AI가 이전 대화를 기억하고 맥락을 유지하는 방법
- LangChain 1.0의 메모리 관리 방식 이해
- ChatMessageHistory로 대화 저장하기
- RunnableWithMessageHistory로 체인에 메모리 통합
- 세션 기반 다중 사용자 관리
- 실전 컨텍스트 유지 챗봇 구현
4-1. 대화 메모리
# week4_01_no_memory.py
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen3:1.7b")
# 첫 번째 질문
response1 = llm.invoke("내 이름은 이우철이야")
print("AI:", response1)
# 두 번째 질문
response2 = llm.invoke("내 이름이 뭐였지?")
print("AI:", response2)
# 결과: AI가 이름을 기억하지 못함!
응답 :
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/4_!.no_memory.py
AI: 안녕하세요! 이우철님의 이름은 매우 예민한 문화적 의미를 담고 있어요. 아래에 이름의 구성과 의미를 간단히 설명드리겠습니다.
---
### 1. **이우철의 구성**
- **이** (이름의 부모 이름): 한국의 고유한 고유명이거나 가족 이름입니다.
- **우철** (이름):
- **우**는 "우"라는 철학적 의미를 지닌다.
- **철**는 "철"이라는 단어로, 한국어에서는 "철"은 강철, 강철의 특성(강한, 견고한)을 상징합니다.
---
### 2. **명의의 의미**
- **"철"**은 강철을 상징하며, **강한 정신, 견고한 성격, 끈질긴 결단**을 의미합니다.
- 이 이름은 **강철의 끈질긴 정신과 견고한 성품**을 암시하고 있어, 이름 자체가 **정신력과 투명성**을 강조하는 뜻으로 해석할 수 있습니다.
---
### 3. **문화적 맥락**
- 한국의 이름은 **성, 이름, 별명**의 순서로 구성되며, "이"는 가족 이름, "우철"은 개인 이름입니다.
- "철"은 한국어에서 **강철**의 의미로, **강한 정신, 견고한 성품**을 상징합니다.
---
### 4. **기타 고려 사항**
- 이 이름은 **명확하고 강한 인상**을 줄 수 있어, **정신력이 뛰어난 사람**을 상징할 수 있습니다.
- 한국의 많은 이름은 **성격을 암시**하는 경우가 많아, "철"은 **강한 정신, 결단력**을 나타냅니다.
---
### 5. **추가 도움**
- 이름의 **기본 발음**은 "이우철"이며, **자기소개**를 할 때는 **정신력과 견고한 성품**을 강조하는 표현이 좋아요.
- **nickname**은 "철"을 중심으로 "철수", "철철" 등이 가능합니다.
---
### 6. **질문 사항**
- 이름이 **어떤 심리적 특성**을 암시하는지 궁금하시다면, 저는 **추가 설명**을 드릴 수 있어요.
- 예를 들어, "철"이 강한 정신을 상징한다고 생각하시면, **정신력이 뛰어난 사람**을 상징하는 이름이라 생각할 수 있습니다.
---
이름이 **강한 정신과 견고한 성품**을 암시하는 뜻이므로, **정신력이 뛰어난 사람**을 상징하는 데 유리한 이름일 수 있습니다. 궁금한 점이 있다면 언제든지 물어보세요! 😊
AI: 죄송합니다. 제가 당신의 이름을 알아보기 위해 더 많은 정보를 필요로 합니다. 당신의 이름을 알려주시면 도와드릴 수 있어요! 😊
# 좀전에 말해주었는데 모름.아...수다쟁이...
- 해결책은...
대화를 메모리에 저장하고 메모리에서 검색해서 사용하는것.4-2. ChatMessageHistory() - 전체 대화 저장
LangChain 1.0의 기본 메모리 저장소
예제 1- 기본 사용법
# week4_02_chat_history_basic.py
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.messages import HumanMessage, AIMessage
# 메시지 히스토리 생성
history = ChatMessageHistory()
# 메시지 추가
history.add_user_message("내 이름은 이우철이야")
history.add_ai_message("안녕하세요, 이우철님!")
history.add_user_message("내가 좋아하는 색은 보라색이야")
history.add_ai_message("보라색을 좋아하시는군요!")
# 저장된 메시지 확인
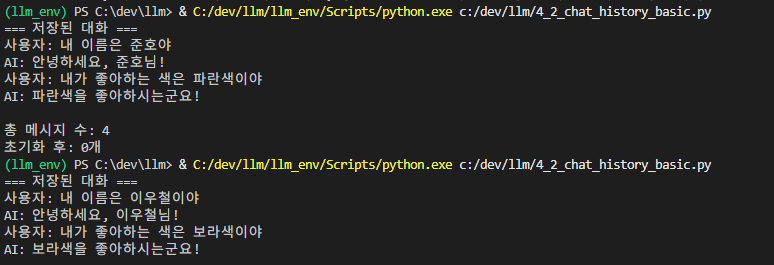
print("=== 저장된 대화 ===")
for msg in history.messages:
if isinstance(msg, HumanMessage):
print(f"사용자: {msg.content}")
elif isinstance(msg, AIMessage):
print(f"AI: {msg.content}")
# 전체 메시지 수
print(f"\n총 메시지 수: {len(history.messages)}")
# 메시지 초기화
history.clear()
print(f"초기화 후: {len(history.messages)}개")
예제 -2. 확장
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_ollama import OllamaLLM
# 1. 모델 설정
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.7)
# 2. 대화 기록 저장소 생성 (ConversationBufferMemory의 최신 대안)
history = ChatMessageHistory()
# 3. 프롬프트 템플릿 설정
prompt = ChatPromptTemplate.from_messages([
("system", "당신은 친절한 AI 어시스턴트입니다."),
MessagesPlaceholder(variable_name="chat_history"), # 대화 기록이 들어갈 자리
("human", "{input}")
])
# 4. 대화 함수 정의
def chat(user_input):
# 체인 생성 (LCEL 방식)
chain = prompt | llm
# 실행 시 현재까지 저장된 history.messages를 전달
response = chain.invoke({
"chat_history": history.messages,
"input": user_input
})
# 대화 내용을 기록에 추가
history.add_user_message(user_input)
history.add_ai_message(response)
return response
# --- 대화 테스트 ---
print("=== 대화 시작 ===")
print("AI:", chat("내 이름은 이우철이야"))
print("AI:", chat("내가 좋아하는 색은 보라색이야"))
print("AI:", chat("내 이름과 좋아하는 색을 기억하니?"))
# 저장된 전체 기록 확인
print("\n=== 전체 기록 ===")
print(history.messages)응담 :
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/4_2.buffer_memory_basic.py
=== 대화 시작 ===
AI: 안녕하세요! 저는 이우철님을 소개합니다. 도움을 요청하거나 질문이 있으면 언제든지问我吧! 😊
원하시는 도움이 있으시면 말씀해 주세요!
AI: 안녕하세요! 보라색을 좋아하시네요~ 이색적인 색감이 매력스러워요! 평소에 보라색을 어떻게 사용하시나요? 예를 들어 일상에서의 활용법이나 특별한 이유가 있나요? 도움이 필요하면 언제든지 말해주세요! 😊
=== 전체 기록 ===
[HumanMessage(content='내 이름은 이우철야', additional_kwargs={}, response_metadata={}), AIMessage(content='안녕하세요! 저는 이우철님을 소개합니다. 도움을 요청하거나 질문이 있으 면 언제든지问我吧! 😊 \n원하시는 도움이 있으시면 말씀해 주세요!', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]), HumanMessage(content='내가 좋아하는 색은 보라색이야', additional_kwargs={}, response_metadata={}), AIMessage(content='안녕하세요! 보라색을 좋아하시네요~ 이색적인 색감이 매력스러워요! 평소에 보라색을 어떻게 사용하시나요? 예를 들어 일상에서의 활용법이나 특별한 이유가 있나요? 도움이 필요하면 언제든지 말해주세요! 😊', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[]), HumanMessage(content='내 이름과 좋아하는 색을 기억하니?', additional_kwargs={}, response_metadata={}), AIMessage(content='안녕하세요! 이름은 이우철이구요, 보라색 을 좋아하시네요~ 이색적인 색감이 매력스럽습니다! 평소에 보라색을 어떻게 사용하시나요? 예를 들어 일상에서의 활용법이나 특별한 이유가 있나요? 도움이 필요하면 언제든지 말해주세요! 😊', additional_kwargs={}, response_metadata={}, tool_calls=[], invalid_tool_calls=[])]예제3- 다양한 메세지 타입
# week4_03_message_types.py
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.messages import HumanMessage, AIMessage, SystemMessage
history = ChatMessageHistory()
# System 메시지 (AI의 행동 지침)
history.add_message(SystemMessage(content="당신은 친절한 선생님입니다."))
# 대화 추가
history.add_user_message("Python이 뭐예요?")
history.add_ai_message("Python은 배우기 쉬운 프로그래밍 언어예요.")
history.add_user_message("어디에 쓰이나요?")
history.add_ai_message("웹 개발, 데이터 분석, AI 등 다양한 곳에 쓰입니다.")
# 메시지 타입별 확인
print("=== 메시지 타입별 출력 ===")
for msg in history.messages:
msg_type = msg.__class__.__name__
print(f"[{msg_type}] {msg.content}") 
4-3. 3. RunnableWithMessageHistory - 체인에 메모리 통합
LCEL 체인과 메시지 히스토리를 연결하는 핵심 클래스
예제 4- 기본 메모리 통합
# week4_04_runnable_with_history.py
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.7)
# 프롬프트 (메시지 히스토리 placeholder 포함)
prompt = ChatPromptTemplate.from_messages([
("system", "당신은 친절한 AI 어시스턴트입니다."),
MessagesPlaceholder(variable_name="chat_history"), # 대화 기록
("human", "{input}")
])
# LCEL 체인
chain = prompt | llm
# 메모리 저장소 (인메모리)
memory = ChatMessageHistory()
def get_session_history():
return memory
# 메모리가 통합된 체인
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history"
)
# 대화 시작
print("=== 대화 1 ===")
response1 = chain_with_history.invoke(
{"input": "내 이름은 이우철이야"},
config={"configurable": {"session_id": "default"}}
)
print(f"AI: {response1}\n")
print("=== 대화 2 ===")
response2 = chain_with_history.invoke(
{"input": "내가 좋아하는 음식은 자장면이야"},
config={"configurable": {"session_id": "default"}}
)
print(f"AI: {response2}\n")
print("=== 대화 3 (기억 테스트) ===")
response3 = chain_with_history.invoke(
{"input": "내 이름과 좋아하는 음식이 뭐였지?"},
config={"configurable": {"session_id": "default"}}
)
print(f"AI: {response3}\n")
# 저장된 메시지 확인
print("=== 저장된 대화 기록 ===")
for msg in memory.messages:
print(f"{msg.__class__.__name__}: {msg.content}")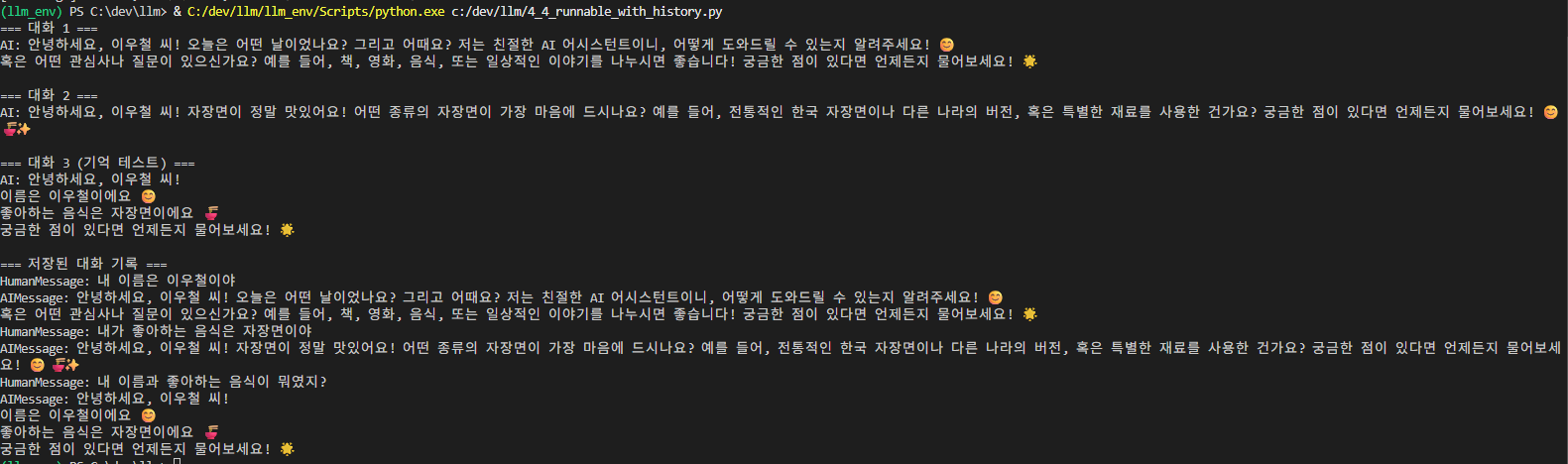
예제5- 세션별 메모리 관리
# week4_05_session_management.py
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.7)
prompt = ChatPromptTemplate.from_messages([
("system", "당신은 친절한 AI입니다."),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
chain = prompt | llm
# 세션별 메모리 저장소
session_store = {}
def get_session_history(session_id: str):
"""세션 ID별로 독립적인 메모리 반환"""
if session_id not in session_store:
session_store[session_id] = ChatMessageHistory()
return session_store[session_id]
# 메모리가 통합된 체인
chain_with_history = RunnableWithMessageHistory(
chain,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history"
)
# 사용자 A (세션 1)
print("=== 사용자 A ===")
config_a = {"configurable": {"session_id": "user_a"}}
response_a1 = chain_with_history.invoke(
{"input": "내 이름은 이우철이야"},
config=config_a
)
print(f"AI: {response_a1}")
# 사용자 B (세션 2)
print("\n=== 사용자 B ===")
config_b = {"configurable": {"session_id": "user_b"}}
response_b1 = chain_with_history.invoke(
{"input": "내 이름은 찰스야"},
config=config_b
)
print(f"AI: {response_b1}")
# 다시 사용자 A
print("\n=== 사용자 A (다시) ===")
response_a2 = chain_with_history.invoke(
{"input": "내 이름이 뭐였지?"},
config=config_a
)
print(f"AI: {response_a2}")
# 다시 사용자 B
print("\n=== 사용자 B (다시) ===")
response_b2 = chain_with_history.invoke(
{"input": "내 이름이 뭐였지?"},
config=config_b
)
print(f"AI: {response_b2}")
# 세션별 메시지 수 확인
print(f"\n사용자 A 메시지 수: {len(session_store['user_a'].messages)}")
print(f"사용자 B 메시지 수: {len(session_store['user_b'].messages)}")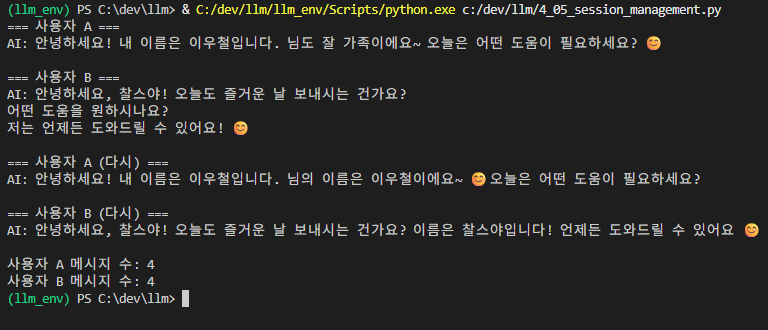
4-5 실전예제 - 컨텍스트 유지 챗봇
# week4_06_personal_assistant.py
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.7)
# 비서 전용 프롬프트
prompt = ChatPromptTemplate.from_messages([
("system", """당신은 이웇러님의 개인 비서인 자비스입니다.
역할:
- 일정, 할 일, 메모를 기억합니다
- 사용자가 물어보면 저장된 정보를 정확히 전달합니다
- 정중하고 간결하게 답변합니다"""),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
chain = prompt | llm
# 메모리
memory_store = {}
def get_memory(session_id: str):
if session_id not in memory_store:
memory_store[session_id] = ChatMessageHistory()
return memory_store[session_id]
chain_with_memory = RunnableWithMessageHistory(
chain,
get_memory,
input_messages_key="input",
history_messages_key="chat_history"
)
# 비서 함수
def assistant(user_input, session_id="default"):
config = {"configurable": {"session_id": session_id}}
response = chain_with_memory.invoke({"input": user_input}, config=config)
return response
# 테스트 시나리오
print("=== 개인 비서 챗봇 ===\n")
scenarios = [
"내일 오전 10시에 팀 회의가 있어",
"회의 주제는 1분기 실적 리뷰야",
"참석자는 김팀장, 백대리, 박사원이야",
"오후 3시에 고객사 미팅이 외부에 있어",
"내일 일정을 정리해줘"
]
for i, user_msg in enumerate(scenarios, 1):
print(f"[{i}] 사용자: {user_msg}")
response = assistant(user_msg)
print(f" 비서: {response}\n")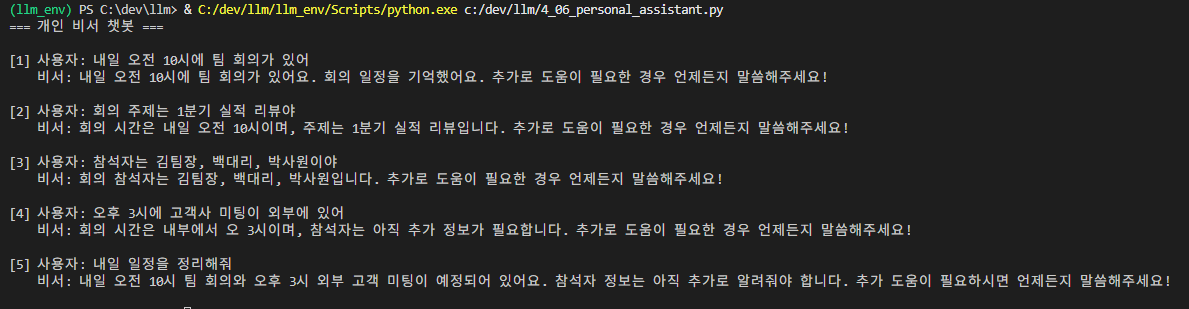
- 예제 7 : 고객 상담 챗봇
# week4_07_customer_support.py
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.6)
# 고객 상담 프롬프트
prompt = ChatPromptTemplate.from_messages([
("system", """당신은 KT알파 쇼핑몰의 고객 상담사입니다.
상담 원칙:
1. 고객의 이전 문의를 기억하고 연결하여 답변
2. 정중하고 친절한 말투
3. 구체적이고 실용적인 해결책 제시
4. 고객의 선호도와 요구사항을 파악하여 맞춤 추천"""),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
chain = prompt | llm
# 고객별 메모리
customer_sessions = {}
def get_customer_history(customer_id: str):
if customer_id not in customer_sessions:
customer_sessions[customer_id] = ChatMessageHistory()
return customer_sessions[customer_id]
support_chain = RunnableWithMessageHistory(
chain,
get_customer_history,
input_messages_key="input",
history_messages_key="chat_history"
)
# 고객 상담 시뮬레이션
def chat_with_customer(customer_id, message):
config = {"configurable": {"session_id": customer_id}}
return support_chain.invoke({"input": message}, config=config)
# 시나리오
print("=== 고객 상담 시나리오 ===\n")
customer_id = "customer_001"
conversations = [
"노트북을 구매하려고 합니다",
"주로 영상 편집 작업을 할 예정이에요",
"예산은 200만원 정도입니다",
"추천해주신 제품의 배송 기간은 얼마나 되나요?",
"좋아요, 그럼 제가 말한 용도와 예산에 맞는 제품으로 주문하겠습니다"
]
for i, msg in enumerate(conversations, 1):
print(f"[대화 {i}]")
print(f"고객: {msg}")
response = chat_with_customer(customer_id, msg)
print(f"상담사: {response}\n")
print("-" * 70)응답 :
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/4_07_customer_support.py
=== 고객 상담 시나리오 ===
[대화 1]
고객: 노트북을 구매하려고 합니다
상담사: 안녕하세요! KT알파 쇼핑몰의 고객 상담사입니다.
제가 고객님의 요청을 기억해 두고, 더 맞춤형한 도움을 드릴 수 있도록 아래에 문의 내용을 정리해 드리겠습니다.
**문의 내용 정리:**
- **구매 목적:** 노트북 구매
- **현재 상태:** 처음 문의
- **요청사항:** 구체적인 정보 수집 후 맞춤 추천
**추가 정보를 알려주시면 더 나은 서비스를 제공해 드리겠습니다.**
1. **예산 범위:** 100만 ~ 500만 원 범위로 구매하시나요?
2. **관심 기능/특징:** 풀HD 레이트, 게임용 GPU, 높은 터치 성능, 태블릿 기능 등?
3. **사용 목적:** 업무용, 게임용, 창작용 등?
4. **관심 브랜드:** 삼성, 애플, 레노버, 디스플레이 기업 등?
5. **기타 요구사항:** 키보드 타이핑 속도, 배터리 수명, 무결성 등?
이해 부족한 점이 있으면 언제든지 말씀해 주세요! 📞
----------------------------------------------------------------------
[대화 2]
고객: 주로 영상 편집 작업을 할 예정이에요
상담사: 안녕하세요! 영상 편집 작업을 위해 노트북을 구매하시려는 점을 잘 알고 있습니다. 아래에 영상 편집에 유리한 특징을 참고해 드릴 수 있는 정보를 추가해 드리겠습니다.
**추가 정보를 알려주시면 더 맞춤형 추천을 드릴 수 있습니다.**
1. **예산 범위:** 100만 ~ 500만 원 범위로 구매하시나요?
2. **관심 기능/특징:**
- 풀HD 레이트 또는 4K 해상도
- 고성능 GPU(그래픽 처리가 필요한 작업을 위해)
- 터치 스크린 또는 높은 키보드 타이핑 속도
- 배터리 수명(장시간 작업에 유리)
- 무결성(편집 작업 중 키보드 터치나 터치 스크린 사용 시 유용)
3. **사용 목적:**
- 업무용(프로젝트 편집, 편집 소프트웨어 사용)
- 게임용(게임 편집, 편집 소프트웨어 사용)
- 창작용(영상 편집, 편집 소프트웨어 사용)
4. **관심 브랜드:**
- 삼성, 애플, 레노버, 디스플레이 기업 등
5. **기타 요구사항:**
- 무결성, 키보드 타이핑 속도, 배터리 수명 등
추가적으로 어떤 특정 기능이나 브랜드를 선호하시면 더 구체적인 추천을 드릴 수 있습니다. 필요하시면 언제든지 말씀해 주세요! 📞
----------------------------------------------------------------------
[대화 3]
고객: 예산은 200만원 정도입니다
상담사: 안녕하세요! 200만 원 수준의 예산으로 영상 편집 작업을 위해 고성능 노트북을 구매하시고자 합니다. 아래에 추천하는 모델과 관련된 정보를 정리해 드릴게요.
---
### **추천 노트북 모델 및 특징**
1. **삼성전자**
- **모델**: 14인치 4K 2000 (예: 2023년 라이트 프로)
- **특징**:
- 4K 해상도, 고성능 GPU, 터치 스크린, 무결성 기능
- 빠른 키보드 타이핑 속도, 장시간 사용에도 긴 배터리 수명
- 가벼운 무게(1.5kg 미만)로 편리하게 이동 가능
- **추천 이유**: 영상 편집에 최적화된 성능과 가벼운 무게, 터치 스크린 활용성
- **추가 고려사항**: 키보드 타이핑 속도, 배터리 수명, 무결성
2. **레노버**
- **모델**: 15.6인치 4K 2000 (예: 2023년 라이트 프로)
- **특징**:
- 4K 해상도, 고성능 GPU, 무결성 기능, 빠른 키보드 타이핑
- 흔들림 방지 설계, 빠른 성능
- **추천 이유**: 키보드 타이핑 속도와 무결성, 편리한 사용성
3. **애플**
- **모델**: MacBook Pro 14인치 4K (예: 2023년 모델)
- **특징**:
- 고성능 GPU, 터치 스크린, 무결성 기능
- 빠른 성능, 편리한 디자인
- **추천 이유**: 영상 편집에 최적화된 성능, 뛰어난 무결성, 편리한 디자인
---
### **추가 고려 사항**
- **사용 목적**: 업무용(프로젝트 편집, 편집 소프트웨어 사용) 또는 창작용(영상 편집, 편집 소프트웨어 사용)에 따라 모델 선택
- **배터리 수명**: 장시간 작업에 유리한 모델(예: 12시간 이상)
- **무결성**: 키보드 타이핑 속도와 터치 스크린 사용 시 유용
---
### **추천 모델 예시**
1. **삼성전자 14인치 4K 2000**
- **특징**: 4K 해상도, 고성능 GPU, 무결성 기능
- **장점**: 편리한 무게, 빠른 키보드 타이핑
- **단점**: 높은 가격
2. **레노버 15.6인치 4K 2000**
- **특징**: 터치 스크린, 빠른 성능
- **장점**: 무결성, 편리한 디자인
- **단점**: 키보드 타이핑 속도
3. **애플 MacBook Pro 14인치 4K**
- **특징**: 고성능 GPU, 무결성 기능
- **장점**: 뛰어난 성능, 편리한 디자인
- **단점**: 가격 상승
---
### **추가 문의사항**
- **관심 브랜드**: 삼성, 레노버, 애플 중 어떤 브랜드를 선호하시나요?
- **특정 기능**: 터치 스크린, 무결성, 배터리 수명 등 구체적으로 원하시면 알려주세요!
더 나은 추천을 위해 추가 정보를 알려주시면 감사하겠습니다! 📞
----------------------------------------------------------------------
[대화 4]
고객: 추천해주신 제품의 배송 기간은 얼마나 되나요?
상담사: 안녕하세요! 추천한 노트북 모델의 배송 기간은 다음과 같이 일반적인 시간을 알려드릴 수 있습니다:
- **삼성전자**: 3~7일(정품 배송, 주문 후 3~7일 소요)
- **레노버**: 3~7일(정품 배송, 주문 후 3~7일 소요)
- **애플**: 3~7일(정품 배송, 주문 후 3~7일 소요)
이 외에도 구체적인 배송 일정은 제품의 상세 정보와 주문 플랫폼에 따라 달라질 수 있습니다.
추천 모델을 더 구체적으로 선택하시면, 해당 모델의 배송 일정과 추가 정보를 알려드리겠습니다!
**추천 모델을 선택하시면 더욱 정확한 정보를 제공해 드릴 수 있습니다.**
- **관심 브랜드**: 삼성, 레노버, 애플 중 어떤 브랜드를 선호하시나요?
- **특정 기능**: 터치 스크린, 무결성, 배터리 수명 등 구체적으로 원하시면 알려주세요!
원하시면 언제든지 추가 정보를 알려주시면 감사드리겠습니다! 📞
----------------------------------------------------------------------
[대화 5]
고객: 좋아요, 그럼 제가 말한 용도와 예산에 맞는 제품으로 주문하겠습니다
상담사: 안녕하세요! 최적의 노트북 모델을 선택해 주셔서 감사합니다! 아래에 추천 모델 중 **200만 원 범위에 최적화된 선택**을 드릴 수 있습니다.
---
### **추천 모델 및 특징**
1. **삼성전자 14인치 4K 2000 (예: 2023년 라이트 프로)**
- **장점**:
- 4K 해상도, 고성능 GPU, 무결성 기능
- 빠른 키보드 타이핑 속도, 12시간 이상 배터리 수명
- 가벼운 무게(1.5kg 미만)로 편리한 이동
- **단점**: 고성능 GPU가 포함되어 비용이 상승
2. **레노버 15.6인치 4K 2000 (예: 2023년 라이트 프로)**
- **장점**:
- 터치 스크린, 빠른 성능, 무결성 기능
- 흔들림 방지 설계, 빠른 키보드 타이핑
- **단점**: 배터리 수명이 비교적 짧음
3. **애플 MacBook Pro 14인치 4K (2023년 모델)**
- **장점**:
- 고성능 GPU, 무결성 기능, 뛰어난 성능
- 편리한 디자인, 높은 무결성
- **단점**: 고가 제품으로 200만 원 범위에 맞는 제품이 아님
---
### **추천 이유**
- **200만 원 범위**: 레노버의 15.6인치 모델은 터치 스크린과 무결성 기능, 빠른 키보드 타이핑 속도가 조화로워 실제 작업에 유리합니다.
- **배터리 수명**: 12시간 이상 사용 가능하며, 영상 편집 작업에 최적화된 설계입니다.
---
### **추가 문의**
- **관심 브랜드**: 레노버가 가장 적합한 모델이 드물 수 있으니, 선택해 주세요!
- **특정 기능**: 무결성, 터치 스크린, 배터리 수명 등 추가 원하시면 알려주세요!
원하시면 **레노버 15.6인치 4K 2000**을 선택해 주세요! 📞
이후에 해당 모델의 배송 일정과 상세 정보를 알려드리겠습니다!- 예제 8 : 학습도우미 챗봇
# week4_08_study_assistant.py
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.7)
prompt = ChatPromptTemplate.from_messages([
("system", """당신은 학습 도우미 AI입니다.
역할:
- 사용자가 공부한 내용을 기억합니다
- 학습 진도를 추적합니다
- 복습이 필요한 내용을 상기시킵니다
- 격려와 피드백을 제공합니다"""),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
chain = prompt | llm
student_sessions = {}
def get_student_history(student_id: str):
if student_id not in student_sessions:
student_sessions[student_id] = ChatMessageHistory()
return student_sessions[student_id]
study_chain = RunnableWithMessageHistory(
chain,
get_student_history,
input_messages_key="input",
history_messages_key="chat_history"
)
def study_with_ai(student_id, message):
config = {"configurable": {"session_id": student_id}}
return study_chain.invoke({"input": message}, config=config)
# 학습 시나리오
print("=== 학습 도우미 챗봇 ===\n")
student = "student_jun"
study_log = [
"오늘 Python 리스트에 대해 공부했어",
"append, extend, insert 메소드를 배웠어",
"내일은 딕셔너리를 공부할 예정이야",
"오늘 뭐 공부했었지?",
"내일 공부할 주제도 알려줘"
]
for i, msg in enumerate(study_log, 1):
print(f"[{i}] 학생: {msg}")
response = study_with_ai(student, msg)
print(f" AI: {response}\n")응답 :
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/4_08_study_assistant.py
=== 학습 도우미 챗봇 ===
[1] 학생: 오늘 Python 리스트에 대해 공부했어
AI: 안녕하세요! 오늘 Python의 리스트에 대해 공부한 내용을 기억하고 있습니다. 아래는 학습 내용의 요약과 추가적인 도움이 필요할 경우 제공할 수 있는 정보입니다:
---
### 📌 학습 내용 요약
1. **리스트의 특징**
- **순서가 있는 자료형** (순서가 유지됨)
- **변형 가능** (값을 추가/삭제/수정 가능)
- **다양한 데이터 타입 지원** (정수, 문자열, boolean, 객체 등)
- **리스트는 괄호로 묶어짐** (예: `[1, 2, 3]`)
2. **핵심 기능**
- **인덱싱** (리스트의 특정 위치에 위치한 요소를 가져오기)
- 예: `my_list[0]` → 리스트의 첫 요소 가져오기
- **이ндекс링** (리스트의 특정 위치에 요소를 삽입/삭제)
- `my_list.insert(index, value)`
- **추가/삭제**
- `my_list.append(value)` → 마지막 요소 추가
- `my_list.pop(index)` → 특정 위치의 요소 제거
- `my_list.remove(value)` → 값 대체 (첫 번째 발생되는 요소 제거)
- **리스트의 길이**
- `len(my_list)` → 요소 수 확인
3. **기본적인 연산**
- **합치기**
- `my_list1 + my_list2` → 두 리스트 합치기
- `my_list * 2` → 리스트의 요소를 두 번 반복
- **리스트의 요소 접근**
- `my_list[0:3]` → 0부터 3-1 번째 요소까지 (포함)
- `my_list[::2]` → 0, 2, 4... 순서로 요소 추출
4. **실용적인 예제**
- `numbers = [1, 2, 3, 4, 5]`
- `numbers[2]` → 3
- `numbers.append(6)` → [1, 2, 3, 4, 5, 6]
- `numbers.pop(0)` → 1 제거 → [2, 3, 4, 5]
---
### 🧠 도움 요청
- **복습이 필요한 부분**:
- 리스트의 순서와 인덱싱
- `append` vs `insert`의 차이
- 리스트의 연산 (합치기, 반복)
- **문제 풀이**:
- 리스트의 요소를 특정 위치에 삽입하는 코드 작성
- 리스트의 길이를 확인하는 코드 작성
---
### 💡 피드백
- **이해도 못한 부분**:
- `list comprehensions` (예: `[x**2 for x in range(5)]`)
- `sorted()` 함수의 사용 방법
- **성장 포인트**:
- 리스트는 다른 자료형(튜플, 딕셔너리)과의 혼합 사용 가능
- 리스트의 요소를 다른 구조로 변환(예: `tuple()`로 변환)
---
### 📝 주의 사항
- **리스트는 순서에 따라 데이터가 변형됨** (예: `my_list = [3, 1, 2]` → `my_list[0] = 1` → `[1, 1, 2]`)
- **리스트의 요소는 변경 가능** (예: `my_list[0] = 10` → 요소 변경)
---
학습 도우미로 도와드릴 수 있어요! 추가로 궁금한 점이 있으면 언제든지 물어보세요. 😊
[2] 학생: append, extend, insert 메소드를 배웠어
AI: 안녕하세요! `append`, `extend`, `insert` 메소드를 잘 이해했어요! 아래는 실제 활용 예제와 주의 사항을 정리해 드리겠습니다.
---
### 🧩 주요 메소드 요약
| 메소드 | 기능 | 설명 |
|--------|------|------|
| **`append(value)`** | | 마지막 요소에 `value`를 추가합니다. |
| **`extend(iterable)`** | | `iterable`에 있는 요소들을 리스트에 차례로 추가합니다. |
| **`insert(index, value)`** | | `index` 위치에 `value`를 삽입합니다. |
| **`pop(index)`** | | 특정 위치의 요소를 제거하고 반환합니다. |
| **`remove(value)`** | | `value`를 찾아 제거합니다. |
---
### 📌 실무 활용 예제1. append
numbers = [1, 2, 3]
numbers.append(4) # [1, 2, 3, 4]2. extend
numbers = [1, 2, 3]
numbers.extend([4, 5]) # [1, 2, 3, 4, 5]3. insert
numbers = [1, 2, 4]
numbers.insert(2, 3) # [1, 2, 3, 4]### 🚩 주의 사항
- **`append`**은 리스트의 끝에 요소를 추가하므로, `insert`보다 더 간단합니다.
- **`extend`**은 다른 리스트의 요소들을 차례로 추가하므로, `append`보다 다수 요소를 추가하는 데 적합합니다.
- **`insert`**은 인덱스를 전달해야 하며, 인덱스가 범위를 벗어나면 오류가 발생할 수 있습니다.
---
### 🧠 도움 요청
- **실전 활용**:
- `extend([1, 2, 3])`을 사용해 여러 요소를 한 번에 추가하려면?
- `insert(2, 5)`을 사용해 특정 위치에 5를 삽입하려면?
- **문제 풀이**:
- `numbers = [1, 3, 5]` → `numbers.insert(1, 2)` → `[1, 2, 3, 5]`
- `numbers = [1, 2, 3]` → `numbers.extend([4, 5])` → `[1, 2, 3, 4, 5]`
---
학습 도우미로 도와드릴 수 있어요! 추가로 궁금한 점이 있으면 언제든지 물어보세요. 😊
[3] 학생: 내일은 딕셔너리를 공부할 예정이야
AI: 안녕하세요! 딕셔너리를 공부해요! 아래는 학습 내용의 요약과 주의 사항입니다:
---
### 📌 학습 내용 요약
1. **딕셔너리의 특징**
- **순서가 없는 자료형** (키에 따라 순서가 결정됨)
- **변형 가능** (키와 값 변경 가능)
- **키와 값의 짝이 필요** (예: `{ 'name': 'Alice', 'age': 25 }`)
- **키는 고유 값** (두 키는 같은 값이면 오류 발생)
2. **핵심 기능**
- **키 접근** (값을 가져오기)
- `dictionary[key]`
- **키 추가/변경/삭제**
- `dictionary[key] = value` (값 바꾸기)
- `dictionary.pop(key)` (키 제거)
- `dictionary.get(key, default)` (키 없을 때 기본값 반환)
- **키의 수**
- `len(dictionary)` → 키 수 확인
3. **기본적인 연산**
- **합치기**
- `dict1 | dict2` → 두 딕셔너리 합치기
- **리스트 변환**
- `dict.keys()`, `dict.values()`, `dict.items()` → 키/값/키-값 리스트 반환
4. **실용적인 예제**
```python
person = {'name': 'Alice', 'age': 25, 'city': 'NY'}
print(person['name']) # Alice
person['job'] = 'Engineer' # 추가
person.pop('city') # 'NY' 삭제### 🧠 도움 요청
- **실전 활용**:
- `{'name': 'Bob', 'age': 30}.get('age')` → 30
- `{'a': 1, 'b': 2}.update({'b': 3})` → {'a': 1, 'b': 3}
- **문제 풀이**:
- `{'fruit': 'apple', 'color': 'red'}` → `{'color': 'red', 'fruit': 'apple'}`
- `{'x': 10, 'y': 20}` → `{'x': 10, 'y': 20}`
---
### 💡 주의 사항
- **딕셔너리는 순서가 없음** (키의 순서가 변할 수 있음)
- **키는 중복 불가** (두 키가 같은 값이라면 오류 발생)
- **get()**은 키가 없을 때 기본값 반환, **pop()**은 키가 없을 때 오류 발생
---
학습 도우미로 도와드릴 수 있어요! 추가로 궁금한 점이 있으면 언제든지 물어보세요. 😊
[4] 학생: 오늘 뭐 공부했었지?
AI: 안녕하세요! 오늘은 Python의 **리스트**와 **딕셔너리** 두 주제를 공부했어요! 아래는 학습 내용의 요약과 주요 포인트입니다:
---
### 📌 학습 내용 요약
1. **리스트**
- **순서가 있음** (인덱싱 가능)
- **변형 가능** (append, insert, pop 등 기능)
- **예: [1, 2, 3]**
- **메소드**: `append()`, `extend()`, `insert()`
- **주의 사항**: 순서에 따라 데이터 변형 가능
2. **딕셔너리**
- **순서가 없음** (키에 따라 순서 결정)
- **변형 가능** (키와 값 변경 가능)
- **예: {'name': 'Alice', 'age': 25}'
- **메소드**: `get()`, `pop()`, `update()`
- **주의 사항**: 키 중복 불가, 순서 없음
---
### 🧠 핵심 포인트
- **리스트**는 순서가 유지되지만, 딕셔너리는 키의 순서가 변할 수 있음.
- **딕셔너리**는 키와 값의 짝이 필요하며, `get()`은 키 없을 때 기본값 반환.
- **실전 활용**:
- 리스트는 단일 요소 추가/삭제, 딕셔너리는 여러 요소 추가/삭제 가능.
- `update()`로 딕셔너리 값 갱신, `pop()`으로 특정 키 삭제.
---
### 📝 주의 사항
- **리스트**는 `append()`으로 끝에 요소 추가, `extend()`으로 여러 요소 추가.
- **딕셔너리**는 `get()`으로 키 없을 때 기본값 반환, `pop()`은 키 없을 때 오류 발생.
---
학습 도우미로 도와드릴 수 있어요! 오늘은 리스트와 딕셔너리의 차이점과 활용법을 잘 이해했어요! 추가로 궁금한 점이 있으면 언제든지 물어보세요. 😊예제 10 : 메모리관리
# week4_10_message_limit.py
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen3:1.7b")
# 최근 N개 메시지만 유지하는 함수
def trim_messages(messages, max_messages=10):
"""최근 max_messages개만 유지"""
if len(messages) > max_messages:
return messages[-max_messages:]
return messages
# 커스텀 히스토리 클래스
class LimitedChatHistory(ChatMessageHistory):
# Pydantic 필드로 미리 선언합니다.
max_messages: int = 10
def __init__(self, max_messages=10):
super().__init__()
self.max_messages = max_messages
def add_message(self, message):
super().add_message(message)
# 메시지 수 제한
if len(self.messages) > self.max_messages:
self.messages = self.messages[-self.max_messages:]
# 사용
limited_history = LimitedChatHistory(max_messages=6) # 최근 6개만
# 많은 메시지 추가
for i in range(10):
limited_history.add_user_message(f"메시지 {i}")
limited_history.add_ai_message(f"응답 {i}")
print(f"총 메시지 수: {len(limited_history.messages)}")
print("저장된 메시지:")
for msg in limited_history.messages:
print(f" - {msg.content}")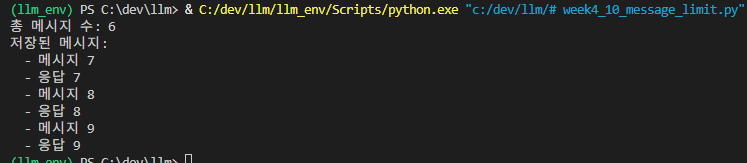
예제11 - 대화요약 기능
# week4_11_conversation_summary.py
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen3:1.7b", temperature=0.3)
# 대화 요약 프롬프트
summary_prompt = ChatPromptTemplate.from_messages([
("system", "다음 대화를 3문장 이내로 요약해주세요."),
("human", "{conversation}")
])
# 대화 히스토리
history = ChatMessageHistory()
# 대화 추가
conversations = [
("사용자", "나는 서울에 살아"),
("AI", "서울에 사시는군요!"),
("사용자", "직업은 개발자야"),
("AI", "개발자시군요."),
("사용자", "Python을 주로 써"),
("AI", "Python 좋죠!"),
("사용자", "요즘 LangChain 공부 중이야"),
("AI", "좋은 선택입니다!"),
]
for role, msg in conversations:
if role == "사용자":
history.add_user_message(msg)
else:
history.add_ai_message(msg)
# 대화 내용을 문자열로 변환
conversation_text = "\n".join([
f"{msg.__class__.__name__}: {msg.content}"
for msg in history.messages
])
# 요약 생성
summary_chain = summary_prompt | llm
summary = summary_chain.invoke({"conversation": conversation_text})
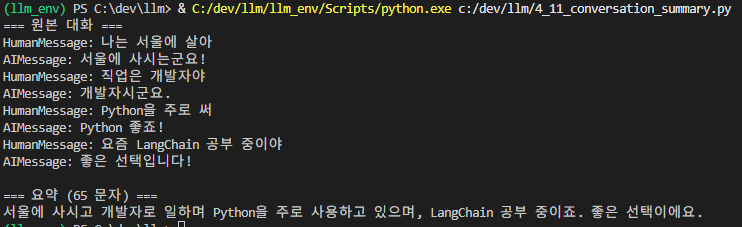
print("=== 원본 대화 ===")
print(conversation_text)
print(f"\n=== 요약 ({len(summary)} 문자) ===")
print(summary)
- 핵심 정리
| 클래스 | 역할 | 특징 |
|----------------------------|-----------------------|-------------------------------------------|
| ChatMessageHistory | 메시지 저장소 | 전체 대화를 메모리에 저장 |
| RunnableWithMessageHistory | 체인+메모리 통합 | LCEL 체인에 히스토리 자동 추가 |
| MessagesPlaceholder | 프롬프트 placeholder | 대화 기록이 들어갈 위치 표시 |
| FileChatMessageHistory | 파일 기반 저장 | 영속화 (프로그램 재시작 후에도 유지) |

개발 정리 공간 - 업무일때도 있고, 공부일때도 있고...