다.
…… 벽을 따라서, 여러가지 종류의 도구, 나무나 돌 등으로 만들어진 인간이나 동물의 상이 벽 위에 옮겨져 간다.
옮겨 가는 사람들 속에는 소리를 내는 것도 있으며, 입 다물고 있는 것도 있다. ……-
플라톤은 동굴의 비유를 통해 우리가 현실에 보고 있는 것은 실체(이데아)의 '그림자'에 지나지 않다고 플라톤은 주장하며, 인간은 동굴 밖의 실체(이데아)를 보아야 한다고 주장했다.
-
머신러닝에 해당 비유를 적용해 보자
- 동굴에 비치는 그림자 = 데이터
- 지하의 동굴에 살고 있는 사람들 = 데이터를 사용하여 ML 모델을 만드는 사람들
- 이데아 = 우리가 알고 싶은 현실
-
비유를 통해 생각나는 포인트를 몇개 짚어보자.
- 데이터 전처리 : 우리가 보는 그림자(데이터)는 현실과 분명히 다르다(왜곡, 노이즈, Outlier, ...)
- Underfitting : 그림자(데이터)에 대해서 제대로 학습해야 일반화 성능을 올릴 수 있다
- Overfitting : 그림자(데이터)에 너무 맞게 학습하면 일반화 성능이 떨어질 수 있다
- Model Drift : 그림자(데이터)도 시간에 따라 변화하며(-> Data Drift), 동굴 밖의 사물들의 관계도 시간에 따라 변화할 수 있다(-> Concept Drift)
머신러닝의 종류
-
지도학습 (Supervised Learning) : 정답 레이블 정보를 활용하여 알고리즘을 학습하는 방법론
- 정답이 있어 모델이 비교적 잘 학습되며, 명확한 평가 수치가 존재하여 모델의 성능을 평가 가능하다. 하지만, 정답 레이블이 필요하기 때문에 추가적인 비용이 필요하다.
- Ex) 회귀 분석, Decision Tree, Random Forest, SVM
-
준지도 학습 (Semi-Supervised Learning) : 일부의 데이터만 정답이 존재하고, 다수의 데이터에는 레이블이 없는 상황에서 알고리즘을 학습하는 학습 방법론
- 레이블이 부족한 데이터셋에 유용하지만, 레이블의 품질이 낮은 경우 치명적으로 성능이 떨어지며, 알고리즘의 복잡성이 높아진다.
-
자기 지도 학습 (Self-Supervised Learning) : 정답이 없는 데이터에서 정답을 강제로 생성 후 학습하는 방법론.
- 보통 데이터의 일부를 훼손 후 복원하는 방법을 사용하여 특정 데이터 내부의 성질을 파악하는데 사용된다. 정답 레이블이 없이 학습 가능하며, 다양한 데이터 (음성, 텍스트, 이미지, ...)에서 활용 가능하다. 하지만 학습 과정이 여러번 반복되어야 하며, 잘못된 패턴을 학습할 위험이 있다.
-
비지도 학습 (Un-Supervised Learning) : 정답 레이블 정보가 없이, 입력 데이터만을 활용하여 알고리즘을 학습하는 학습 방법론
- 사용자가 의도한 패턴 이외의 새로운 패턴을 찾을 가능성이 있으며, 정답 레이블이 필요하지 않다.
- Ex) K-means Clustering, DBSCAN, PCA, t-SNE, Isolation Forest
-
강화 학습 (Reinforcement Learning) : 어떤 환경(Enviornment)에서 에이전트(Agent)가 보상(Reward)을 이용해 특정 행동을 하도록 유도하는 학습 방법론.
- Ex) 로봇 청소기
분산
-
분산도 (degree of dispersion) : 관찰된 자료가 흩어져 있는 정도를 말한다
- Ex) 범위, 평균편차, 표준편차, 분산
-
범위 (range) : 관찰값들 중에서 가장 큰 수치와 가장 작은 수치의 차 (MAX(X) - MIN(X))
- 범위 자체로는 분포의 양상을 설명 할 수 없다는 단점이 있다
- IQR (InterQuartile Range)와 같은 범위는 이상치 탐지에 활용 가능하다
-
평균편차 (average deviation) : 관측값이 평균으로부터 얼마나 떨어져 있는지를 나타내는 값의 평균
- 평균편차는 집단의 크기로 스케일링하기 때문에 두 집단에 대한 상대적인 비교를 할 때 유용하지만, 절대적인 분산도가 큰지 작은지를 명확하게 나타내지 않는다는 한계가 있다.
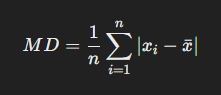
- 평균편차는 집단의 크기로 스케일링하기 때문에 두 집단에 대한 상대적인 비교를 할 때 유용하지만, 절대적인 분산도가 큰지 작은지를 명확하게 나타내지 않는다는 한계가 있다.
-
분산 (variance) : 관측값이 평균값을 기준으로 얼마나 흩어져 있는지를 나타낸다.
- 데이터가 평균 주변에서 얼마나 변동하는지를 절대적으로 나타내는 지표다
- 분산은 편차(|관측값 - 평균|)를 제곱하여 계산하기 때문에 평균에서 멀리 떨어진 관측값일 수록 민감하게 반응하며 관찰값의 단위를 그대로 사용할 수 없다는 문제가 있다 (Ex. cm -> cm^2)
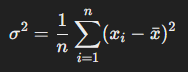
-
표준편차 (standard deviation) :
- 분산의 특성을 모두 가지고 있으며, 관측값과 동일한 단위를 사용할 수 있다. 또한, 분산에 비해 이상치에 대한 민감도를 줄일 수 있다는 장점도 있다.
분산의 특성
-
분산의 정의 :
-
상수(a) 곱하기 :
- 데이터의 변동성을 a의 제곱배로 변화시킨다. a>1일 때는 분포가 커지고, 0<a<1일 때는 분포가 작아진다
-
상수(a) 더하기 :
- 데이터의 위치를 수평적으로 이동하여 평균(기대값)에는 영향을 주지만, 관측값에 동일한 값이 더해지므로 분산에는 영향을 미치지 않는다
-
확률변수의 선형결합
- linear regression 모델의 예측값의 변동성을 평가할 때 사용 가능
- 혹은 확률변수 X와 Y를 선형결합 하여 만들어낸 파생변수의 변동성을 측정 가능
정보량
-
평소에 화를 잘 내지 않는 A라는 사람을 생각해보자. 우리는 ~ 의 사건 중 에 대해 A는 화를 내지 않을 것으로 예측해 볼 수 있다. 하지만, 사건 에 의해 A가 화가 났다면, 이는 일반적인 예측과 다르며(놀라움의 정도가 크며), 우리는 를 통해 A에 대한 정보를 더 얻을 수 있을 것이다.
-
한 사건(event)에서 기대되는 정보량(quantity of information, I)을 수량화 해보기 위해 확률(P)와 정보량(I)을 중요성과 가법성의 관점에서 살펴보자
-
정보량
- 중요성(significance) : 어떤 사건이 일어날 가능성이 작을수록, 그 사건은 더 많은 정보를 가진다
- 가법성(additivity) : 독립적인 사건 , 는 를 만족해야 한다
- 중요성(significance) : 어떤 사건이 일어날 가능성이 작을수록, 그 사건은 더 많은 정보를 가진다
-
중요성 조건은 어떤 사건의 확률이 높을수록 이 사건으로 알려지는 정보량이 적어짐을 나타내므로, 중요성에 따른 정보량을 아래와 같이 나타낼 수 있다
- ... (1.1)
- 이때, 이므로 이다
-
하지만, 이므로, (1.1)은 가법성의 조건이 충족되지 못한다.
-
두 독립 사건의 확률값은 곱으로 이루어지지만, 두 사건의 결합된 정보 내용은 더해져야 한다. 우리는 log를 도입하여 해당 문제를 해결할 수 있다.
- ... (1.2)
-
계산된 정보량은 밑이 2인 로그로 계산되기 때문에 그 단위는 bit가 된다. 해당 값은 그 사건에 의해 생성되는 놀라움의 정도(amount of surprise)라고 할 수 있다. 예를 들어, 로또 1등에 당첨되는 경우(확률값이 작은 경우)는 매우 놀랍지만, 꽝인 경우(확률값이 큰 경우)는 놀라움의 정도가 작다.
엔트로피
-
엔트로피(H) : 확률 변수의 표본 공간에서 나타나는 모든 사건들의 정보량의 평균적인 기댓값
(= 평균 정보량 = 확률분포에서의 정보량을 정량화)- 어떤 확률 변수(X)가 지니는 평균적인 불확실성(uncertainty)을 측정한다
- 불확실성이 크다는 것은 사건의 발생 결과가 다양하고 예측하기 어렵다는 것을 의미한다. 결국 엔트로피가 클수록 정보량이 많다
분포의 크기와 엔트로피
-
분포가 크다는 것은 데이터가 더 넓게 퍼져 있다는 것을 의미한다. 즉, 각 사건의 발생 가능성이 더 균등하게 분포될 수 있음을 알려준다.
-
분포가 작을 경우는 데이터가 평균에 가까이 모여 있다는 것을 의미한다. 이는 특정 사건의 발생 가능성이 더 높음을 알려준다.
-
결국 분포가 크면 데이터의 변동성이 크고, 엔트로피가 높아지며, 이는 더 많은 정보량을 의미한다. 반면 분포가 작으면 데이터의 변동성이 적고, 엔트로피가 낮아지며, 이는 정보량이 적다는 것을 의미한다.
분산과 엔트로피
-
분산은 주로 수치 데이터의 변동성을 측정하고, 데이터 값이 평균에서 얼마나 멀리 떨어져 있는지를 나타낸다. 반면, 엔트로피는 확률분포의 불확실성을 측정하며, 이는 사건의 발생 확률 분포에 따라 달라집니다.
-
데이터 포인트들이 평균에서 멀리 떨어져 있어도, 그 분포가 예측 가능하거나 균일하지 않을 수 있다. 예를 들어, 매우 높은 분산을 가진 데이터 분포도 평균 근처에 많은 데이터가 집중되어 있고 극단적인 값을 가진 소수의 이상치에 의해 분산이 높아질 수 있다. 이 경우 엔트로피는 반드시 높지는 않다.
-
엔트로피는 예측이 어렵고 결과의 분포가 균일할 때(가 일정할수록) 높게 나타나므로, 분산이 높다고 해서 반드시 엔트로피가 높은 것은 아니다.
공분산
-
결합확률분포 : 두 개 이상의 확률변수가 관련된 확률분포
-
공분산(Covariance) : 결합확률분포(확률변수 2개)의 분산
-
공분산의 해석
- > 0 : X가 증가할 때 Y도 증가하는 경향성 (양의 선형 관계)
- < 0 : X가 증가할 때 Y는 감소하는 경향성 (음의 선형 관계)
- 이 0에 가까움 : 두 변수 간의 선형 관계가 거의 없음
-
피어슨 상관계수(Correlation, Coefficient)
- 공분산을 두 독립변수의 표준편차로 나눠준다 ... (1)
- 이때, 각 묶음의 평균과 분산은 0, 1이 된다
- (1)은 공분산을 표준화하는 과정이다. 결과적으로 상관계수는 다음과 같은 특징을 갖게된다.
- 공분산의 단위를 지워준다. 예를 들어 X는 cm 단위, Y는 kg 단위일 경우 공분산의 단위는 cm * kg이므로 직관적인 해석이 어렵지만, 상관계수는 단위가 없다.
- 대칭성을 갖는다.
- 평균을 0, 분산을 1로 표준화했기 때문에 [-1, 1]의 값을 갖는다
공분산의 특성
-
상수(a, b) 곱하기
-
상수(a, b) 더하기
-
확률변수의 선형결합 (상수항은 무시됨)
추론의 접근 방법
-
Deterministic approach
- 모든 것들은 명백하게 결정될 수 있다고 생각하는 접근 방법이다.
Deterministic approach에 의하면 우리가 관측하는 모든 것들은 확실하게 존재하며, 우리가 알고자 하는 모든 것들에 대해서 확실한 값을 제시할 수 있다. 만약 우리가 제시한 값이 실제 값과 일치하지 않는 경우 예측하기 위한 충분한 정보를 가지고 있지 않기 때문이다. - Ex) OLS(정규방정식)
- 모든 것들은 명백하게 결정될 수 있다고 생각하는 접근 방법이다.
-
Probabilistic approach
- 모든 것들은 명확하게 결정지을 수 없는 확률적인 현상이라고 생각하는 접근 방법이다. Probabilistic approach에 의하면 우리가 관측치는 확률적인 현상의 발현이며 예측하는 결과 또한 확률적으로 존재하는 무수히 많은 값들 중 하나이다. 따라서 모든 현상에 확률을 부여한다.
- Ex) 베이지안 선형 회귀 (Bayesian Linear Regression)
-
보통 머신러닝(ML)에서 결정론적 방법으로 해결할 수 있는 문제는 제한적인데, 이유는 아래와 같다.
- 데이터의 불확실성 및 노이즈
- 비선형적이고 복잡한 패턴
- 주어진 데이터에 대한 과적합(Overfitting) 문제
추정
-
우리가 사용하는 데이터는 현실(모수)에서 추출된 일부분(표본)이다. ML의 목표는 표본을 사용하여 현실을 가장 잘 설명하는 모델을 만드는 것이기 때문에, 우리는 표본을 통해 모집단의 특성을 알아내야 한다.
-
추정 : 표본의 특성을 기초로 하여 모집단의 특성을 파악하는 것
-
추정값(estimate) : 모수를 추정하여 나온 결괏괎 그 자체
-
추정치/추정량(estimator) : 추정값을 구하기 위하여 사용되는 추정방법, 혹은 추정값 계산을 위한 통계량
-
MSE(Mean Squared Error)를 사용하여 최적 추정치를 찾아보자 -> Deterministic
-
: 각 데이터 포인트 || : 추정치 || : 데이터 포인트의 수
-
에 대해 미분하면
-
위 식이 0일 경우 MSE가 최소가 된다
-
결국 MSE를 최소화하는 추정치는 평균이고, 이것이 최적 추정치이다.
-
-
MLE(Maximum Likelihood Estimation) : 주어진 데이터에 대해 특정한 확률 모델(분포)의 파라미터(모수)를 추정하는 통계적 방법
- 우도(Likelihood) : 관측된 데이터가 특정한 파라미터 값을 가정할 때 얼마나 가능성이 높은지를 나타낸다.
- 우도 함수(Likelihood Function) :
- 로그 우도 (Log-Likelihood) : 계산의 용이함을 위해 로그 우도를 사용한다.
- 최대우도추정(MLE) : 로그 우도 함수를 최대화하는 파라미터 를 찾는 과정이다.
- 데이터가 어떤 분포를 따르는지 가정한다 (정규분포, 포아송분포, 이항분포, ...)
- 로그 우도 함수를 정의한다
- 로그 우도 함수가 최대화되는 파라미터 를 찾는다
- MLE(Maximum Likelihood Estimation)를 사용하여 최적 추정치를 찾아보자(정규분포 가정) -> Probabilistic
- 정규분포에서 각각의 데이터 포인트 에 대한 확률 밀도 함수는 다음과 같다
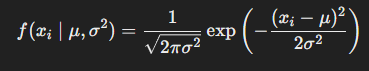
- 전체 표본에 대한 우도 함수는 각 확률 밀도 함수의 곱으로 표현된다.
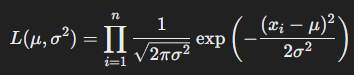
- 우도 함수에 로그를 취해 로그 우도 함수를 만든다
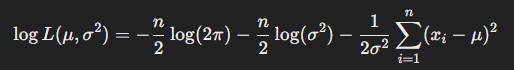
- 로그 우도 함수를 에 대해 최대화하기 위해 에 대해 미분을 계산하고, 0으로 설정한다
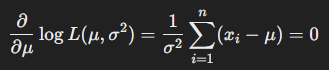
- 위 식을 정리하면 아래와 같다
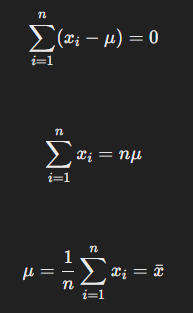
- 정규분포에서 각각의 데이터 포인트 에 대한 확률 밀도 함수는 다음과 같다
Simple Liner function
- 과자(1,500원/개수)와 우유(1,200원/개수)를 사기위해 마트에서 장을 본다고 가정하자. 총 가격은 아래와 같은 선형 방정식의 형태로 표현할 수 있다.
- total cost =
- matrix로 이를 표현해보자. 물품의 가격을 A, 개수를 B라고 할 때 total cost TC는 , 즉 내적으로 표현 가능하다.
-
이처럼, 서로 선형 독립인 변수들(과자와 우유의 개수)이 파라미터(가격) 만큼 일정한 비율로 종속 변수(total cost)에 영향을 미치는 관계를 표현한 것이 liner function이다.
-
이를 일반화 시키면 아래와 같다
- 종속변수 y에 대해 파라미터와 독립변수가 선형 결합을 이루고, 이것으로 종속 변수의 값을 표현 할 수 있는 경우, 이를 선형 모델이라고 한다.
- y =
( : feature || : parameter, weight || : 상수)
-
feature가 하나인 단순한 경우 (y = ) MSE를 사용하여 에러가 최소화되는 값을 찾아보자
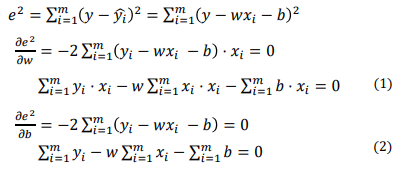
- (1)과 (2)를 m으로 나눠준다.
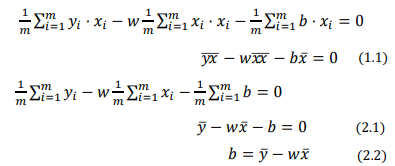
- (2.2)를 (1.1)에 대입한다
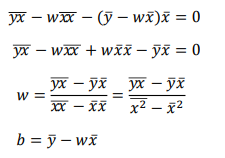
-
최적 추정치는 평균이므로, 위 식의 값들은 아래와 같이 나타낼 수 있다.
-
결국, 최적 와 는 다음과 같다.
