1교시 - Fundamentals1
Processing 성능과 Connecting 성능의 관계
각 칩이 빠르다고 해도, 결국 스스로가 빠른만큼 끊임없이 자신이 연산한 결과를 보내야 하고 또 받아들여야 하기 때문에 통신의 발전과 연산의 발전은 서로 함께 이루어질 수밖에 없다.
이에, 다양한 제조/개발사들에 의해 각 기기 또는 IP는 매우 다양한 종류가 난립할 수밖에 없으며 이들을 묶는 protocol의 도입은 필수적이다.
집마다 1개 PC 보급완료
사람마다 1개 SmartPhone 보급완료
사람마다 다수의 IoT장비 보급중 => 새로운 시장(사실 오래된 얘기)
이러한 상황속에서 여러 protocol 이 춘추전국시대를 거쳤었다.
춘추전국시대가 거의 끝나고, 통일된 Connecting Protocol
PAN & BAN(Personal Area & Body Area Network)
BLE(블루투스)
WLAN(Wireless Local Area Network)
802.11 b, g, n Wi-Fi
=> STAR 구조
WMLAN(Wireless Mesh Local Area Network)
IEEE 802.15.4
=> MESH 구조
연산처리에 있어서의 Energy 이슈
Memory 사용으로 인한 Overhead
연산에 1의 에너지가 소요된다고 하면, 레지스터는 1, 버퍼는 10, DRAM에서 읽어오는데는 에너지가 약 500 소요된다.
Deep Learning 의 경우, 연산자체는 간단한데 Data Parameter 가 매우 다양하고 커서, Data Accessing 횟수가 매우 크기 때문에 대량의 Energy가 요구되는 단점이 있다.
즉, 대부분의 에너지는 데이터를 불러오는 과정에서 소모된다는 뜻이다.
그렇다면, 어떻게 Energy-Efficient 한 NN을 만들 수 있을까?
Defining Computer Architecture
Old view of computer architecture
=> ISA Design && register 개수, memory addressing, addressing mode, instruction operand, available operation, control flow instructions, instruction encoding, ...
Real Computer Architecture
=>실제 target machine 의 요구사양에 맞춤설계
Power, cost, availability, ISA, miroarchitecture, hardware 모두 고려
2교시 - Fundamentals2
예전처럼 보드에 전부 구현하기보다는
무슨 system 을 위한 chip 을 만들건지가 중요해졌다.
같은 모바일 제품군이라도 사용자의 용도에 따라 저전력 or 고성능의 trade-off를 고려해야한다.
14nm~7nm: FinFET
7nm~5nm: Gate All Around & Nanowire Contact
5nm~: Tunnel FET
Market Volume Wall
반도체 foundry 에서는 특히, 가장 발전된 기술은 곧 대량으로 만들 수 있는 상품을 의미하고, 이는 가격의 하락을 의미하며 강력한 시장파괴력을 가진다.
Memory: Winner Takes All
특히 메모리 반도체에서는 기술선도자가 성능향상과 동시에 가격도 낮출 수 있고, 기술을 따라잡지 못한 회사는 성능뿐만 아니라 가격경쟁에서 밀려서 파산할 수밖에 없다.
Data Bandwidth for DRAM
DRAM으로부터 읽는 속도는 빠른데, 그걸 버스가 제대로 물어올 수 있어야 한다.
HBM: DDR에 비해 매우 높은 Data Bandwidth
Imbalance of R/W Bandwidth of Flash Memory
Flash 는 읽고 쓰는 bandwidth가 매우 크게 차이가 나는 특징과 단점이 있다.
다만 속도측면에서는 여전히 HDD를 압도하고 저장공간 측면에서는 다른 Nonvolatile Memory(FRAM RRAM 등등) 를 압도하기 때문에 HDD를 부분적으로 대체하여 사용중이다.
SSD는 charge가 있냐 없냐를 얼마나 fine 하게 구분하느냐에 따라 하나의 cell에도 여러 data를 담게 할 수 있는데, 이를 SLC, QLC, TLC 라고 하며 이 경우 storage 의 이점이 있는 대신 wear leveling 등의 안정성 문제가 발생한다.
이를 통신에서 사용하는 ECC같은 알고리즘을 사용하여 복잡한 신호처리를 거쳐 Cell이 깨지는 것을 막거나 감지가능하도록 하여 보완하고 있다.
NAND 플래시가 NOR 플래시를 압도한 이유?
NOR는 flash 특성상 속도는 빠른데 집적화하기에 비효율적이었기 때문. 따라서 HDD를 대체하기에는 NAND가 더 적절했다.
따라서 NOR은 현재 ROM Table 같은 부분적인 용도로 활용된다.
다른 layer 속도차도 있지만, RAM과 SSD 사이의 속도차이는 여전히 너무 크지 않나?
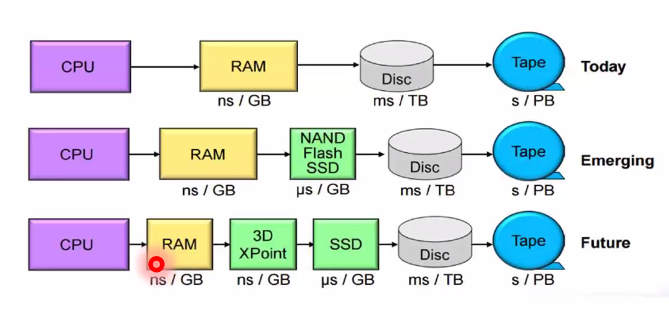
따라서 3D XPoint 라는 메모리를 넣어서 속도차를 완화해보고자하는 시도도 현재 있다.
성능이란 무엇인가?
속도 && Power Consumption
속도차란 엄밀히 무엇인가?
1. Bandwidth == Throughput
=> 처리속도
예전에 가장 중요시됨.
여태 Microprocessor 발전, 메모리 발전, 네트워크 발전은 모두 bandwidth 측면의 노력이었음.
2. Latency == Response Time
=> 반응속도
현재 각광되고있는 issue임.
IC 양산에서의 Issue
같은 Ingot으로부터 Chip 을 만든다고 하더라도, 100% 양품을 기대할 수 없으며, 이를 수율이라고 한다.
yield의 비율은 고장을 기준으로 삼는데, 매우 폐급의 칩을 의미한다.
minimum bound에 아슬아슬하게 걸치면 컴덕들이 소위 "뽑기운" 이라고 하는 것이다.
Package 기술의 각광
예전에는 DIP 방식(소위 "지네"모양 칩) 으로 대충 packaging 을 했지만,
pin 이 매우 많아지고 low power 및 performance 에도 package 가 영향을 미침에 따라
discrete package-> die-stack 및 package-stack -> TSV-stack 등등의 순으로 packaging 기술도 많은 연구가 이루어지고 있다.

예를 들어, 이와같이 Silicon Interposer 를 활용하여 DRAM과 CPU/GPU 간의 Bandwidth를 매우 크게 확보한 packaging 기법 등이 있다.
집적도가 높다고 무조건 좋지 않다.
그 이유는 가격때문. 언제나 팔 수 있는 물건의 기대판매량과 집적도를 올림으로 인해 취할 수 있는 양산율+성능UP 을 저울질해야하는데, 최신 foundry 기술의 경우 25M개, 즉 2500만개정도를 팔아야 한다는 계산이 나온다고 한다.
이러한 판매량은 스마트폰 등을 제외하면 사실상 힘들고,
따라서 최신공정이 있다고 하더라도 스마트폰 등 제한적인 부분에서만 사용되는 것이다.
Battery Wall
모두 알듯, 연산처리능력의 발전보다 배터리 효율의 발전은 매우 더디다.
Power Challenges 라고 하는데, 모바일의 경우 적어도 충전없이 하루는 가야 소비자들에게 납득가능한만큼 중요한 이슈이다.
또한, Thermal Challenge 도 따라오며 이를 제어하지 못하면 쓰로틀링으로 인해 기껏 짜놓은 시스템의 성능최대치를 뽑지 못하는 상황이 벌어질 것이다.
여러 기법이 있는데, HMP, DVFS 등의 기술이 있다.
HMP(Heterogeneous Multi Processing)
현재 휴대폰에 쓰이는 에너지 절약 기술이다.
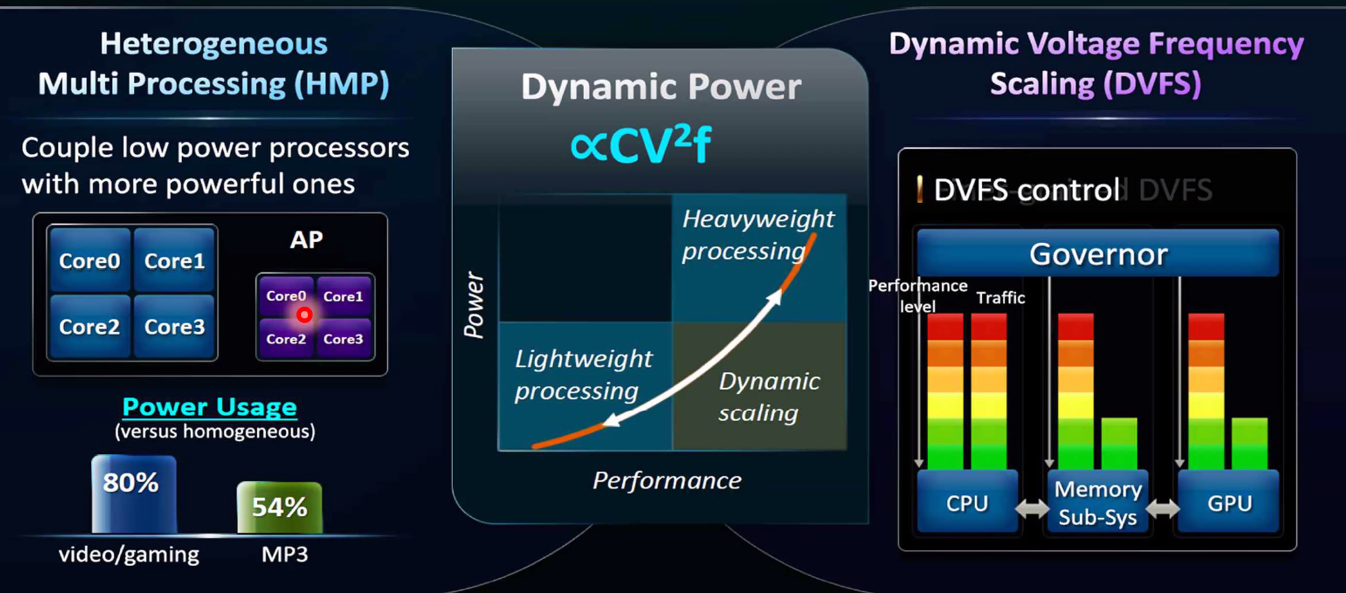
빅 리틀코어기술의 근간이 되는 이론인 것 같은데, 나중에 찾아볼 가치가 있을 것 같다.
NTC(Near Threshold Computing)
간당간당한 전압으로 컴퓨팅을 해서 전기를 아끼는 개념인 것 같다.
Bio쪽 반도체의 경우 수백nm 공정인데 왜 이렇게 큰지?
간단한 센싱 신호처리만 요구되고 무거운 컴퓨팅 오버헤드가 요구되지 않기 때문.
