3교시 - Digital System Review
대략 학부2학년 수준의 강의이니 가볍게 들으면 될 것 같다.
MSB, LSB 헷갈리지 말기

헷갈리면 안되는데, 가끔씩 헷갈려서 기재한다.
16진법 알파벳 하나가 0.5바이트임에 유의
Unsigned Number System
중학교때 배울 이론.
음수를 포기하는 대신, 가장 간단하다.
Sign & Magnitude Number System
논리회로 1학년때 배웠을 이론.
MSB 1개를 sign 표기용으로 포기한다.
대신 0이 두 개 있는 단점이 있는 수 시스템.
다만, 절댓값 판별이 빠르고 양/음 판별이 빠르다는 장점이 있다.
따라서, 절댓값을 자주 취하는 알고리즘의 경우 현재도 드물게 사용되기도 한다.
2의 보수 Number system
역시 논리회로 1학년때 배웠을 이론.
0이 한 개 있는 단점이 있는 수 시스템.
덕분에 음의 범위가 양의 범위보다 1 크다.
MSB가 1이면 무조건 음임이 보장되기 때문에 양/음 판별도 쉽다.
Sign Conversion은 모든 비트를 뒤집고 1을 더하는것으로 구현된다. 음->양 양->음 모두 동일.
폭이 다를 때, Bandwidth를 어떻게 확장할 것인가?
큰 버스에서 좁은 버스는 오히려 쉽다. 그냥 잘라버리면 되기 때문이다.
이것은 좁은 버스에서 큰 버스로 옮길 때의 issue이다.
Sign Extension
MSB를 그대로 append한다
Zero Extension
무지성으로 0만 그대로 append한다.
연산이 쉽고, 에너지효율이 좋다는 장점이 있다.
다양한 Digital Building Blocks
- Gate
- Mux
- Decoder
- Register
- Arithmetic Circuit
* Full Adder- Half Adder
- Counter
- Memory Array
- Logic Array
가 가장 기초적인 블록이다.
Functionally Complete
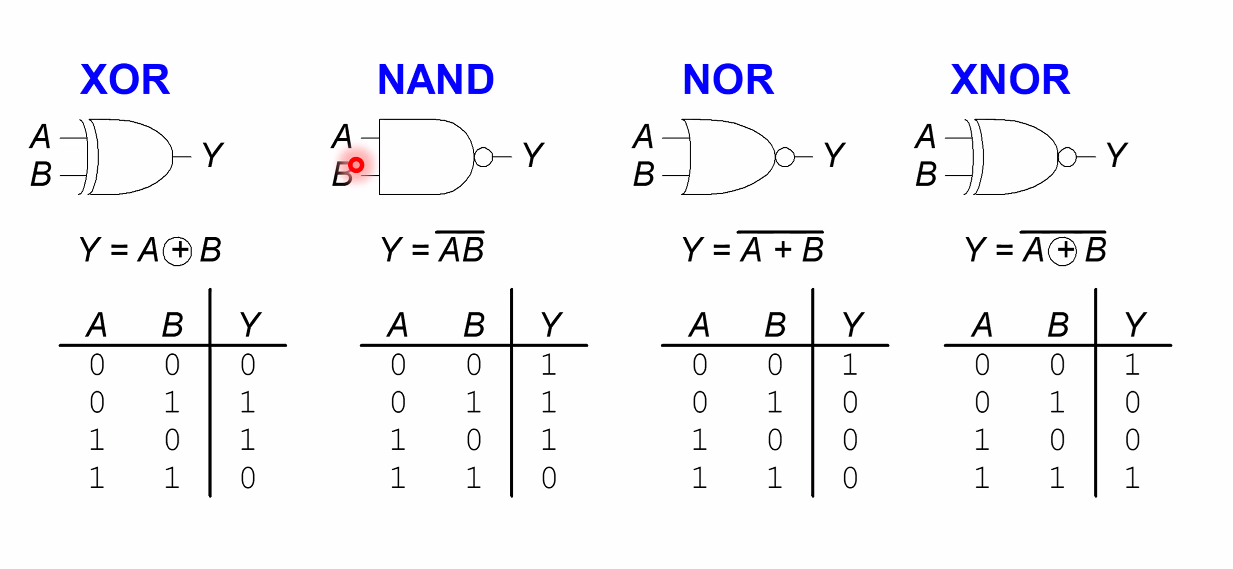
위 4가지 Gate 는 한가지만으로도 어떠한 logic도 구현할 수 있음이 알려져있다.
참조
Carry Propagate Adder(CPA)의 종류
Ripple Carry(slow)
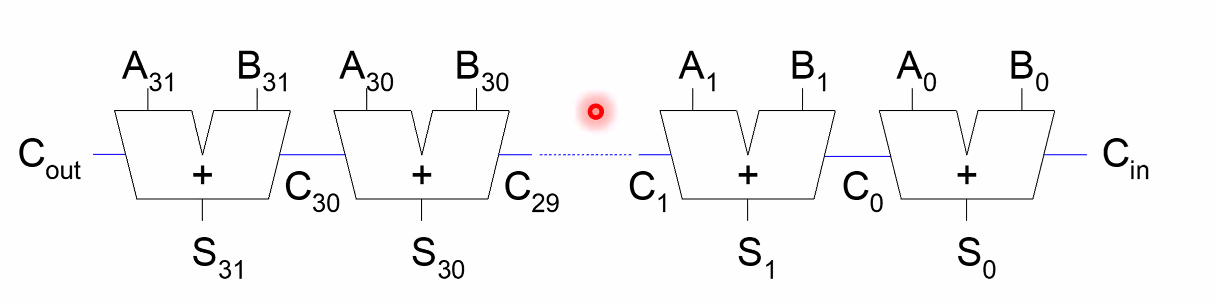
CarryChain 이 모든 비트를 지나가야 하기 때문이 필연적으로 느리다.
다만, 가장 적은 HW Cost 가 들고 가장 직관적이며 간단하기 때문에 연산성능이 크게 요구되지 않으면 도리어 가장 효율적이다.
일반적으로 Under 8-bit 의 경우 RC 를 사용한다고 한다.
Carry Lookahead(Since Pentium) Adder
Generate Signal Gi와 Propagate Signal P_i 를 사용하고
$C_i = A{i}B{i}+(A{i}+B{i})C{i-1}$
는 되는데 위는 왜 수식이 깨지지?
어쨌든 CLA는 구글링하면 많이 자료 나온다.
일반적으로 16비트 이상에서는 확연한 이득이 있다고 알려져있다.
다만 Area 가 크고, 복잡하여 비직관적이라는 단점이 있다.
Prefix Adder
생략
ALU Design
내일 설명
Shifter 의 종류
Logical Shifter
Arithmetic Shifter
Left Shift 는 동일하고, Right Shift 가 다르다.
Right Shift 시 MSB를 복붙하여 Append한다.
Rotator
Shifter Design
의외로 많은 연구가 있다고 한다.
잠깐 본 회로도상에서는 Mux가 사용되는데, Shift 구현법을 나중에 한 번 봐야겠다.
Shifter as Multipliers or Dividers
A<<N == A*2^N
ex) signed unsigned 공통이므로 동일
A>>N == A/2^N
ex) Right Shift 이후에도 음수의 경우 부호가 유지되므로, Arith shift 의 경우임에 유의
8/2^2=2
-16/2^2=-4
보통 곱셈기는 덧셈기의 10배
나눗셈기는 곱셈기의 10배 비용이기에
안쓸 수 있다면 안쓰는게 나은데, Shifter 로 대체가능하면 매우 저렴하게 구현가능하다.
Counter Design
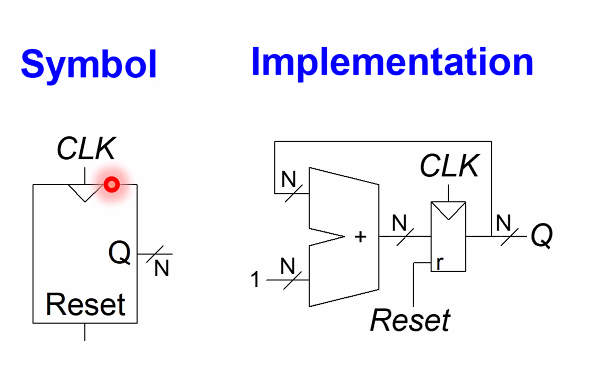
다양한 분야에 사용되는 Counter의 Design이다.
Shift Register Design
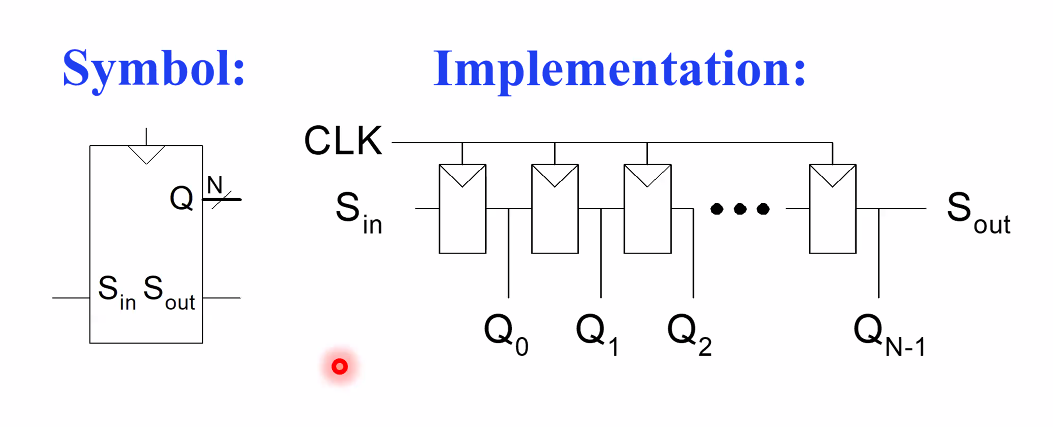
FIFO 와 비슷한 용도로 쓰이는 Component이다.
1바이트전송시 8겹의 lane 을 깔기엔 비용이 크다면
이를 serial 하게 보낸 뒤에 다시 parallel 하게 읽음으로써 reconstruction할 수 있는데, 이런 용도로 쓰인다.
즉 Serial-Parallel, Parallel-Serial 변환에 사용된다.
Shift Register with Parallel Load
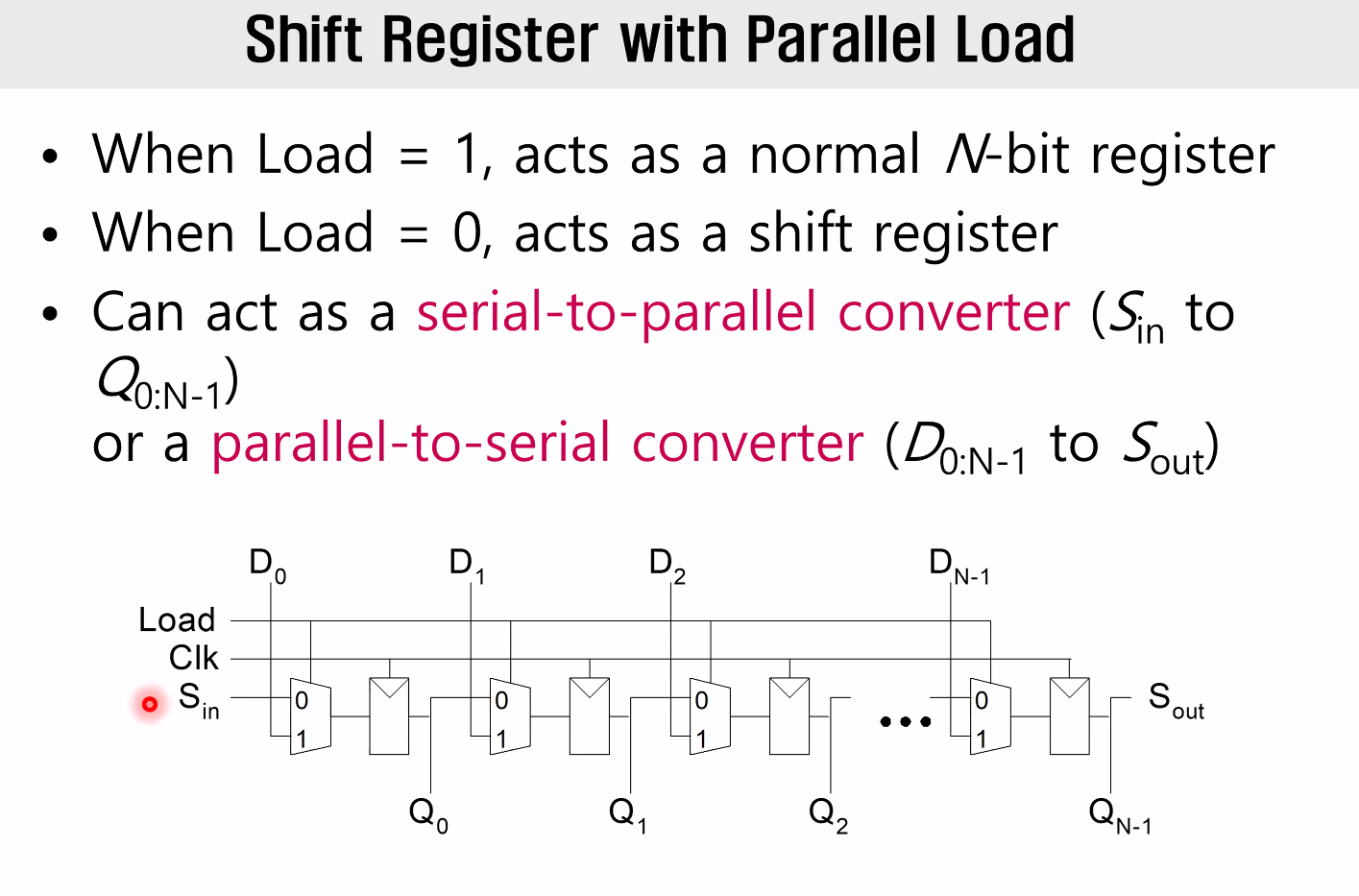
D로써 S의 serial한 입력이 Parallel하게 출력되는 것을 볼 수 있다.
디지털 SoC 구조라고 되어있는데, 약 1/4 정도 수강이 되었지만 일단 현재까지는 컴퓨터구조개론과 동일하다.
음... 2일차가 되면 좀 SoC가 되려나.
4교시
SOC의 핵심구성요소
- Core
- Memory system
- Accelerator
- On chip bus
ISA란?
HW 엔지니어에게 있어서는 내가 설계하는 HW가 어떻게 동작해야하고 무엇을 제공해야하는지를 명세하는 구간
SW 엔지니어에게 있어서는 자신이 다루는 HW가 제공하는 가장 low-level의 도구를 얻을 수 있는 구간
Instruction Set 에만 집중하는게 아니라,
Register 구조와 용도 및 CPU 내의 저장공간 등등 CPU 전반의 Architecture 에 대한 정보를 SW 엔지니어에게 제공해야함
The Stored Program Concept
Program is stored with data in the computer's memory.
지극히 당연한데, 예전의 튜링시절 프로그램이 HW에 구현되고 그런 방식이었던듯.
아, 그 시절엔 진공관 배선으로 프로그래밍하는거였었나?
폰노이만 구조
구현할 때 메모리구조를 어떻게 설계할지에 따라 갈린다.
하버드 구조
둘이 구분되는 개념인줄은 처음알았다...역시 안다고 착각해도 잘 들어야한다.
참조링크
Classical한 Instruction Set 분해
add r1, r2, r3
알테니 스킵한다.
Data Movement Instruction
- Load: Mem->Reg
- Store: Reg->Mem
- Move: Reg->Reg
Arithmetic and Logic(ALU) Instruction
Branch and Control Flow Instruction
70~80s의 CPU 발전방향
4 Address Instruction
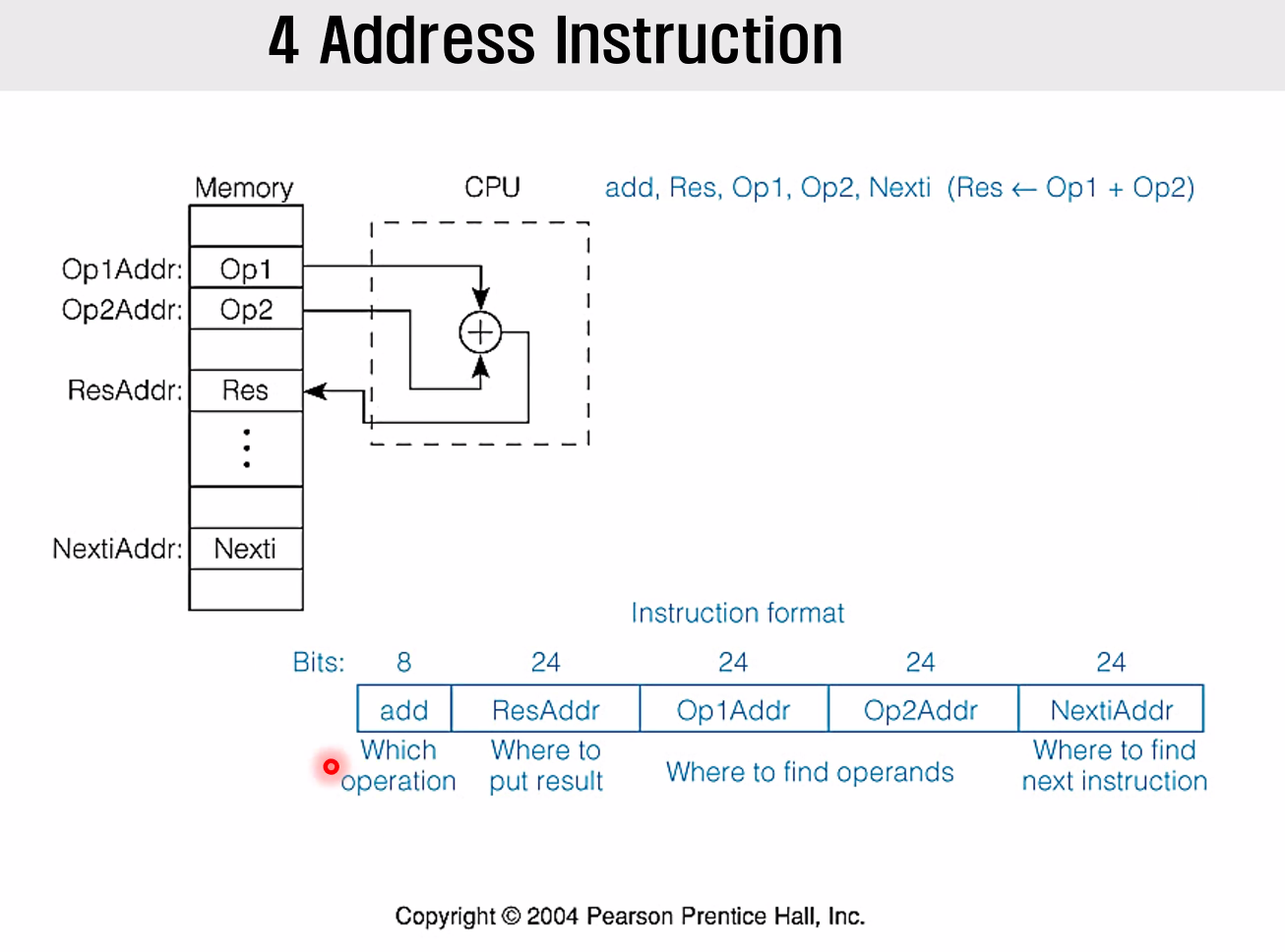
256가지의 연산종류를 택할 수 있고, 메모리의 종류가 24비트로 표현될 때 메모리 주소값 4개가 Serial하게 명령어에 붙어있음을 확인할 수 있다.
즉 CPU 내에는 어떠한 저장공간도 없고, 메모리로부터 op1 op2를 읽어온 뒤 다시 메모리에 res에 저장.
그 뒤 메모리의 next addr 을 다시 가져온다.
하나의 명령어를 위해 100비트가 넘는 instruction size 를 자랑하는, 매우 초창기 instruction set 이다.
명령어의 size가 너무 커지기때문에 보완이 필요했다.
이에, Address 수를 줄일 필요가 있었다.
3 Address Instruction
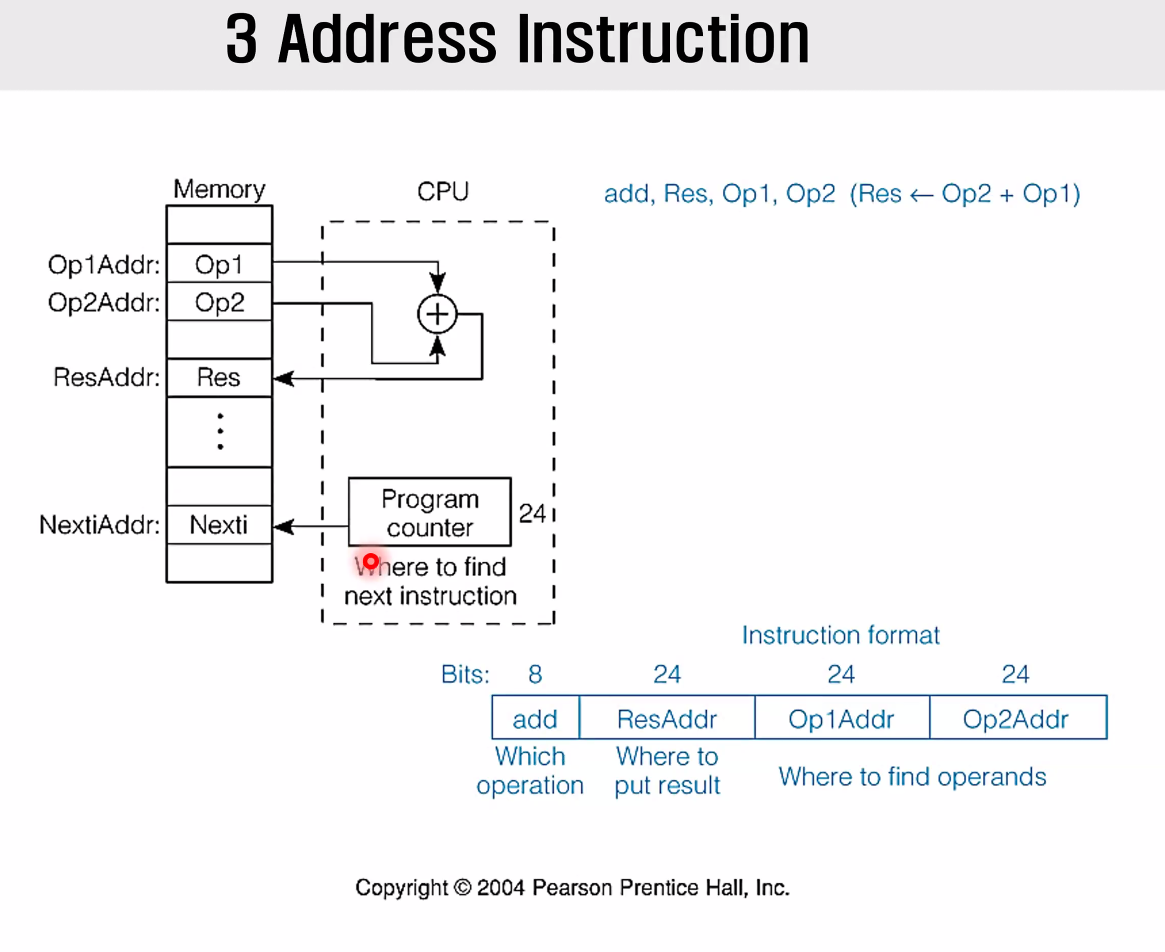
그렇게 엔지니어들이 생각을 해본 결과, 마지막 NextiAddr은 필요가 없다는 생각을 하게 되었다.
PC라는 내부적으로 24비트를 저장할 수 있는 저장소를 CPU내부에 만들어놓고, NextiAddr는 단순히 PC에 담긴 값만 가져오고, PC는 +=1 또는 loop, function 같은 특이한 상황의 경우만 예외처리되게끔 설계하였다.
그 결과, 아래처럼 24비트를 한꺼번에 줄였다.
그러나 여전히 길다.
operand 주소가 24비트씩이기 때문이다.
어떻게 줄일까?
2 Address Instruction
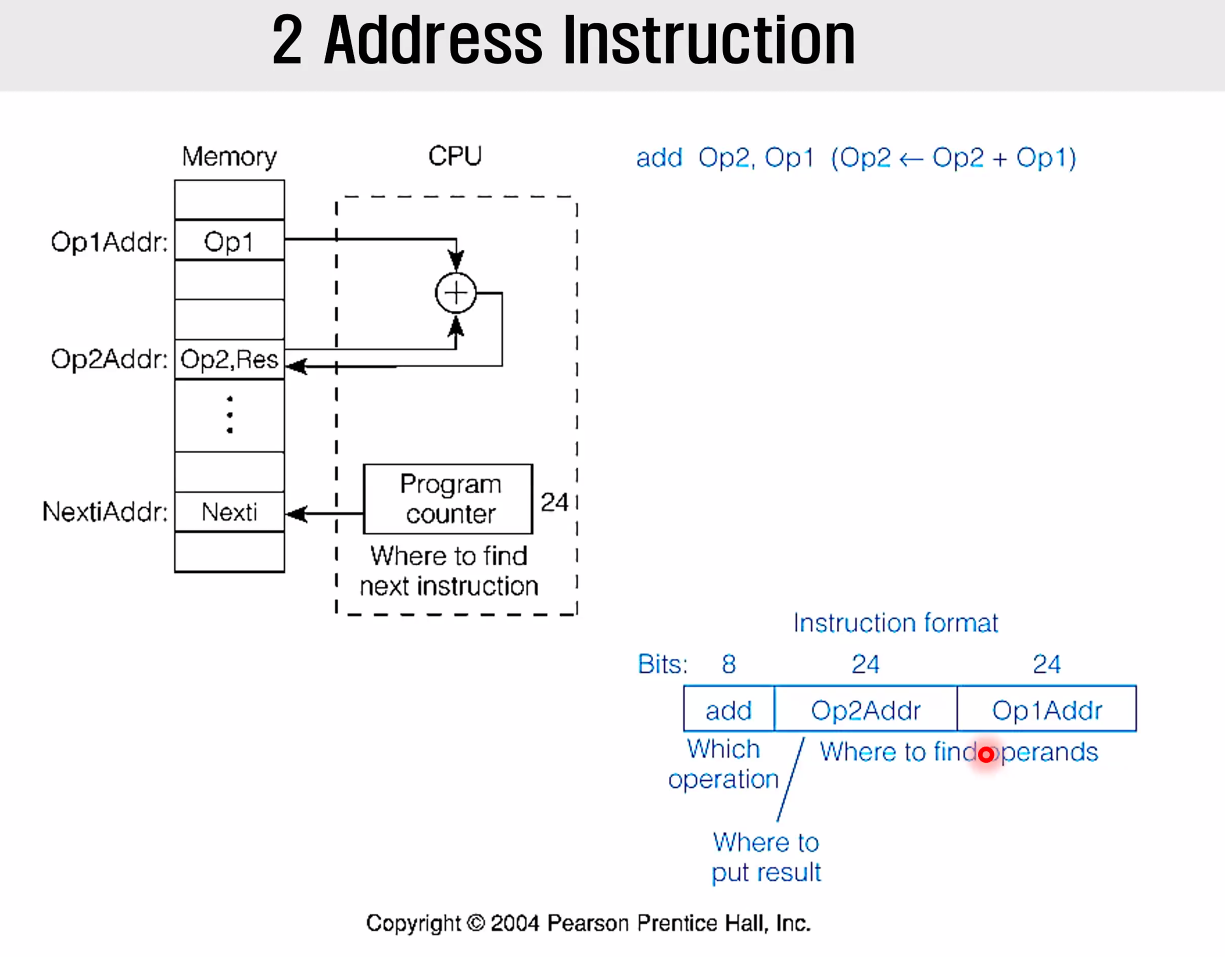
사람들이 곰곰이 생각해보니, Op1 Op2 로 연산해서 Res 에 저장할 때, 대부분의 경우 재사용없는 add op1 op1 op2 꼴이었다는 것이다.
keep해야하는 특이한 상황에 대한 부담의 경우 instruction을 별도로 추가함으로써 해결가능하고, 그 cost가 훨씬 저렴하게 바뀜을 확인하고 이를 사용했다.
그러나 반드시 줄어드는건 아니고,
명령어에 비대한 메모리를 희생하는 대신 Fetch하는 갯수가 줄어든다는 3 Address Instruction 은 고성능용으로 사용하였다.

Memory to Memory Architecture
위의 모든 것과 같이 메모리에서 메모리로 쓰는 아키텍쳐이다.
이렇게, High Speed한 아키텍쳐를 적은 instruction 으로 구현가능하며 컴파일러 구현이 쉽다.
다만, Memory Traffic 이 매우 커지며, 메모리 접근에 따른 CPI가 다양해지는, 파이프라이닝에 있어서 애로사항이 발생한다.
더욱이, two operand 의 경우 추가적인 data movement 가 요구된다는 점에서 단점이 있다.
1 Address Instructions- Accumulator Machine
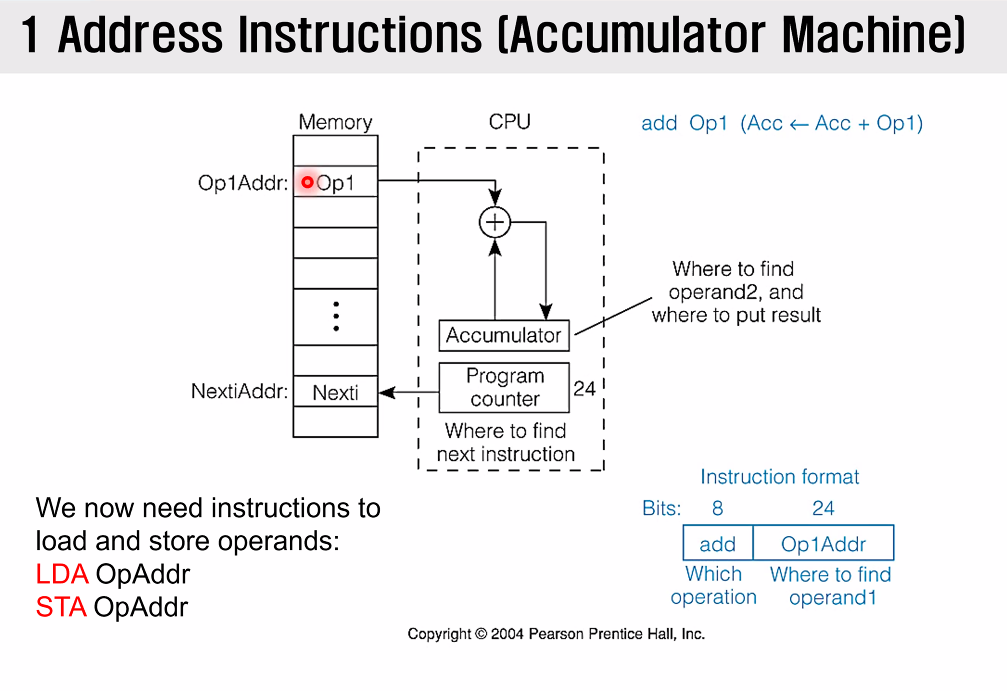
이제 극단적으로 줄였다.
피연산자 중 하나를 Accumulator Register에 저장하고, 연산결과 또한 Accumulator Register 에 덮어씀으로써 저장해야하는 공간조차 줄였다.
이에, 비로소 Load 와 Store 라는 개념이 최초로 생기게 된다.
register 와 memory 라는 두 메모리가 공존하게 되었기 때문이다.
여담으로, Shenzhen IO 라는 어셈블리 코딩 게임이 있는데, 해당 게임의 가장 저렴했던 MCU가 지금보니 Accumulator Machine 이었다.
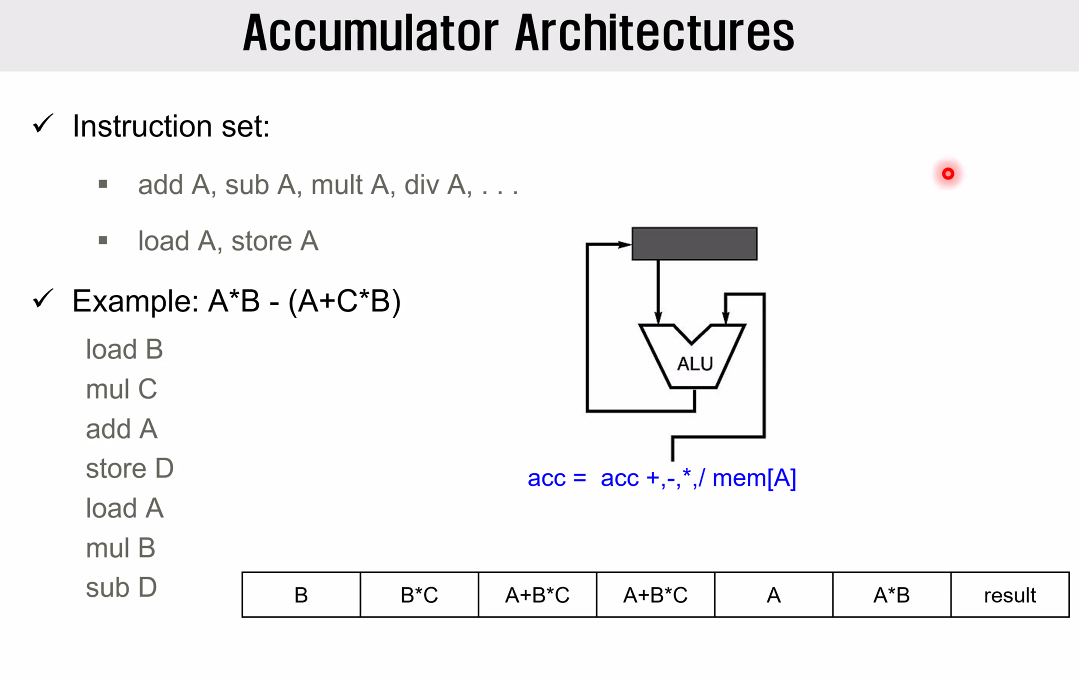
장점으로는 아주 쉽게 구현이 가능한 반면,
Accumulator 에 접근하는 과정자체가 위와 같이 비대한 코드의 형태로 Bottleneck 이 되어버린다.
그리고 Parallelism 및 Pipelining 을 사용하기 힘들며, Memory Traffic 또한 너무 큰 단점이 있다.
0 Address Instructions - Stack Machine
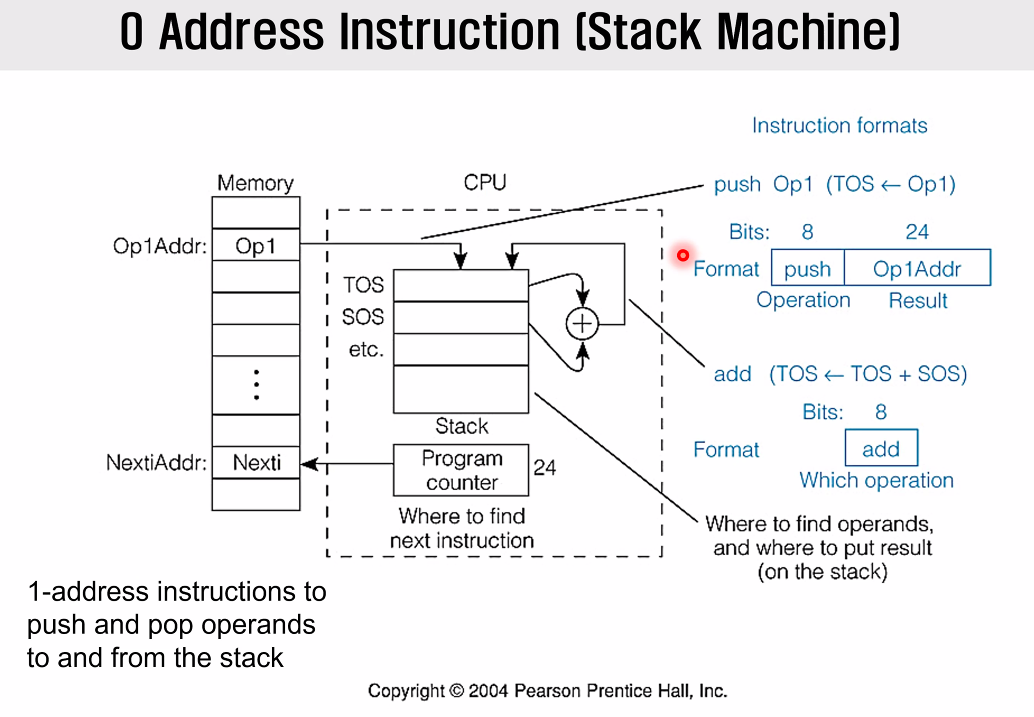
이제 극단적으로 줄였다.
스택을 사용하면 사실 메모리의 주소를 유지할필요조차 없다. 어차피 접근가능한건 top밖에 없으니까.
Half Address Instruction 이라고 부르기도 한다.
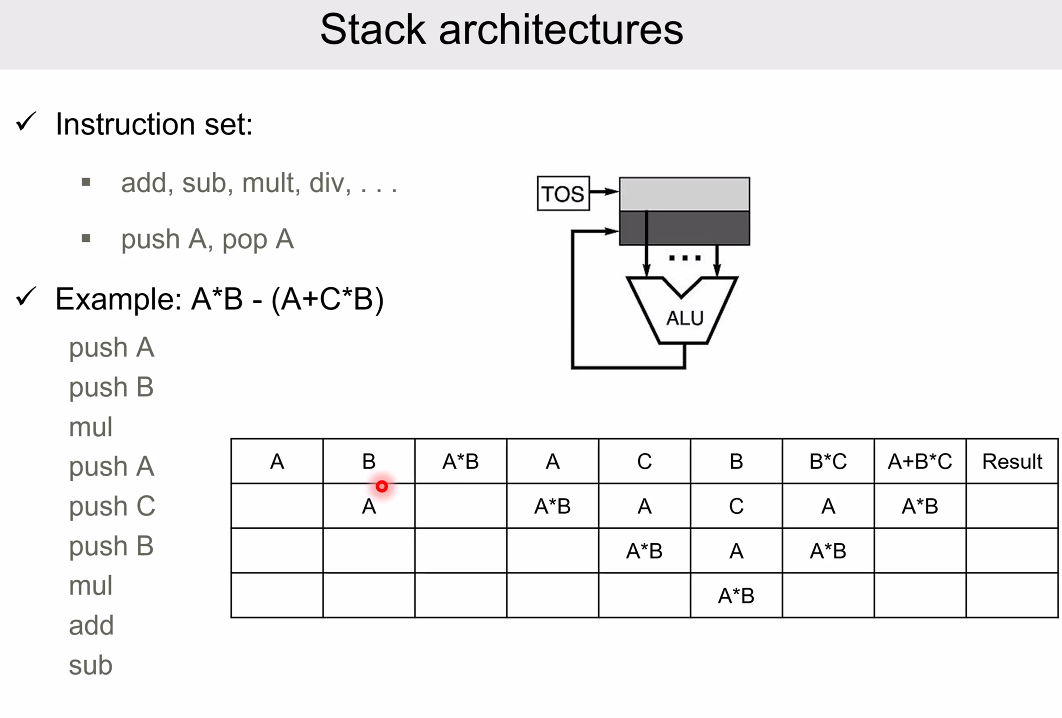
따라서 이런 간단한 연산을 함에 있어서도 이와 같은 비대한 기계어가 나온다.
push와 pop, add/sub/mul/div 같은 정말 essential 한 것밖에 없기 때문이다.
장점으로는 대부분의 instruction 비트를 날려버릴 수 있다. 정말 극단적으로 줄였다.
따라서 HW Requirement도 낮고, Compiler도 Stack이면 오히려 친화적이므로 구현이 매우 편하다.
다만, parallelism 과 pipelining 에 애로사항이 있고, top만 접근가능하므로 top이나 swap 의 연산에도 큰 비용이 들게 된다.
stack architecture 는 더 이상 최적화하는데 한계가 있다고 알려져있다.
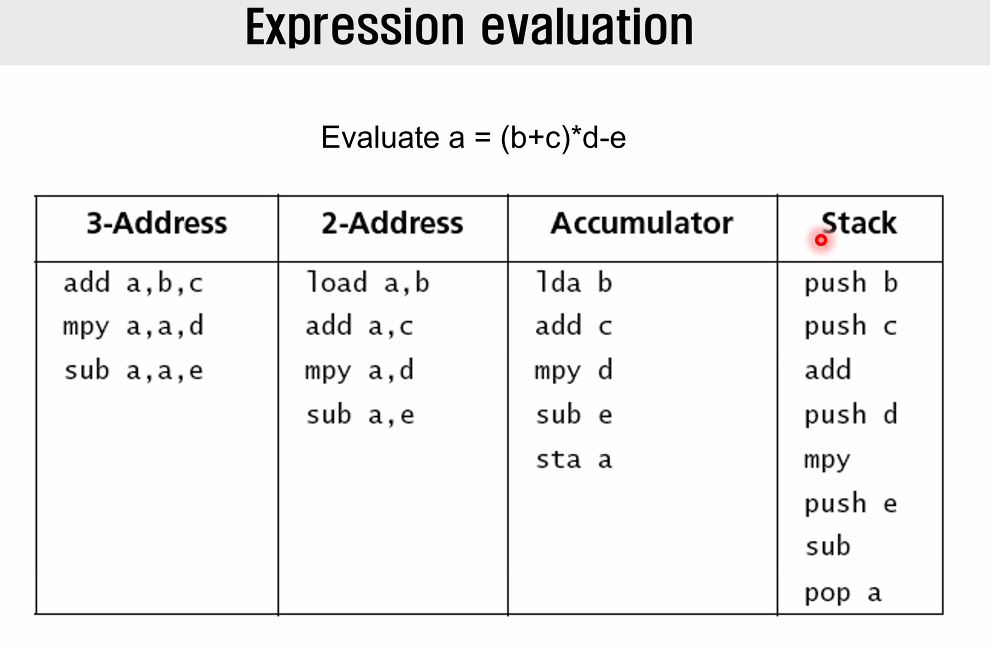
위와 같이 점점 instruction의 size는 줄지만, line 수는 늘어남을 확인할 수 있다.
이것이 초창기 CPU의 발전방식이다.
혁신 - General Register Machines
CPU 내부에 여러 개의 Register를 두고, Register 내부에서만 연산가능하며 Memory는 Register와 Load, Store 와만 소통가능토록 하였다.
Register-Memory Architecture
instruction 의 종류를 최소화할 수 있으면서도 register 개수는 적으므로 operand 에 필요한 instruction bit 이 줄고, 속도도 확보할 수 있다.

Full memory address 는 load, store 시에만 활용되므로 instruction bit 을 확보할 수 있다.
Register-Register or Load-Store Machine
모든 피연산자들의 위치와 그 결과저장소를 Register 로 한정하는, Load-Store Architecture 라고도 한다.
Register-Register와 Register-Memory와의 차이는 위와 같은데, X86과 RISC 의 차이같다.
직접 메모리에 접근가능한지의 여부로 보인다.
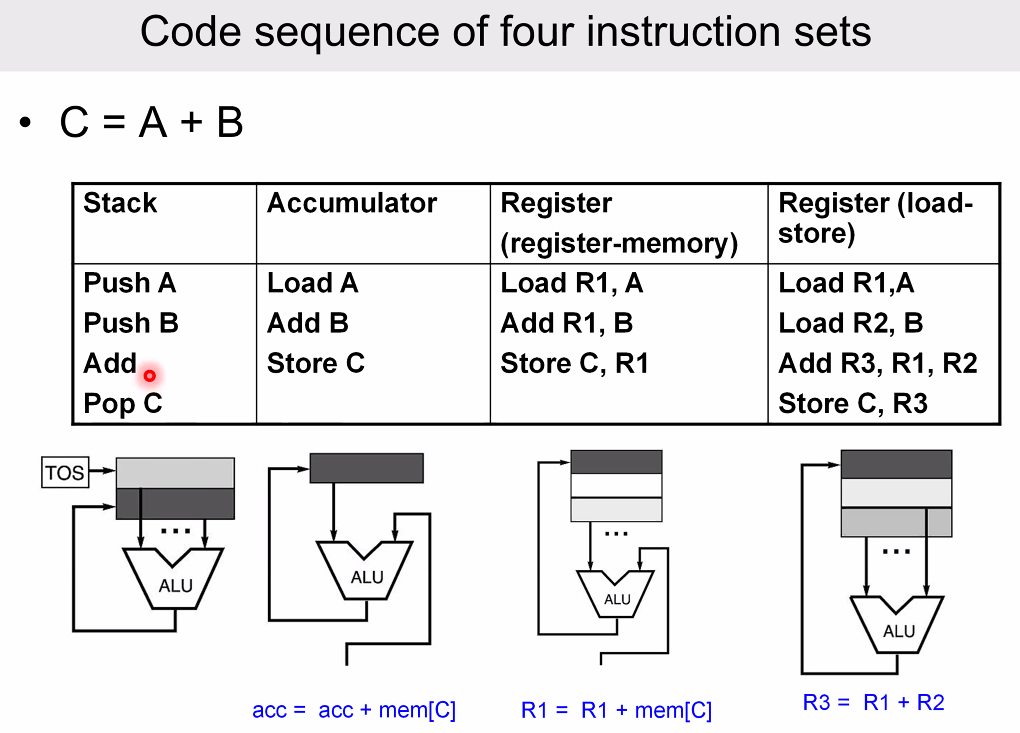
Pipeline과 Superscalar 등의 여러 기법을 적용하는데 유리하다.
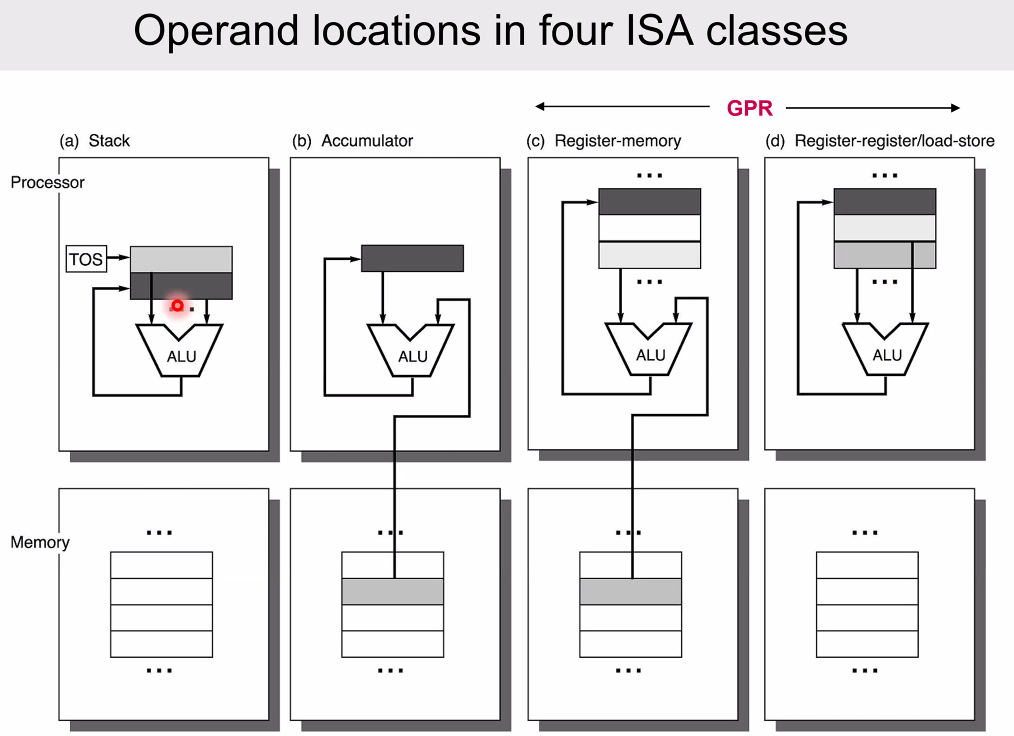
다만, 여전히 특수한 목적의 microcode 수행용 device 같은 경우 1-address, 등등의 기법을 활용하기도 한다고 한다.
질문)
한 가지만 더 질문드리고 싶은데 실수형을 fixed point로 옮기는 과정이 장애요인일 수 있는데 어떻게 극복을 하시는지요?
답)
HW Complexity 를 극단적으로 낮출 수 있지만 Quantization Error 가 있기 때문에 알고리즘의 정확도가 떨어지게 된다.
Fixed System 으로 포팅을 하면 Complexity 이점을 취한 대신 Accuracy 희생을 감안하는 것.
멀티미디어용 알고리즘의 경우, 이미지처리나 음성처리같은 경우는 상대적으로 약간의 오차를 감안가능하기 때문에 좀더 Active 한 Fixed Point Conversion 이 사용되기도 한다.
질문)
microprocessor 같은 경우 functional verification을 수행 할 때 instruction set simulator(ISS)와의 cosim을 통하여 equivalent checking을 하는것으로 알고있는데 NPU나 GPU 또한 이러한 방식으로 검증을 하는지 궁금합니다. 또한 만약 ISS를 사용한다면 microprocessor 와 GPU/NPU의 ISS간에 차이점이 존재하는지 궁금합니다.
답)
맞다.
프로세서 자체적으로는 ISS를 통해 C같은 High Level Evaluation 을 통한 Validation 을 거쳐야 한다.
그러나 상대적으로 NPU나 GPU같은 경우 General Purpose 가 아니라 Data Parallelism 을 위한 특수코드가 들어오기때문에, 그 검증과정이 좀더 Relaxation 되는 경향이 있다.
CrossChecking은 필요하다.
질문)
교수님~ CPU/FPU/GPU/NPU 모두 고유의 ISA가 있고 코딩은 하이레벨 C언어로 하기에 IDEC에서 <compiler설계>를 꼭 배우고 싶습니다.
답)
상위레벨 Compiler은 교수의 전공이 아니다.
Compiler 를 새로 개발하는건 큰 의미가 있을것같지 않고, 추가적인 기법연구는
질문)
HBM 말고 일반 2d DRAM에서 일반적으로 SRAM 보다 density가 좋다고 들었는데 이게 왜 그런가요? DRAM 캡 1개의 사이즈가 SRAM 6T 보다 훨씬 클거 같아 SRAM이 더 density가 좋을 거라고 생각되서 잘 이해가 가지 않습니다. SRAM 설계떄 미스매치나 여러 효과를 고려해서 cell 사이즈를 크게하기떄문인가요?
답)
일반적으로 density가 좋은건 맞다.
SRAM의 경우 Static S Line? 이 있다고 하는데 이건 내가 공부해봐야할듯.
DRAM은 CAP 이 있어서 Leakage를 허용하고 훨씬 더 Density 를 좋게 할 수 있다.
대신 SRAM 은 Static 한 상황을 상정함으로써 훨씬 더 빠르게 구현할 수 있다.
Accessing Speed가 빠른 쪽으로 가면 갈수록 Density 가 안좋아진다. 그 극단은 General Purpose Register 이며 얘는 아예 Flip Flop이다.
그 다음이 SRAM, DRAM, Flash 이다.
강의가 재미있었다.
