1) 단어 범위
AI > ML > DL
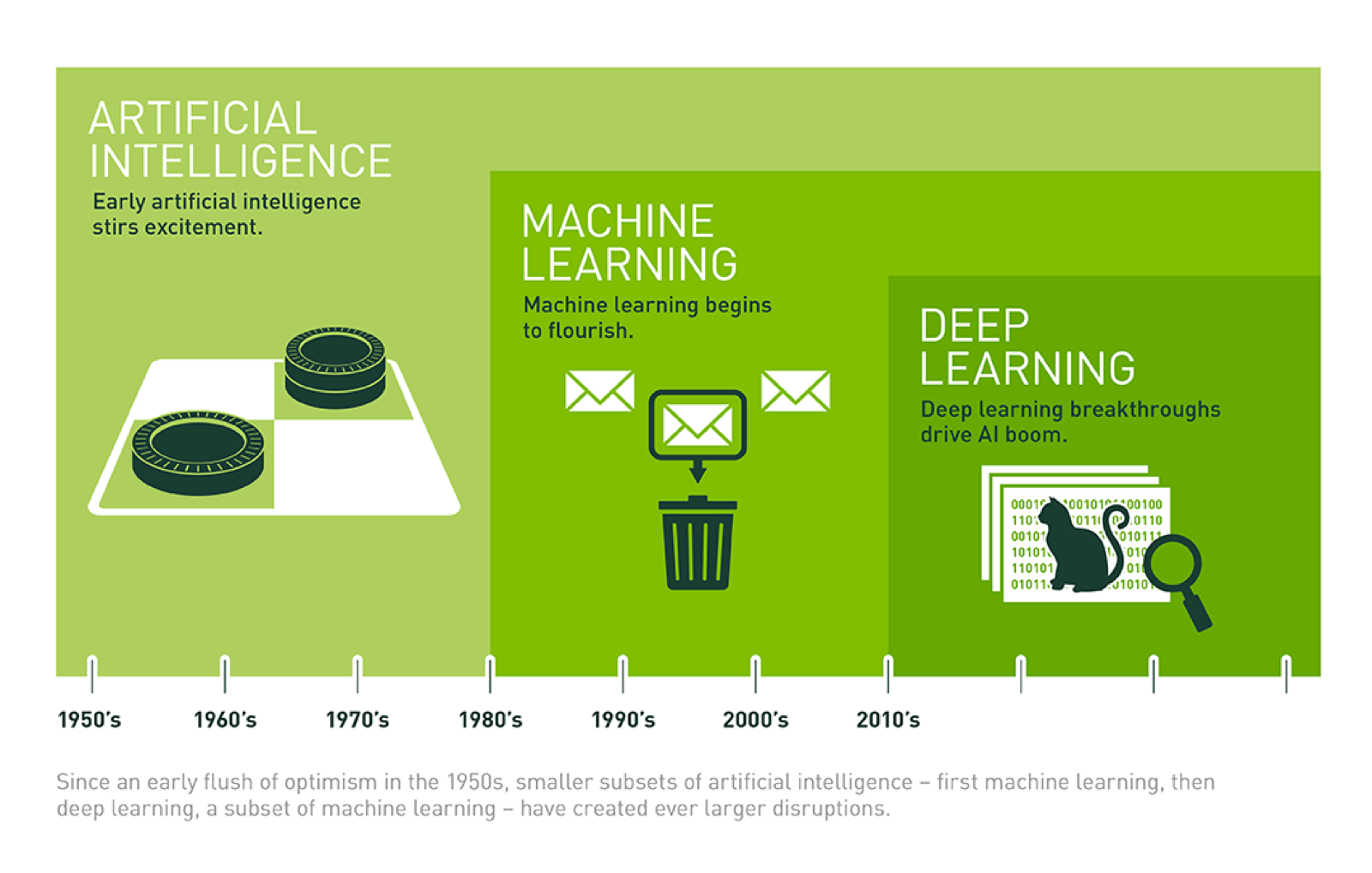
2) ML vs DL
ML은 학습 데이터를 수동 제공
ML은 그 기능이 무엇이든 점진적으로 향상되기에
알고리즘이 부정확한 예측을 반환하면 엔지니어가 개입하여 조정 필요
DL 모델을 사용하면 알고리즘이 자체 신경망을 통해 예측의 정확성을 높이고,
분류를 더욱 잘할 수 있게 스스로 학습
ex) 고양이 사진을 구분하는 AI를 만들 때
- ML case
고양이의 feature를 선택해서 어떤 feature가 이미지를 잘 설명하는지
엔지니어가 feature 직접 선택
- DL case
한 스텝 나아가서 정답지만 있으면 feature를 자동적으로 스스로 학습하여 골라내고
컴퓨터 스스로 이러한 특징을 가지고 있으면 고양이다! 라고 결론을 내린다.
Q : 스스로 해석하는 DL이 무조건 더 좋은거 아닌가?
해석력의 차이
DL은 학습이 오래걸리지만 성능이 매우 뛰어나다.
그러나 아주 치명적인 단점이 있는데, 왜 결과가 그렇게 나왔는지 모른다.
알파고가 왜 그런 수를 놓았을까? 모른다
왜냐면 인공신경망에 의해 가장 높은 승리의 확률을 가지는 수를 놓는 것이기 때문이다.
반면 의사결정나무 같은 ML 알고리즘은 우리가 feature를 선택하기 때문에,
선택에 따른 좋은 결과와 좋지 않은 결과의 원인 파악이 가능하다.
따라서 '결과'가 아닌 '해석'이 필요하면 ML 알고리즘이 적합하다.
3) 결론
하지만 ML이든 DL이든 중요한건 데이터
"AI는 로켓을 만드는 것과 비슷하다고 생각합니다.
거대한 엔진과 많은 연료가 필요합니다.
엔진이 크지만 연료가 적다면 궤도에 오르지 못할 것입니다.
엔진이 작고 연료만 많다면 이륙하지도 못할 것입니다.
로켓을 만들려면 거대한 엔진과 많은 연료가 필요합니다.” - Andrew Ng
엔진 = 모델
연료 = 빅데이터
모델과 데이터를 모두 생각해서 설계하자!
