OpenIntro Statistics 4th Edition
Chater 7. Inference for numerical data를 바탕으로 작성했습니다.
묶음 글
1. One-sample mean with the t-distribution
2. Paired data
3. Difference of two means(현재글)
지난번에는 쌍을 이루는 데이터로 T테스트도 해보고 신뢰구간도 구해봤다. 이번에는 쌍을 이루지 않는 두 분포의 표본평균을 비교해본다.
쌍을 이룬 데이터(paired data)보다 더 다양한 경우에 사용할 수 있다.
다음 프레임워크를 적용한다.
- Prepare 중요한 상황 정보를 확인한다. 필요하면 가설까지 세운다.
- Check 필요한 조건들이 충족되는지 확인한다.
- Calculate 표준오차를 찾고, 신뢰구간을 구성한다. 혹은 가설검정을 한다.
- Conclude 결론을 도출한다.
Confidence interval for a difference of mean
배아줄기세포(ESCs)를 이용한 처치가 심장 발작 이후 심장 기능 향상에 도움이 될까?
Prepare
아래 표는 심장 발작이 있는 양들에게 ESCs를 실험한 결과를 요약한 것이다.
- 각 양은 무작위로 ESC 또는 통제 그룹으로 배분됐다.
- 처치 이후의 심장 펌프 용량을 측정했다.
- 가 음수인 경우는 이전보다 용량이 줄어든 것이고 양수면 늘어난 것이다.
95% 신뢰구간을 구해보자.

Check
데이터는 준비했으니 조건을 확인해보자. t-분포를 이용해서 모델링 하려면 데이터 독립성과 정규성을 확인해야 한다.
- 독립성(확장) 데이터는 두 그룹 내부에서, 사이에서 모두 독립적이어야 한다. 데이터가 독립적인 무작위 표본이나 무작위 실험에서 나온 경우 등이 있다.
- 정규성 outliers rules of thumb을 각각의 그룹에서 확인한다.
outliers rules of thumb에서는 눈에 띄는 outlier가 있는지 직접 확인해야 한다.
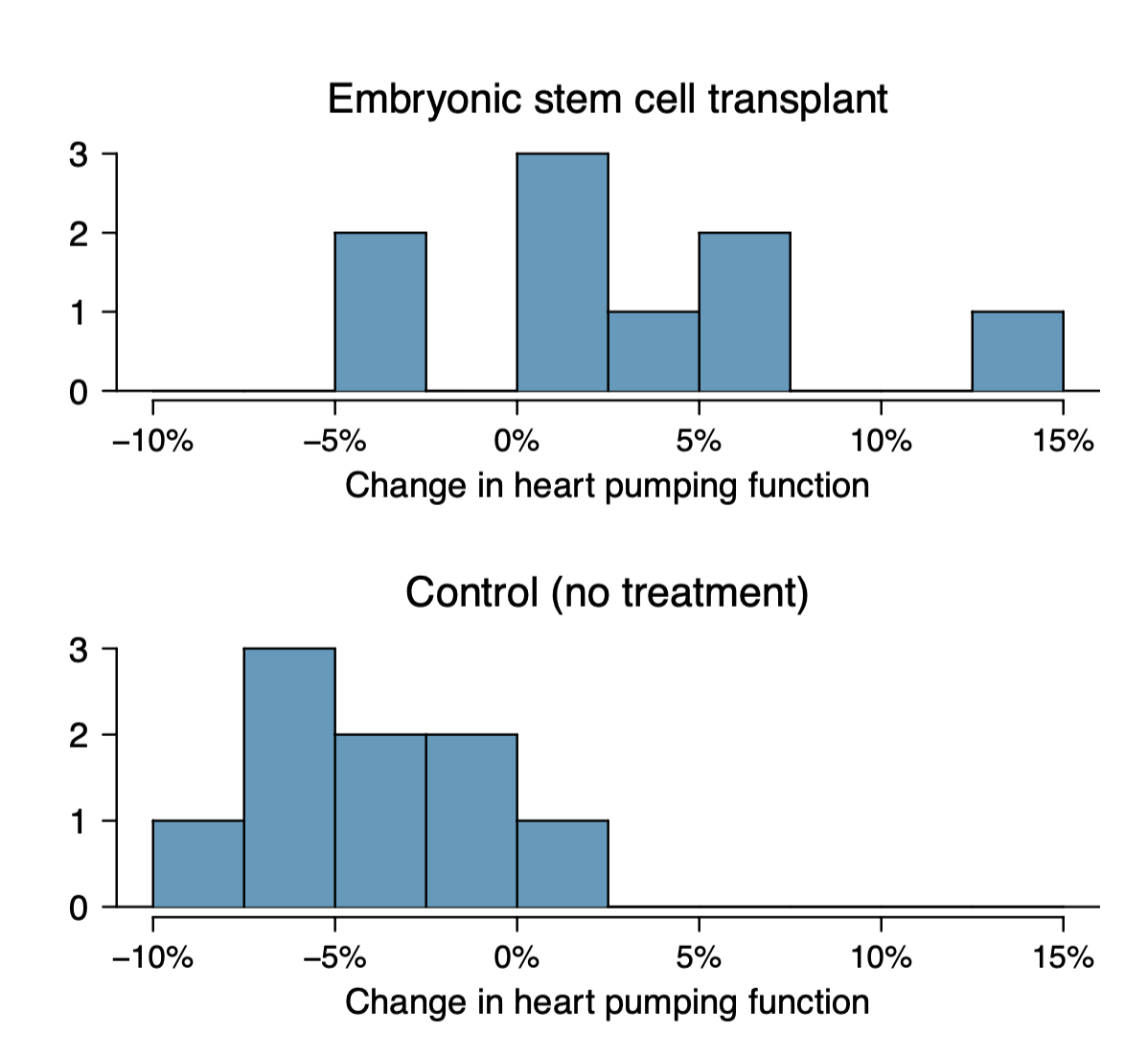
ESC 표본이 넓게 분포하긴 하지만 눈에 띄는 outlier는 없다.
Calculate
두 표본 평균의 차이는 아래 처럼 계산할 수 있다.
표준오차 계산식은 아래와 같다.
자유도 계산 공식은 매우 복잡해서 소프트웨어를 이용해 계산하는 것이 일반적이다. 달리 계산할 방법이 없다면 또는 중 작은 쪽을 선택할 수 있다. 여기서는 8로 한다.
95% 신뢰구간을 구해본다.
Conclude
심장 발작을 겪은 양을 배아줄기세포(ESC)로 치료하면 3.32% 에서 12.34%의 심장 펌핑 기능을 향상 효과를 얻을 수 있음을 95% 확률로 확신할 수 있다는 결론을 얻었다.
Hypothesis tests for the difference of two means
Prepare
산모의 흡연 여부, 산모의 몸무게 등을 조사한 데이터를 이용한다. 흡연 그룹은 50개, 비흡연 그룹은 100개의 표본을 조사했다. 이때 귀무가설은 '두 그룹 간 몸무게 차이는 없다' 이고 대립가설은 '몸무게차이가 있다' 이다. 흡연(smoking) 그룹의 평균은 로 비흡연(none-smoking) 그룹의 평균은 로 표기했다.
Check
임의 표본이기 때문에 독립성은 만족한다. 정규성은 두 그룹 각각의 표본수가 30을 넘기 때문에 명시적 oulier가 없는지만 확인하면 된다.
두 표분 그룹의 히스토그램은 아래와 같다.
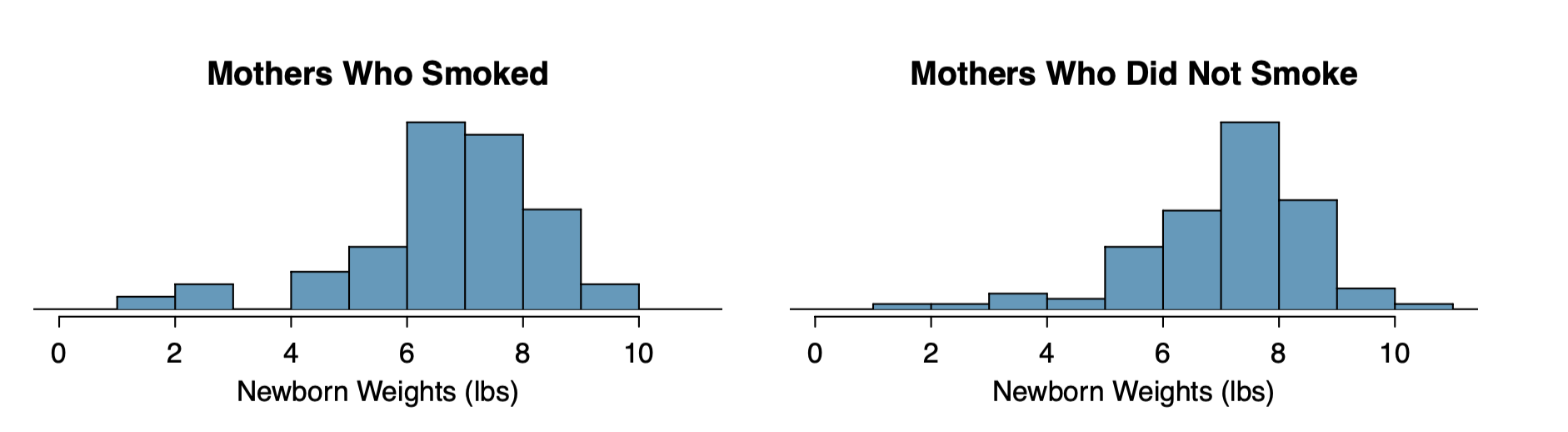
특별한 outlier는 없는 것으로 보인다. t-분포를 적용해볼 수 있겠다.
Calculate
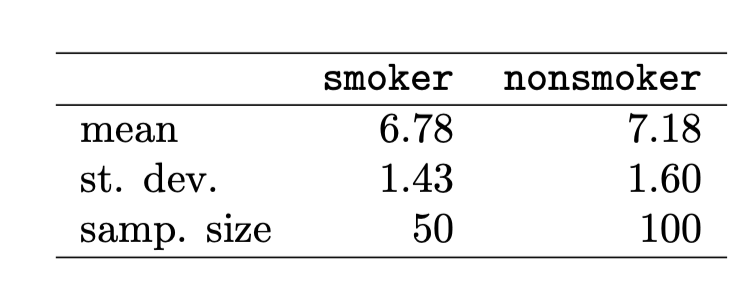
데이터 집계 결과는 위와 같다. 평균의 차이는 0.40, 표준 오차는 약 0.26이다.
가설 검정을 위한 null 분포는 아래와 같다. 이제 검정 통계값을 구해보자.
검정 통계값 약 1.55, 자유도 49로 계산한 p값은 0.13이다. 유의수준 0.05보다 크기 때문에 귀무가설을 기각하지 못한다.
95% 신뢰구간을 구해보자. 자유도 49의 95% 양꼬리 t값은 2.01이다.
0이 구간에 포함돼 있는 것을 확인 할 수 있다.
Conclude
따라서 임신 기간 흡연한 산모와 흡연을 하지 않은 산모간의 신생아 평균 몸무게 차이가 있다는 가설은 근거가 부족하다는 결론을 얻을 수 있다.
하지만 데이터를 보면 그럴지도 모른다는 의심이 들긴 한다. 표본 숫자를 더 확보할 수 있다면 다른 결론이 도출 될지도 모르겠다.
여기까지 우리는 t-분포에서 두 표본 그룹의 차이에 대해 신뢰구간을 구하고, 가설검정까지 해봤다. 무작정 계산부터 시작하는 것이 아니라 t-분포를 적용할 수 있을지부터 따져보고 계산하고 결과를 얻는 Prepare, Check, Calculate, Conclude 프레임워크를 적용해 봤다. 두 표본 차이를 계산하면 오차는 증폭된다. 전체 표본 오차를 구하기 위해 두 그룹의 표본 오차를 더해줬다. 두 표본을 이용하는 경우 자유도를 얻기 위해 매우 복잡한 계산을 해야 한다. 소프트웨어 등의 도움을 받을 수 없는 경우엔 둘 중에 표본이 작은 쪽을 기준으로 n-1 해도 괜찮다.
