문서를 AI가 이해할 수 있게 만드는 첫 단계를 마스터
- RAG (Retrieval-Augmented Generation)의 개념 이해
- 다양한 문서 포맷 로드하기 (PDF, DOCX, CSV, TXT, 웹)
- 효과적인 텍스트 분할 전략 습득
- 메타데이터로 문서 관리하기
- 실전 사내 문서 로드 시스템 구축
1 RAG의 필요성
# week5_01_without_rag.py
from langchain_ollama import OllamaLLM
llm = OllamaLLM(model="qwen3:1.7b")
# LLM에게 회사 내부 정보 질문
response = llm.invoke("우리 회사의 2024년 휴가 정책이 뭐야?")
print(response)
# 결과: LLM은 회사 내부 문서를 모르므로 답변 불가! > 헛소리 하는 경우도..문제: LLM은 학습 데이터에 없는 정보 (회사 문서, 최신 뉴스 등)를 모릅니다. 정확히는 학습에 쓰인 데이터까지의 정보만으로 답변을 합니다.

RAG 작동 원리
- 문서 로드 → 2. 텍스트 분할 → 3. 임베딩 → 4. 벡터 DB 저장
→ 5. 질문 입력 → 6. 유사 문서 검색 → 7. LLM에 컨텍스트 제공 → 8. 답변 생성
- Document Loader - 다양한 문서 로드하기
예제 1: 텍스트 파일 로드
# week5_02_text_loader.py
from langchain_community.document_loaders import TextLoader
# 텍스트 파일 로드
loader = TextLoader("조직도_및_복지.txt", encoding="utf-8")
documents = loader.load()
print(f"로드된 문서 수: {len(documents)}")
print(f"문서 내용 미리보기:\n{documents[0].page_content[:200]}...")
print(f"메타데이터: {documents[0].metadata}")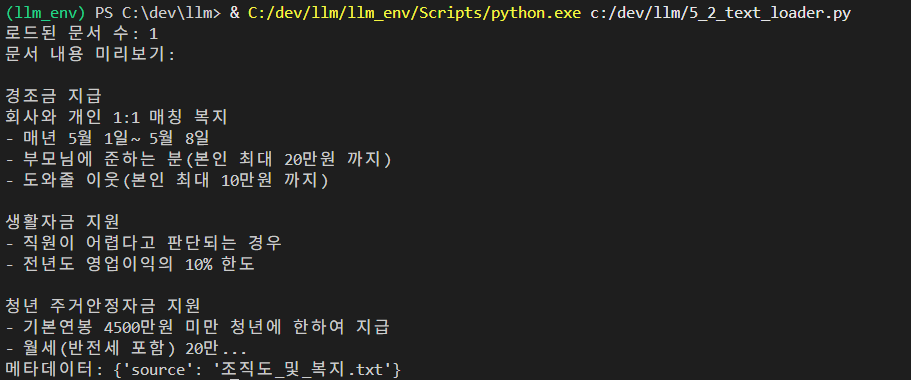
- 회사 조직도 및 복지 ppt 문서에서 text만 추출하여 (복지부분만) 사용
예제 2: PDF 파일 로드
# week5_03_pdf_loader.py
from langchain_community.document_loaders import PyPDFLoader
# PDF 로더
loader = PyPDFLoader("company_report.pdf")
documents = loader.load()
print(f"총 페이지 수: {len(documents)}")
# 각 페이지 확인
for i, doc in enumerate(documents):
print(f"\n=== 페이지 {i+1} ===")
print(f"내용: {doc.page_content[:150]}...")
print(f"메타데이터: {doc.metadata}")
총 11페이지 나오네요.
예제3:CSV 파일 로드 (샘플 생성 후 로드)
# week5_04_csv_loader.py
from langchain_community.document_loaders import CSVLoader
import csv
# 샘플 CSV 생성
employees = [
["이름", "부서", "직위", "입사일"],
["김개발", "개발팀", "주니어 개발자", "2026-01-05"],
["이마케", "마케팅팀", "마케팅 매니저", "2025-04-03"],
["박영업", "영업팀", "영업 이사", "2020-02-13"],
["정인사", "인사팀", "HR 담당자", "2024-12-23"],
]
with open("employees.csv", "w", encoding="utf-8", newline="") as f:
writer = csv.writer(f)
writer.writerows(employees)
# CSV 로드
loader = CSVLoader(
file_path="employees.csv",
encoding="utf-8",
csv_args={"delimiter": ","}
)
documents = loader.load()
print(f"직원 수: {len(documents)}")
for i, doc in enumerate(documents):
print(f"\n직원 {i+1}:")
print(doc.page_content)
print(f"메타데이터: {doc.metadata}")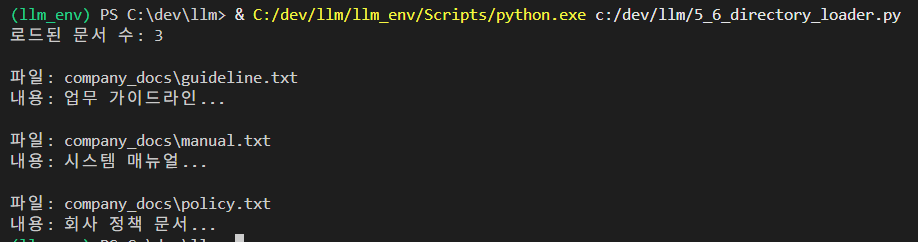
예제 4: 웹 페이지 로드
from langchain_community.document_loaders import WebBaseLoader
# SSL 인증서 검증을 비활성화하는 옵션 추가
loader = WebBaseLoader(
"https://www.parucnc.com",
requests_kwargs={"verify": False}
)
documents = loader.load()
print(f"로드된 문서 수: {len(documents)}")
print(f"내용 길이: {len(documents[0].page_content)} 문자")
print(f"내용 미리보기:\n{documents[0].page_content[:300]}...")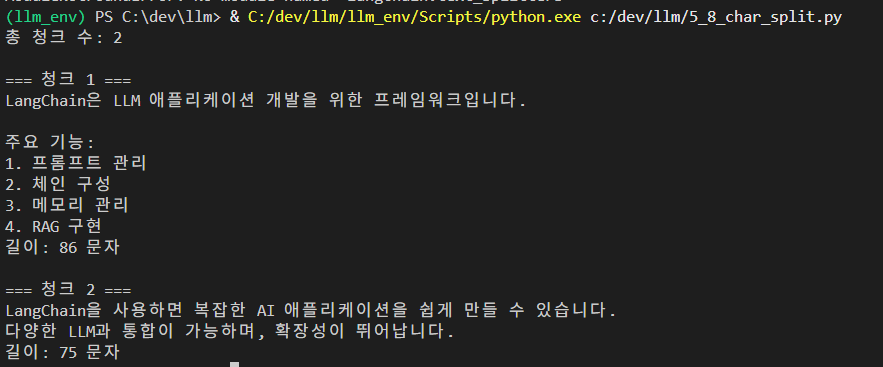
예제 5: 디렉토리 전체 로드
# week5_06_directory_loader.py
from langchain_community.document_loaders import DirectoryLoader, TextLoader
import os
# 샘플 디렉토리 구조 생성
os.makedirs("company_docs", exist_ok=True)
docs = {
"company_docs/policy.txt": "회사 정책 문서",
"company_docs/guideline.txt": "업무 가이드라인",
"company_docs/manual.txt": "시스템 매뉴얼"
}
for path, content in docs.items():
with open(path, "w", encoding="utf-8") as f:
f.write(content)
# 디렉토리 전체 로드
loader = DirectoryLoader(
"company_docs",
glob="**/*.txt", # 모든 .txt 파일
loader_cls=TextLoader,
loader_kwargs={"encoding": "utf-8"}
)
documents = loader.load()
print(f"로드된 문서 수: {len(documents)}")
for doc in documents:
print(f"\n파일: {doc.metadata['source']}")
print(f"내용: {doc.page_content[:100]}...")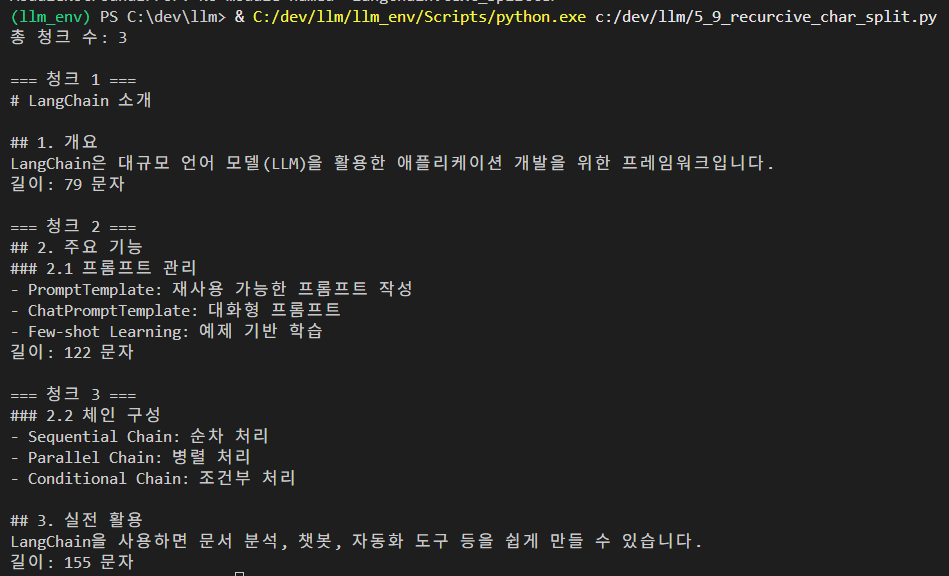
3. Text Splitter - 텍스트 분할 전략
왜 분할이 필요한가?
긴 문서를 그대로 사용하면?
long_document = "A" * 10000 # 10,000자
문제:
1. LLM 컨텍스트 길이 제한 초과
2. 관련 없는 정보까지 포함
3. 검색 정확도 하락
- 해결책: 문서를 의미 있는 청크(chunk)로 나누기
예제 6: CharacterTextSplitter (기본)
# week5_08_character_splitter.py
from langchain_text_splitters import CharacterTextSplitter
# 샘플 문서
text = """LangChain은 LLM 애플리케이션 개발을 위한 프레임워크입니다.
주요 기능:
1. 프롬프트 관리
2. 체인 구성
3. 메모리 관리
4. RAG 구현
LangChain을 사용하면 복잡한 AI 애플리케이션을 쉽게 만들 수 있습니다.
다양한 LLM과 통합이 가능하며, 확장성이 뛰어납니다."""
# 문자 기반 분할
splitter = CharacterTextSplitter(
separator="\n\n", # 문단 단위 분할
chunk_size=100, # 청크 최대 크기
chunk_overlap=20, # 청크 간 중복
length_function=len
)
chunks = splitter.split_text(text)
print(f"총 청크 수: {len(chunks)}")
for i, chunk in enumerate(chunks):
print(f"\n=== 청크 {i+1} ===")
print(chunk)
print(f"길이: {len(chunk)} 문자")** 버전업 되면서 CharacterTextSplitter는 이제 langchain.text_splitter가 아니라 langchain_text_splitters (끝에 s가 붙습니다) 로 이동했습니다!!
예제 7: RecursiveCharacterTextSplitter (권장)
# week5_09_recursive_splitter.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 긴 문서
text = """# LangChain 소개
## 1. 개요
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크입니다.
## 2. 주요 기능
### 2.1 프롬프트 관리
- PromptTemplate: 재사용 가능한 프롬프트 작성
- ChatPromptTemplate: 대화형 프롬프트
- Few-shot Learning: 예제 기반 학습
### 2.2 체인 구성
- Sequential Chain: 순차 처리
- Parallel Chain: 병렬 처리
- Conditional Chain: 조건부 처리
## 3. 실전 활용
LangChain을 사용하면 문서 분석, 챗봇, 자동화 도구 등을 쉽게 만들 수 있습니다."""
# 재귀적 분할 (계층적 구분자 사용)
splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=50,
length_function=len,
separators=["\n\n", "\n", " ", ""] # 우선순위 순서
)
chunks = splitter.split_text(text)
print(f"총 청크 수: {len(chunks)}")
for i, chunk in enumerate(chunks):
print(f"\n=== 청크 {i+1} ===")
print(chunk)
print(f"길이: {len(chunk)} 문자")
예제 8: Document Splitter (문서 객체 분할)
# week5_10_document_splitter.py
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
# 문서 로드
with open("long_document.txt", "w", encoding="utf-8") as f:
f.write("""회사 규정 1조: 근무 시간은 오전 9시부터 오후 6시까지입니다.
회사 규정 2조: 점심시간은 12시부터 1시까지입니다.
회사 규정 3조: 연차는 입사일 기준으로 부여됩니다.
회사 규정 4조: 재택근무는 주 2회까지 가능합니다.""")
loader = TextLoader("long_document.txt", encoding="utf-8")
documents = loader.load()
# 문서 분할
splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20
)
split_docs = splitter.split_documents(documents)
print(f"원본 문서 수: {len(documents)}")
print(f"분할 후 청크 수: {len(split_docs)}")
for i, doc in enumerate(split_docs):
print(f"\n=== 청크 {i+1} ===")
print(f"내용: {doc.page_content}")
print(f"메타데이터: {doc.metadata}")결과 :
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/5_9_recurcive_char_split.py
총 청크 수: 3
=== 청크 1 ===
# LangChain 소개
## 1. 개요
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크입니다.
길이: 79 문자
=== 청크 2 ===
## 2. 주요 기능
### 2.1 프롬프트 관리
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크입니다.
길이: 79 문자
=== 청크 2 ===
## 2. 주요 기능
### 2.1 프롬프트 관리
- PromptTemplate: 재사용 가능한 프롬프트 작성
- ChatPromptTemplate: 대화형 프롬프트
- Few-shot Learning: 예제 기반 학습
길이: 122 문자
=== 청크 3 ===
### 2.2 체인 구성
- Sequential Chain: 순차 처리
- Parallel Chain: 병렬 처리
- Conditional Chain: 조건부 처리
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크입니다.
길이: 79 문자
=== 청크 2 ===
## 2. 주요 기능
### 2.1 프롬프트 관리
- PromptTemplate: 재사용 가능한 프롬프트 작성
- ChatPromptTemplate: 대화형 프롬프트
- Few-shot Learning: 예제 기반 학습
길이: 122 문자
=== 청크 3 ===
### 2.2 체인 구성
- Sequential Chain: 순차 처리
- Parallel Chain: 병렬 처리
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크입니다.
길이: 79 문자
=== 청크 2 ===
## 2. 주요 기능
### 2.1 프롬프트 관리
- PromptTemplate: 재사용 가능한 프롬프트 작성
- ChatPromptTemplate: 대화형 프롬프트
- Few-shot Learning: 예제 기반 학습
길이: 122 문자
=== 청크 3 ===
### 2.2 체인 구성
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크입니다.
길이: 79 문자
=== 청크 2 ===
## 2. 주요 기능
### 2.1 프롬프트 관리
- PromptTemplate: 재사용 가능한 프롬프트 작성
- ChatPromptTemplate: 대화형 프롬프트
- Few-shot Learning: 예제 기반 학습
길이: 122 문자
LangChain은 대규모 언어 모델(LLM)을 활용한 애플리케이션 개발을 위한 프레임워크입니다.
길이: 79 문자
=== 청크 2 ===
## 2. 주요 기능
### 2.1 프롬프트 관리
- PromptTemplate: 재사용 가능한 프롬프트 작성
- ChatPromptTemplate: 대화형 프롬프트
길이: 79 문자
=== 청크 2 ===
## 2. 주요 기능
### 2.1 프롬프트 관리
- PromptTemplate: 재사용 가능한 프롬프트 작성
- ChatPromptTemplate: 대화형 프롬프트
## 2. 주요 기능
### 2.1 프롬프트 관리
- PromptTemplate: 재사용 가능한 프롬프트 작성
- ChatPromptTemplate: 대화형 프롬프트
- PromptTemplate: 재사용 가능한 프롬프트 작성
- ChatPromptTemplate: 대화형 프롬프트
- Few-shot Learning: 예제 기반 학습
길이: 122 문자
- Few-shot Learning: 예제 기반 학습
길이: 122 문자
=== 청크 3 ===
=== 청크 3 ===
=== 청크 3 ===
### 2.2 체인 구성
- Sequential Chain: 순차 처리
- Parallel Chain: 병렬 처리
- Conditional Chain: 조건부 처리
## 3. 실전 활용
LangChain을 사용하면 문서 분석, 챗봇, 자동화 도구 등을 쉽게 만들 수 있습니다.
길이: 155 문자
(llm_env) PS C:\dev\llm> & C:/dev/llm/llm_env/Scripts/python.exe c:/dev/llm/5_10_document_splitter.py
원본 문서 수: 1
분할 후 청크 수: 2
=== 청크 1 ===
내용: 회사 규정 1조: 근무 시간은 오전 9시부터 오후 6시까지입니다.
회사 규정 2조: 점심시간은 12시부터 1시까지입니다.
회사 규정 3조: 연차는 입사일 기준으로 부여됩니다.
메타데이터: {'source': 'long_document.txt'}
=== 청크 2 ===
내용: 회사 규정 4조: 재택근무는 주 2회까지 가능합니다.
메타데이터: {'source': 'long_document.txt'}4. 메타데이터 관리
예제 9: 메타데이터 추가
# week5_11_metadata.py
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 메타데이터가 있는 문서 생성
documents = [
Document(
page_content="2024년 1분기 매출은 100억원입니다.",
metadata={
"source": "재무보고서",
"quarter": "Q1",
"year": 2024,
"department": "재무팀",
"author": "김재무"
}
),
Document(
page_content="2024년 2분기 매출은 120억원입니다.",
metadata={
"source": "재무보고서",
"quarter": "Q2",
"year": 2024,
"department": "재무팀",
"author": "김재무"
}
)
]
# 분할 시 메타데이터 유지
splitter = RecursiveCharacterTextSplitter(chunk_size=50, chunk_overlap=10)
split_docs = splitter.split_documents(documents)
print(f"분할된 청크 수: {len(split_docs)}")
for i, doc in enumerate(split_docs):
print(f"\n청크 {i+1}:")
print(f"내용: {doc.page_content}")
print(f"메타데이터: {doc.metadata}")- 이전버전에서 모듈 자리이동
langchain.schema에 모여 있던 핵심 클래스들이 langchain_core 전용 패키지로 이동
예제 10: 메타데이터 필터링
# week5_12_metadata_filter.py
from langchain_core.documents import Document
# 다양한 문서
documents = [
Document(
page_content="Python은 프로그래밍 언어입니다.",
metadata={"category": "개발", "level": "초급", "language": "Python"}
),
Document(
page_content="JavaScript는 웹 개발에 사용됩니다.",
metadata={"category": "개발", "level": "초급", "language": "JavaScript"}
),
Document(
page_content="마케팅 전략 수립 가이드입니다.",
metadata={"category": "마케팅", "level": "중급", "language": None}
),
Document(
page_content="고급 Python 디자인 패턴입니다.",
metadata={"category": "개발", "level": "고급", "language": "Python"}
)
]
# 메타데이터로 필터링
def filter_documents(docs, **filters):
"""메타데이터 조건으로 문서 필터링"""
filtered = []
for doc in docs:
match = True
for key, value in filters.items():
if doc.metadata.get(key) != value:
match = False
break
if match:
filtered.append(doc)
return filtered
# 필터링 예시
print("=== 개발 카테고리 문서 ===")
dev_docs = filter_documents(documents, category="개발")
for doc in dev_docs:
print(f"- {doc.page_content}")
print("\n=== Python 초급 문서 ===")
python_beginner = filter_documents(documents, language="Python", level="초급")
for doc in python_beginner:
print(f"- {doc.page_content}")
개발 정리 공간 - 업무일때도 있고, 공부일때도 있고...