회귀분석의 전제 조건
-
선형성 (Linearity) : 종속 변수 Y와 독립변수 X 사이에 관계가 선형적이어야 한다
- 확인 방법 : 잔차와 독립 변수 간의 산점도를 통해 선형성을 시각적으로 확인 가능하다
-
독립성 (Independence) : 각 관측값은 서로 독립적이어야 한다. 특히, 잔차들 사이에는 자기 상관이 없어야 한다
- 확인 방법 :
Durbin-Watson 통계량 -> 2에 가까울수록 잔차의 독립성이 만족된다,
Cov(잔차, 독립변수) -> 0에 가까울수록 잔차의 독립성이 만족된다.
- 확인 방법 :
-
등분산성 (Homoscedasticity) : 잔차들의 분산이 독립 변수 값에 따라 일정해야 한다. 즉, 모든 수준의 독립 변수에 대해 잔차의 분산이 동일해야 한다.
- 확인 방법 : 잔차와 예측값의 산점도
-
정규성 (Normality) : 잔차가 정규분포를 따라야 한다 (잔차에는 정보가 없어야 한다)
- 시각적 확인 방법 : 히스토그램, Q-Q 플롯
- 통계 검정 : Shapiro-Wilk test
최소제곱법
-
최소제곱법(Ordinary Least Squares, OLS) : 회귀 직선이 실제값과 근접하도록 적합선을 만들어내는 선형 회귀 모델의 추정방법
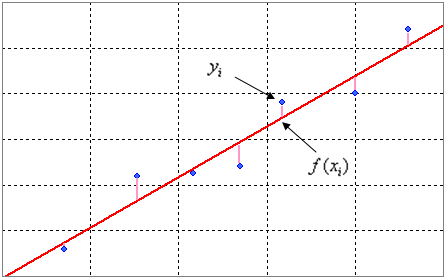
- (예측값)와 (실제값)의 수직편차를 잔차()라고 한다
- OLS는 잔차들의 제곱합을 최소화하여 가장 적합한 회귀 직선을 찾는다
- (예측값)와 (실제값)의 수직편차를 잔차()라고 한다
-
단순 회귀모델은 다음과 같다
-
잔차
- 가정 1) 잔차는 평균이 0이고, 분산이 인 확률변수라고 가정한다
- 가정 2) 잔차들()은 동일한 분산을 가지며(등분산성), 실험마다 서로 독립이다
-
절편(), 기울기()
- n회의 실험을 통해 얻은 n개의 관측값에 의해 구한 모수 (, )에 대한 추정치를 (, )이라고 한다
- sampling을 진행해 반복실험을 하면, (, ) 값이 매번 달라질 것이다
- 이렇게 얻은 추정값들을 확률변수 (, ) 값으로 간주 할 수 있다 (∵Sampling에 따라 변화)
-
위 회귀모델에서 는 실제값(true function)이며 이는 확정된 값(결정적 모수)이다. 따라서 에 대해 불확실성을 제공하는 요소는 잔차가 유일하며, 모든 에 대해 가 성립한다
-
표본분산의 경우 이지만, 변동성이라는 관점에 집중해 을 으로 대체한다
-
추정치 이 (모수)의 불편추정량임을 증명해보자(은 모두 의 축약)
- 추정치 의 분산을 계산해보자
-
단순 회귀 모형에서는 이 위와 같지만, 다중 회귀 모형에서는 다중공선성 문제를 고려해야 한다.
-
다중공선성 (Multicollinerity) : 회귀분석에서 독립변수들 간에 강한 상관관계가 나타나 중요도가 제대로 파악되지 않는 문제. 회귀분석의 전제 조건 중 독립성(Indepndence)에 위배되며, 아래와 같은 문제가 발생한다.
-
계수 추정의 민감성 : 독립 변수 의 작은 변화가 회귀 계수 의 큰 변화를 유발할 수 있다. 즉, sampling에 따라 회귀 계수의 추정치가 크게 변할 수 있다. 이는 추정치의 분산이 커지는 것을 의미한다.
-
과대/과소 추정 : 회귀 모델은 다중공선성이 있는 독립 변수들(예: )의 기여도()를 명확하게 구분하기 어렵기 때문에, 모델이 샘플에 따라 계수를 과대 또는 과소 추정할 수 있다. 이는 추정치의 분산을 증가시키고, 회귀 계수를 정확하게 추정하기 어렵게 만든다.
-
-
다중 회귀 모형에서는 다중공선성이 있는 상황에서 회귀 계수의 분산이 과소평가되는 것을 방지하기 위해 VIF(Variance Inflation Factor)를 추가하여 를 정의한다
-
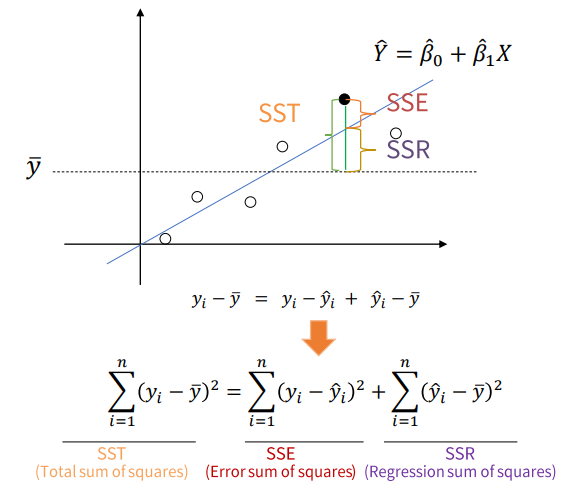
결정계수 () : 종속변수 Y가 독립 변수들()에 의해 얼마나 잘 설명되는지 나타나내는 값. 0~1 사이의 값을 가지며, 결정계수가 클수록 모델이 데이터를 잘 적합시키고 있으며, 독립 변수들이 종속 변수에 대한 예측력을 갖고 있음을 시사한다
-
ex) 인 경우 독립 변수들이 종속 변수의 변동 중 80%를 설명하고 있음을 의미한다.
-
-
: 독립변수 X_i가 다른 독립 변수들에 의해 얼마나 잘 설명되는지를 나타내는 값
- 값이 클수록 (1에 가까울수록) 값이 커지며, 이는 다중공산성이 심각하다는 신호이다.
-
의 계산방법
- 1) 를 종속 변수로 설정하고, 나머지 독립 변수들을 독립 변수로 설정한다
- 2) 회귀 모델 을 사용하여 회귀 분석을 수행 후 결정계수를 계산한다
- 회귀계수의 분산이 작다는 것은 추정된 가 큰 변동 없이 특정 값에 수렴할 가능성이 높다는 뜻이다. 즉, 회귀계수의 분산이 작을수록 예측 모델이 일관된 결과를 제공할 가능성이 높다.

- 회귀계수의 분산을 줄이기 위해서 어떻게 해야 하는지 요소별로 살펴보자
- (잔차의 분산) 줄이기
- feature selection, 변수 변환(로그 변환, 제곱근 변환,...) 등을 통해 모델이 종속 변수를 더 잘 설명할 수 있도록 해야 한다.
- (VIF) 줄이기
- 다중공선성을 feature selection, PCA, 규제적용(Ridge, Lasso) 등으로 완화해야 한다
- (의 분산) 늘리기
- 더 다양성이 높은 데이터 샘플을 수집하거나, 데이터의 스케일을 변경(로그 스케일, ...)하여 분산을 늘릴 수 있다
- (잔차의 분산) 줄이기
- 추정치 가 (모수)의 불편추정량임을 증명해보자
-
추정치 의 분산을 계산해보자
-
절편의 분산의 경우도 회귀 계수의 분산과 같이 작을수록 예측 모델이 일관된 결과를 제공할 가능성이 높다.
-
절편의 분산을 줄이기 위해서 어떻게 해야 하는지 요소별로 살펴보자 (회귀계수와 중복 설명 생략)
-
(잔차의 분산) 줄이기
-
(독립 변수의 제곱합) 줄이기
- 데이터 스케일 조정 및 outlier 관리
-
(표본 크기) 늘리기
- 더 많은 데이터를 확보하여 모델의 추정치가 데이터 변동성에 덜 민감하게 하기
-
(독립변수의 편차 제곱합)
-
회귀 계수의 평가
-
개별 회귀 계수(각 독립 변수 X가 종속 변수 Y에 미치는 영향력)는 아래와 같이 정의했다
-
회귀 계수 값이 통계적으로 유의미한지 검정해 볼 수 있다
-
k개의 회귀 계수 각각에 대해 t-검정을 진행할 수 있다
- : (X와 Y는 선형 관계가 없다)
- : (X와 Y는 선형 관계가 있다)
-
검정통계량 (t-value)은 아래와 같다
- t-value가 크다는 것은 회귀 계수가 표준 오차(SE)에 비해 크다는 것을 의미하며, 독립변수 X가 종속 변수 Y에 유의미한 영향을 미친다고 해석할 수 있다
-
p-value는 가 자유도 (n-k-1)의 t-분포를 따른다고 가정하고 계산된다
- n : 데이터의 row수 || k : feature 개수 || -1 : 절편(독립 변수가 모두 0일 때 예상 Y값)
-
p-value가 유의수준 보다 작으면 를 기각한다
