CodingTest
1.[C++] 백준 1008번 문제 : A / B - 소수점 고정, 소수점 N자리
내가 쓴 오답 코드정답 코드실패 요인1\. '실제 정답과 출력값의 절대오차 또는 상대오차가 10^(-9) 이하이면 정답이다.' 라는 문구를 그대로 무시해버렸다. 즉, 출력과 실제 정답 간의 오차가 0.000000001 이하여야 한다는 것인데 기존에 입력했던 대로 코드를
2.[C++] 백준 10926번 문제 : ??! - 배열 기본
오답 코드정답 코드느낀 점사실 답을 알고 나니 굉장히 허탈한 문제였다. 심지어 위의 오답 코드는 컴파일조차 되지 않는 엉터리 배열 답안이었다. 배열 문제 푸는 방법을 확실하게 익혀야겠다.오답 요인1\. joonas, baekjoon이어야만 ??! 을 출력해야겠다는 생각
3.[C++] 백준 10172번 문제 : 개 - 기호 출력
"(큰따옴표)를 출력하고자 하면, 바로 앞에 \\(역슬래쉬)를 적으면 된다.'(작은따옴표)를 출력하고자 하면, 바로 앞에 \\(역슬래쉬)를 적으면 된다.\\(역슬래쉬) 를 출력하고자 하면, 바로 앞에 \\(역슬래쉬)를 한번 더 적으면 된다.즉, 바로 앞에 \\만 적으면
4.[C++] 백준 알고리즘 : 입출력 실행 속도 높이기

C++로 알고리즘을 풀 때 실행 속도를 높이기 위해 흔히 아래와 같은 구문을 작성한다.c++의 cin, cout은 c언어의 scanf, printf보다 속도가 느리다. 출력에서 큰 차이는 아니지만 입력의 경우, 2배 이상의 속도 차이가 난다.그렇기에, 백준의 일부 문제
5.[C++] 백준 25304번 문제 : 영수증 - 동적 할당
ㄴ
6.[C++] 백준 11382번 문제 : 꼬마 정민 - 데이터 타입 long long
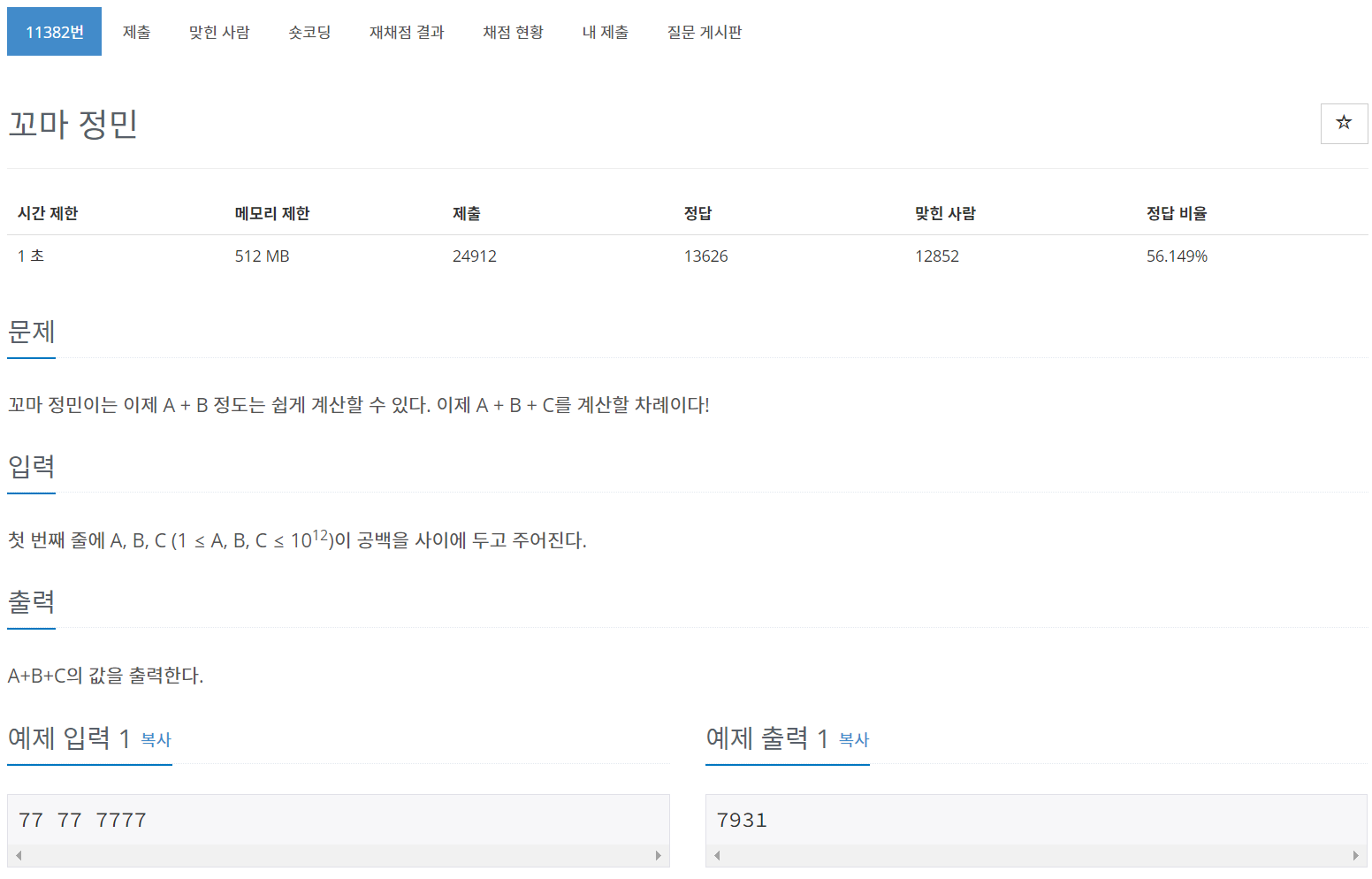
내가 쓴 답안
7.[C++] 백준 10951번 문제 : A + B - 4 - cin.eof()
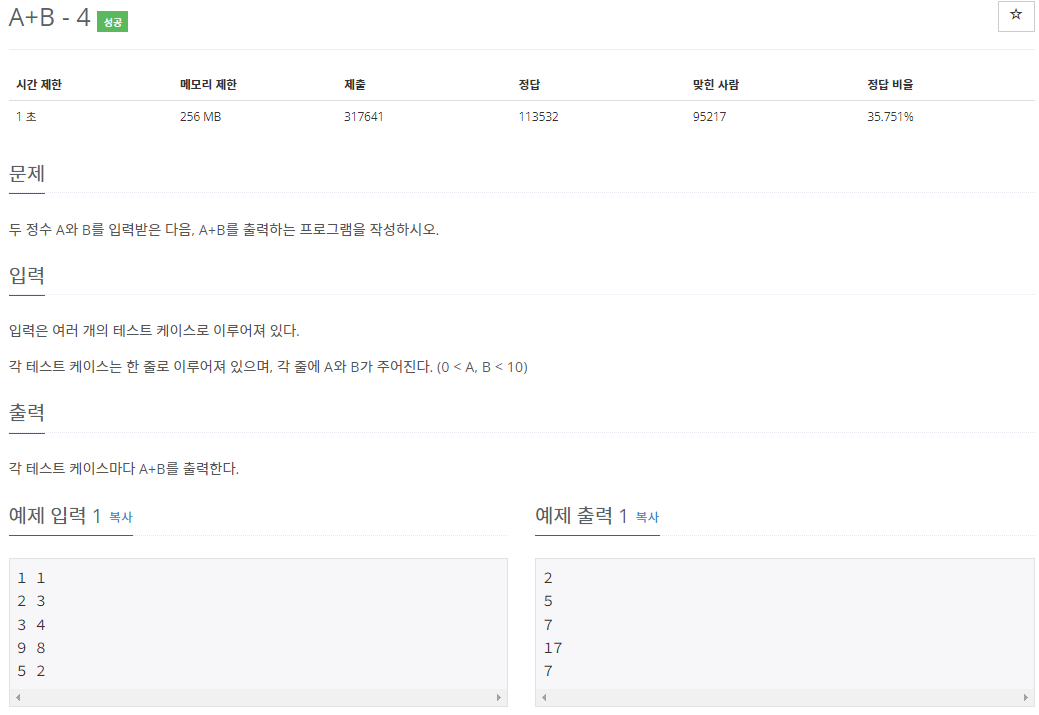
a라는 배열을 넉넉하게 100의 크기를 가질 수 있도록 int형 변수로 선언했다. 문제를 너무 쉽게만 보았던 것이 함정이었다고 생각한다. 넉넉하게 입력값을 넣으면 단 한 번에 이에 대한 출력이 나오나? 라고 생각하면서 만든게 위의 코드다. 물론 넣을때마다 바로 더한 값
8.[C++] 백준 10813번 문제 : 공 바꾸기 - 배열의 swap()
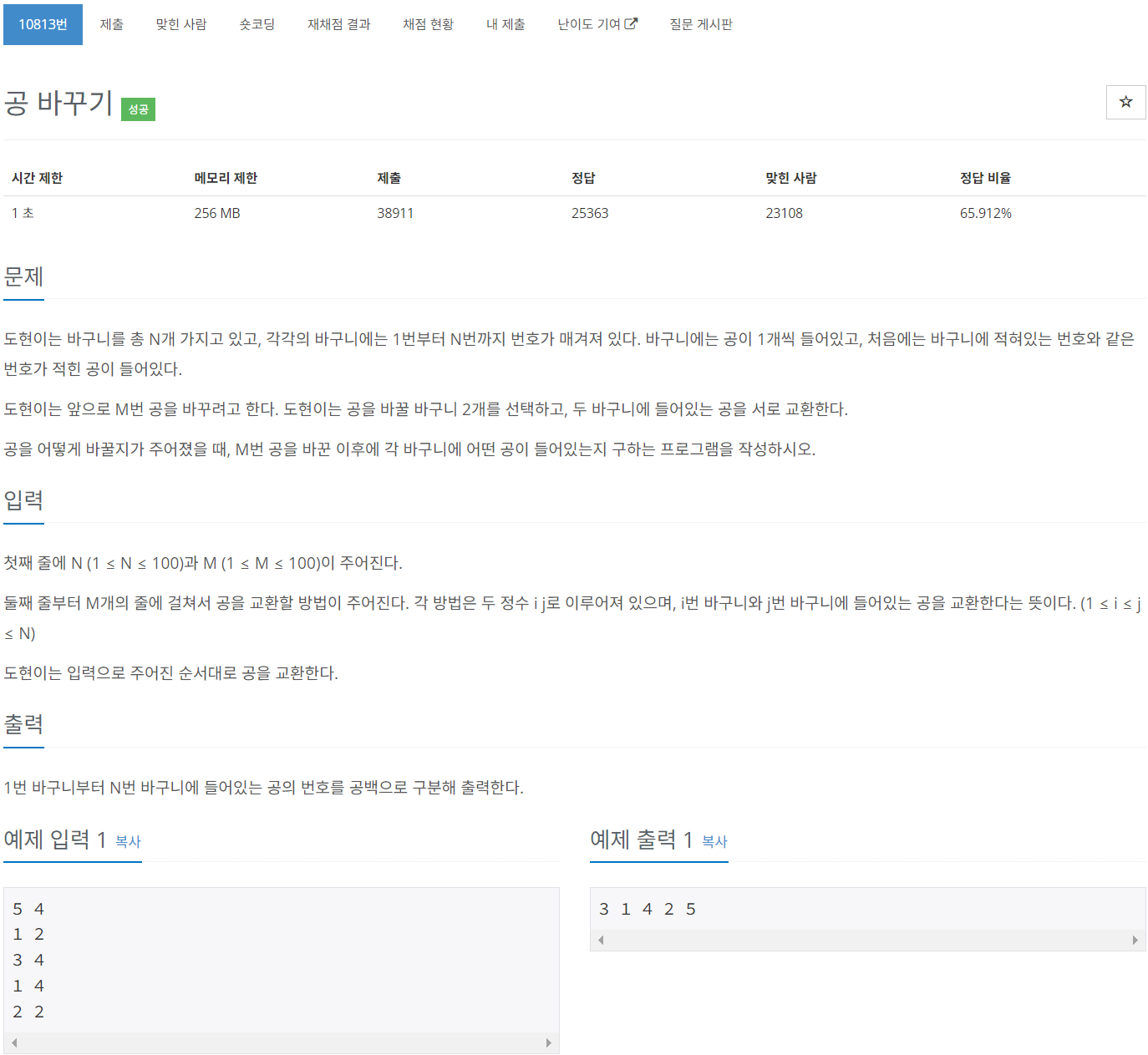
그렇다.. 심지어 미완성 코드다. 원래 내가 접근하려던 방식은 다음과 같다.공이 몇 번까지 있는지에 대한 번호를 range로 받아서 arrrange 배열로써 원소와 함께 저장하고, 바꿀 횟수 num을 행의 개수로 가지며 열은 2개로 고정인 2차원 배열을 생성하여 사용자
9.[C++] : Vector
내가 쓴 풀이벡터에 대해 잘 몰랐지만 등한시할 수 없는 부분이라 생각했고, 이 문제가 vector로 푸는 가장 쉬운 문제가 아닐까 싶어 공부하고 위처럼 풀었다.vector와 iterator는 예전에 문법 공부할때 알고는 있었지만 사용하지 않아서 감 잡기 쉽지 않았다.
10.[C++] 자릿수 더하기 - while문 활용
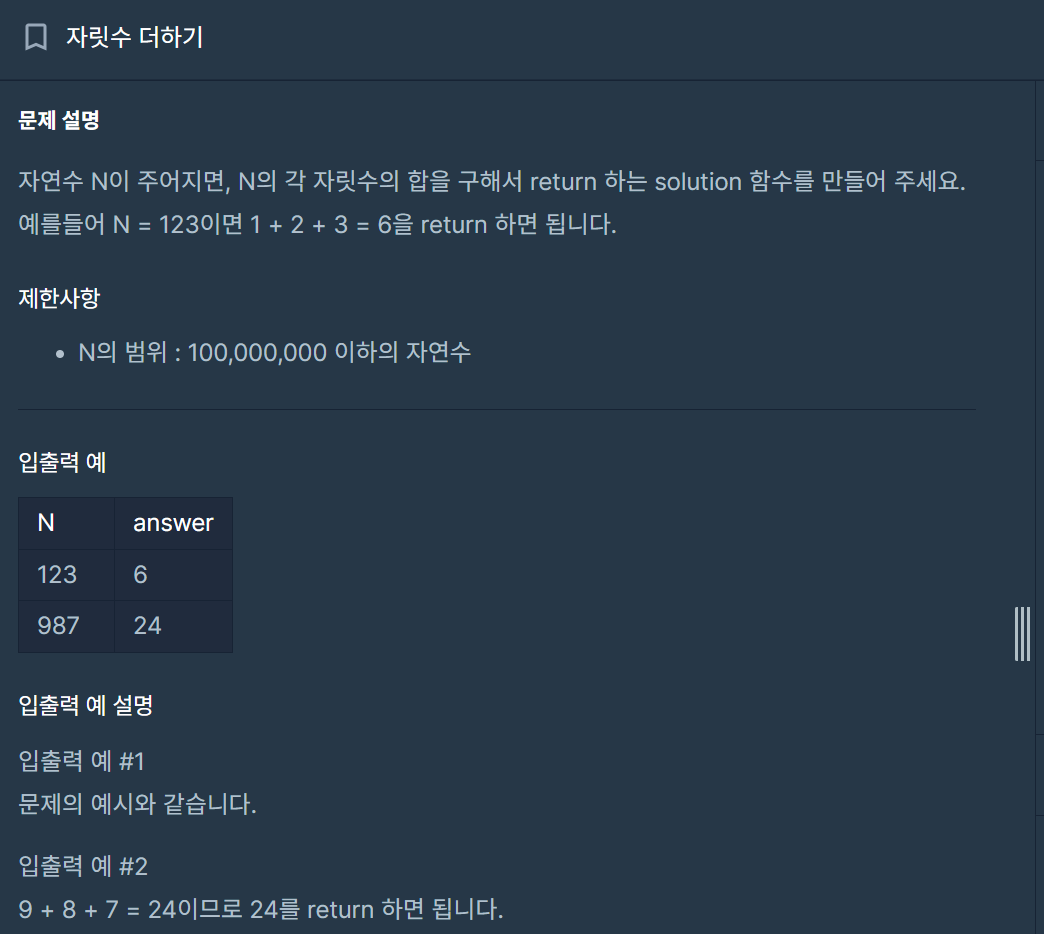
정답 확인정답을 보고야 말았다. answer와 n을 += 와 /= 로 써도 됐었는데 이해를 돕기 위해 풀어서 썼다. 기존에 내가 풀이하려던 방향은 받아오는 input을 string으로 돌리고 split 함수를 작성하여 delimiter를 중심으로 parsing 하려 했
11.[C++] 정수 내림차순으로 배치하기 - 벡터의 내림차순, 벡터 to int
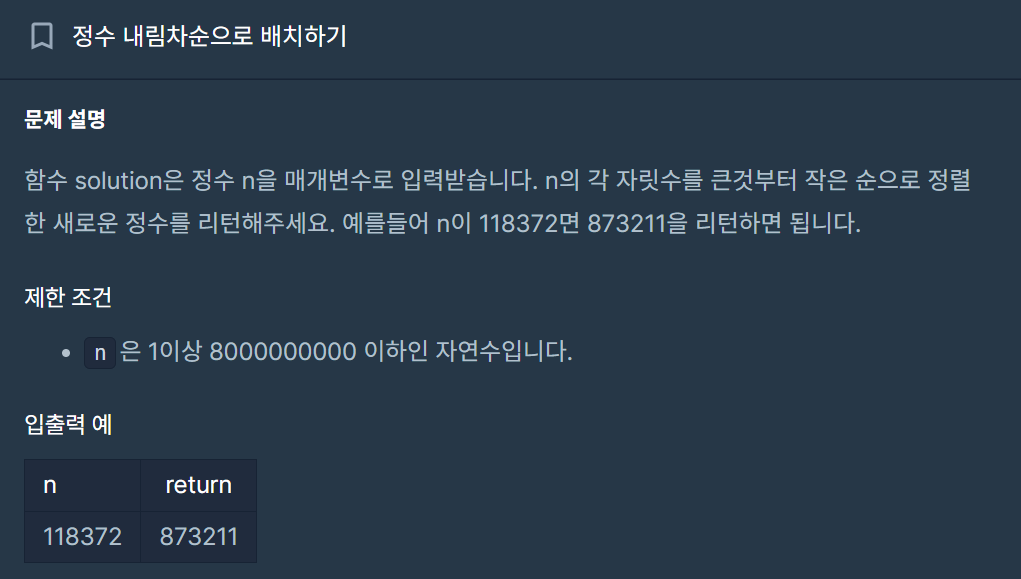
내 풀이 + ChatGPT 풀이위의 풀이 중 다음의 코드만 GPT의 도움을 받았다.아 물론, sort 함수를 사용한 코드는 구글링으로 해결했다. 내림차순을 나타내는 방법이 세가지 있음을 알게 되었다.1번째 sort(): r을 붙이고 (reverse) begin, end
12.[C++] 서울에서 김서방 찾기 - int to string
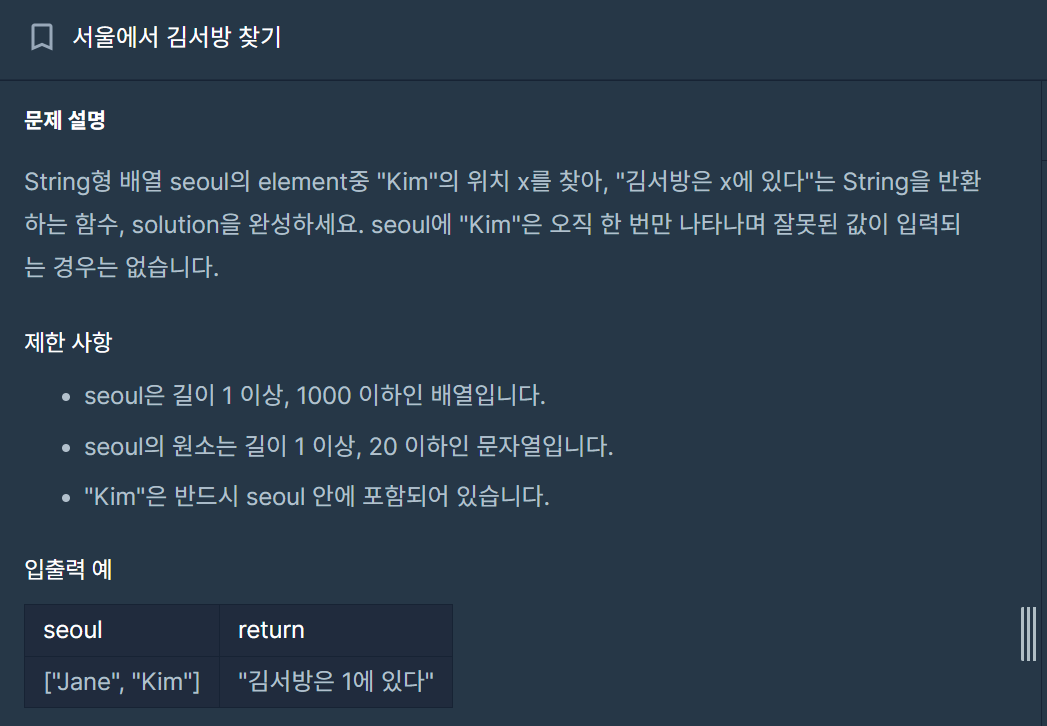
GPT + 나의 풀이 (전체적인 아이디어는 내 몫이었지만 문법이나 string 함수는 gpt의 몫이었다.. 사실상 반 이상 ..)line 04: Debugging을 위해 cout을 열심히 두들겼었지만 가장 기초적인 iostream 조차 선언되지 않은 상태였다.line
13.[C++] 제일 작은 수 제거하기 - 벡터 원소 제거, 최솟값(min_element)
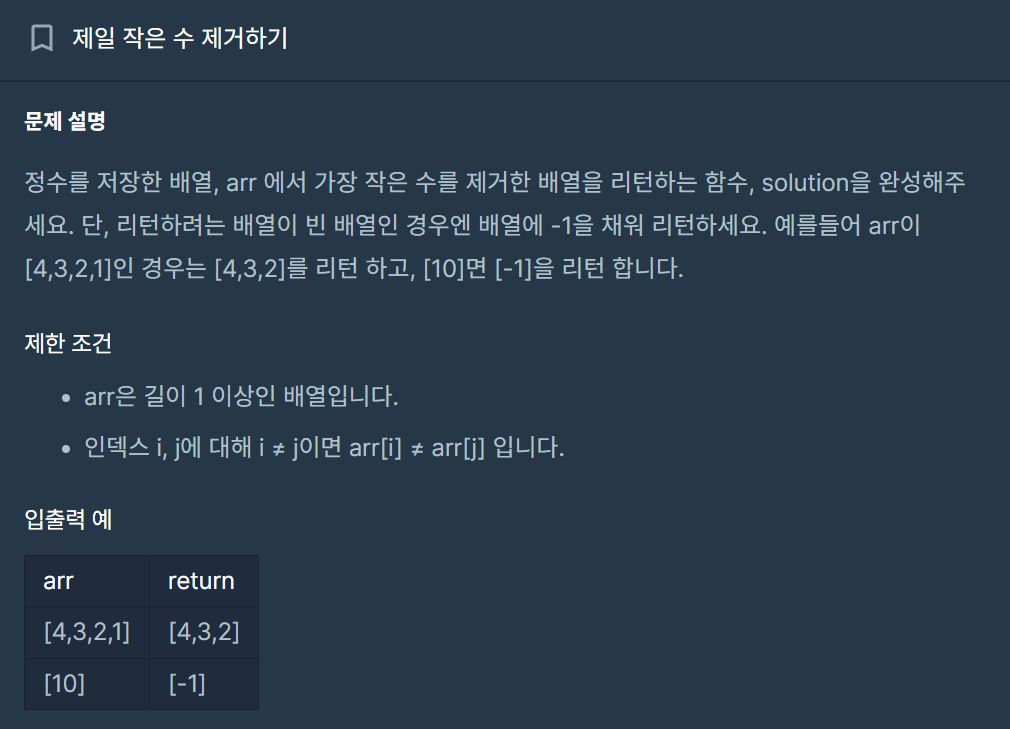
풀이 with 구글링int를 다루는 vector에서 최솟값과 최댓값 찾기erase()와 remove() 함수를 활용하여 원소를 제거한 방식은 추가 포스팅 참조vector에서 원소 하나 삭제하기 : 시간 복잡도 O(N)
14.[C++] erase()와 remove() 함수의 차이

: 주어진 값을 컨테이너 내에서 삭제하고 마지막 인덱스 + 1 (== end)를 반환한다. 단, 이 때 컨테이너의 크기가 실제로 줄어드는 것이 아니라, 삭제되어야 할 원소들의 위치에 유지될 원소들의 값을 덮어 씌우는 것이다. 그래서 컨테이너의 뒤 쪽에 쓸데없는 데이터가
15.[C++] 문자열 다루기 기본 - isDigit()
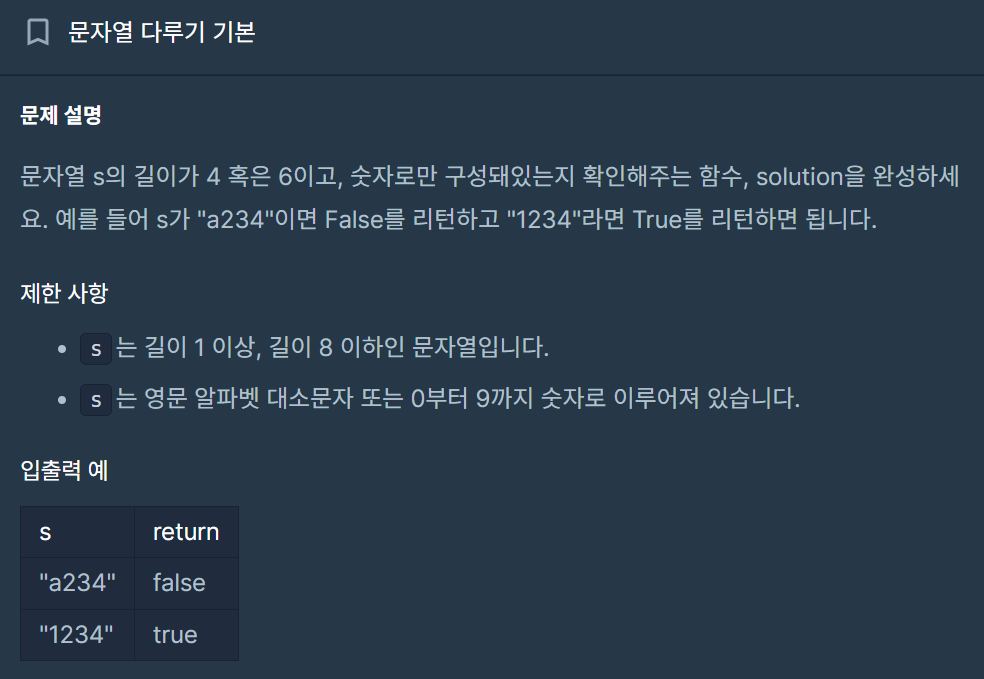
당연히 문자열의 길이가 4 or 6으로 들어오겠구나 하고 예외처리를 해두지 않았음.위의 for문을 다음 코드의 else 문 내부에 넣어두니 정확도 84.7% -> 100%로 만족할 수 있었다.결론: 문제를 잘 읽고 사소한 부분도 완벽하게 검토하자.
16.[C++] : 행렬의 덧셈 - 2차원 벡터
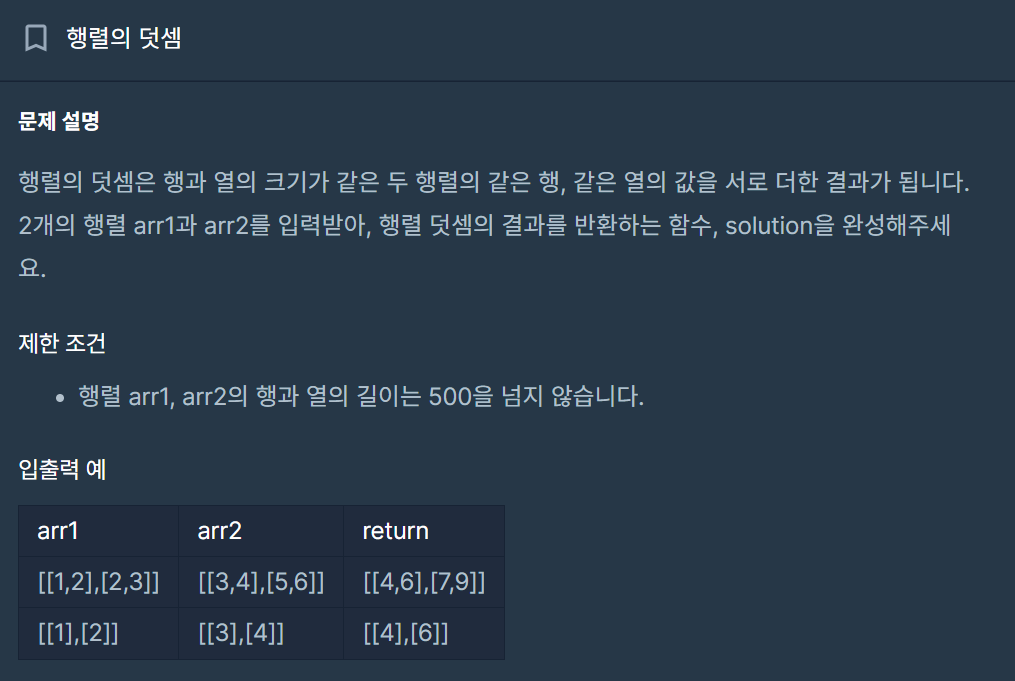
정답 확인2차원 벡터를 어떻게 다루는지 몰랐다. 그래도 for문을 이중으로 반복 시 arr1으로 한번 돌리고, arr1i로 한번 돌리는 방식은 알고 있었다. (Thx for ASP 수업)TODO: 2차원 벡터 정리하기만약 테스트 케이스를 추가한다면 다음과 같이 내가 기
17.[C++] 최대공약수와 최소공배수 - 구현

코드 분석: 로직상의 틀린 부분은 없었다. 다만, 제출 시 18.8%의 낮은 정확도를 보였고, 테스트 케이스를 추가했을때 1000000 999999 를 원하는 기댓값으로 처리하지 못하면서 Overflow가 발생하고 있었다. 이를 해결하기 위해 solution 함수와 a
18.[C++] 같은 숫자는 싫어 - vector의 unique()
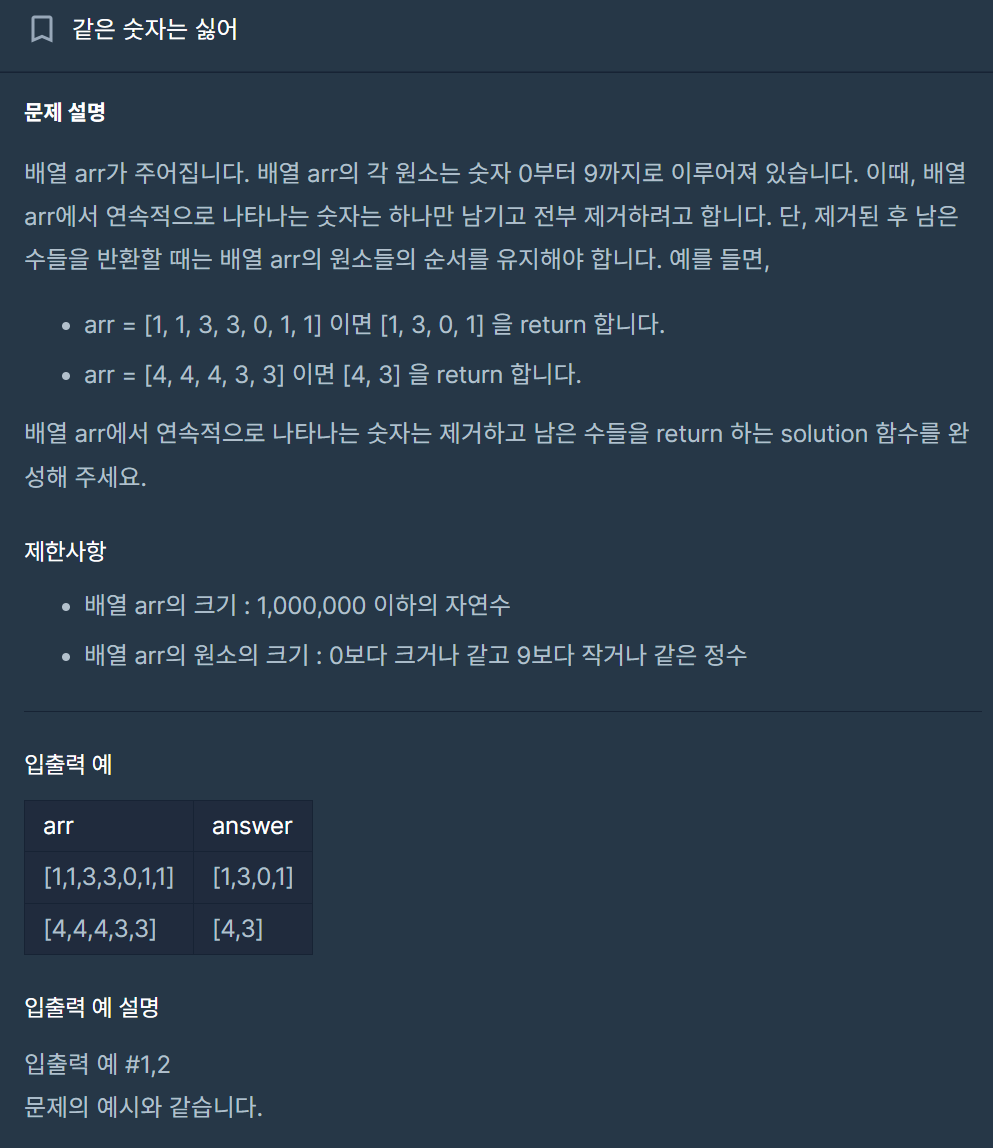
두 풀이의 차이점은 중복된 원소를 맨 뒤의 쓰레기 값으로 빼주는 unique() 함수를 썼는지에 대한 유무다. 두번째 풀이는 조금만 생각해도 머릿속에서 충분히 나올 수 있을만한 풀이이다. 하지만 unique 함수를 안썼기 때문에 정확한 처리가 힘들다. unique()
19.[C++] 3진법 뒤집기 - 구현
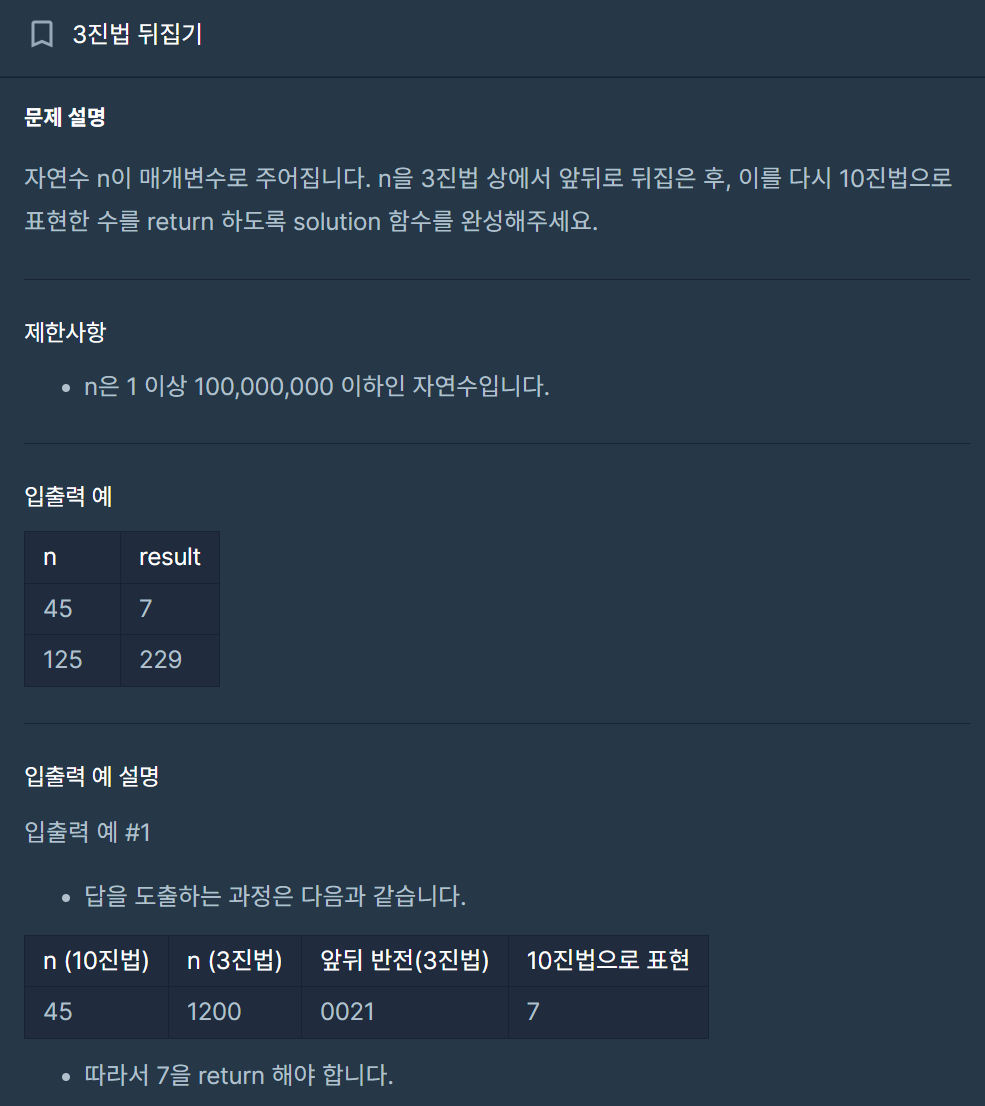
내 풀이
20.[C++] 이상한 문자 만들기 - split 함수 만들기, 대소문자 toupper, tolower 함수 사용
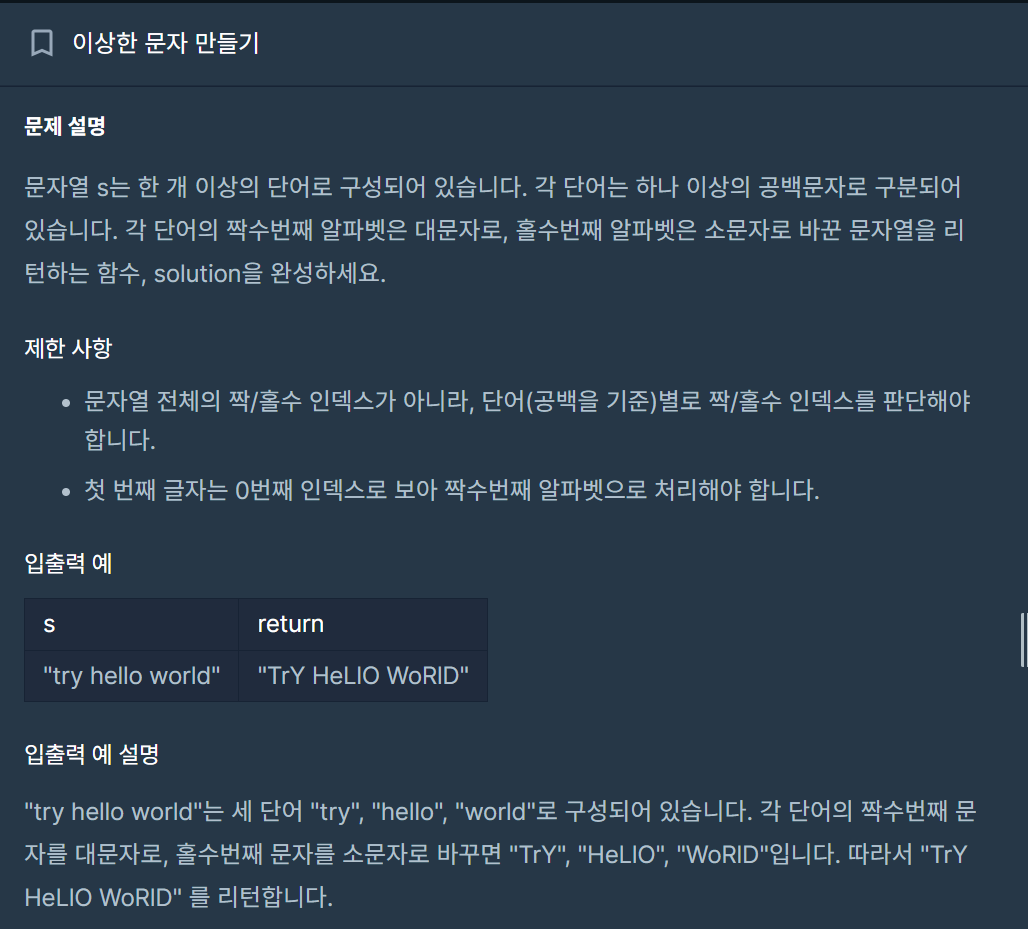
위의 코드를 사용하면 연속된 공백 문자를 전혀 대응하지 못해서 사실상 못 쓰는 풀이이다. 물론 조금 수정해보면 답을 도출할 수 있겠지만, 정답 풀이처럼 공백이 올때마다 새로운 인덱스를 반복적으로 초기화하여 toupper, tolower 함수를 사용해 대소문자 변환을 수
21.[C++] 크기가 작은 부분 문자열 - stoll(), substr()
전체적으로 아이디어 구상 + 초반 재귀 반복문 모두 잘 구현했다. 이후 디버깅 과정에서 18자리까지의 p의 길이를 고려하느라 애를 먹었는데, 힌트를 참고해서 long long으로 선언하는 것까지는 알아냈지만 stoll()이 처음엔 떠오르지 않았다. long long을
22.[C++] JadenCase 문자열 만들기 - split(), toupper/tolower(), insert + 초간단 풀이

총 주석 포함 64줄이 나왔다. 뿌듯한 마음을 가득 안고 다른 사람들의 풀이를 봤는데 놀라움을 금치 못했다. (초간단풀이...에서 소개)전체적으로 설명하자면 다음과 같다.얼마 전부터 연습 중인 split()의 구현으로 공백을 분리해서 result에 저장한다.answer
23.[C++] 이진 변환 반복하기 - 2진법 형태 문자열 만들기

https://school.programmers.co.kr/learn/courses/30/lessons/70129테스트 케이스를 따라가면서 1회만큼의 코드를 구현하고 while 문으로 반복해서 최종적으로 s가 "1"이 되면 반복문이 끝나도록 구성했다. 아무래도
24.[C++] bitset 라이브러리 활용: 2진수 변환 및 응용
bitset은 string, unsigned long, unsigned long long형으로 바꿀 수 있음
25.[C++] transform 함수의 활용
algorithm을 include한다.원형 - 단항 함수형: first, last : transform 함수를 적용할 원소들을 가리키는 범위d_first : 결과를 저장할 범위 (first와 동일해도 됨. 이 경우, 기존 데이터를 덮어쓰게 됨)unary_op : 원소
26.[C++] 숫자의 표현 : 구현

while문: left가 n보다 작은 한 계속 반복한다.내부에는 cnt가 n보다 작을 경우, 클 경우, 같을 경우로 나눈다.먼저, cnt < n인 경우: right 1 추가, cnt는 이전 cnt에 right를 더한다.다음, cnt = n인 경우: answer에
27.[C++] 피보나치 수 : DP(동적 계획법)

https://school.programmers.co.kr/learn/courses/30/lessons/12945하나의 큰 문제를 여러 개의 작은 문제로 나누고, 그 결과를 저장해서 다시 큰 문제를 해결할때 저장한 값을 가져오는 방식으로 해결문제 속의 문제가
28.[C++] 피보나치 수 : DP(동적 계획법)
https://school.programmers.co.kr/learn/courses/30/lessons/12945하나의 큰 문제를 여러 개의 작은 문제로 나누고, 그 결과를 저장해서 다시 큰 문제를 해결할때 저장한 값을 가져오는 방식으로 해결문제 속의 문제가
29.[C++] 피보나치 수 : DP(동적 계획법)
https://school.programmers.co.kr/learn/courses/30/lessons/12945하나의 큰 문제를 여러 개의 작은 문제로 나누고, 그 결과를 저장해서 다시 큰 문제를 해결할때 저장한 값을 가져오는 방식으로 해결문제 속의 문제가
30.[C++] 기능개발 - 큐(Queue)

큐(Queue)는 대표적인 FIFO(First In First Out) 구조이다. 제일 처음에 넣은 데이터가 처음으로 빠져나온다.기본 함수는 push, pop, empty, front, back, swap 등이 있다.스택과 달리 front 원소와 back 원소에 접근할
31.[C++] 프로세스 - 큐, pair, max_element

https://school.programmers.co.kr/learn/courses/30/lessons/42587값을 큐에 전부 복사합니다.복사할 때 {우선순위, 인덱스}를 함께 복사합니다.1번 수행 후 priorities의 순서는 보장되지 않아도 됩니다.so
32.[C++] BOJ : 시간 복잡도
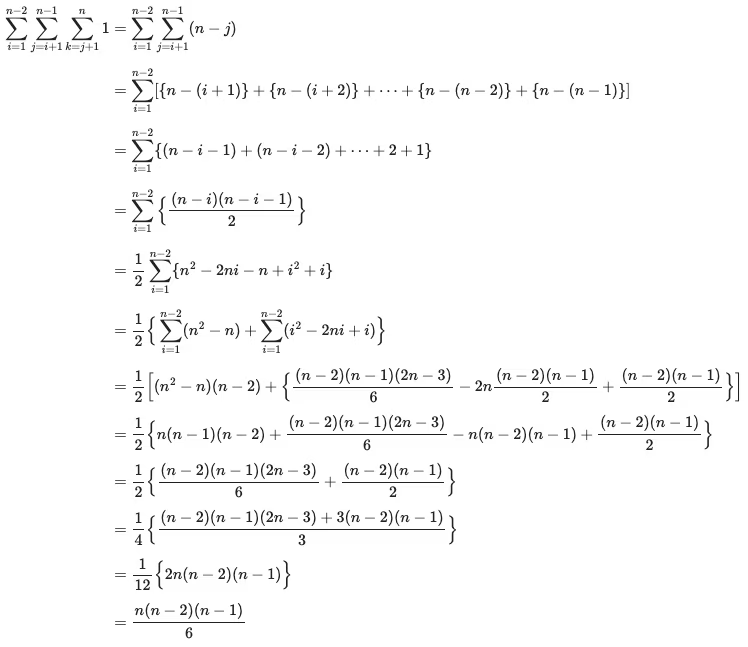
익명의 백준 수식 작성자분
33.PGMRS : 타겟 넘버 - 순열, DFS, BFS [3가지 풀이]
34.PGMRS : 네트워크 - DFS
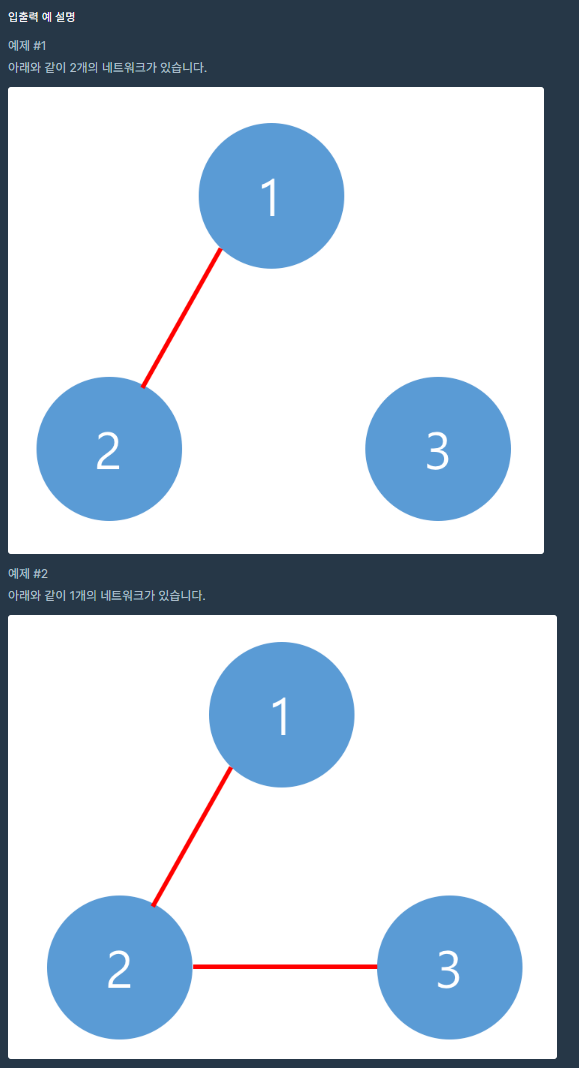
solution 함수에서 방문되지 않은 노드에 대해 network++을 하면서 computersi가 0인 외톨이 노드도 함께 카운팅된다. visited, computers 벡터에 대해 참조자를 넘기면서 메모리 절약 및 시간을 단축할 수 있다.DFS()에서, ...fro