한동안 일반(?) 프로그래밍을 하느라 정리할 시간이 없었다.
프로젝트 나가있는 알파는 좀 너무하다. 뭐 그건 차차 정리할 시간이 있겠지만, 암튼 너무하다 :)
요즘 핀(ai team) 에서 강좌 진행하기에 나도 예전 하던 것들을 정리해보고자 한다.
누군가의 먼저간 길이, 다른 누군가에게 도움이 되길 바라며.
- 환경가이드
- 도커 데스크탑
- python 3.x
를 설치한 개인 노트북
예전 스터디때 코랩(colab)도 써보고, 로컬 환경 구성도 해보고 이런 저런 구성을 해보았는데,
개인적으로 가장 효율적인 상황은 (매우 개인적인 관점이다),
개인 노트북에 , 도커를 설치하고 도커에 ollama를 설치한 후,
ollama에서 비교적 빌리언수가 적은 llm을 다운받아 적당히 타협하며 개발 테스트를 해보는 것이다.
매우 개인적인 사항이라 아니라고 한다면 당신 말이 옳다. :)
그래서,
앞으로의 스터디 내용을 위 환경으로 (doker desktop + ollama + qwen3 1.7B 구성으로 진행하려 한다)
음, 분명 다들, 1.7B는 그렇다. 나중에 RAG로 들어가면 8B 로 갈아치우겠다.

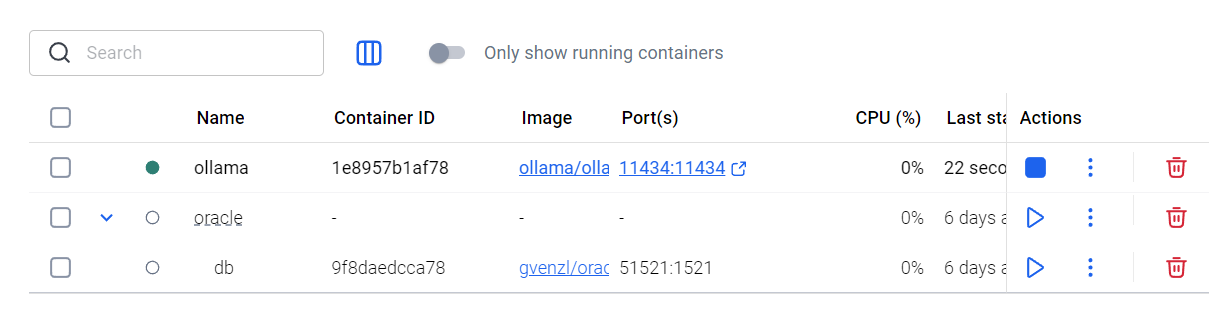
0-1. ollama docker 실행
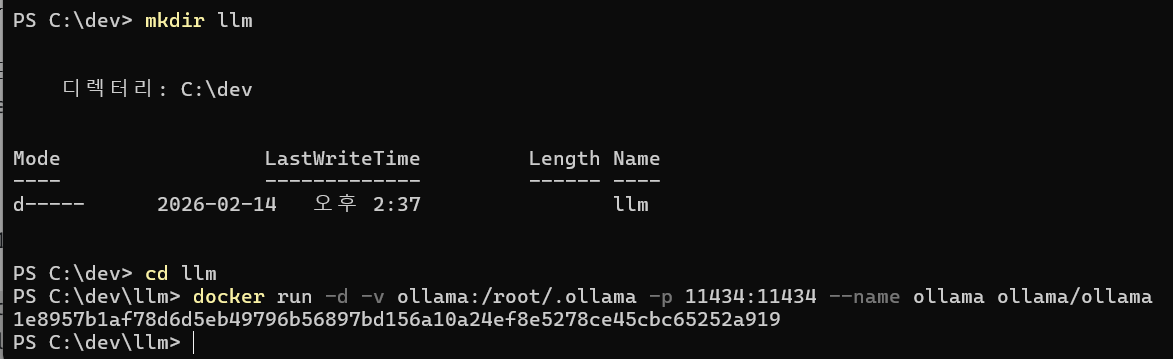
-- # Ollama Docker 실행
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
-- ollama run qwen3:1.7b
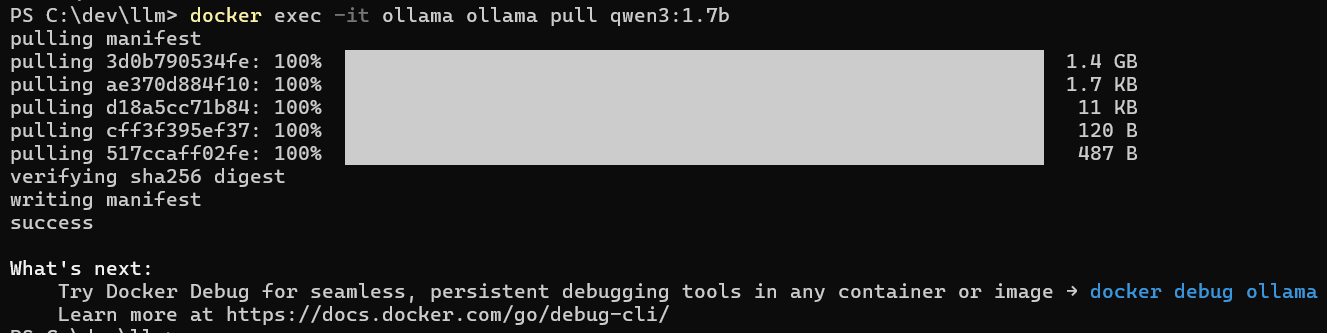
docker exec -it ollama ollama pull qwen3:1.7b
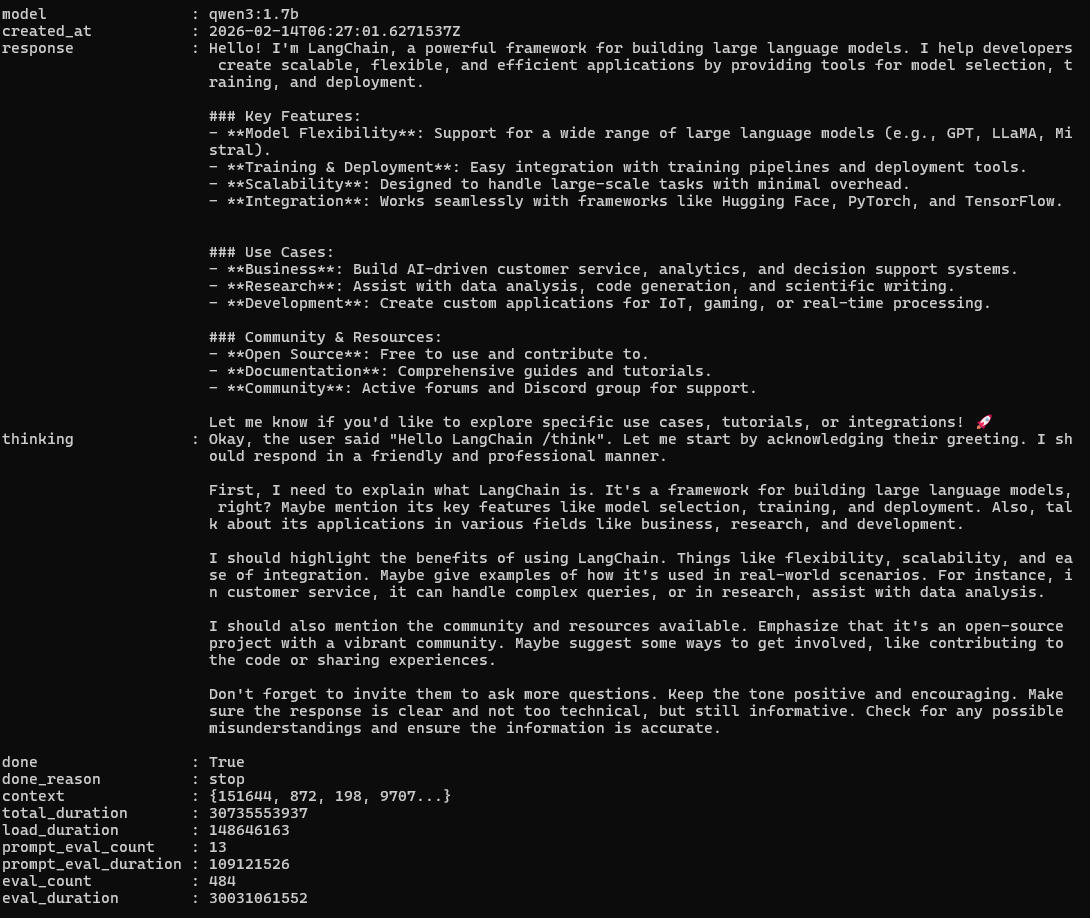
-- in powershell
(Invoke-WebRequest -Uri "http://localhost:11434/api/generate" `
-Method Post `
-ContentType "application/json" `
-Body '{"model":"qwen3:1.7b","prompt":"Hello LangChain","stream":false}').Content | ConvertFrom-Json
0-2. python 환경
--# 가상환경 생성
python -m venv llm_env
llm_env\Scripts\activate
--# 필수 패키지 설치
pip install langchain langchain-ollama python-dotenv jupyter

DONE!
무언가 무기를 다시 장착한 느낌이다. ready~ get set go~

LangChain 1.0 주요 Import 변경 사항
구버전(0.x) -> 신버전 (1.0)
from langchain.prompts import PromptTemplate -> from langchain_core.prompts import PromptTemplate
from langchain.prompts import ChatPromptTemplate -> from langchain_core.prompts import ChatPromptTemplate
from langchain.schema import HumanMessage -> from langchain_core.messages import HumanMessage
from langchain.output_parsers import StrOutputParser -> from langchain_core.output_parsers import StrOutputParser