Paired data
OpenIntro Statistics 4th Edition
Chater 7. Inference for numerical data를 바탕으로 작성했습니다.
묶음 글
1. One-sample mean with the t-distribution
2. Paired data(현재 글)
대학을 다녔다면 학교 서점과 인터넷 서점의 전공 서적 가격을 비교해 본 적이 있을 것이다. 같은 책인데 파는 곳만 다르기 때문에 (학교 서점 가격, 인터넷 서점 가격)으로 한 쌍의 데이터가 나온다. 이런 데이터를 paired data 라고 부른다.
참고로 딥러닝에서도 paired data라는 말을 쓰기도 하는데 데이터에 레이블링이 된 경우를 이야기 한다. 다른 개념이므로 구분하자.
책에서는 UCLA 서점과 아마존 판매 가격 데이터를 예시로 제공한다.
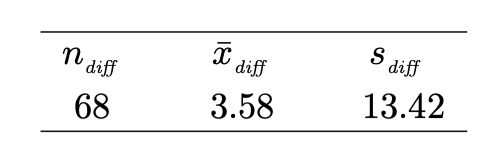
t-분포를 사용할 수 있을지 따져보자.
- Prepare 표본평균, 표본분산, 표본 수는 위 처럼 주어졌다.
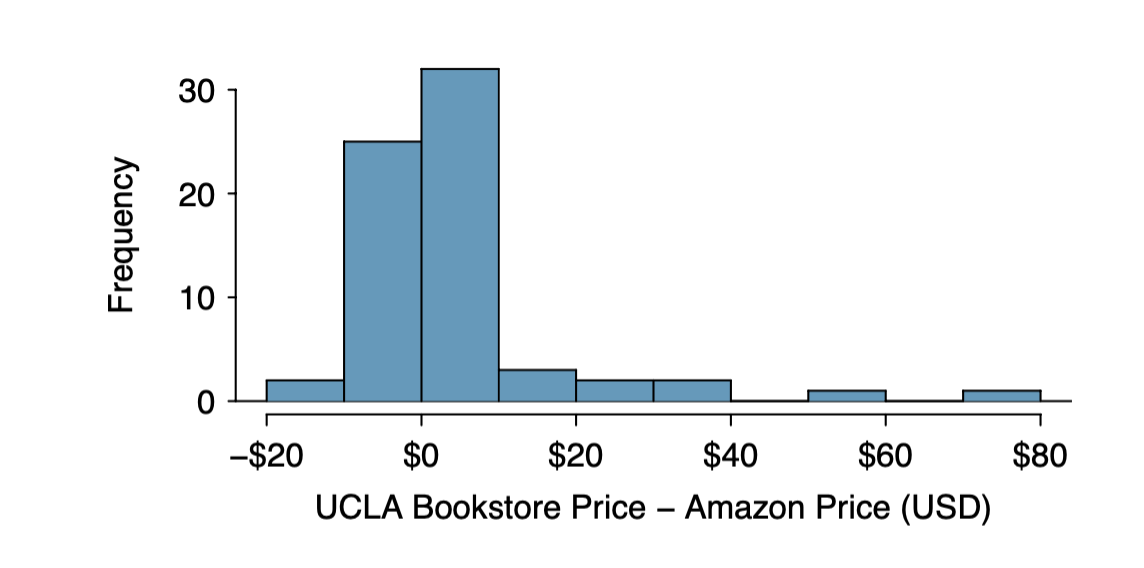
- Check 의 정규성 확인.(지난 글의 Rules of thumbs 참고) 표본 크기는 68로 충분히 크다. 극단적인 outlier가 있는지만 확인하면 된다. 아래 그림을 보면 표본 히스토그램에 극단값은 확인되지 않는다. 정규성 또한 만족하는 것으로 보인다.
이제 테스트를 할텐데 그 전에 가설을 세워보자. 귀무가설은 '학교 서점과 인터넷 서점의 도서 가격 차이가 없다' 대립 가설은 '차이가 있다' 이다. 수식으로 표현해보자.
표준오차는 아래와 같이 계산할 수 있다.
null 조건에서 T-score을 구해보자.
이제 이 값을 구글 스프레드 시트의 TDIST 함수에 넣어보자.
TDIST(x, degrees_freedom, tails)
TDIST(2.200, 67, 2)p값 0.0313 을 출력한다. 0.05보다 작기 때문에 귀무가설을 기각한다. 아마존의 교재 가격이 더 저렴했다는 이야기다.
그럼 95% 신뢰구간을 구해보자. 구글 스프레드 시트의 TINV 함수를 이용하면 된다.
TINV(probability, degrees_freedom)
TINV(0.05, 67)z값 약 2.000을 출력한다. 신뢰구간을 계산하면 아래와 같다.
