
데이터는 어떻게 쪼개지고 저장될까?
1. 벡터 데이터: 숫자로 바뀐 문장의 의미
로컬에 구축한 RAG 시스템이 내 문서를 이해하게 하려면, 먼저 텍스트를 컴퓨터의 언어로 번역해야 한다. 컴퓨터는 텍스트를 직접 이해하지 못하기 때문에, 우리는 이를 고차원 공간상의 좌표인 벡터(Vector)로 변환하는 과정을 거친다.
- 구조: 보통 ID, 임베딩 값(고차원 숫자 배열), 그리고 원문 정보를 담은 메타데이터 세트로 저장된다.
- 핵심 원리: 의미가 유사한 문장들은 벡터 공간 내에서 서로 가까이 위치하게 된다. 내가 "Redis 성능 개선"을 물어보면, 시스템은 이 질문의 벡터값과 가장 가까운 곳에 있는 문서 조각들을 찾아내는 방식이다.
2. 청킹(Chunking): 검색의 품질을 결정하는 '칼질'의 기술
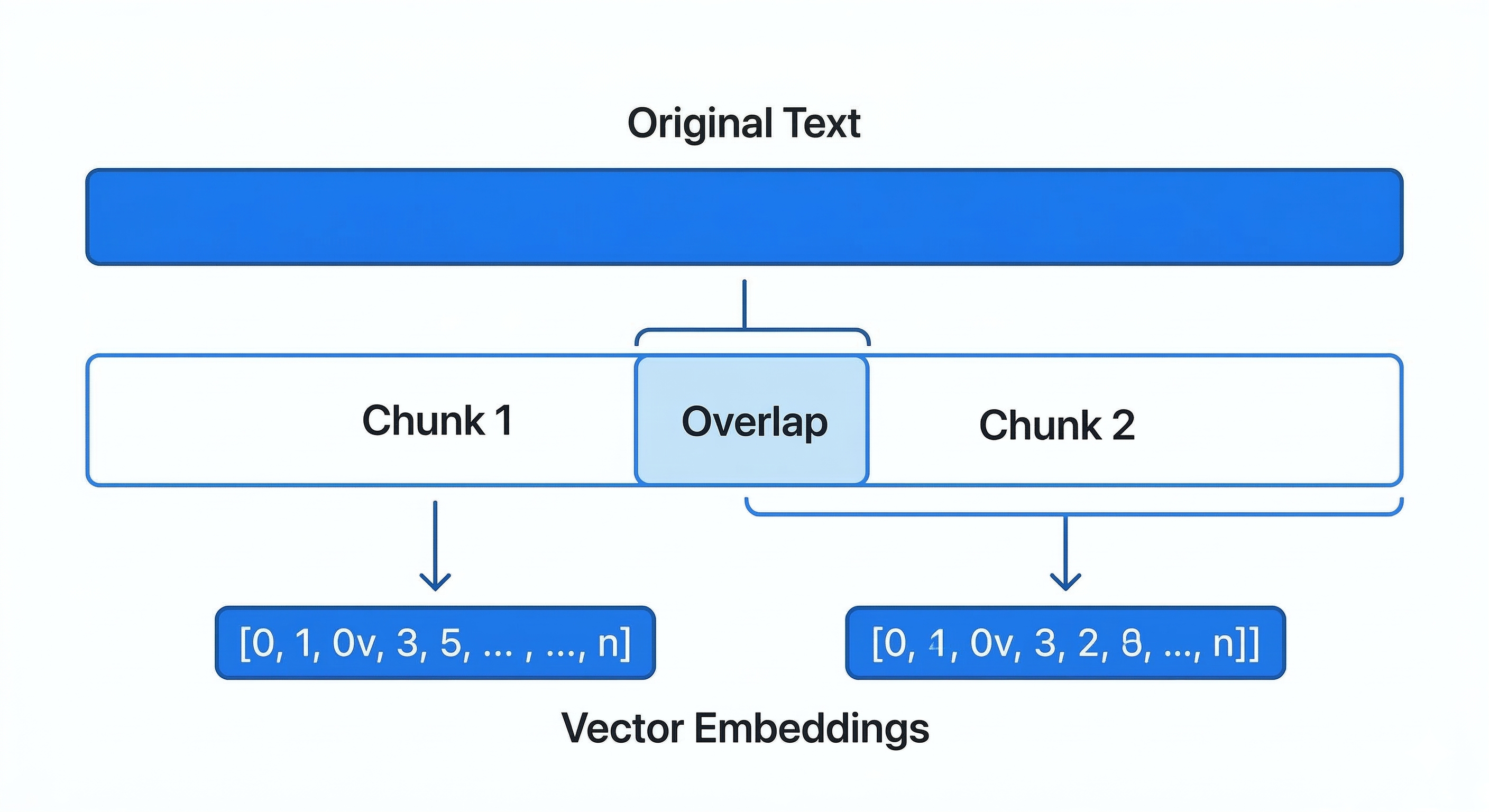
긴 문서를 통째로 Vector DB에 넣으면 AI는 길을 잃는다. 너무 많은 정보가 섞여 있어 질문에 딱 맞는 답변을 추출하기 어렵기 때문이다. 그래서 문서를 '청크(Chunk)'라는 작은 단위로 쪼개는 청킹 과정이 필요하다. 단순히 자르는 것이 아니라 '잘' 자르는 것이 실력이다.
- 재귀적 분할: 단순히 글자 수로 뭉텅 자르는 게 아니라, 마침표나 줄바꿈을 기준으로 의미 단위를 최대한 보존하며 자른다.
- 중복 허용(Overlap): 청크와 청크 사이에 교집합을 두어, 맥락이 끊기지 않도록 앞뒤 내용을 일부 겹치게 만드는 것이 핵심이다.
3. Spring AI + Ollama 실전 구현
Spring AI 환경에서는 TokenTextSplitter를 통해 이 과정을 자동화할 수 있다. 특히 항목별로 나뉜 기술 문서를 처리할 때는 기본값에 의존하기보다, 데이터의 특성에 맞는 세밀한 설정이 중요하다.
// Spring AI를 활용한 청킹 최적화 설정 예시
List<Character> punctuationMarks = List.of('.', '\n', ']', '-');
TokenTextSplitter splitter = new TokenTextSplitter(
150, // chunkSize: 한 항목의 핵심 내용이 충분히 들어갈 크기
50, // minChunkSizeChars: 너무 짧아 의미가 없는 '부스러기' 청크 방지
10, // minChunkLengthToEmbed: 의미 없는 단순 줄바꿈 등 제거
100, // maxNumChunks: 생성할 최대 청크 수
true, // keepSeparator: 문장 구조 유지를 위해 구분자 보존
punctuationMarks // 분할 기준이 될 구분자들
);[해당 값은 문서의 속성에 따라 최적화 과정이 필요하다]
4. 설정을 최적화하는 이유
처음에는 시스템이 제공하는 기본 설정을 그대로 사용했다. 하지만 테스트를 해보니 명확한 한계가 보였다. 기본값이 너무 크면 여러 주제가 하나의 거대한 청크로 뭉쳐버리는 '노이즈'가 발생했고, 반대로 너무 작게 자르면 문맥이 완전히 파괴되어 버렸다.
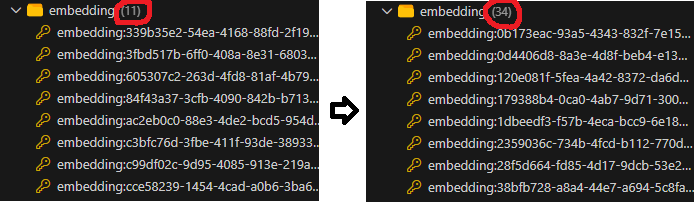
이를 해결하기 위해 스플리터 설정을 튜닝했다. 흥미로운 점은 튜닝 전후로 LLM이 내놓은 최종 답변의 퀄리티는 겉보기에 크게 다르지 않았다는 것이다. 하지만 내부 동작을 뜯어보니 결정적인 변화가 있었다. 전체 데이터의 청크 개수가 11개에서 34개로 세밀하게 늘어난 것이다.
결과가 같은데 청크 개수가 늘어난 것이 왜 유의미한 개선일까? 객관적인 이유는 다음과 같다.
- 검색 정밀도 향상: 11개의 뭉툭한 덩어리에서 검색하는 것보다, 34개의 정교한 조각 중에서 사용자의 질문에 딱 들어맞는 핵심 조각만 정확하게 타겟팅할 수 있게 되었다.
- 불필요한 토큰 소모 방지: 이전에는 질문 하나를 해결하기 위해 불필요한 주변 정보까지 통째로 LLM의 프롬프트에 실어 보내야 했다. 이제는 딱 필요한 조각만 전달하므로 처리 비용과 시간이 단축된다.
- 환각 리스크 차단: 관련 없는 정보가 프롬프트에 섞여 들어갈 확률을 원천 차단하여, 모델이 엉뚱한 맥락에 휘둘릴 가능성을 줄였다.
나는 이 튜닝 과정을 거치며 확실히 깨달았다. "RAG 시스템의 성능은 단순히 LLM 모델의 스펙보다, 우리가 준비한 데이터의 해상도를 얼마나 높이느냐에 더 큰 영향을 받는다"는 사실을 말이다.
5. 마치며: 데이터의 '양'보다 '질'과 '구조'
이번 과정을 거치며 RAG 시스템에서 데이터를 쪼개는 나름의 기준이 생겼다. 처음엔 기본 설정값만으로 충분할 줄 알았지만, 실제로는 내 데이터의 특성에 맞춰 Chunk Size와 Overlap을 집요하게 튜닝하는 과정이 필수였다.
청크 개수가 11개에서 34개로 늘어난 건 단순한 숫자의 증가가 아니다. 검색의 '해상도'를 높여 LLM이 정답에 도달하는 길을 훨씬 촘촘하게 닦아준 것이다. 결론은 명확하다. RAG의 성능은 모델의 스펙보다 '데이터를 얼마나 검색 친화적으로 정제하느냐'에 달려 있다는 것이다.
