2-1 Introduction to AMBA AHB
본격적으로 AHB 의 설명에 들어간다.
용어
접두어
HCLK for AHB
PCLK for APB
BCLK for ASB
A~ for unidirectional signal between MASTER <-> ARBITER for ASB
ex) AGNTx, AREQx
D~ for unidirectional signal for ASB decoder signal
ex) DSELx
T~ for test signal
접미어
~n for ACTIVE LOW
ex) HRESETn, PRESETn
용어
- Master
- Slave - Master가 생성한 transaction 에 응답. Slave 는 메모리공간주소체계를 가지고있어야함.
- Arbiter - 1 개의 버스를 단 하나의 마스터만 사용할 수 있도록 버스를 관리함.
- Decoder - Master가 날린 메모리주소를 메모리공간주소체계에 따라 분석하여 어느 Slave 에 신호가 가야하는지를 해석해줌.
개념적으로 아래와 같다.
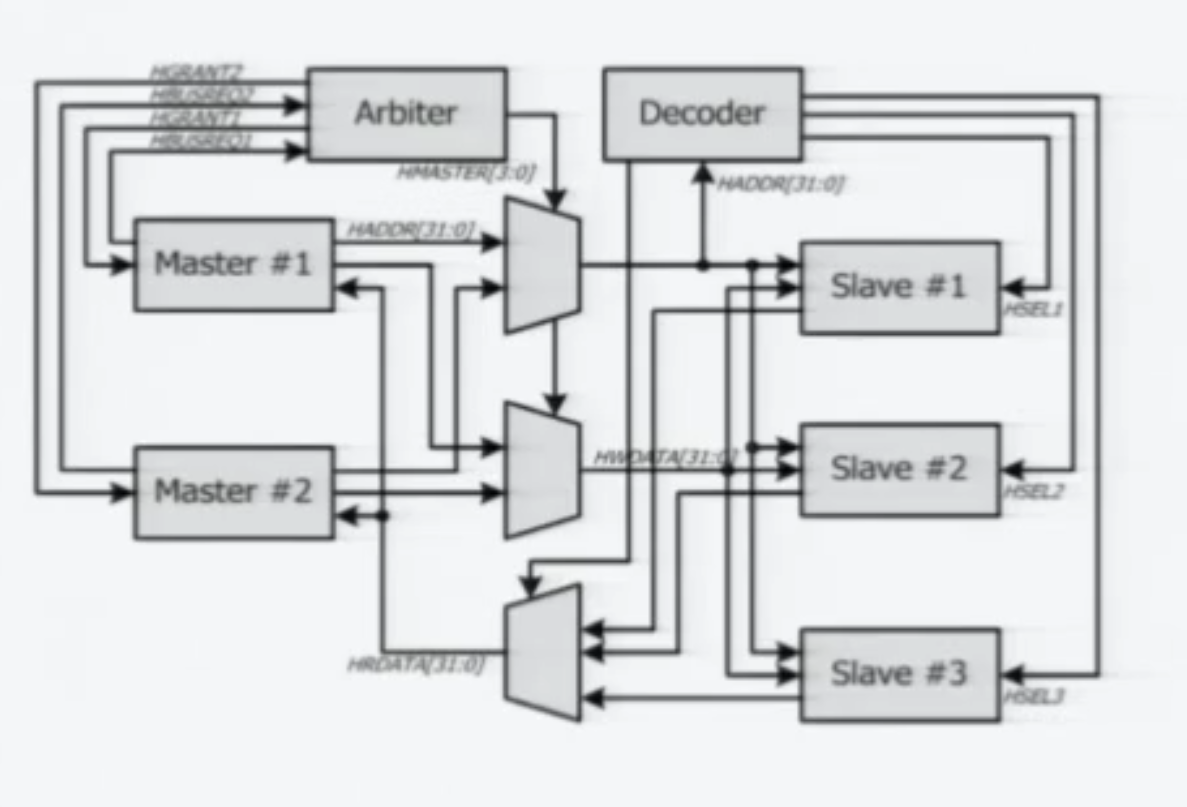
Address Path
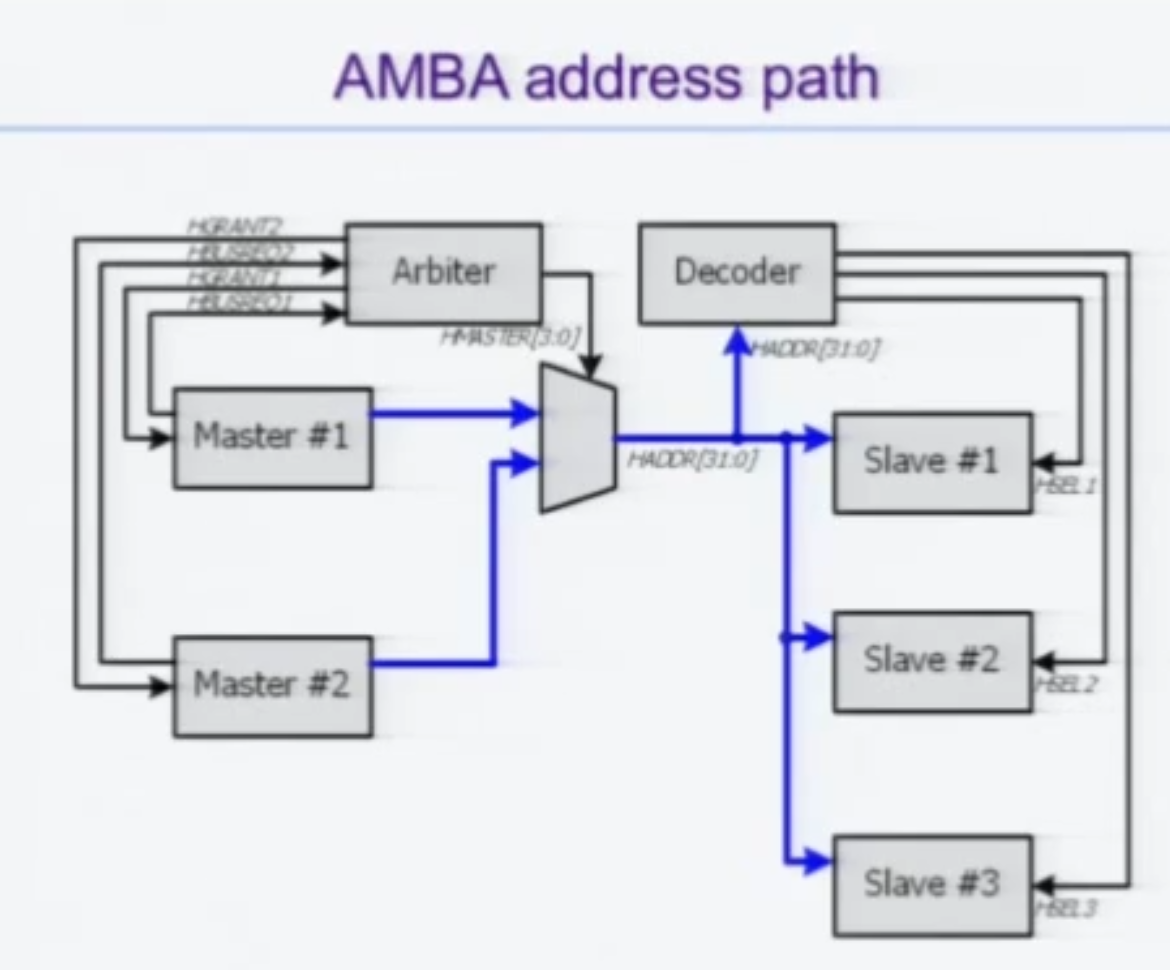
Data Path - Write
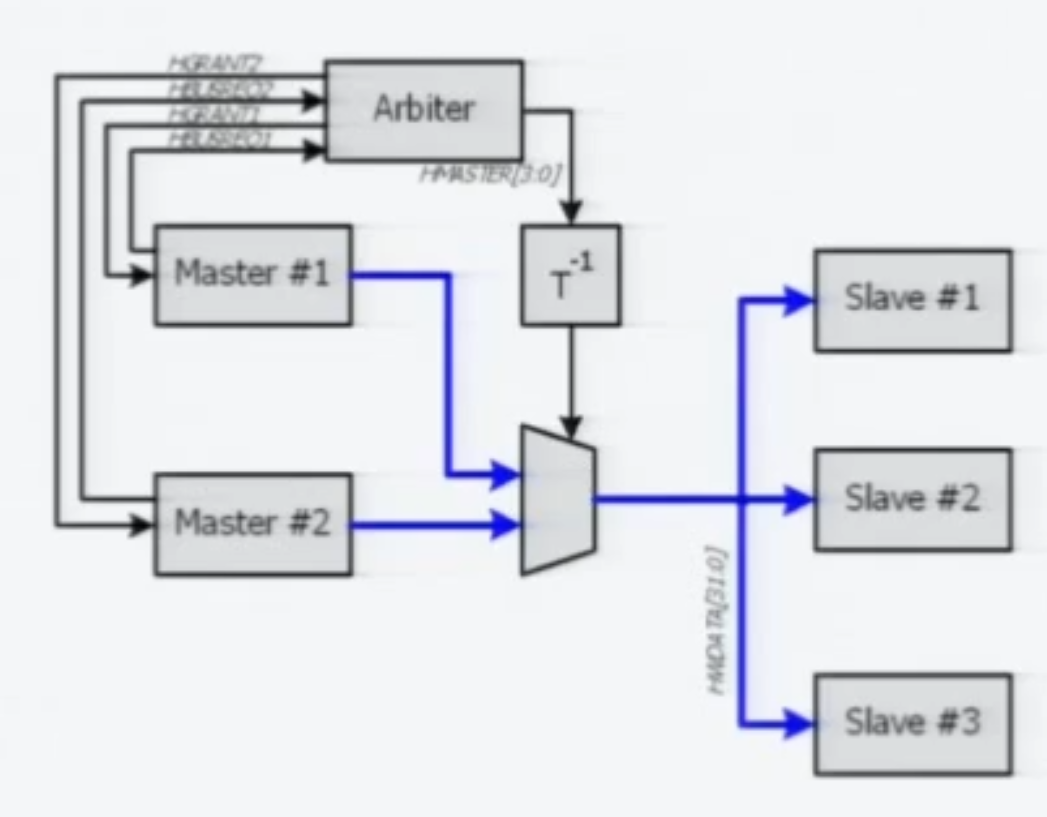
Arbiter 결과가 T-1 되는 것은, Address Derive Cycle 다음 Cycle 에 Data 가 Derive 되어야 함을 나타낸 것이다.
실제 구현할 때, Write 의 경우 2 사이클 딜레이인데 Data 는 1사이클 전의 것, Address 는 2사이클 전의 것을 사용하는 것의 이유가 이것이다.
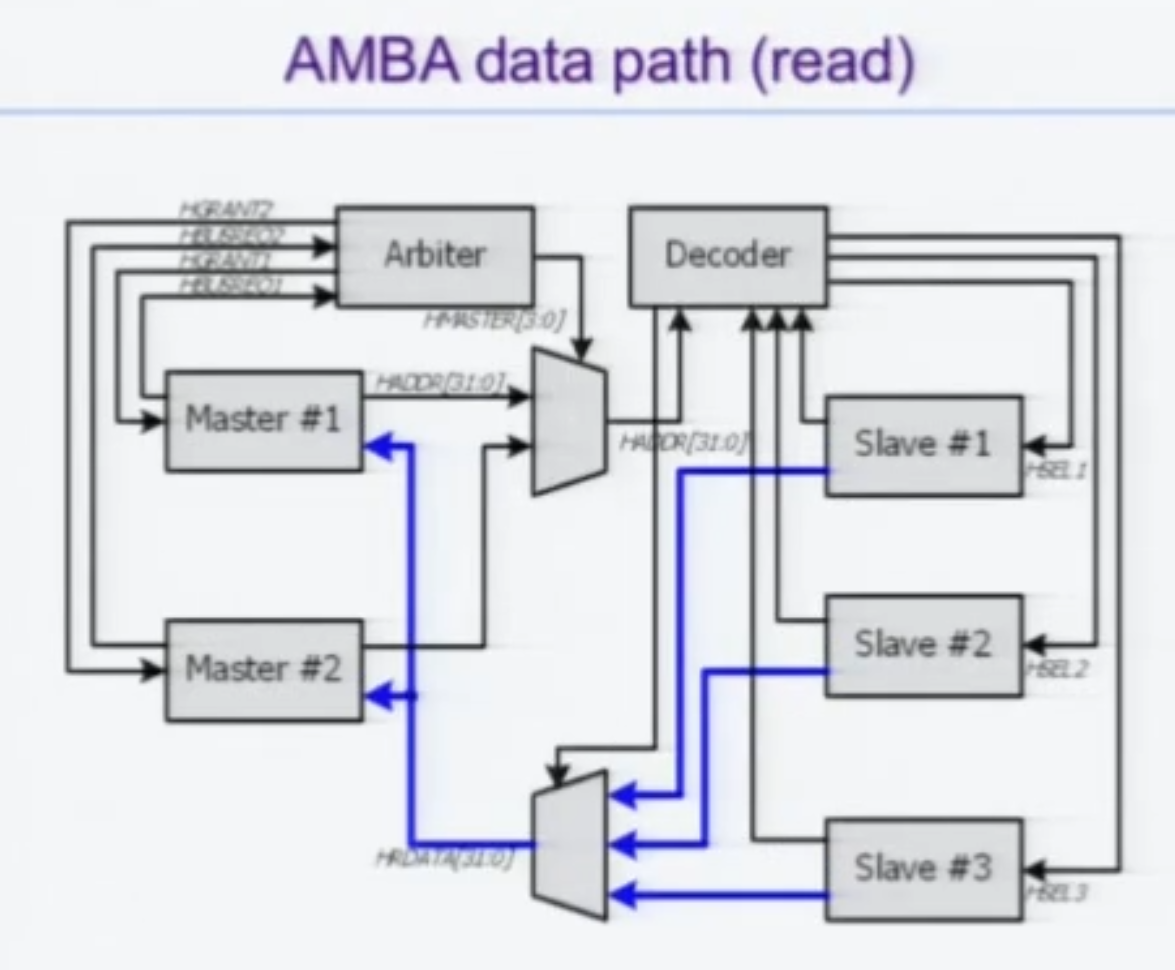
Data Path - Read
AHB 타이밍 분석
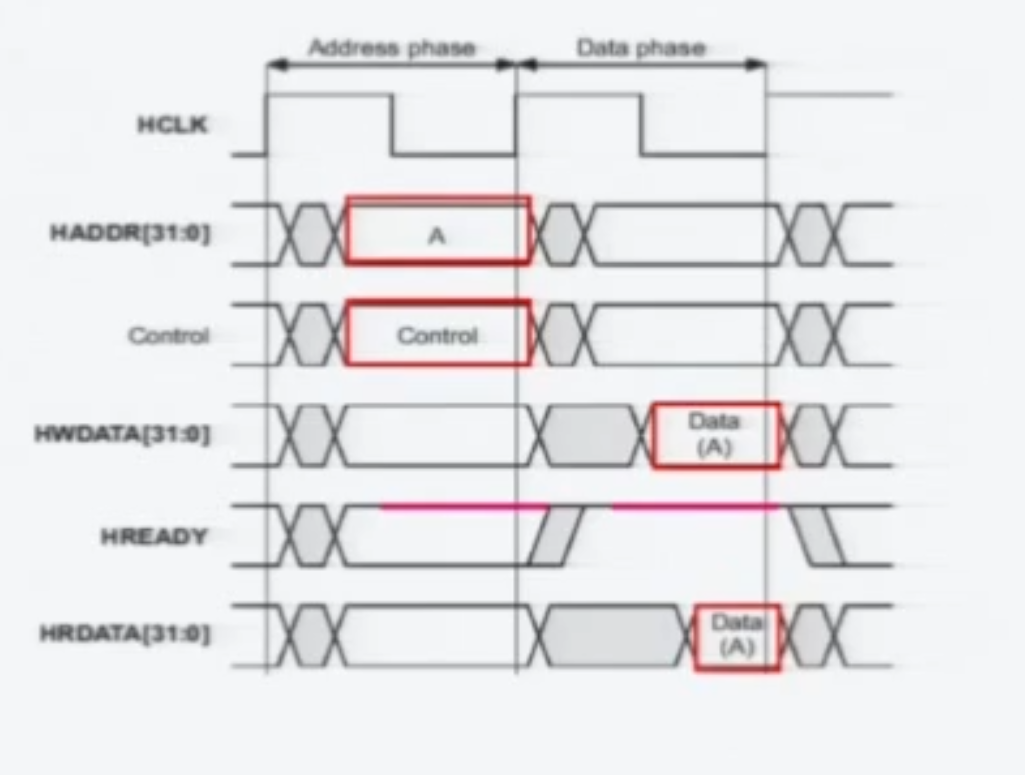
Control 신호는 W인지 R인지를 판별, 그리고 의미있는 신호인지 등등의 여러 신호들의 집약체이다.
HREADY 가 1이면 Slave에서 동작이 제대로 되었다는 뜻이며, 핑크선이 맞다.
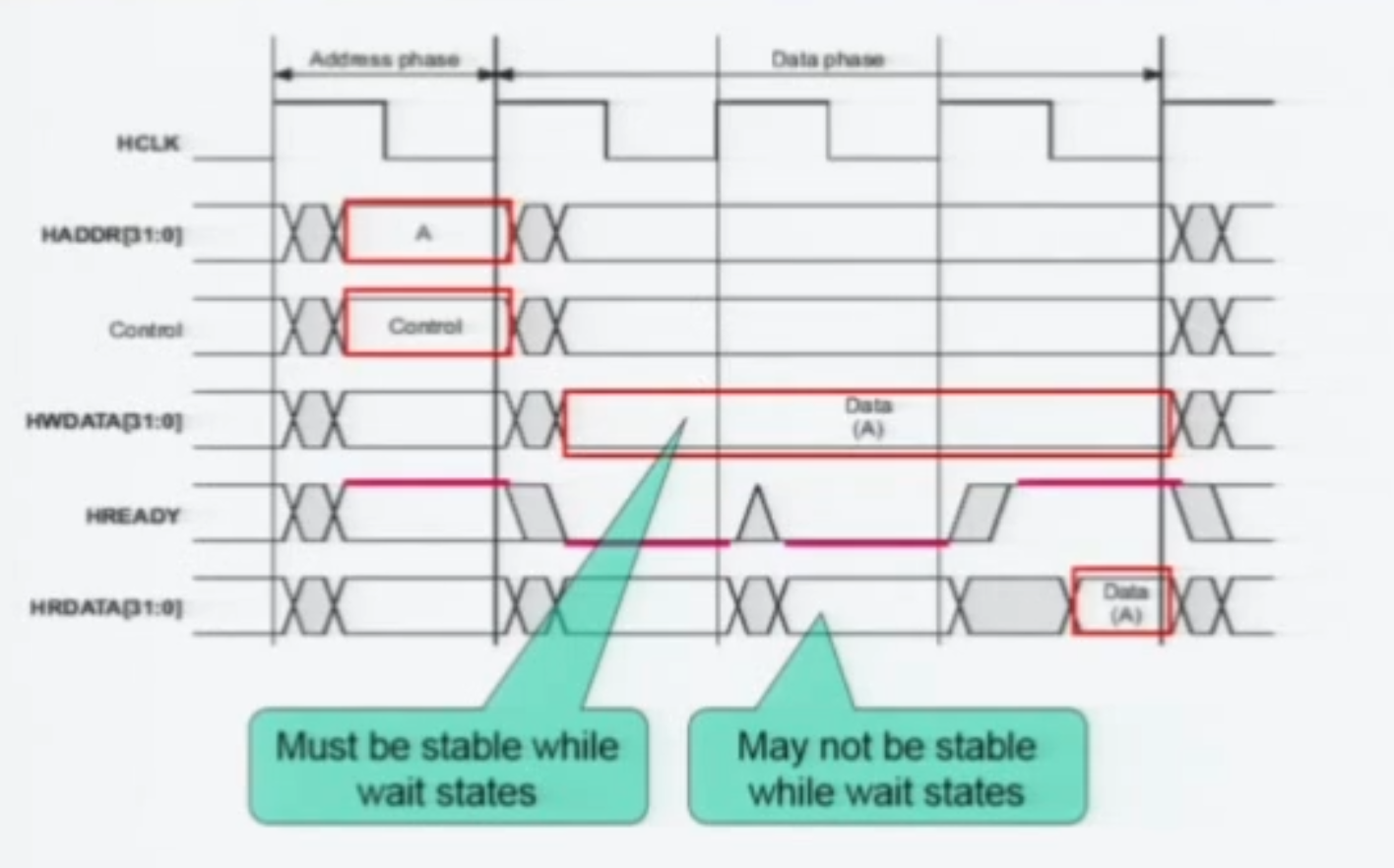
위와같이, 만일 HREADY가 0이면, HWDATA 가 계속 가해져야한다. 슬레이브가 아직 처리를 못했다는 뜻이기 때문이다. 이를 wait State 라고 한다.
A 주소에 쓰는 명령 직후 B 주소에 쓰는 명령이 올 때
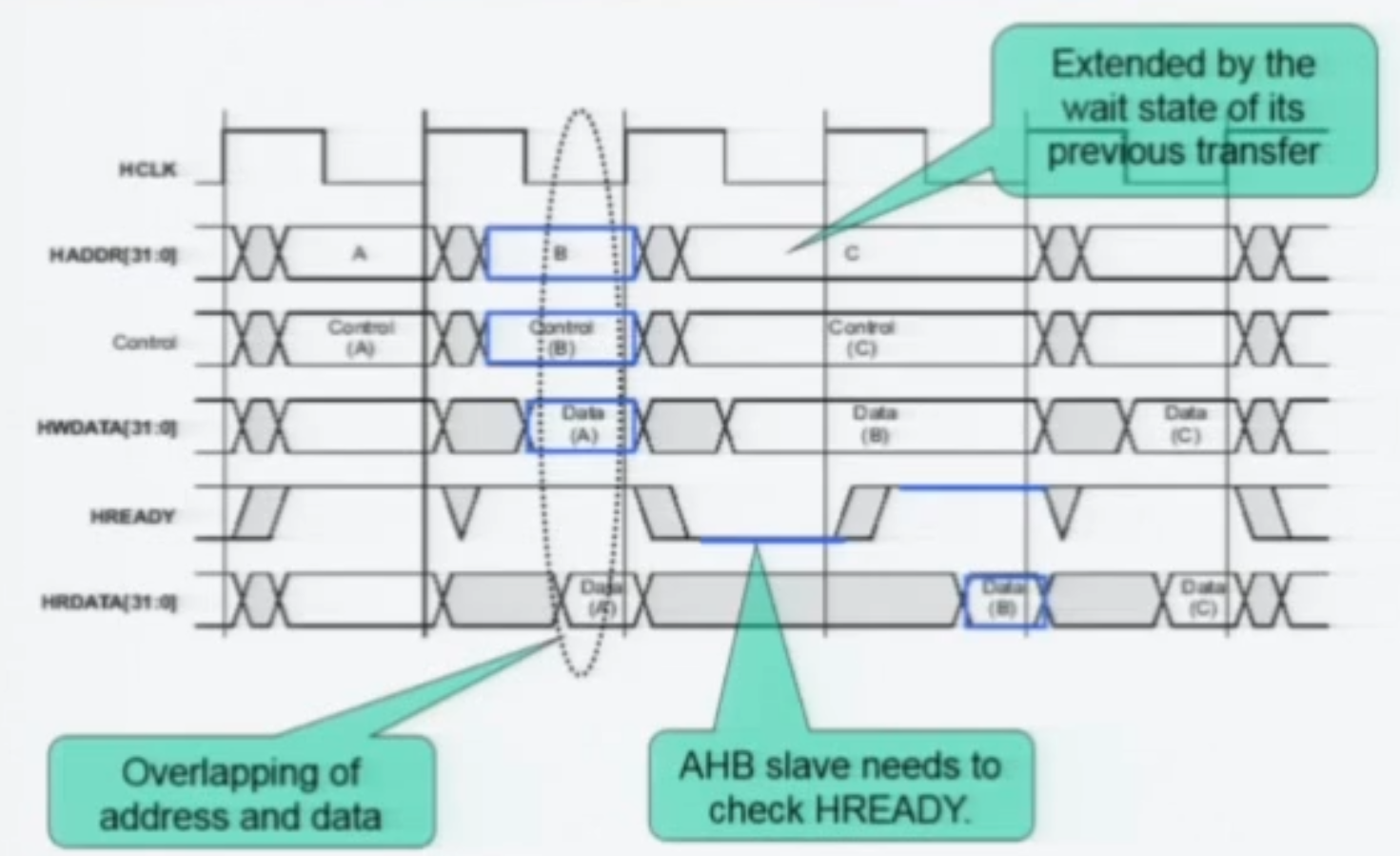
A의 access는 2사이클만에 끝났고, 그 도중 B 에 대한 명령이 왔다.
따라서 HREADY 를 Low로 하고, B 그룹의 Data Phase 가 진행되는동안 C 명령어가 또 왔다.
Data 버스는 공유를 하기 대문에 ADDRESS 자체도 지연되어야한다. 따라서 C의 Address 는 2사이클동안 인가된다.
AHB Master
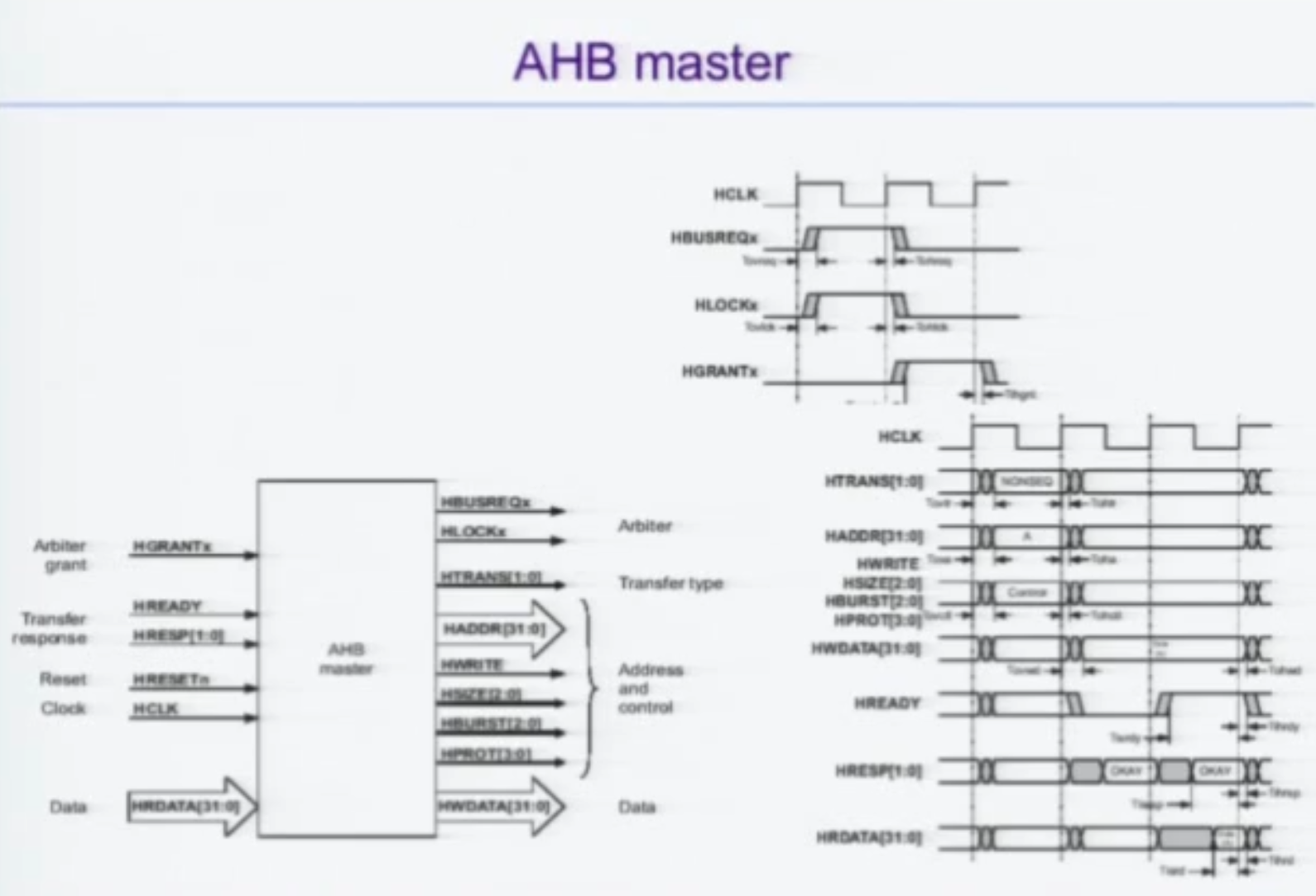
Grant 를 받아야 address를 slave 에 보낼 수 있게 된다.
HTRANS는 일종의 valid 신호라고 보면 된다.
AHB Slave
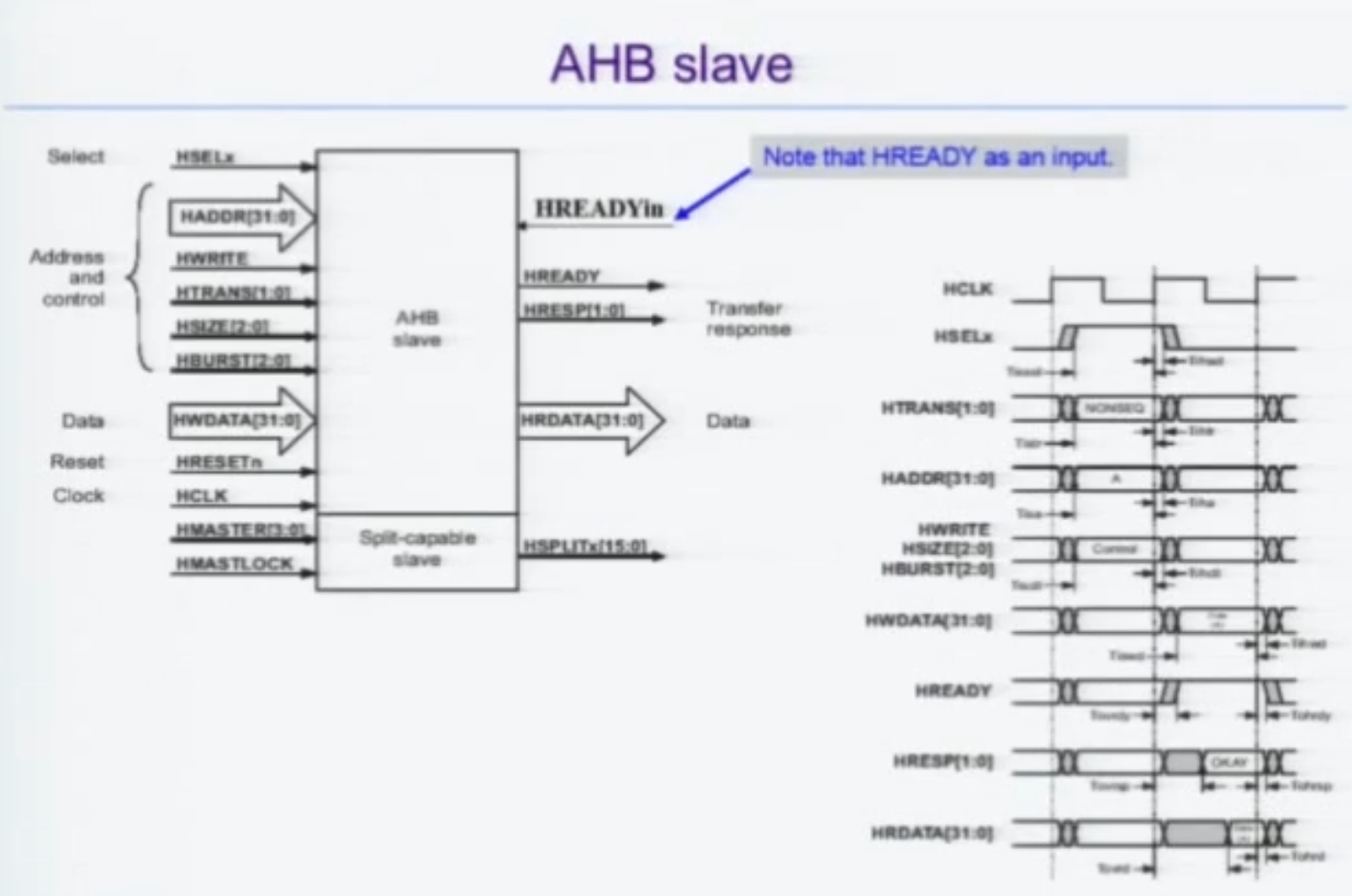
HREADYin과 HREADYout 이 둘 다 있는 이유
AHB Slave 가 아까 나온 그림에서
HREADY가 1인지 0인지를 토대로
C주소가 자기껀줄은 알았다. 이건 디코더가 알아서 HSEL로 알려주니까.
문제는, 내가 다음 사이클에 해당 주소를 처리할 수 있는 상황인지 아닌지를 나 말고 다른 슬레이브도 알아야 한다.
AHB Decoder
매우 쉽게 구현이 가능하다.
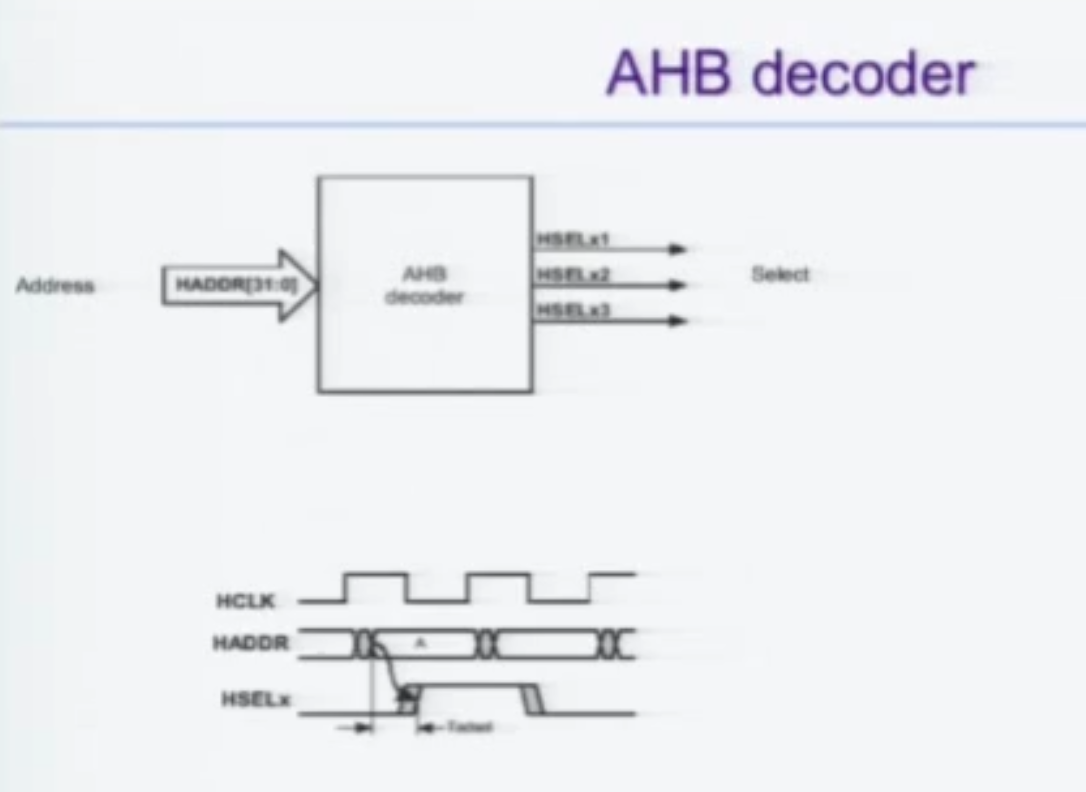
그저 주소범위에 따라 HSEL 중 하나를 ON 해주면 된다.
AHB Arbiter
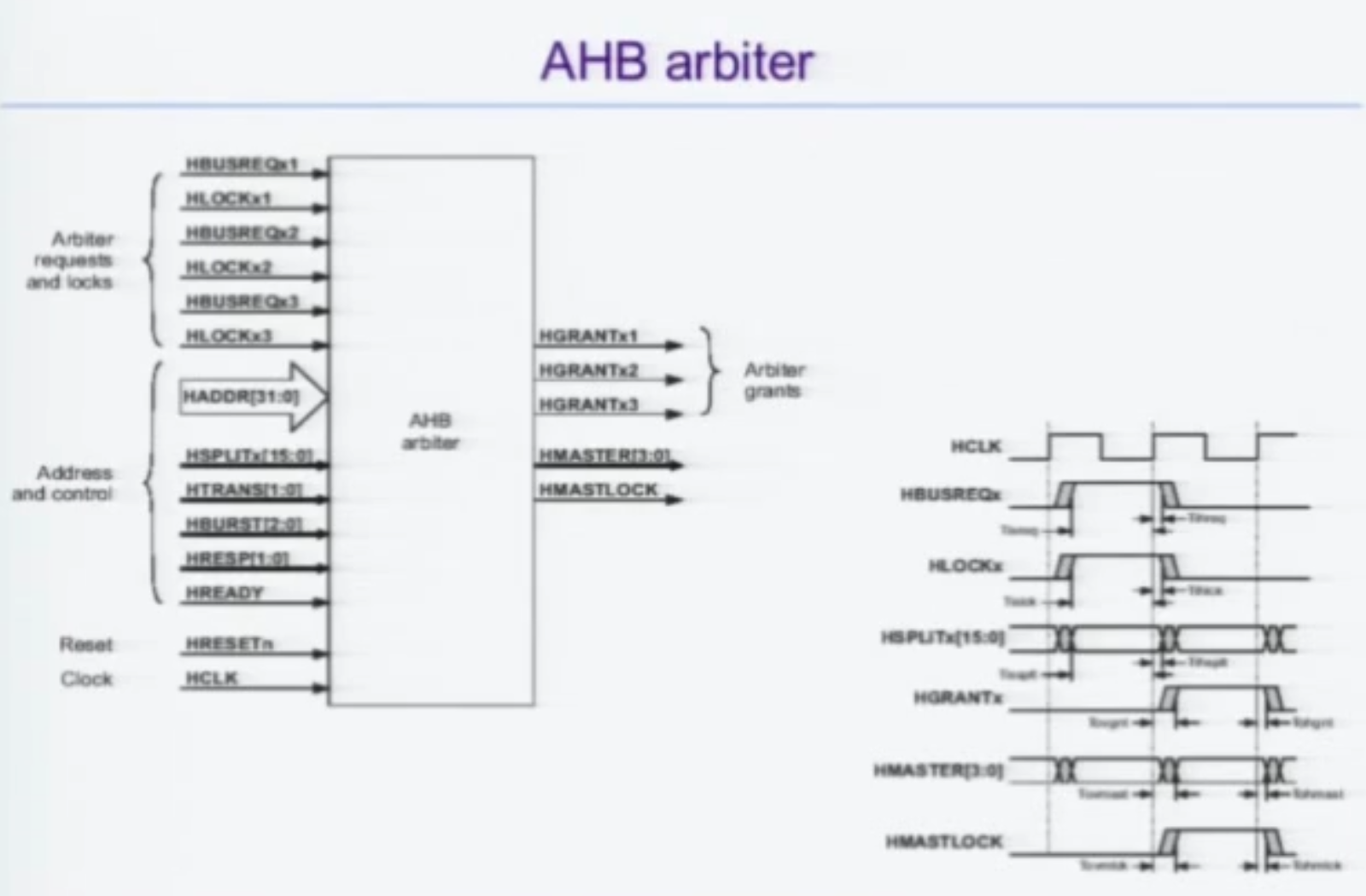
BUSREQ 를 받고 HGRANT 중 하나를 승인한다.
즉 하나의 마스터에게 허락한다.
따라서 아비터는 어느 마스터가 점유중인지는 내부에서 유지해야한다.
LOCK의 경우 Read Modify Write 신호같은게 있을 때 중간에 무결성이 깨지는 것을 방지할 필요가 있을 때 사용한다.
기본적으로 3사이클이 필요한데,
1. 리퀘스트보내고
2. 그란트받고
3. 데이터나가고
이기 때문이다.
HREADY가 계속 1일 때의 AHB Arbitration
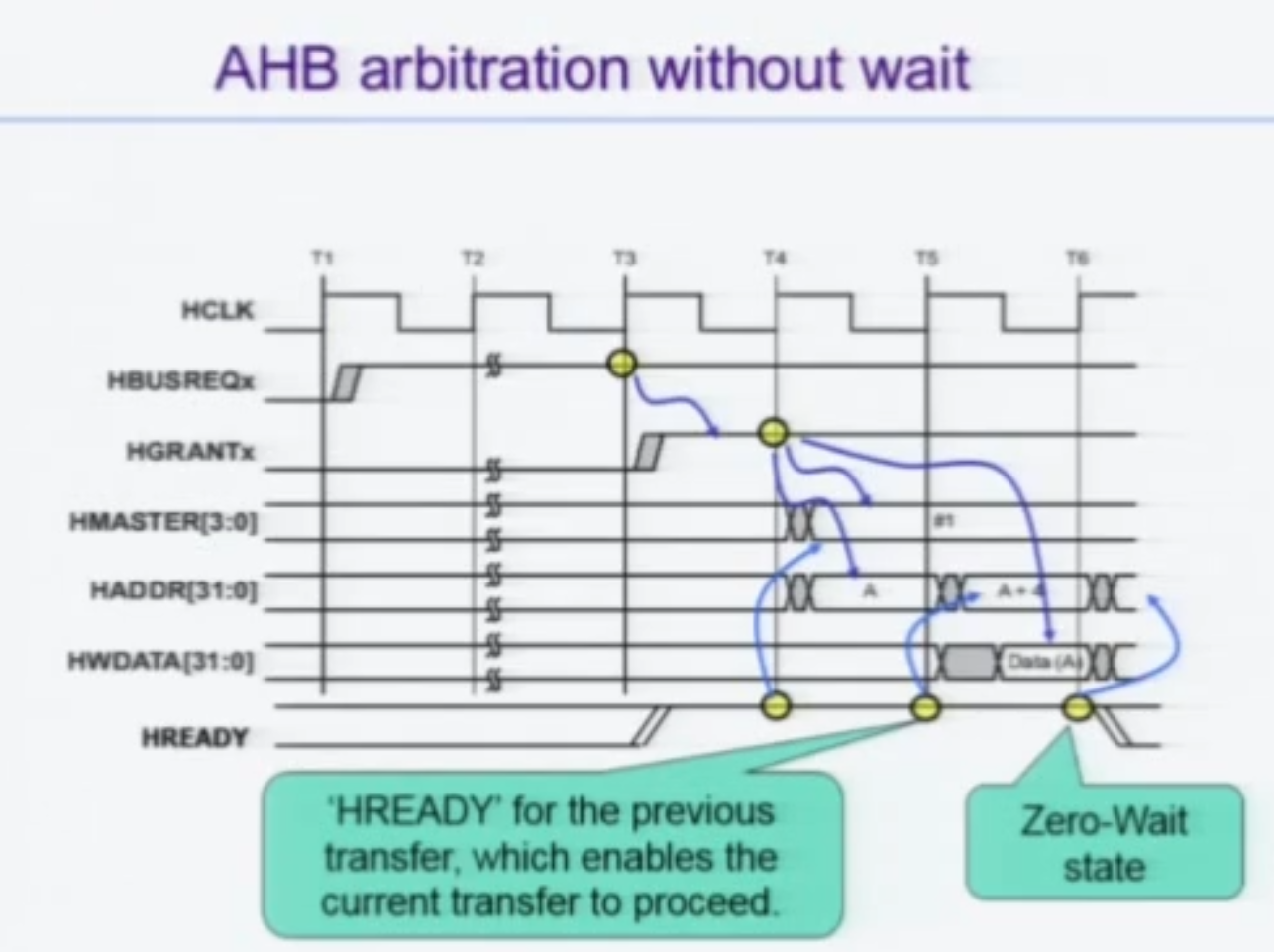
HBUSREQ 를 Master가 계속 보내주고 있고,
1. 첫 사이클에 BUSREQ 를 아비터가 수신.
2. Slave가 READY 되었으니 두 번째 사이클에 GRANT 승인
3. GRANT 를 받았으니 Master 는 Addr를 세 번째 사이클부터 투입, 그리고 Slave 의 HREADY 1로 변경 -> 맞나?
4. Master 는 Data 를 네 번째 사이클부터 투입
이 때 주의해야할 점은
그란트 받았다고 무조건 주소 전송하는게 아니라, Slave 가 HREADY 인지 Master 가 판단을 해야한다는 점이다 -> 맞겠지?
마스터는 HGRANT를 받고, 바로 ADDR를 보내지 않고 HREADY 가 1인 경우에만 ADDR 를 보낸다. 이건 아비터가 아니라 마스터 설계자의 몫이다.
다만 여기서 우리가 예측할 수 있는 사태는
1. 1번 마스터가 GRANT 받음
2. 1번 마스터가 1번 슬레이브 접근시도했는데 HREADY가 0임, 즉 바쁨
3. 따라서 1번 마스터가 GRANT 내려놓음. 다음 사이클에 2번 마스터가 GRANT를 가져감
이런 시나리오를 가정가능하다.
이는 아래와 같다.
Slave 가 wait 을 보낼 때의 Master의 동작 - GRANT 내려놓기
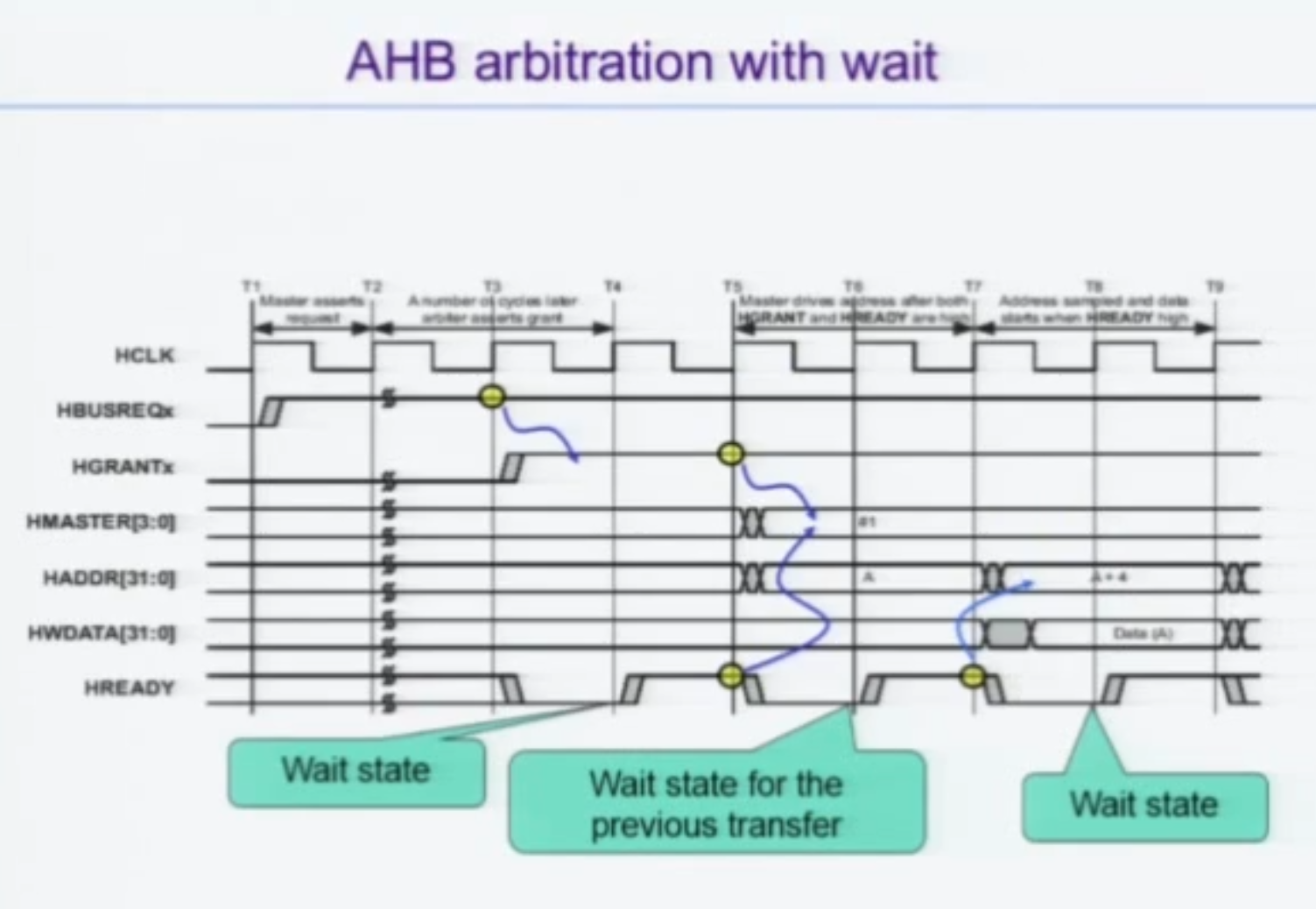
보다시피 T3에서 GRANT 받은 마스터는 슬레이브의 HREADY를 슬쩍 보니 0이라 그란트를 내려놓고
T5에서 GRANT 받은 마스터가 되어서야 슬레이브의 HREADY 가 1이 되므로 Address를 Derive 함을 확인할 수 있다.
Bus Ownership
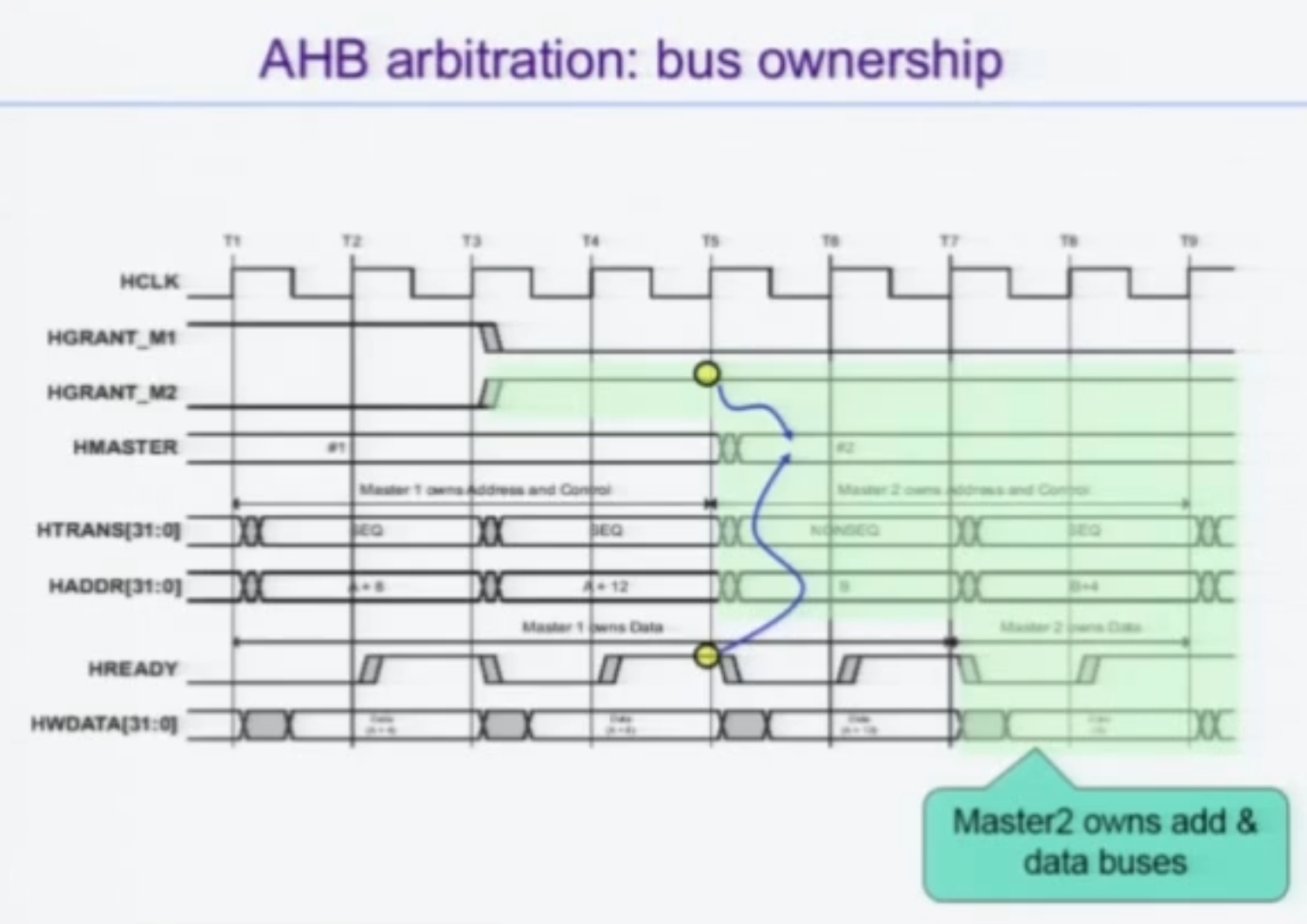
GRANT를 받았다 하더라도 Bus의 Ownership 은 HREADY 가 1일때여야 비로소 가능하다.
즉 노예의 HREADY 사정을 고려해주는 주체는 ARBITER 가 아니라 MASTER다. 강조한다.
M2가 GRANT 를 미리 받았다 한들, 실제로 Address 를 인가하는 시점은 최초로 HREADY 가 1이 되는 Rising Edge인 T5 부터라는 것이다.
T5 까지는 HMASTER는 여전히 M1이다. 즉 아비터는 HGRANT를 M2에게 주고 있지만 여전히 내부적으로는 M1이 Master 라고 인식하고 있다. 아직 M1이 HREADY 탓에 완전한 BUS Ownership 을 가지지 못했기 때문이다.
마찬가지로, HREADY가 1일 때 ADDR 을 보내게 되고, HREADY가 1일 때 DATA 를 보내게 된다.
Handover
더 높은 우선순위의 Request 가 왔을 때 등등의 경우이다.
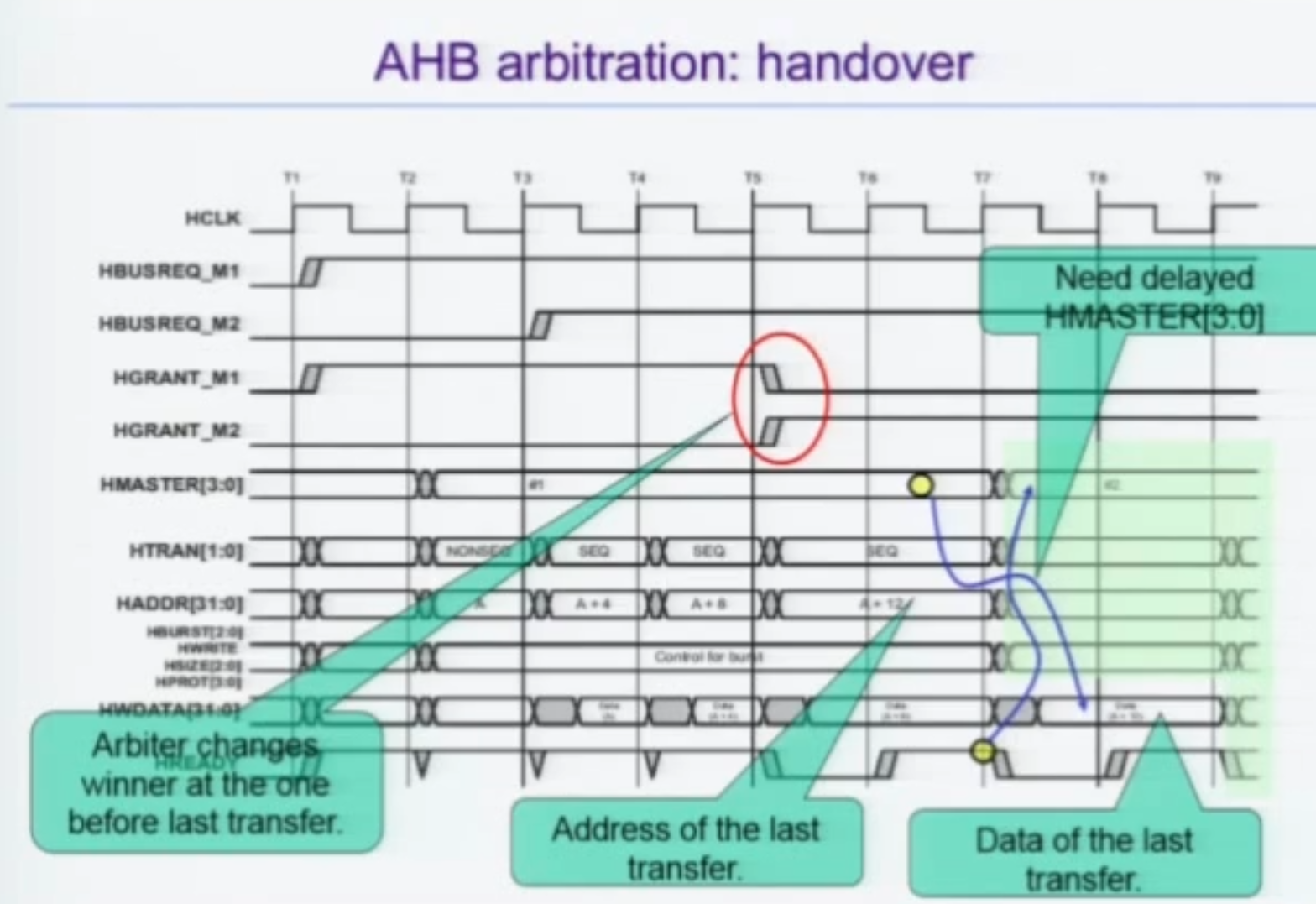
HGRANT 가 바뀌고, HREADY를 고려하여 1사이클 뒤에 ADDR를 보내고 1사이클 뒤에 DATA를 보낸다.
Split
여태까지는 Slave측에서 조금 더 시간을 요구한다면 HREADY 를 통해 지연시켰다.
다만, 그 소요시간이 매우 길 예정이라면 이는 비효율적이다.
그 경우에는 Bus를 홀딩하면 안된다. 당연히 비효율때문.
Data bus를 못쓰게되고, 그럼 당연히 Addr 버스도 못쓰게 된다.
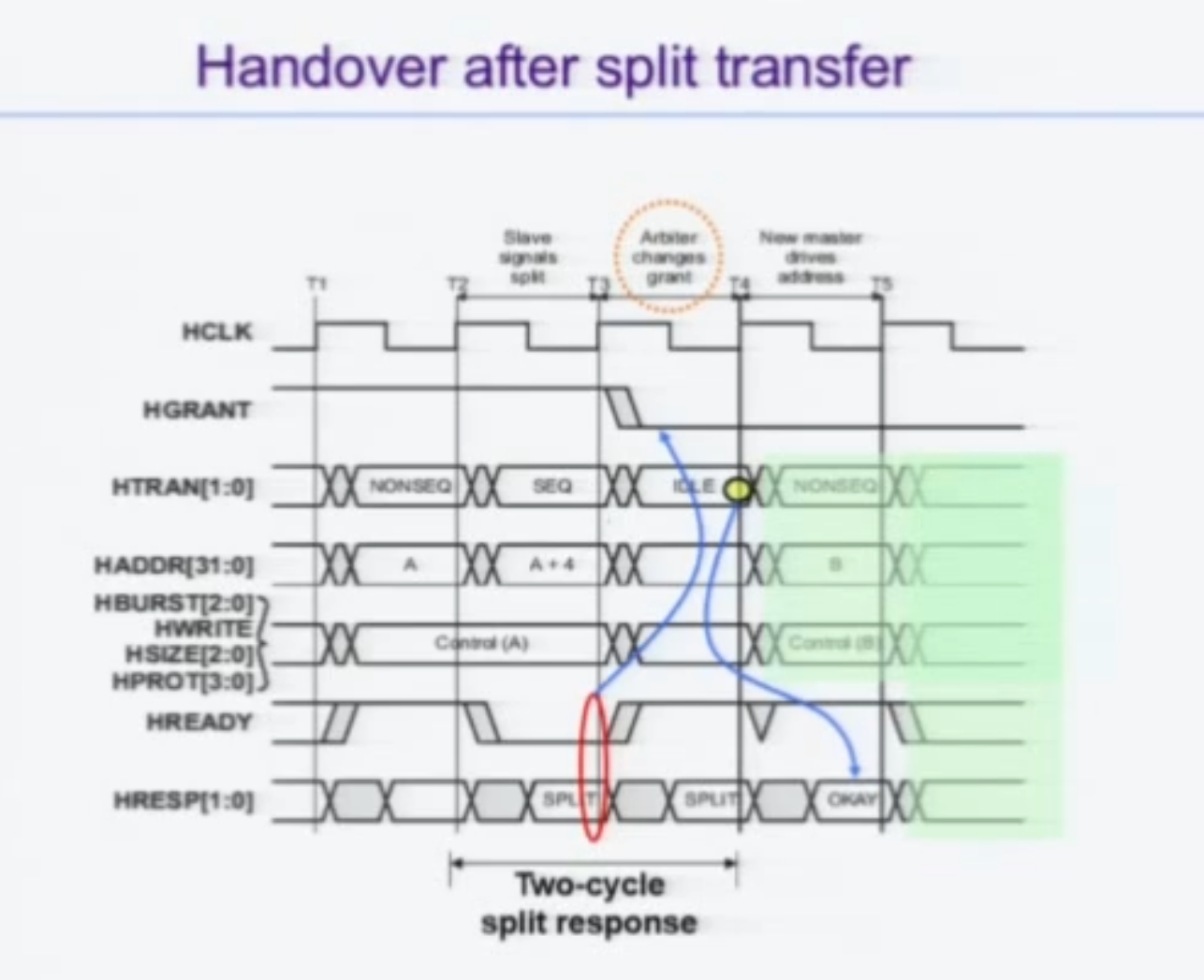
이 때는, Slave가 HRESP에 SPLIT 이라는 신호를 담아 Arbiter로 보낸다.
Arbiter는 해당 트랜잭션을 끝내고, 해당 노예로부터 OKAY라는 신호를 다시 받으면 끊었던 트랜잭션을 재시작한다.
노예가 아비터에게 OKAY를 보내고 그럼 해당 마스터(어케암?)는 한 번 더 동일한 작업을 해준다.
이 때, split 을 addr의 다음사이클이 아니라 1사이클 지연시키라고 명세되어있고, 이는 구현의 큰 편의성차이때문이다. SPLIT을 1사이클만 딱 보내버리면, 마스터는 얘가 1번은 반드시 Split인줄모르니까 주소랑 쓰기를 시도하게 되는데 음.... 솔직히 이해안됨.
어쨌든 마스터가 더 이상 진도를 못나가게 하기 위함이라고 한다.
재시작할때는 NONSEQ로 재시작함에도 유의하라.
Retry
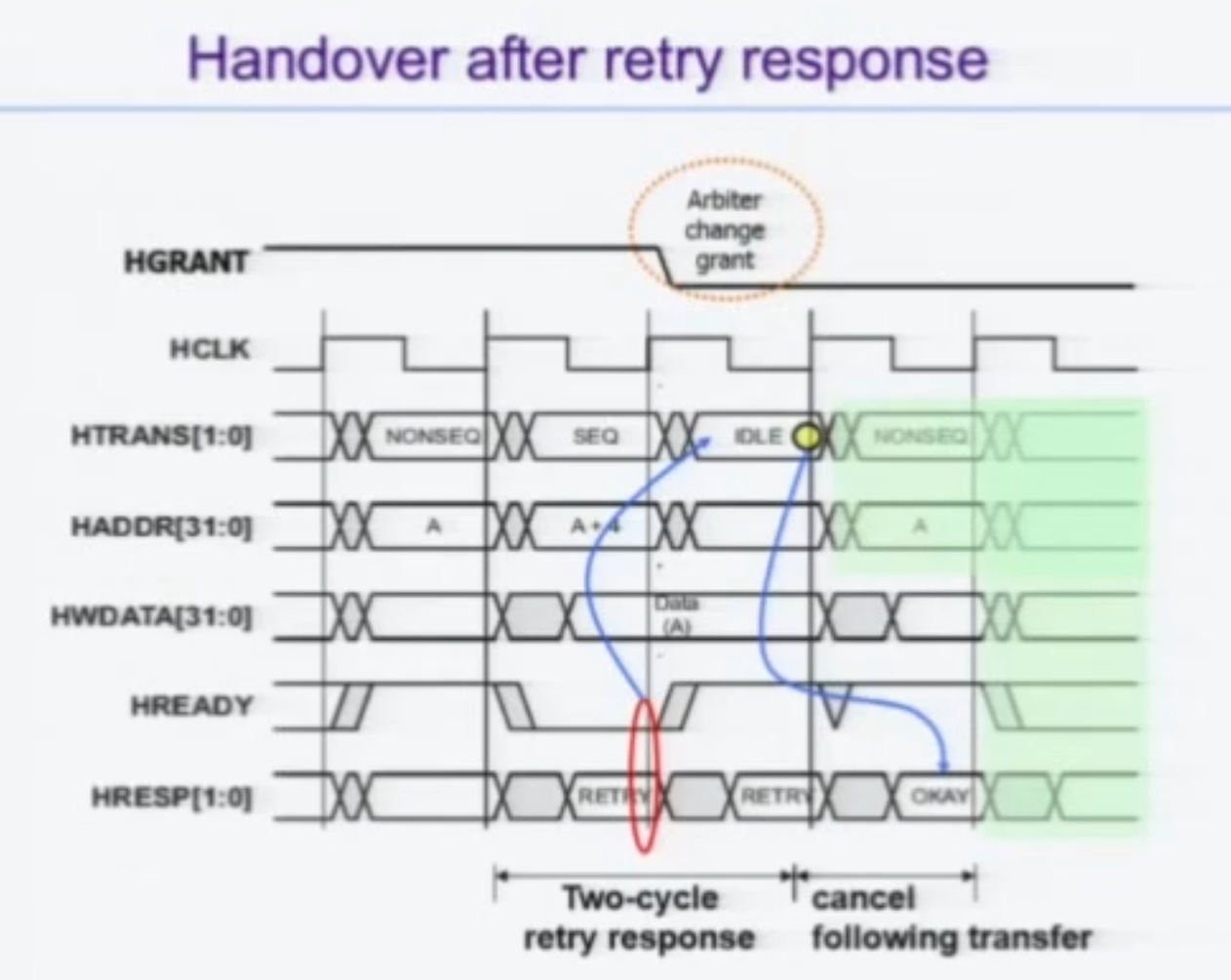
노예가 마스터에게 한 번 더 보내달라고 보내는건데, 이 역시 2클럭동안 보내야 한다.
Error
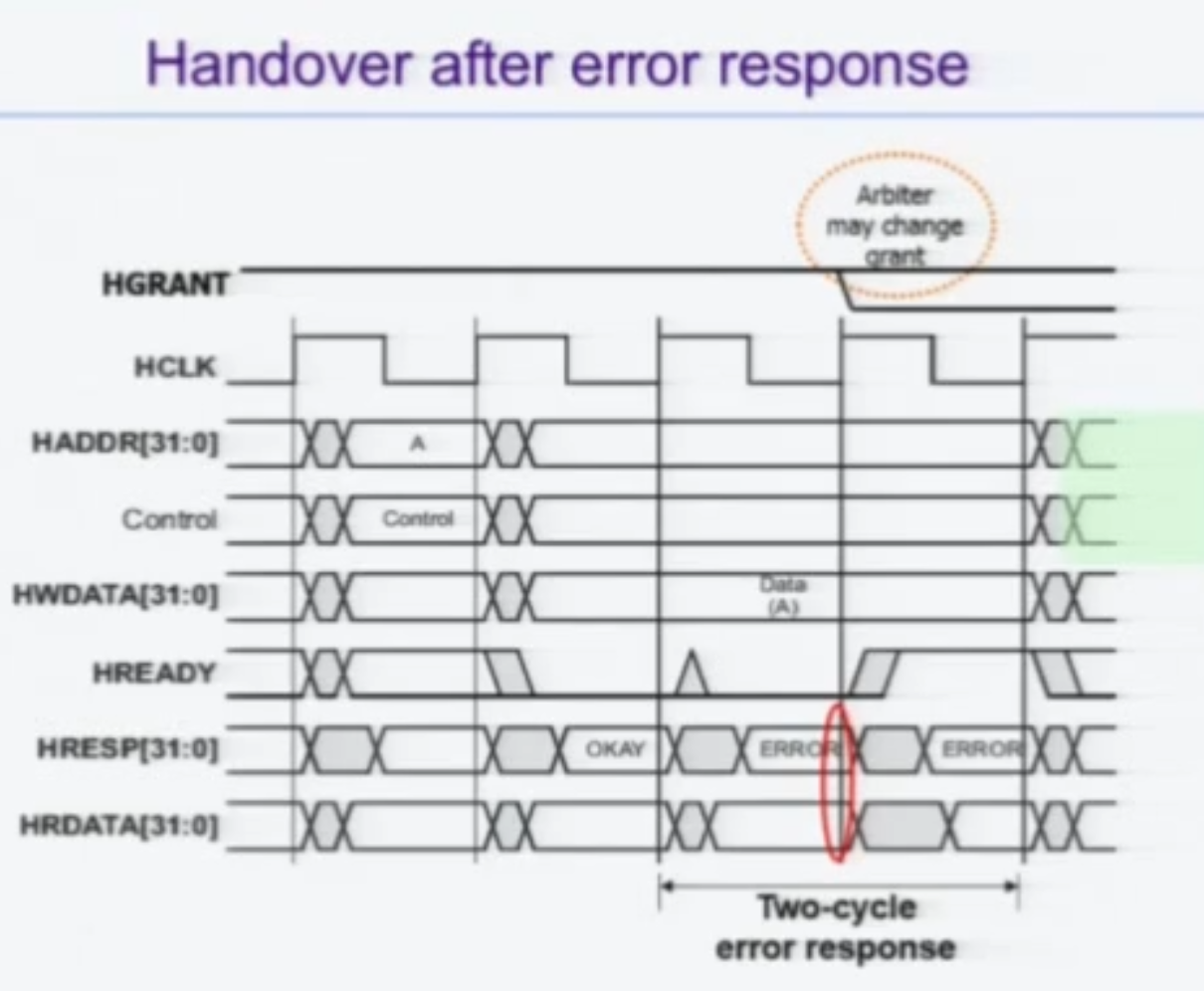
역시 슬레이브 설계자가 고려해야할 사항이다.
마찬가지로 2-Cycle Resp 임에 유의하라.
왜 HREADY 를 slave 가 체크해야 하는가?
앞서 노예측 HREADY 는 in out 둘 다 있다고 했다.

결론적으로, 이전 사이클이 안끝났는데 마스터가 자기가 Arbitration Win 했다고 ADDR 보내버리면 안되기 때문
HREADY_X 가 0인 것을 Y 슬레이브가 모른다면 HRDATA_X 가 버스를 타고 흐를 때 Y도 HRDATA_Y 를 보냄으로써 동일버스에서 충돌이 발생할 것이다.
엄밀하게는, 데이터는 문제없다. MUX에 의해 라인이 분리되어있으니까.
Address 가 통일된 라인을 공유하므로 여기서 문제가 발생할 것이다.
따라서 Y의 입장에서 X의 READY 상태를 반드시 확인해야한다.
Transfer Direction and Size
HWRITE
1이면 쓰기 0이면 읽기
HSIZE
000~111: 8비트~1024비트
Transfer Type
현재 버스를 타고 흐르는 주소신호의 의미를 해석할 단서를 제공한다
IDLE
현재 흐르는 신호를 무시해도 좋다.
BUSY
HREADY의 반대버전.
Master가 슬레이브에게 "좀 더 천천히 응답해달라" 라고 말하는 것.
NONSEQ
Single 이면 얘밖에 없다.
Burst의 경우 첫 신호.
SEQ
Burst 의 경우 두 번째 신호부터.
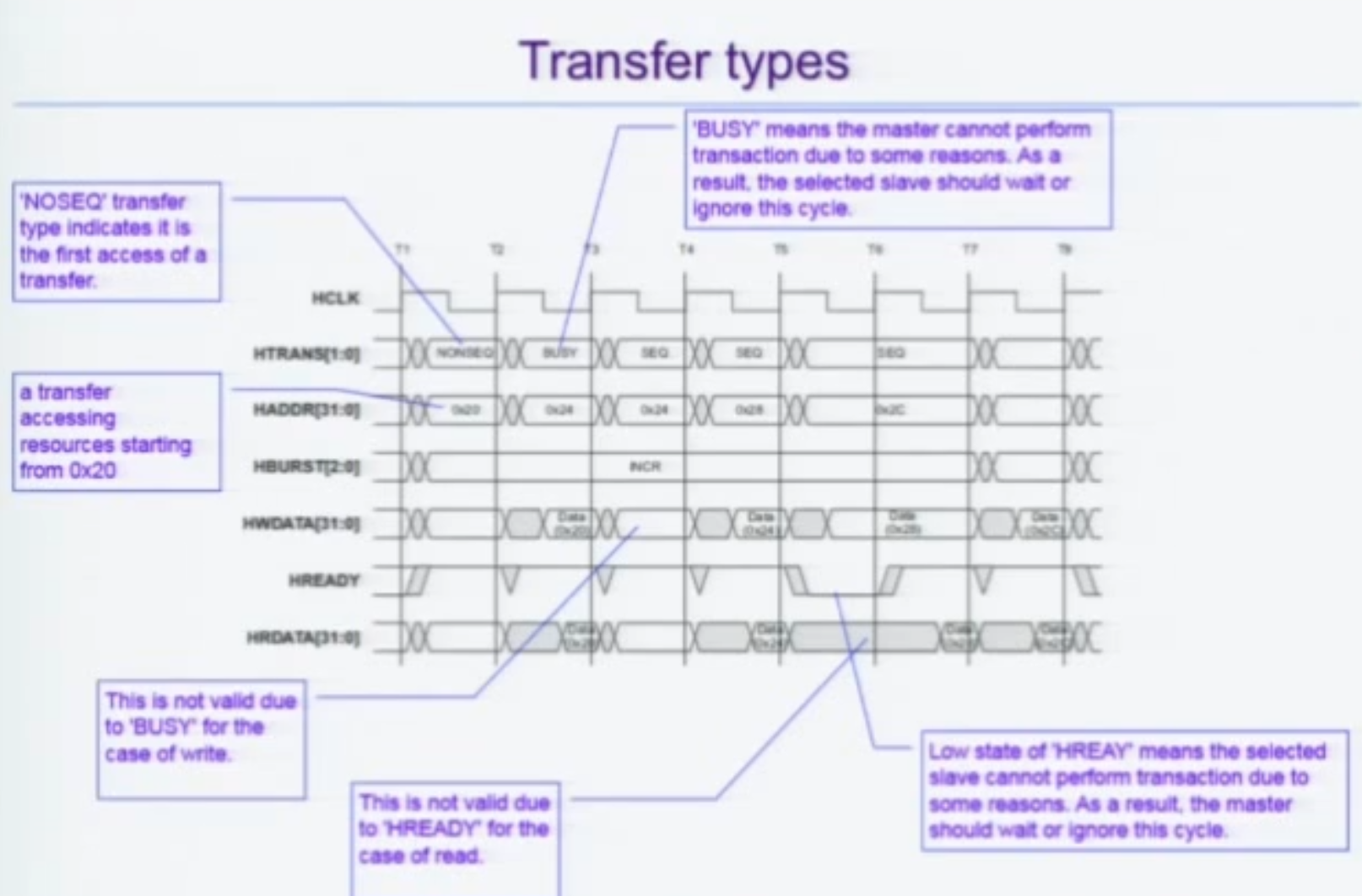
즉, 제대로 트랜잭션 동작이 되었는지를 확인하기 위해서는
GRANT가 구동했는지
TRANS
ADDR
DATA
SLAVE가 HREADY를 구동했는지
5가지를 확인하면 빠르게 체크가능하다.
BURST OPERATION
SINGLE
말그대로 NONSEQ만 보냄
INCRx
x는 Beat 수를 의미
Burst는 한 번에 1KB 를 초과할 수 없다.

WRAPx
Undefined Length Bursts
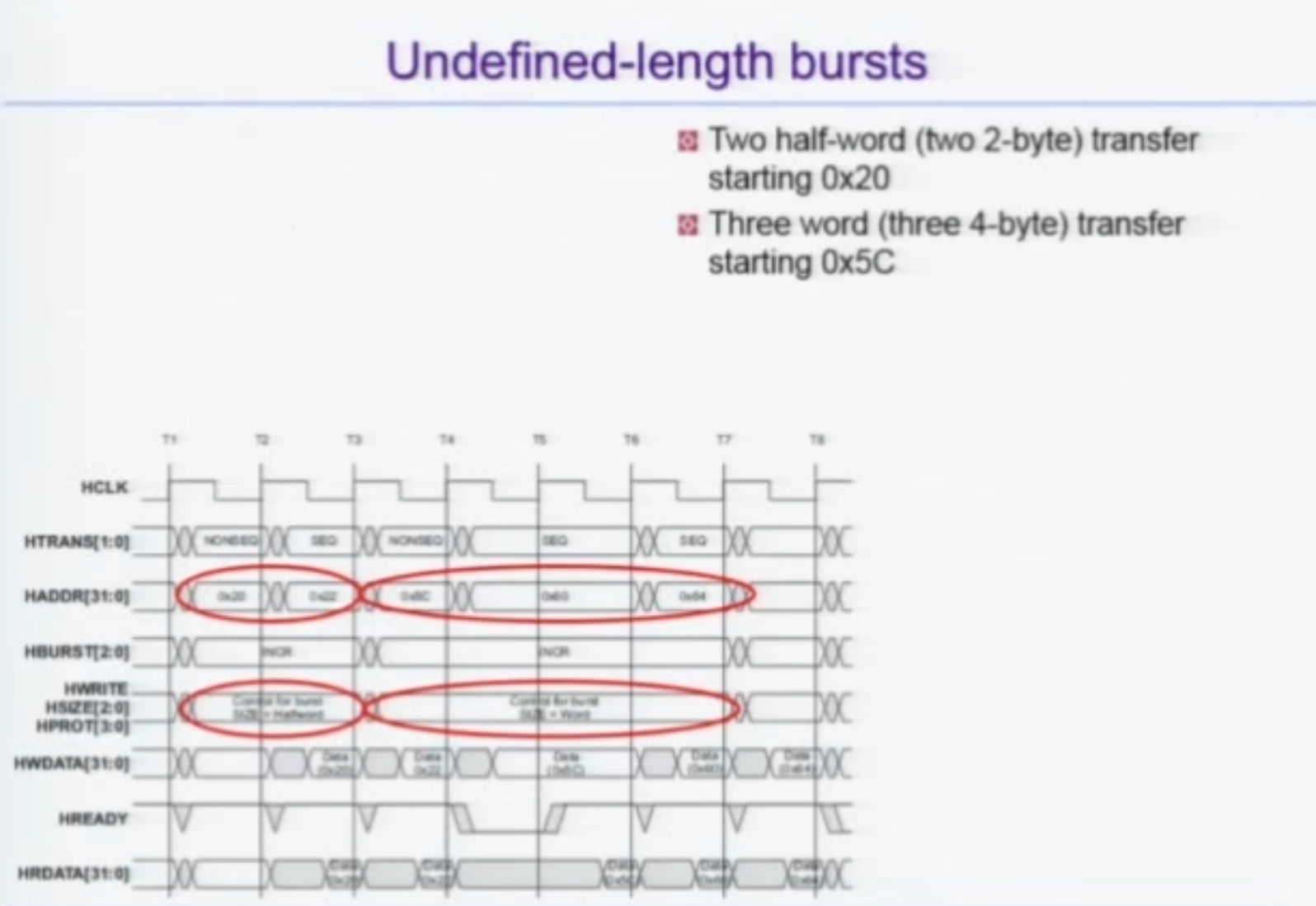
할 수는 있으나, Slave 가 얼마나 긴 처리를 할지 Deterministic 하게 알 수 없는 단점이 있다. 즉 최적화에서 불리하다.
Why Wrapping Burst is Defined?
당장 Processor 와 Memory 를 생각해보자.
AMBA로 메모리에 접근하는데만 4사이클이 소모된다.
아비터 받고, 주소 날리고 데이터 날리고 하는데 4클럭 먹힌다(세 클럭 아님? 아다리 안맞을 최악의 경우 고려한 것?).
이걸 방지하기 위해 캐시를 쓴다.
근데, 캐시는 데이터를 보관하는 단위가 KB가 아니라 바이트이다.
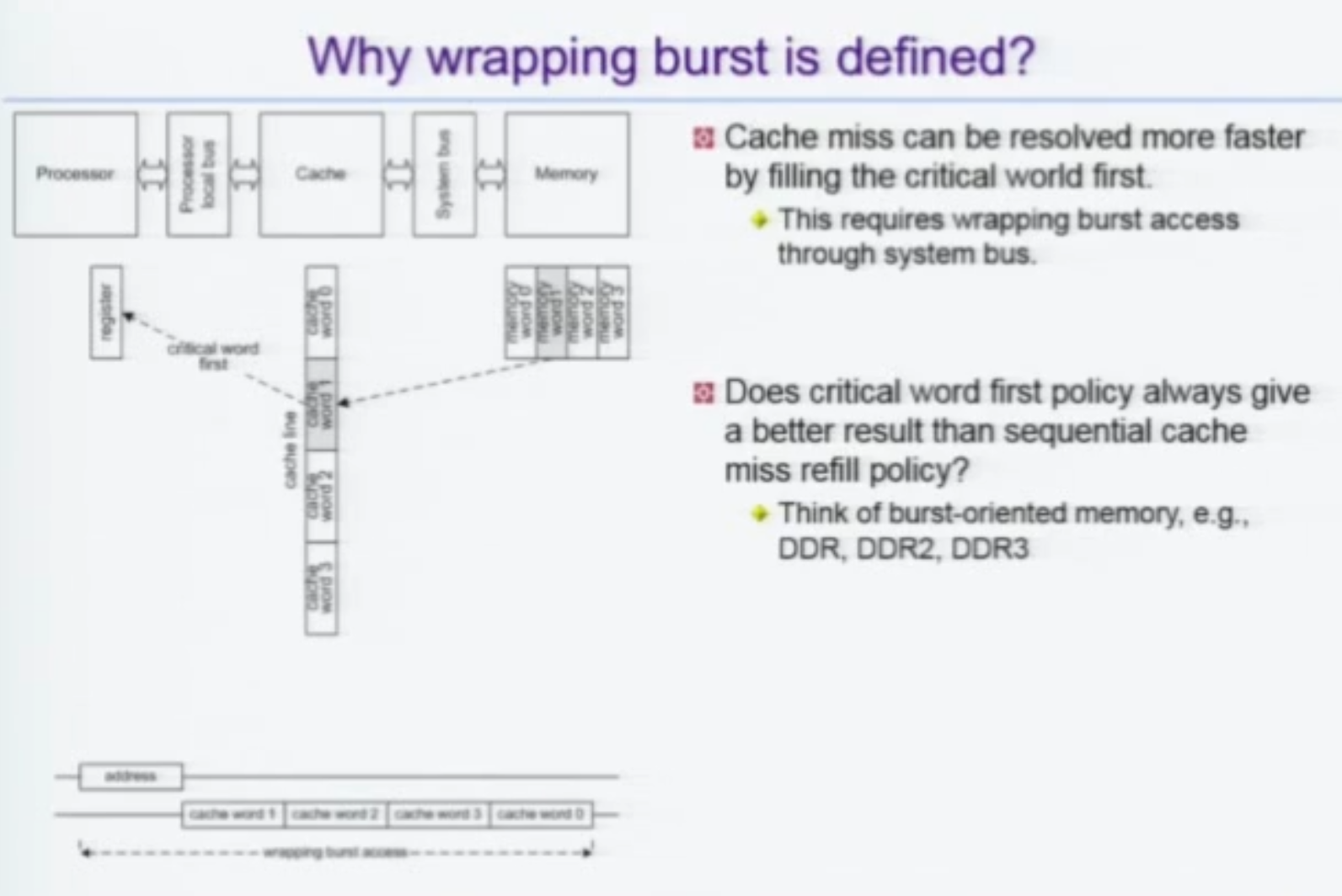
16바이트를 워드로 관리하는 캐시의 경우,
어중간한 중간꺼를 접근하다 미스뜨면, 예를들어 3번주소 접근하다 미스뜨면 0번 1번 2번 채워준 뒤에야 3번주소 채우고 리턴한다.
따라서 Critical 한 워드를 먼저 채워주는 것이 요구된다.
이것을 Critical Word First Policy 라고 한다.
왜 INCR, WRAP 의 경우 주소 상승값이 고정인데 굳이 ADDR 을 보내서 전력낭비를 하느냐?
일장일단이 있는데, Slave 설계할 때 Slave 는 단지 ADDR 를 읽기만 하면 되게끔 설계하면 된다는 구현상의 이점이 있기 때문.
HPROT 의 용도 - Write Buffer
Read 는 Write 보다 Critical 한 작업이다.
간단하다. HOST의 Write요청이 Slave에서 느리게 처리되는지는 관심없지만, Read요청의 회신이 늦다면 그만큼 기다리게 된다. 따라서 Read 는 중요하다.
따라서 성능향상을 위해 Write 를 하다가도 Read 를 처리할 샛길이 필요하다. 이것이 Write Buffer이다.
이 때 여러 문제가 생기는데, 특히 멀티프로세싱에서 문제가 생긴다.
어던 것은 Write Buffer 하지 마라는 정보가 필요할 때가 있다.
HPROT의 용도이다. 주로 MMU에서 사용하게 된다.
HRESP - for SLAVE TRANSFER RESPONSE
앞서 보았듯,
OKAY
OKAY를 제외한 신호는 반드시 2사이클동안 지속되어야한다.
ERROR
RETRY
사실 거의 안씀
SPLIT
사실 거의 안씀
SLAVE TRANSFER RESPONSE에 대해 살펴볼 점이 있다면, 한 번 Master 가 전송을 시작했으면 slave 가 ERROR, RETRY, SPLIT 등으로 중단시키는 경우는 있어도
Master 측에서 transfer 를 중단시키는 것은 불가능하다.
=> Early termination 과의 차이는 뭐지?
엔디안
AMBA의 경우 엔디안은 명세되어있지 않다. 즉 자유이다.
정리
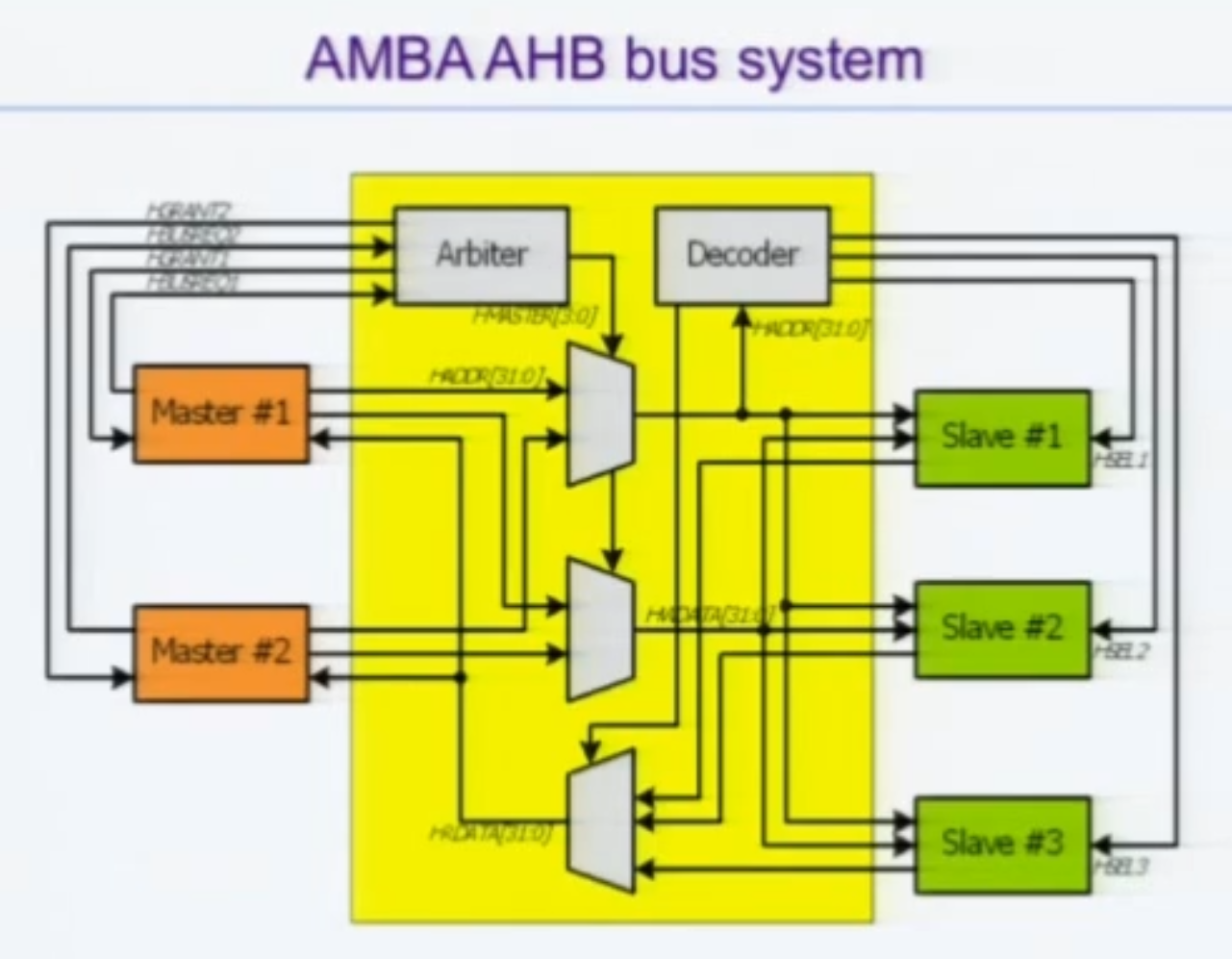
노란 부분이 BUS가 되게 된다.
AHB-Lite
Master 가 1개 뿐인 경우, Arbiter 가 필요없다.
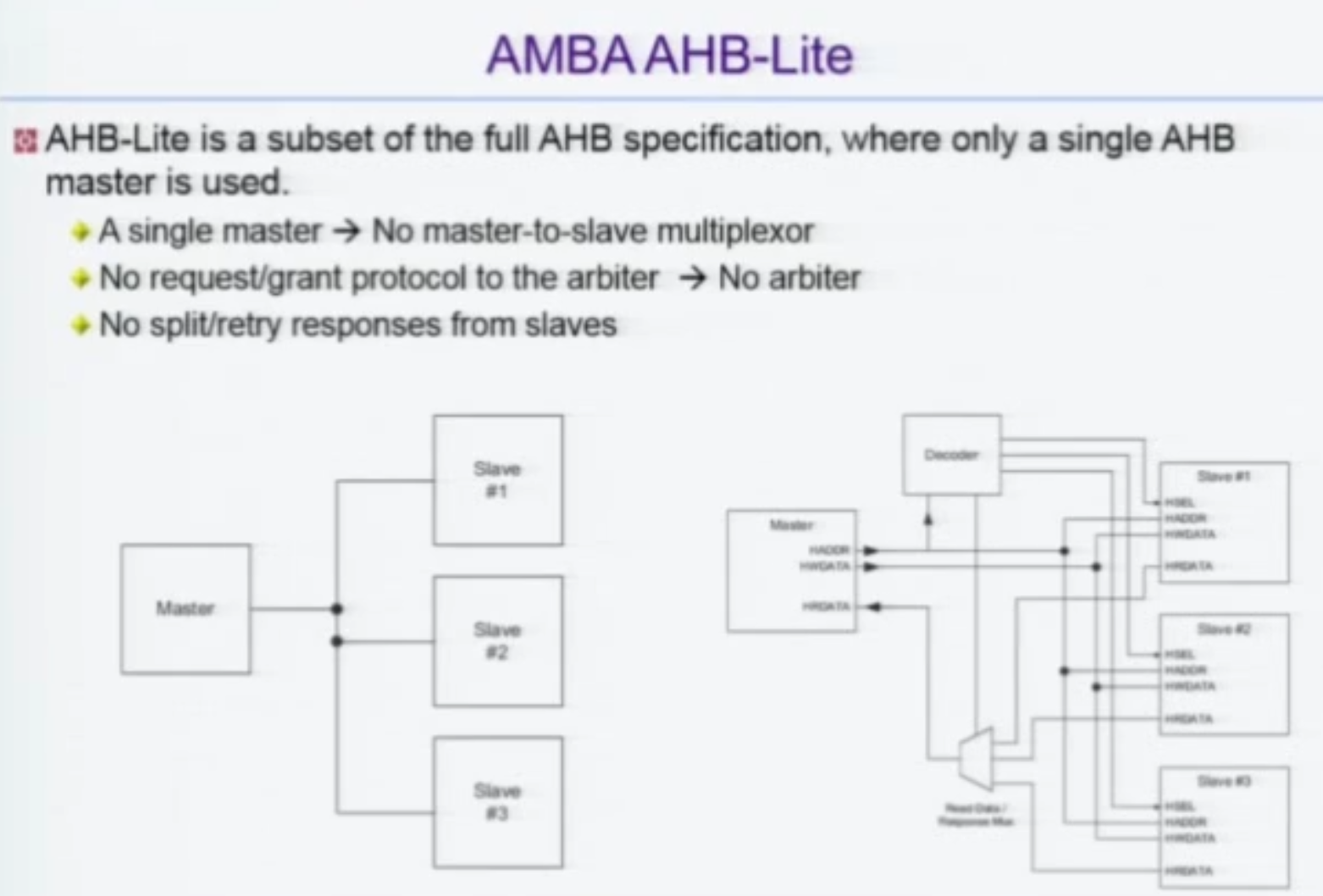
이를 AMBA-Lite 라고 한다.
Multi-Layer AHB -> 마스터1이 슬레이브1을 쓰고 있는데 마스터2가 슬레이브3을 못쓸 이유는 뭐냐?
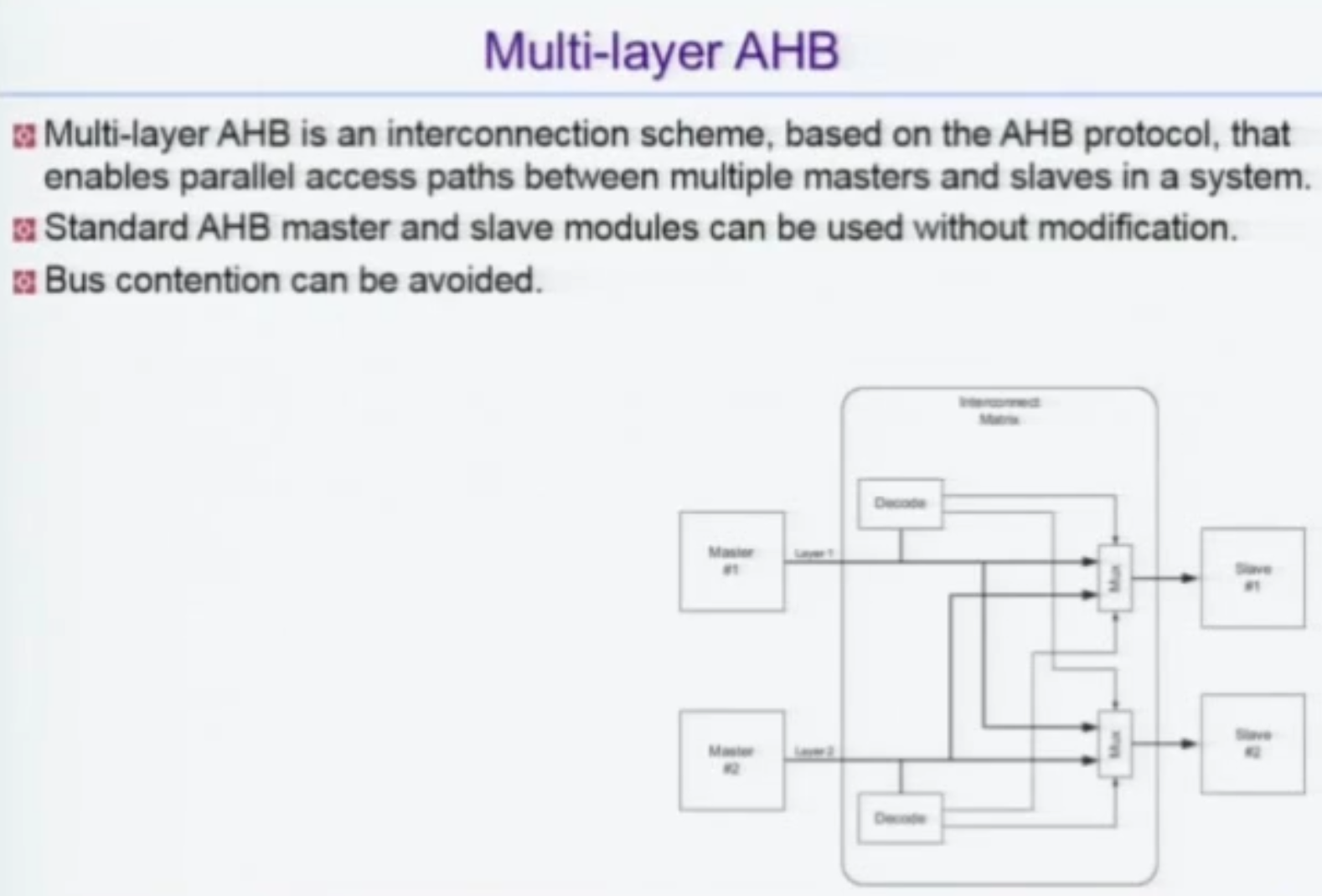
이렇게 버스를 구성하면 동시에 접근이 되는데, 일종의 Matrix 형태, Switching 형태가 되게 된다.
잡다한 질문
- 문제는, 내가 다음 사이클에 해당 주소를 처리할 수 있는 상황인지 아닌지를 나 말고 다른 슬레이브도 알아야 한다. >>> 왜?? 솔직히 납득안됨.
- Arbiter 가 왜 HREADY 를 입력받지? >>> 아, 혹시 버스가 이미 점유되었다는 사유로 빠꾸먹이는게 아니라 버스 여유가 있지만 해당 슬레이브가 바빠서 해당 요청에는 버스를 줄 수 없다는 것도 Arbiter가 판단하는거구나? 아 아니다. 마스터구나? 근데 왜 아비터 마스터 둘 다 HREADY 를 받지?
- HREADY==0이면 마스터가 GRANT를 내려놓는게 아닌가? 계속 GRANT를 쥐고있고, HMASTER로 Arbiter 내부에서 승인이 안되었을 뿐인가? Arbiter가 HMASTER 도 바꿔줄때까지 계속 마스터가 GRANT 쥐고있나?
- 위 사진에서, OKAY 신호가 왜 HREADY 신호보다 1클럭 느린가?
- "노예가 아비터에게 OKAY를 보내고 그럼 해당 마스터(어케암?)는 한 번 더 동일한 작업을 해준다." 에서, 그럼 아비터는 Split 신호가 왔을 때 중간에 작업을 끊어먹은 마스터가 누구인지를 내부에 별도의 레지스터로 저장해야되나?
- "이 때, split 을 addr의 다음사이클이 아니라 1사이클 지연시키라고 명세되어있고, 이는 구현의 큰 편의성차이때문이다. SPLIT을 1사이클만 딱 보내버리면, 마스터는 얘가 1번은 반드시 Split인줄모르니까 주소랑 쓰기를 시도하게 되는데 음.... 솔직히 이해안됨." 왜 Split Resp 는 2사이클동안 보내라고 명세되어있는거지?
- 아래 사진에서
- clk이랑 cycle은 다른 뜻인지?
- Burst 가 1킬로바이트 초과하면 안된다는게, INCR16의 경우 한 Beat 당 1킬로바이트 초과하면 안된다는건지 아니면 16번 Beat 한게 1킬로바이트를 초과하면 안된다는건지?
- INCR4의 경우 아래 사진에서

- HSIZE 3'b010에 INCR4 이니까 NONSEQ SEQ SEQ SEQ 한 뒤에 다시 NONSEQ SEQ SEQ SEQ 하는 식으로 0x38 0x3C 0x40 0x44, 0x48 0x4C 0x50 0x54 이렇게 되나?
- WRAP4의 경우 아래 사진에서

- HSIZE 3'b010에 INCR4 이니까 NONSEQ SEQ SEQ SEQ 한 뒤에 다시 NONSEQ SEQ SEQ SEQ 하는 식으로 0x38 0x3C 0x40 0x44, 0x38 0x3C 0x40 0x44 이렇게 되나? 아니면 초기화되는 단위는 4의 배수인 0x38 0x3C 0x30 0x34 , 0x38 0x3C 0x30 0x34 가 되는게 아닌가? 첫 아다리는 고정이 아니라 변동이라는 뜻인가 맞나? 전자가 맞는것같긴한데, 첫 주소를 기준으로 하는 변동인가?
- Why Burst Wrapping is Defined? 아직도 이해가 안된다.
- Early Termination 은 Master 에 의해 수행되는 것 아닌가? 무슨차이지?

그냥 둘러보다가 글남겨요~~.
Early burst termination과 SPLIT 동작에는 큰 차이가 있습니다.
SPLIT 의 경우 Slave가 자신이 아직 Command를 처리할 준비가 안되었을 때 ( Ex. Slave 단 Buffer가 꽉찼거나 기타 등등의 이유로), Command를 보내줄 Master가 Bus를 계속 점유하게 되면 System bus performance가 떨어지게 됩니다. ( 다른 동작을 해야할 Master 들이 동작을 못하고 기다리고 있기 때문에 )
따라서 다른 Master 동작할 수 있도록 Slave는 SPLIT 신호를 내주어 Bus 점유를 다른 Master가 할 수 있게 해줍니다.
Early termination은 Master가 단순히 Bus 소유권을 잃어버린 경우에 발생됩니다. ( Arbitration scheme에 따라 Ex. 할당된 시간내에 모든 동작을 끝마치지 못했을 경우. ) 이는, Slave가 판단하는 것이 아닌 Arbitration scheme에 따라서 현재 Master의 동작이 중단되고, 다음 차례에 해당 Master가 Bus 소유권을 가지게 되었을 때 남아있던 Burst 동작들을 수행하게 됩니다.~~.