목적
타이타닉 탑승 고객들의 정보를 활용 --> 승선한 사람들의 생존여부를 예측하는 모델 생성
학습할 부분
- 파이썬 이용, 주피터 노트북을 이용하여 데이터 분석 예정
- 파이썬 가상환경 사용 (가상환경 사용 방법 파악)
- 각 커널 3번씩 반복 작성 --> 파이썬 이용하여 빅데이터 분석 문법 파악
- 각종 시각화 방법 파악
가상환경
- 맥북 환경에서 iTerm에서 가상환경 생성 방법
- Vscode를 사용하여 가상환경 생성 방법
iTerm환경에서 conda 사용하여 가상환경 생성
Mac에서 아나콘다 설치 후 사용 가능
- 가상환경 생성
conda create -n <가상환경명> python=버전(3.5, 3.7 등...)- 가상환경 활성화
conda activate <가상환경명>- 가상환경 비활성화
conda deactivateVscode에서 pyenv 사용하여 가상환경 생성
- pyenv, pyenv-virtualenv 설치
brew install pyenv pyenv-virtualenv- 환경변수 설정
이거는 왜 하는지 모르겠지만... 하라고 하니..
vim ~/.zshrc으로 zsh 쉘파일에 들어가서 아래 내용을 복붙한다.
export PYENV_ROOT="$HOME/.pyenv"
export PATH="$PYENV_ROOT/bin:$PATH"
eval "$(pyenv init --path)"
eval "$(pyenv init -)"위 부분은... 이렇게 하는게 맞는건지 까먹어서.. 추후에 다시 확인
- pyenv 활용법
- 설치 가능한 파이썬 버전 확인 가능
pyenv install --list- 특정 버전 파이썬 설치
pyenv install 3.9.0- 특정 버전 파이썬 삭제
pyenv uninstall 3.9.0- 설치된 파이썬 버전 리스트 확인
pyenv versions- 특정 버전 파이썬을 전역 설정
pyenv global 3.9.0- pyenv-virtualenv 활용법
- pyenv로 파이썬 설치 후 pyenv-virtualenv로 가상환경을 생성
pyenv virtualenv <파이썬 버전> <가상환경명>- 가상환경 활성화
pyenv activate <가상환경명>- 가상환경 비활성화
pyenv deactivate- 가상환경 리스트 확인
pyenv virtualenvsTitanic 데이터 분석
기본 셋팅
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('seaborn')
sns.set(font_scale=2.5)
import missingno as msno
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline-
numpy
파이썬에서 배열 자료구조를 사용하기 위한 패키지 -
pandas
데이터는 대부분 시계열 또는 표(table)형식으로 제공. pandas는 이러한 데이터를 다루기 위해 시리즈(Series), 데이터프레임(Data Frame) 클래스 제공.
pandas를 사용하여 데이터셋의 간단한 통계적 분석부터, 복잡한 처리들을 간단한 메서드를 활용하여 가능 -
matplotlib, seaborn
matplotlib는 Python 프로그래밍 언어 및 수학적 확장 NumPy 라이브러리를 활용한 플로팅 라이브러리
seaborn은 Matplotlib을 쉽게 사용하기 위해 개발된 고수준(high-level) 라이브러리. 간결함이 장점 -
missingno
Null 데이터들을 파악하는데 직관적인 함수를 제공 -
%matplotlib inline
jupyter notebook을 실행한 브라우저에서 바로 그래프를 볼 수 있게 함
Process
1. 데이터셋 확인
Data Set에서 Null Data를 확인 및 가공
2. 탐색적 데이터 분석
다수의 feature들을 개별적 분석, feature간의 상관관계 파악.
여러 시각화 툴을 사용하여 인사이트 도출
3. Feature Engineering
모델 생성 전에 모델 성능 향상 위해 여러 feature들을 engineering함.
ex) one-hot encoding, class로 나누기, 구간으로 나누기, 텍스트 데이터 처리 등
4. model 생성
sklearn 사용하여 모델 생성. 파이썬에서 머신러닝을 할 때는 sklearn을 사용하여 많은 알고리즘을 일관된 문법으로 사용 가능. 딥러닝은 tensorflow, pytorch 등 사용.
5. 모델 학습 및 예측
Train Data를 사용하여 모델 학습 후, Train Data를 가지고 예측
6. 모델 평가
모델의 예측 성능이 원하는 수준인지 파악. 문제에 따라 모델 평가 방식도 달라짐.
1. 데이터셋 확인
Train Data와 Test Data 확인
df_train = pd.read_csv("../titanic/train.csv")
df_test = pd.read_csv("../titanic/test.csv")
현재 데이터 분석 파이썬 파일 위치는 위 경로에서 Lv_1 폴더에 존재. 데이터 파일 경로는 titanic 폴더에 존재.
따라서 파이썬 파일 기준으로 전 경로로 가서 titanic폴더에 가야 함.
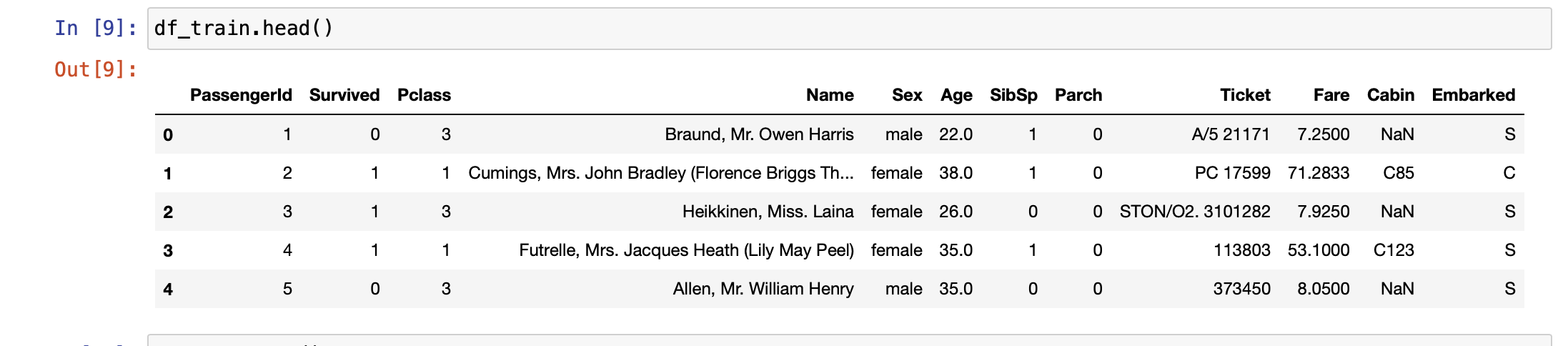
Train Data의 개요 확인. Feature는 PassengerId, Survived, PClass, Name, Sex, Age, SibSp, Parch, Fare, Cabin, Embarked이다.
위 Feature에서 다루려는 Feature는 Pclass, Age, SibSp, Parch, Fare이다. 예측하고자 하는 Target Label은 Survived이다.
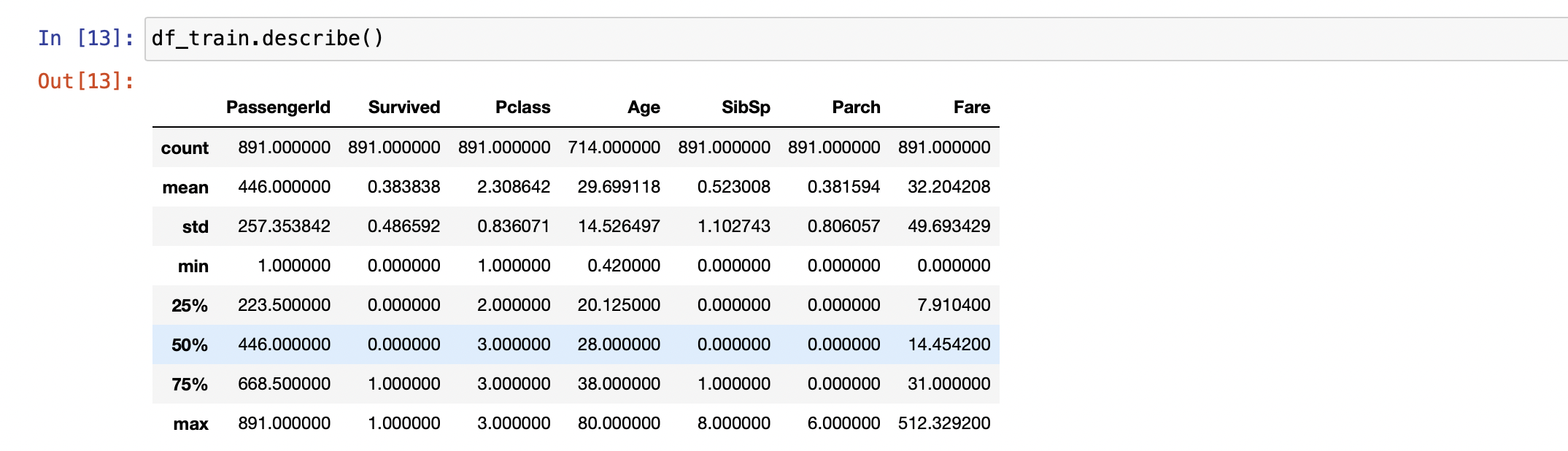
DataFrame에서 describe() --> 각 feature가 가진 통계치들을 반환
- PassengerId는 891개의 데이터를 가짐. 하지만 Age를 보면 714개의 데이터를 가지는것으로 보아 Null Data가 존재함을 알 수 있다.
- Survived를 보면 min, max값은 각각 0,1이다. 이로 생존여부를 0과 1로 표혀함을 알 수 있음.
- Pclass를 보았을 꺠 50% ~ max값이 전부 3이다. 이로 Pclass가 3인 승객이 반 이상을 차지함을 알 수 있음.
솔직히 위 표로 각 feature을 직접적으로 알기에는 힘듦...
그래프를 이용하거나 다른 툴을 사용하여 분석해보자
1.1 Null Data Check
for col in df_train.columns:
msg = 'column : {:>11}\t Percent of NaN value : {:.2f}%'.format(col, 100*(df_train[col].isnull().sum() / df_train[col].shape[0]))
print(msg)위 결과물을 보면 다음과 같다.
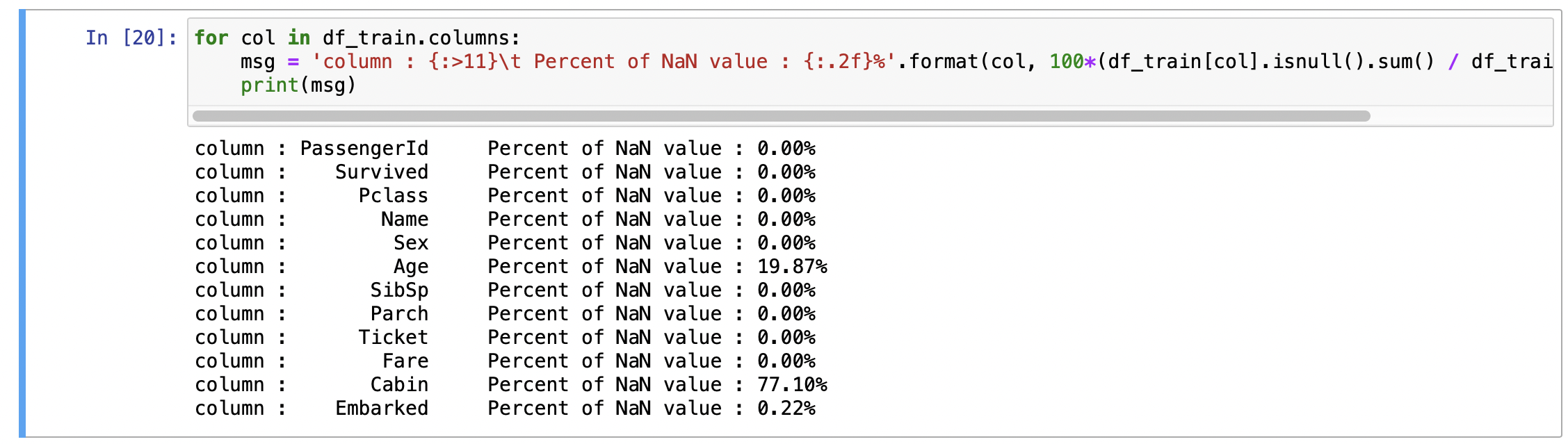
각 feature의 Null Data를 가지고 있는 퍼센트지를 알 수 있다. 위에 사용한 메서드를 각각 살펴보면,
isnull()

Data Frame의 각 col에 대해서 isnull을 사용하면 각 feature의 목록에 대해서 Null Data인지 bool값으로 파악해준다.
그럼 여기다 sum()을 사용하면?
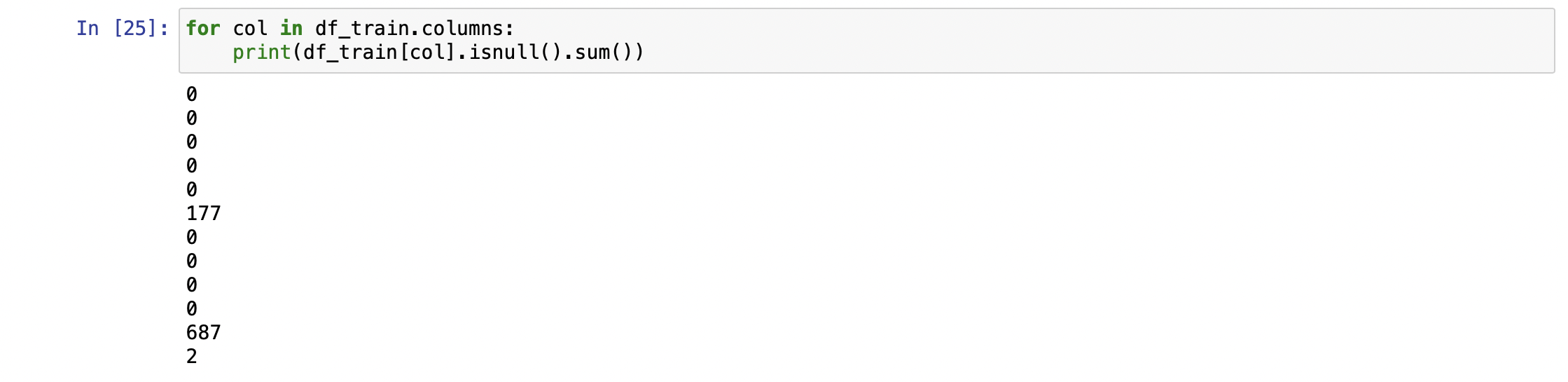
feature 순서대로 Null Data의 총 개수를 파악해준다. isnull()은 Null Data를 1로 표시해주기 때문.
shape[0]??
shape 메서드는 Data Frame의 각 col에 대해서 말 그대로 모양?을 말해준다. shape를 사용할 시 튜플형태로 반환해준다. shape[0]을 사용하면 튜플의 앞부분 891을 반환

참고로 shape는 tuple자료형을 가짐
똑같이 test Data에도 적용
for col in df_test.columns:
msg = 'column : {:>11}\t Percent of NaN value : {:.2f}%'.format(col, 100 * (df_test[col].isnull().sum()/df_test.shape[0]))
print(msg)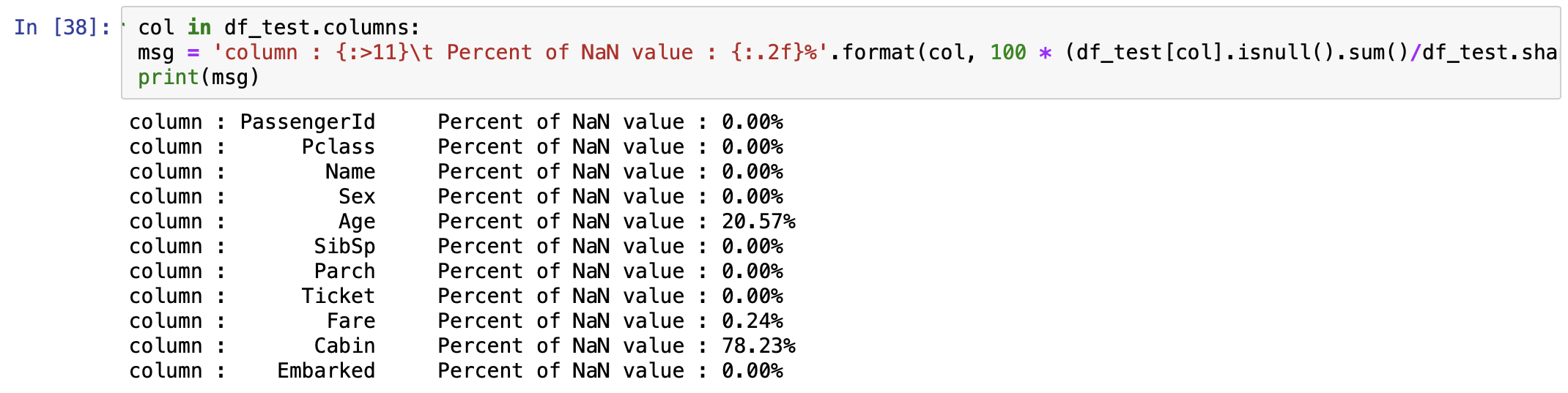
MANO
missingno 라이브러리를 사용할 시 Null Data를 더 쉽게 볼 수 있다.
msno.matrix(df=df_test.iloc[:,:], figsize=(8,9), color=(0.2, 0.4, 0.5))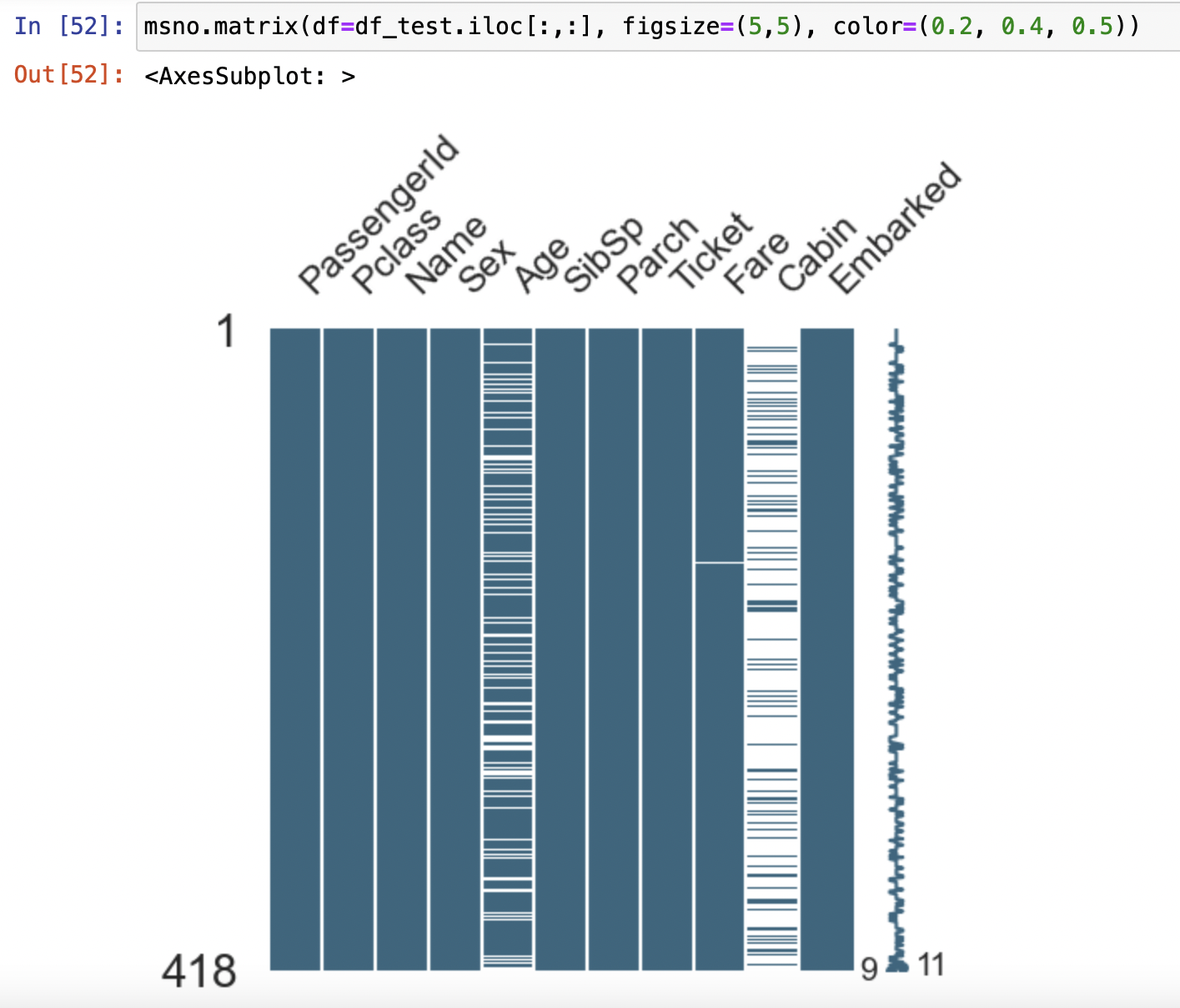
msno.bar(df=df_test.iloc[:,:], figsize=(5,5), color=(0.5,0.1,0.7))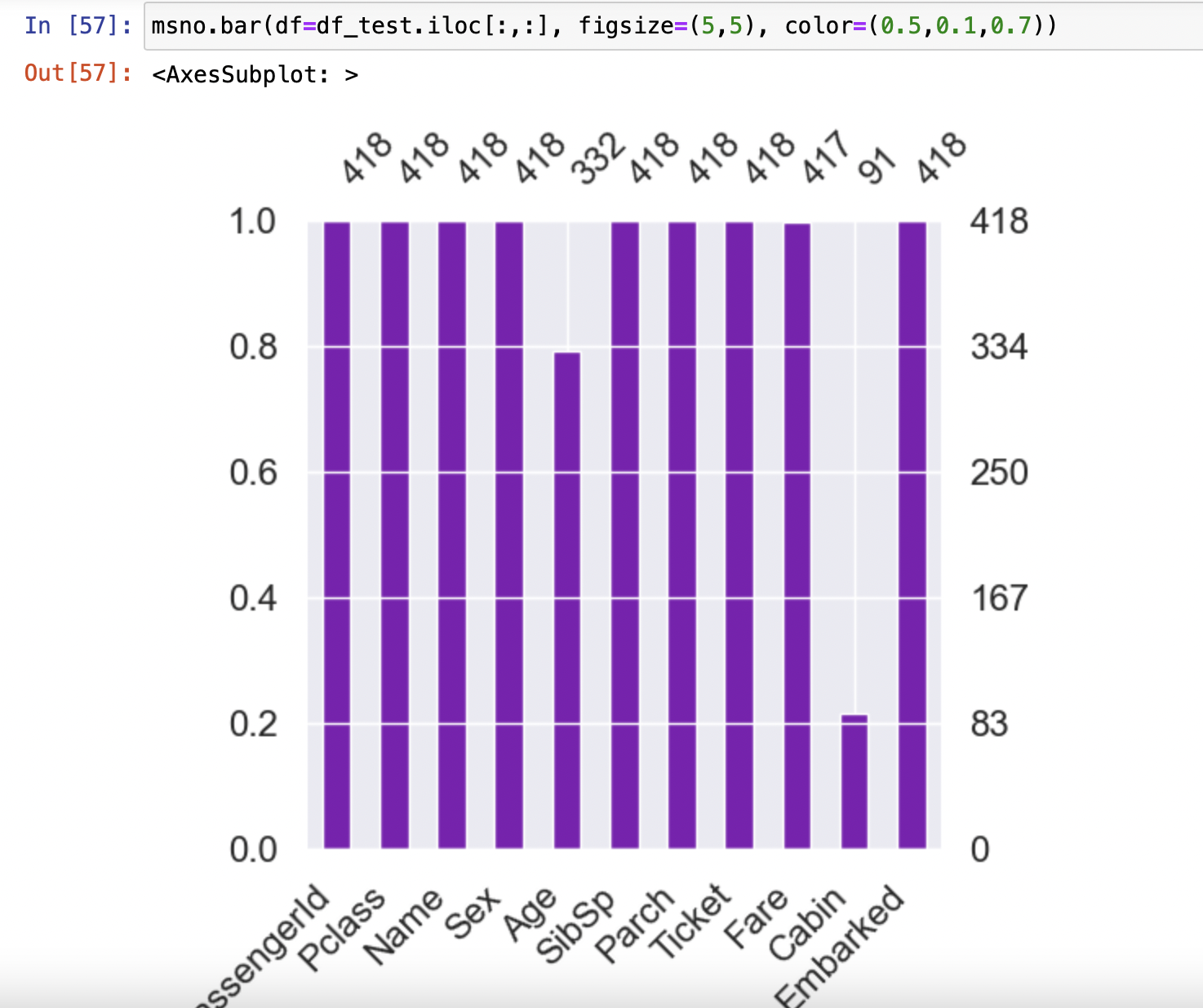
msno.bar(df=df_train.iloc[:, :], figsize=(5,5), color=(0.4, 0.6, 0.2))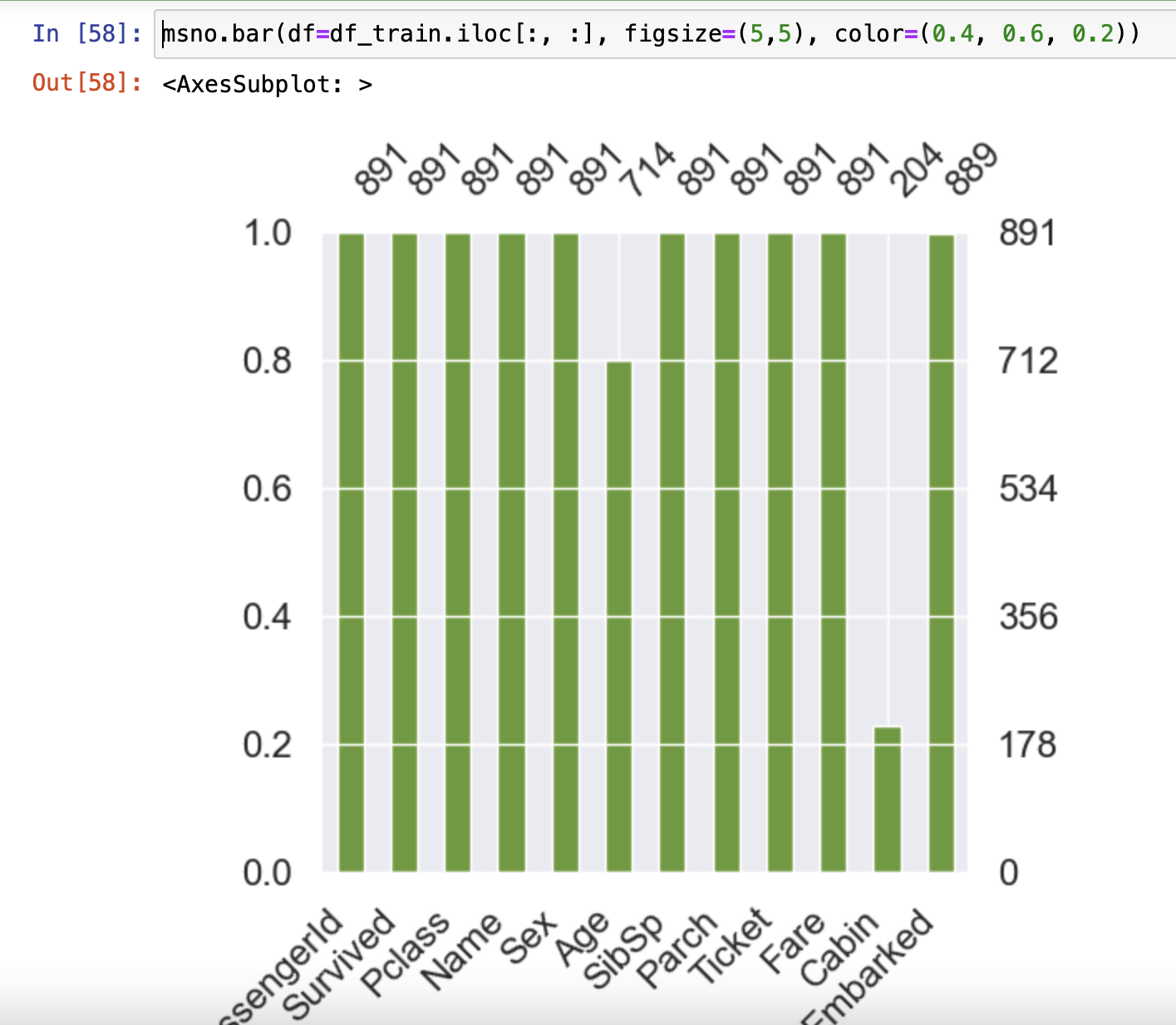
loc vs iloc
loc
Data Frame 행 or 칼럼의 label 또는 boolean array로 인덱싱. 이는 사람이 읽을 수 있는 라벨 값으로 특정 값을 인덱싱한다.
df.loc[행, 칼럼]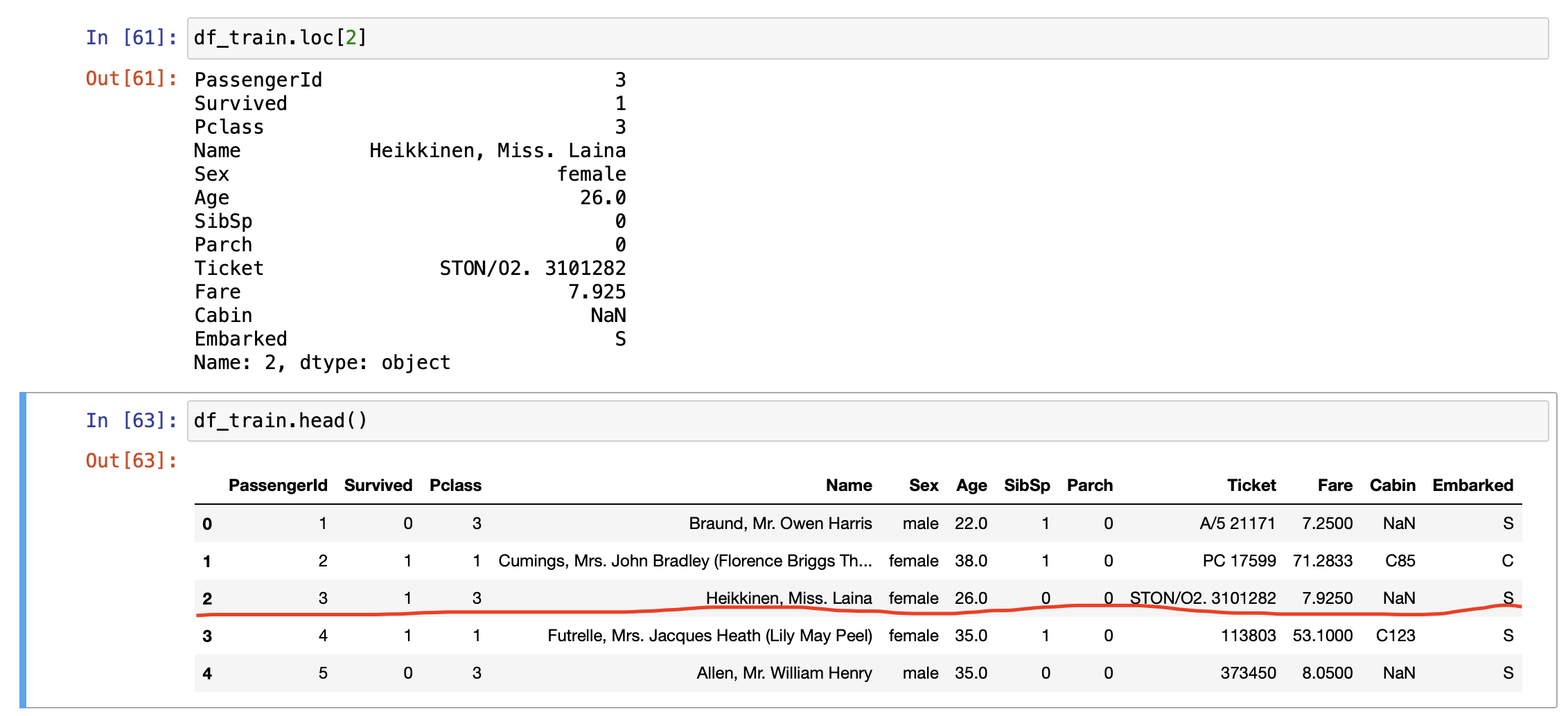
loc메서드에 값 하나만 입력 시 그 값에 해당하는 하나의 행만 인덱싱한다.

위와 같이 특정 행의 특정 칼럼을 뽑고싶다면, 특정 칼럼의 이름을 적어주면 된다.
1.2 Target Label
Target Label이 어떤 분포를 가지는지 확인.
타이타닉 문제같은 경우는 생존을 0,1로 표현하는 Binary Classification 문제이다. 이는 1, 0의 분포가 어떠냐에 따라 모델 평가 방법이 달라질 수 있다.
이번 타이타닉 문제에서 생존자들의 분포를 확인해보자
f, ax = plt.subplots(1, 2, figsize=(18, 8))
df_train['Survived'].value_counts().plot.pie(explode=[0, 0.1], autopct='%1.1f%%', ax=ax[0], shadow=True)
ax[0].set_title('Pie - Survived')
ax[0].set_ylabel('')
sns.countplot(data=df_train, x='Survived', ax=ax[1])
ax[1].set_title('Countplot - Survived')
plt.show()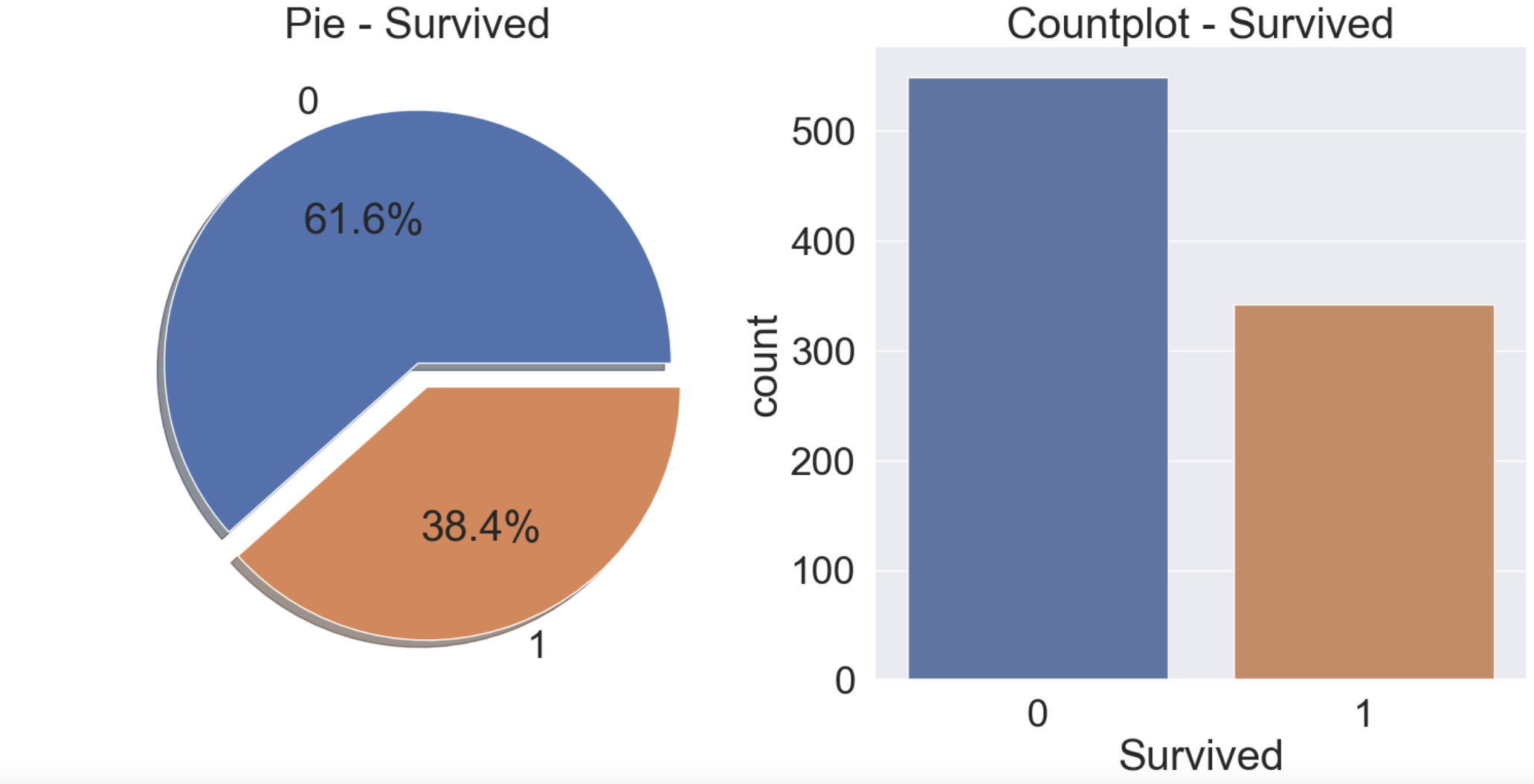
생존자는 전체 승객중에 38.4%이다. 위 분포는 극단적으로 생존 or 사망에 몰리지 않고 균일하다고 볼 수 있다. 만약 99.9%가 사망이고 0.1%가 생존이라고 한다면 그 데이터로 학습해도 모델이 정확한 결과값을 줄 수 없을 것이다.
(생존에 대한 학습이 부족하므로)
2. 탐색적 데이터 분석
많은 데이터 안에 숨겨진 정보를 찾기 위해서는 시각화가 필수이다.
시각화에는 matplotlib, seaborm, plotly 등이 존재
이제 해당 Column에 대해서 데이터 분석을 진행해보자
2.1 Pclass
Pclass는 ordinal, 서수형 데이터이다. 이는 카테고리이면서 순서가 있는 데이터임을 의미.
Pclass별로 생존률 추이를 확인해보자.
# 각 Pclass별 승객 수
df_train[['Survived', 'Pclass']].groupby(['Pclass'], as_index=True).count()# 각 Pclass별 생존자 수
df_train[['Survived', 'Pclass']].groupby(['Pclass'], as_index=True).sum()
위 과정을 한번에 하기 위해 pandas의 crosstab 메서드를 사용할 수 있다.
pd.crosstab(df_train['Pclass'], df_train['Survived'], margins=True).style.background_gradient(cmap='summer_r')
Pclass 1의 경우 생존율은 전체 개수 216명중 생존자명 136이므로 136/216 = 0.63정도 된다. (생존 여부를 0, 1로 구별하였으므로 전체 데이터를 더하면 생존자 명수 126이 되고 전체 명수는 216이므로)
# 각 Pclass별 생존률
df_train[['Pclass', 'Survived']].groupby('Pclass', as_index=True).mean().sort_values('Survived', ascending=False).plot.bar()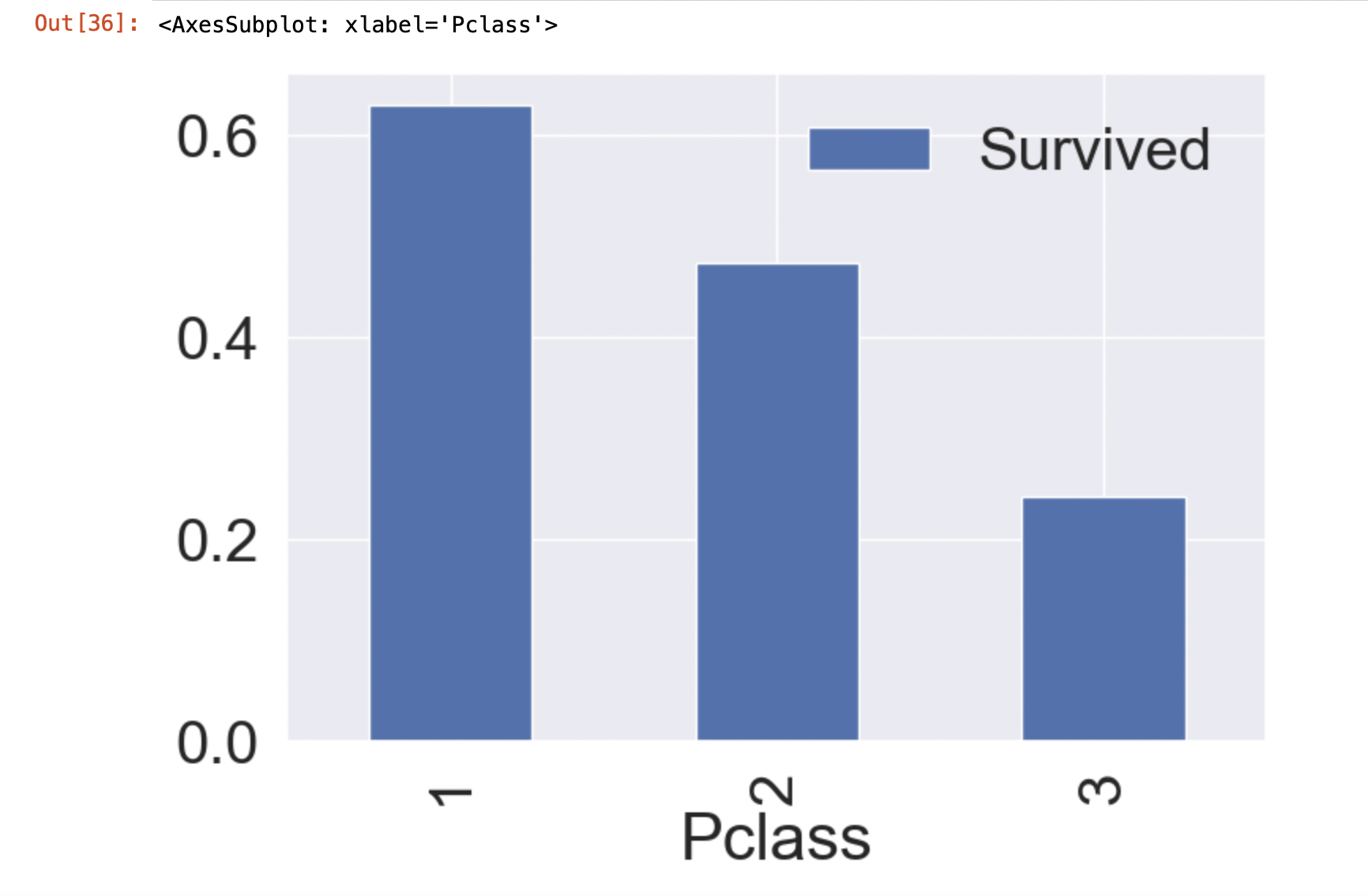
위 그래프를 보았을 때 Pclass 등급이 좋을수록 (1로 갈수록) 생존율이 높아진다.
#countplot을 이용하여 확인
y_position = 1.02
f, ax = plt.subplots(1, 2, figsize=(18, 8))
df_train['Pclass'].value_counts().plot.bar(color = ['#CD7F42','#FFDF00','#D3D3D3'], ax=ax[0])
ax[0].set_title('Number of Passengers by Pclass', y=y_position)
ax[0].set_ylabel('Count')
sns.countplot(data=df_train, x='Pclass', hue='Survived', ax=ax[1])
ax[1].set_title('Pclass : Survived vs Dead', y=y_position)
plt.show()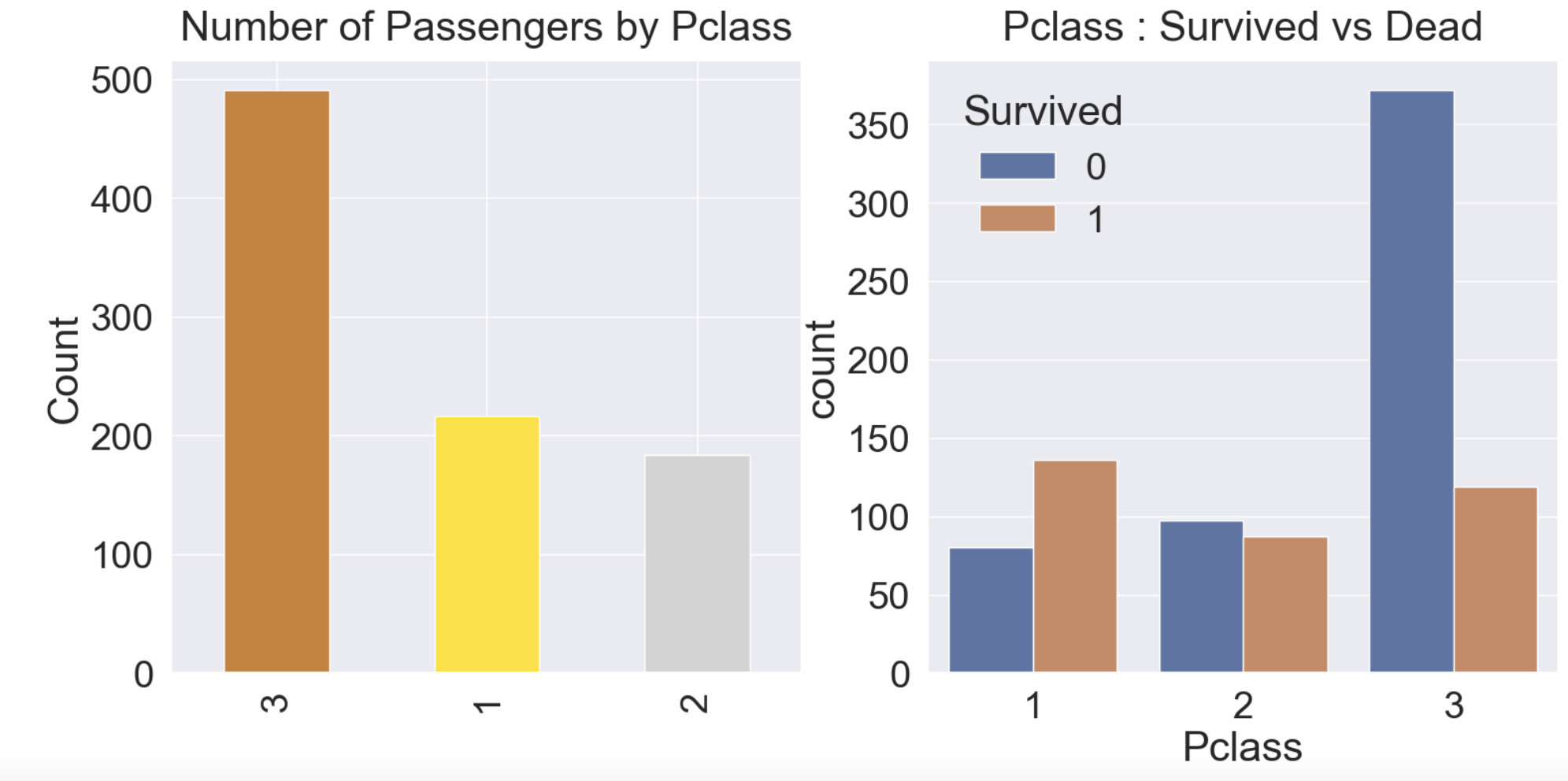
2.2 Sex
성별에따라 생존률의 차이를 알아보자
y_pos = 1.02
f, ax = plt.subplots(1, 3 ,figsize=(24,8))
df_train['Sex'].value_counts().plot.bar(ax=ax[0])
ax[0].set_title('Number of Passengers by Sex', y=y_pos)
df_train[['Sex', 'Survived']].groupby(['Sex'], as_index=True).mean().plot.bar(ax=ax[1])
ax[1].set_title('Mean of Survived of Sex', y=y_pos)
sns.countplot(data=df_train, x='Sex', hue='Survived', ax=ax[2])
ax[2].set_title('Sex : Survived vs Dead')
plt.show()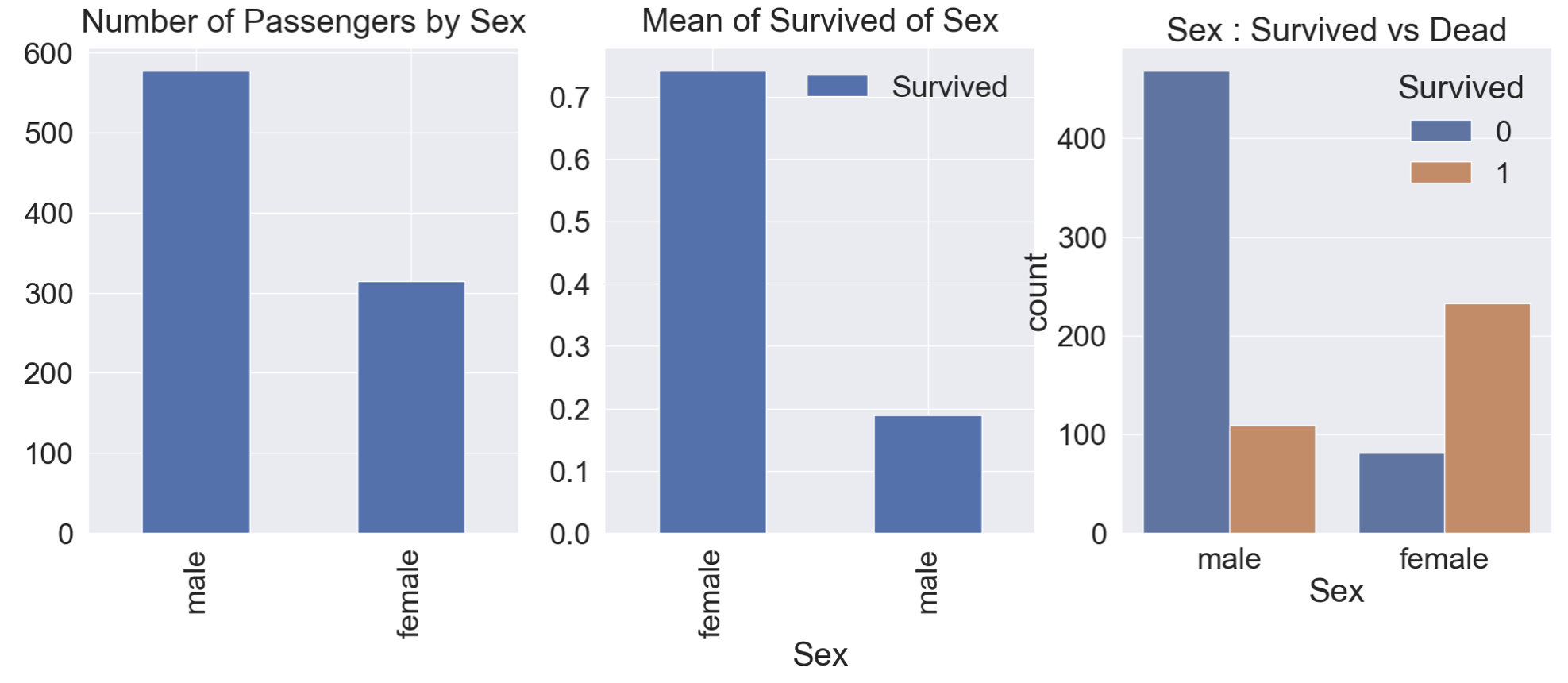
승객의 대부분은 남성이지만 생존율을 보면 여성이 70%넘는것을 알 수 있다. 이로 보아 여성의 생존을 우선시했다는 것을 알 수 있음.
df_train[['Sex', 'Survived']].groupby(['Sex']).mean().sort_values('Survived', ascending=True)
pd.crosstab(df_train['Sex'], df_train['Survived'], margins=True).style.background_gradient(cmap='summer_r')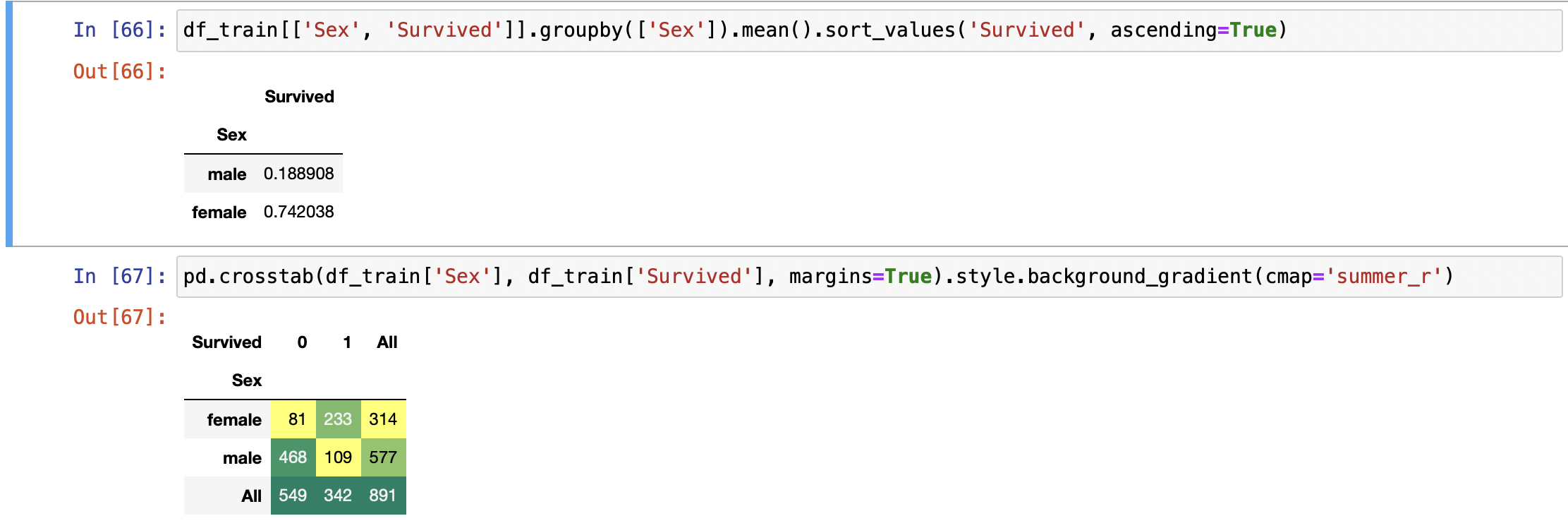
성별에 따라 생존율의 차이가 나므로 이 feature 또한 학습 모델에 쓰일 중요한 요소임을 알 수 있다.
2.3 Both Sex and Pclass
이제는 Sex, Pclass를 가지고 생존율이 어떻게 변하는지 확인해보자
원래는 seaborn의 factorplot을 사용하는데 seaborn 버전 0.12.0에선 해당 plot 메서드가 사라져서 대신 lineplot을 사용해보자
sns.lineplot(data=df_train, x='Pclass', y='Survived', hue='Sex')
plt.show()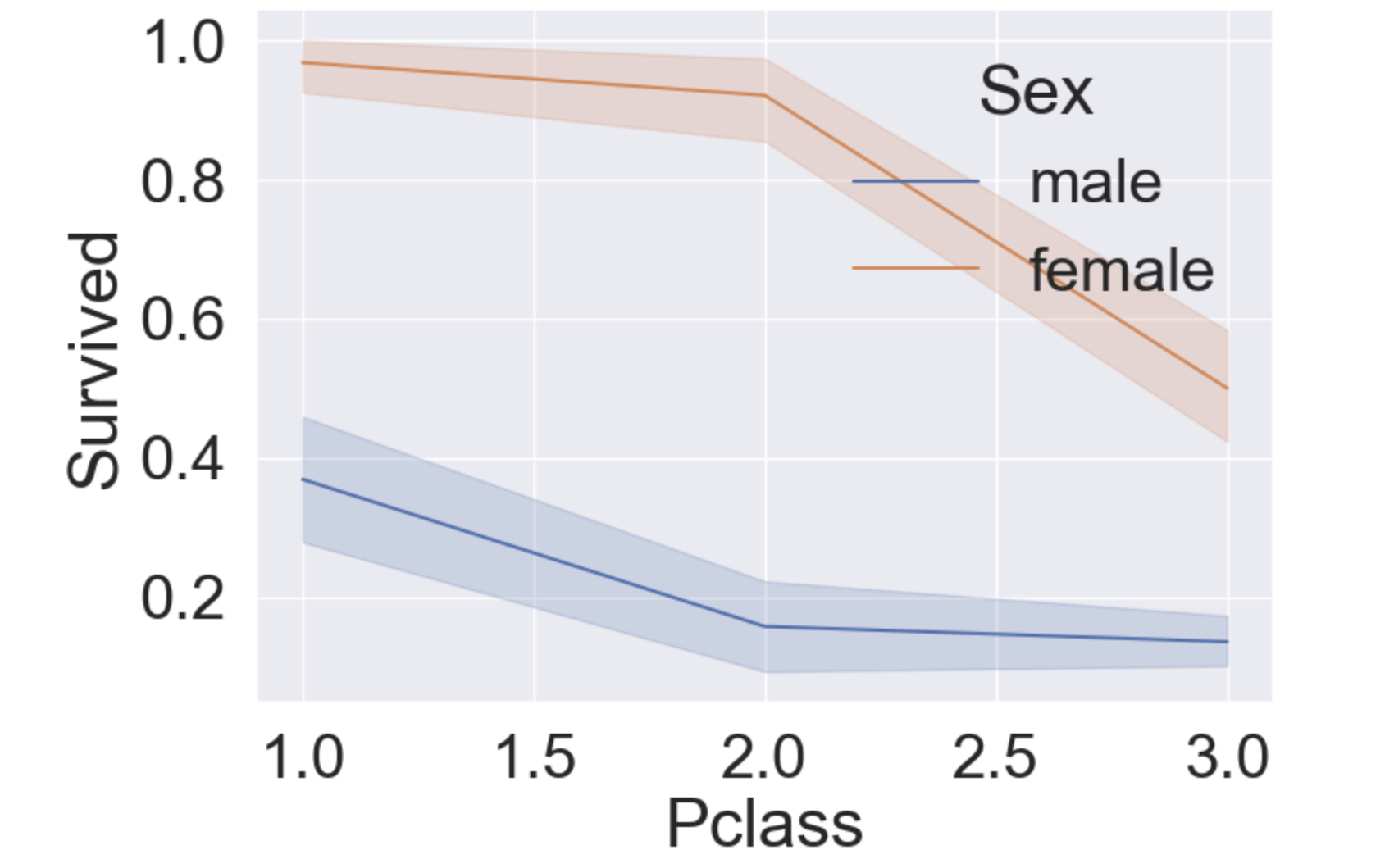
가운데 실선은 각 Pclass별 평균을 의미하고 옅은 구간은 신뢰구간을 의미.
각 x값에 대해서 다수의 y값을 가지고 있기 때문에, sns.lineplot()은 이 데이터들에 대해서 중심 경향(아마 평균?)을 긋고, 그 경향에 대한 신뢰 구간도 체크해준다. (출처 : https://stackabuse.com/seaborn-line-plot-tutorial-and-examples/)
위 그래프를 보면 Pclass가 높을 수록 생존율이 높고, 여성이 남성보다 생존율이 높다.
이제는 Pclass별 따로 그래프를 그려보자. 원래는 factorplot에서 cold을 사용하면 되지만(seaborn version =0.9.0에서는 사용 가능) 현 버전에서는 불가능하므로 sns.FacetGrid를 사용하자.
facet = sns.FacetGrid(df_train, col='Pclass', height= 10)
facet = facet.map(sns.lineplot, 'Sex', 'Survived')
2.4 Age
나이의 최대, 최솟값, 평균값을 알아보자.
print('제일 나이가 많은 탑승객 : {:.1f} Years'.format(df_train['Age'].max()))
print('제일 어린 탑승객 : {:.1f} Years'.format(df_train['Age'].min()))
print('탑승객 평균 나이 : {:.1f} Years'.format(df_train['Age'].mean()))
그럼 나이별 생존율을 살펴보자
f, ax = plt.subplots(1, 1, figsize=(9, 5))
sns.kdeplot(df_train[df_train['Survived'] == 1]['Age'], ax=ax)
sns.kdeplot(df_train[df_train['Survived'] ==0]['Age'], ax=ax)
plt.legend(['Survived == 1', 'Survived == 0'])
plt.show()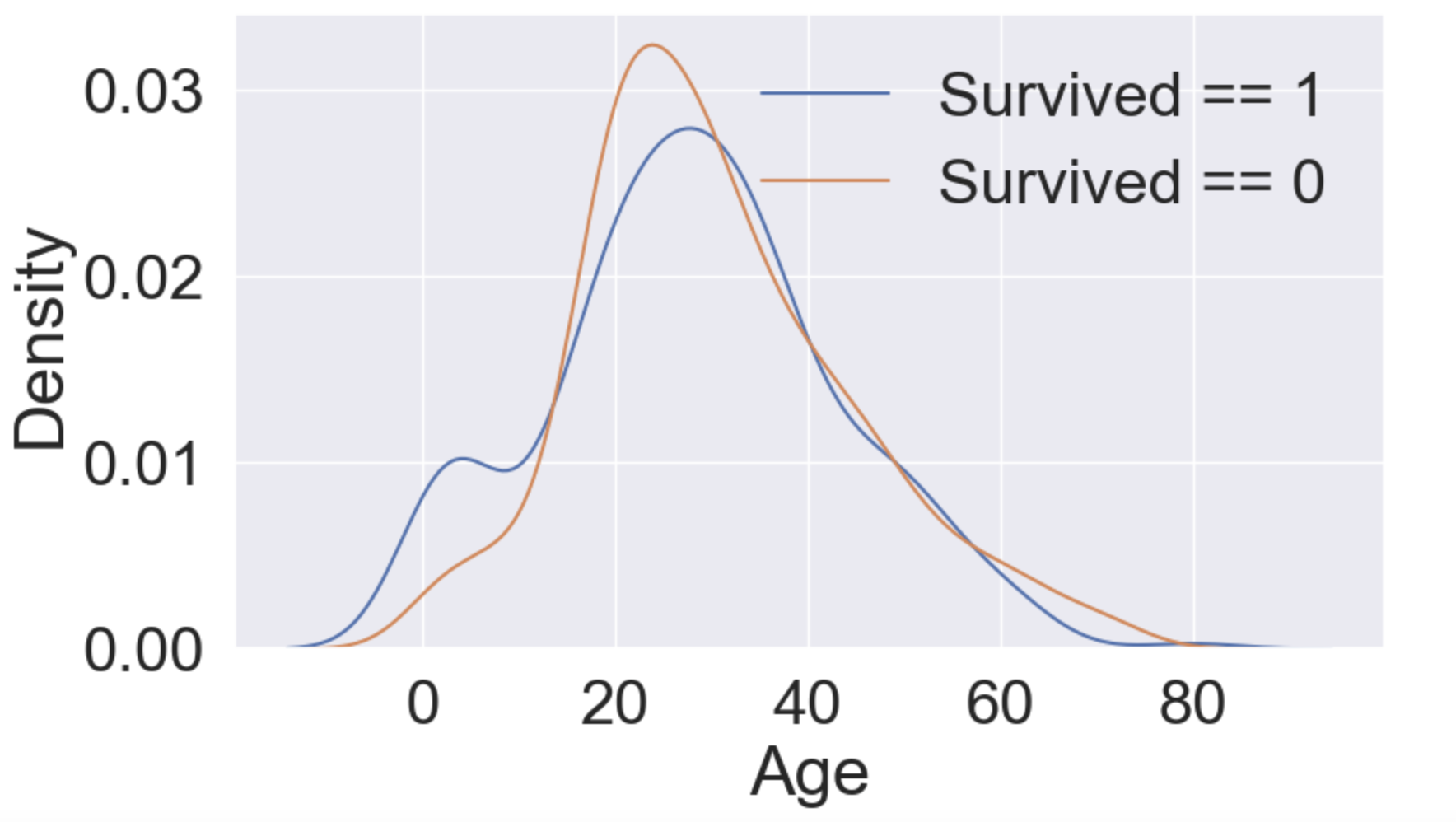
위 히스토그램으로 데이터의 분포를 알 수 있다. 막대그로프로는 각 계급당 해당 데이터 수를 알 수 있지만 히스토그램만큼 데이터 분포를 알 수는 없다. 이처럼 연속적인 계급을 이용해서 전체 데이터의 분포가 어떻게 흐르는지 알 수 있다.
히스토그램은 계급의 구간을 어떻게 나누는냐에 따라 데이터 분석에 대한 해석이 달라질 수 있다. 적당한 계급 수로 나누는게 중요한데 이를 보완하기 위해 파이썬에서 kdeplot을 사용할 수 있다.
kdeplot(커널 밀도 추정) 은 히스토그램을 곡선화시킨 그래프이다.
kde에 대한 자세한 설명은 https://darkpgmr.tistory.com/147
나이가 어릴수록 생존할 확률이 높아진다. 10대 중후반부터 사망 확률이 생존 확률보다 높아진다. y축은 밀도로 확률을 뜻한다.
밀도(density)는 수학적으로는 mass/volume으로 정의되지만, 밀도추정(density estimation), 기계학습, 확률, 통계 등에서 말하는 밀도(density)는 확률밀도(probability density)를 의미한다 (확률밀도에서 확률을 생략하고 흔히 밀도라고 표현).
출처 : https://darkpgmr.tistory.com/147
이제 Pclass, 성별에 따른 나이를 살펴보자
plt.figure(figsize=(8, 6))
df_train['Age'][df_train['Pclass']==1].plot(kind='kde')
df_train['Age'][df_train['Pclass']==2].plot(kind='kde')
df_train['Age'][df_train['Pclass']==3].plot(kind='kde')
plt.xlabel('Age')
plt.legend(['1st Class', '2nd Class', '3rd Class'])
plt.show()
plt.figure(figsize=(9, 6))
df_train['Age'][df_train['Sex']=='male'].plot(kind='kde')
df_train['Age'][df_train['Sex']=='female'].plot(kind='kde')
plt.xlabel('Age')
plt.legend(['male', 'female'])
plt.show()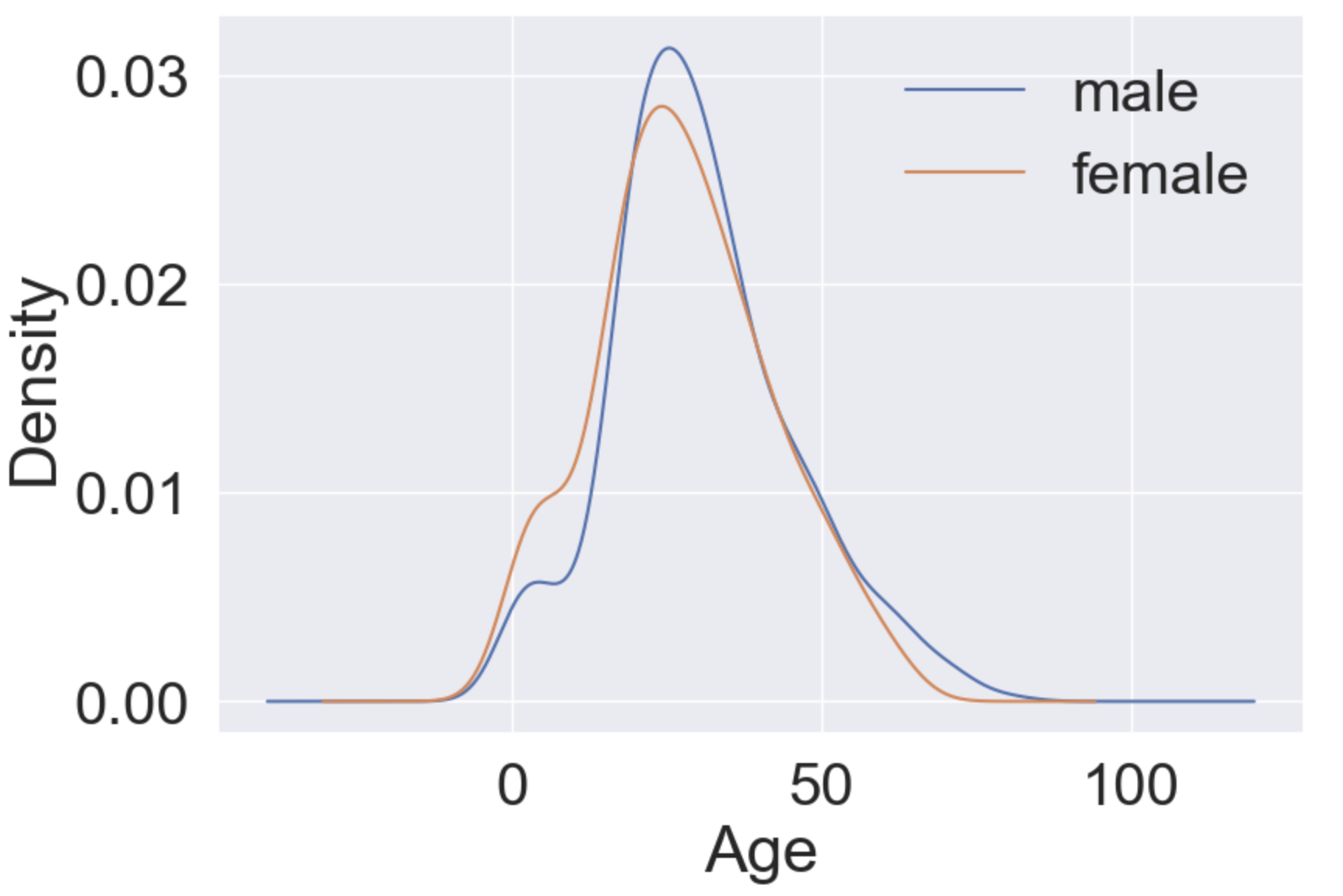
위에서 나이에 따른 생존률을 봤을 때 나이가 어릴수록 생존 확률이 높았다. 이를 Pclass와 성에 따라 나누어봤을 때 확인 가능한것은
1. Pclass가 높을수록 생존율이 높았는데 나이가 어릴수록 Pclass는 낮다. 그리고 나이가 어릴수록 생존율은 높다.
2. 여성일수록 생존율이 높았다. 그런데 나이가 어릴수록 여성일 확률이 높다.
3. 성별과 나이와 연관이 있을 수도 있다?그럼 이번에 나이대를 확장함에 따라 생존율이 어떻게 변화하는지 확인해보자
cummulate_survival_ratio = []
for i in range(0, 80):
cummulate_survival_ratio.append(df_train[df_train['Age'] < i]['Survived'].sum() / len(df_train[df_train['Age'] < i]['Survived']))
plt.plot(cummulate_survival_ratio)
plt.title('Survival Ratio change depending on range of Age', y=1.02)
plt.xlabel('Range of Age(0~x)')
plt.ylabel('Survival Rate')
plt.show()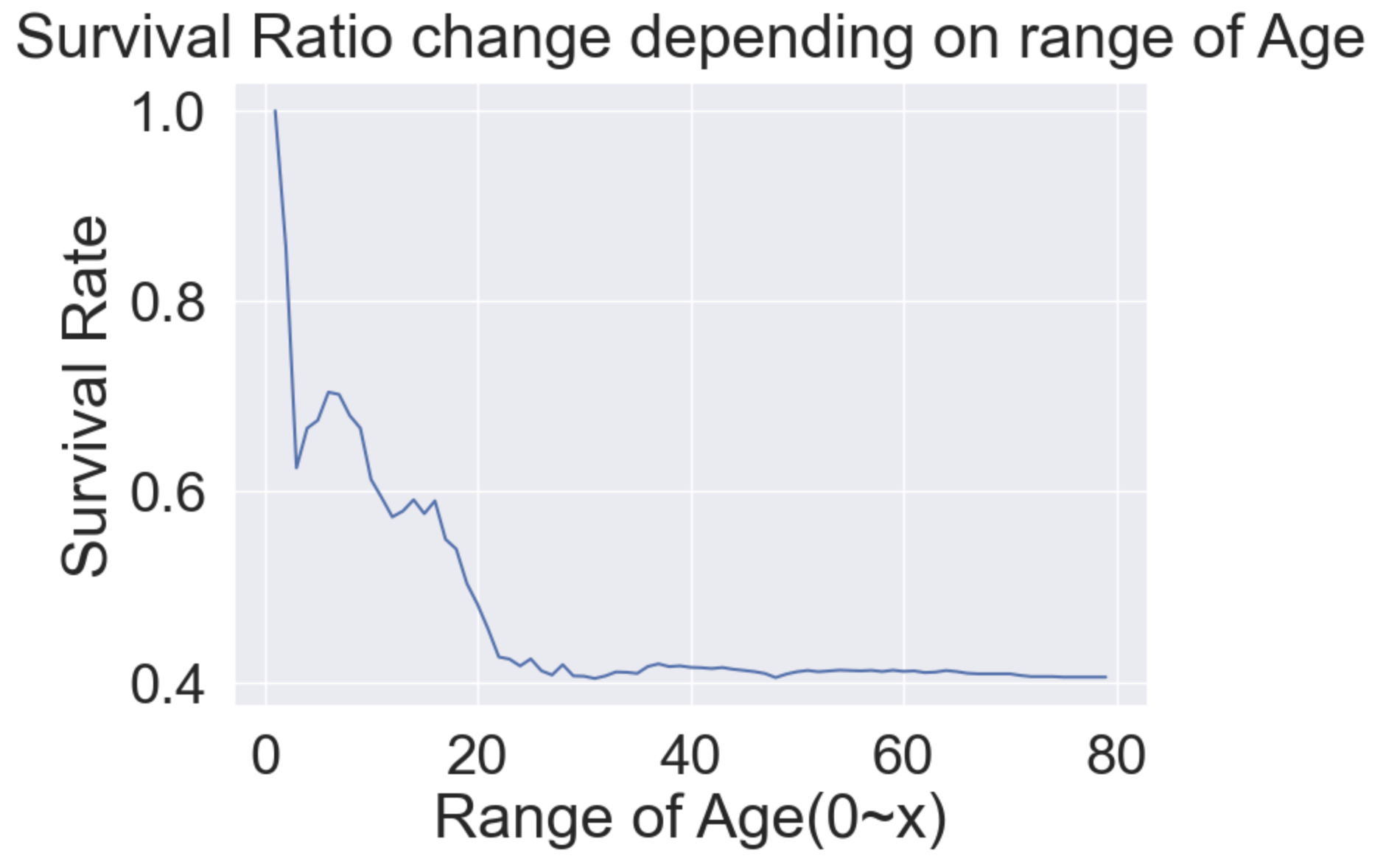
나이가 많아질수록 생존율이 감소함을 알 수 있다.
2.5 Pclass, Sex, Age
이번엔 여태 살펴보았던 Pclass, Sex, Age, Survived를 한번에 살펴보려고 한다.
이 모든 Feature를 담기 위해 Violin Plot를 사용하려고 한다.
f, ax = plt.subplots(1, 2, figsize=(18, 8))
sns.violinplot(data=df_train, x='Pclass', y='Age', hue='Survived', scale='count', split=True, ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot(data=df_train, x='Sex', y='Age', hue='Survived', scale='count', split=True, ax=ax[1])
ax[1].set_title('Sex and Age vs Sutvived')
ax[1].set_yticks(range(0,110,10))
plt.show()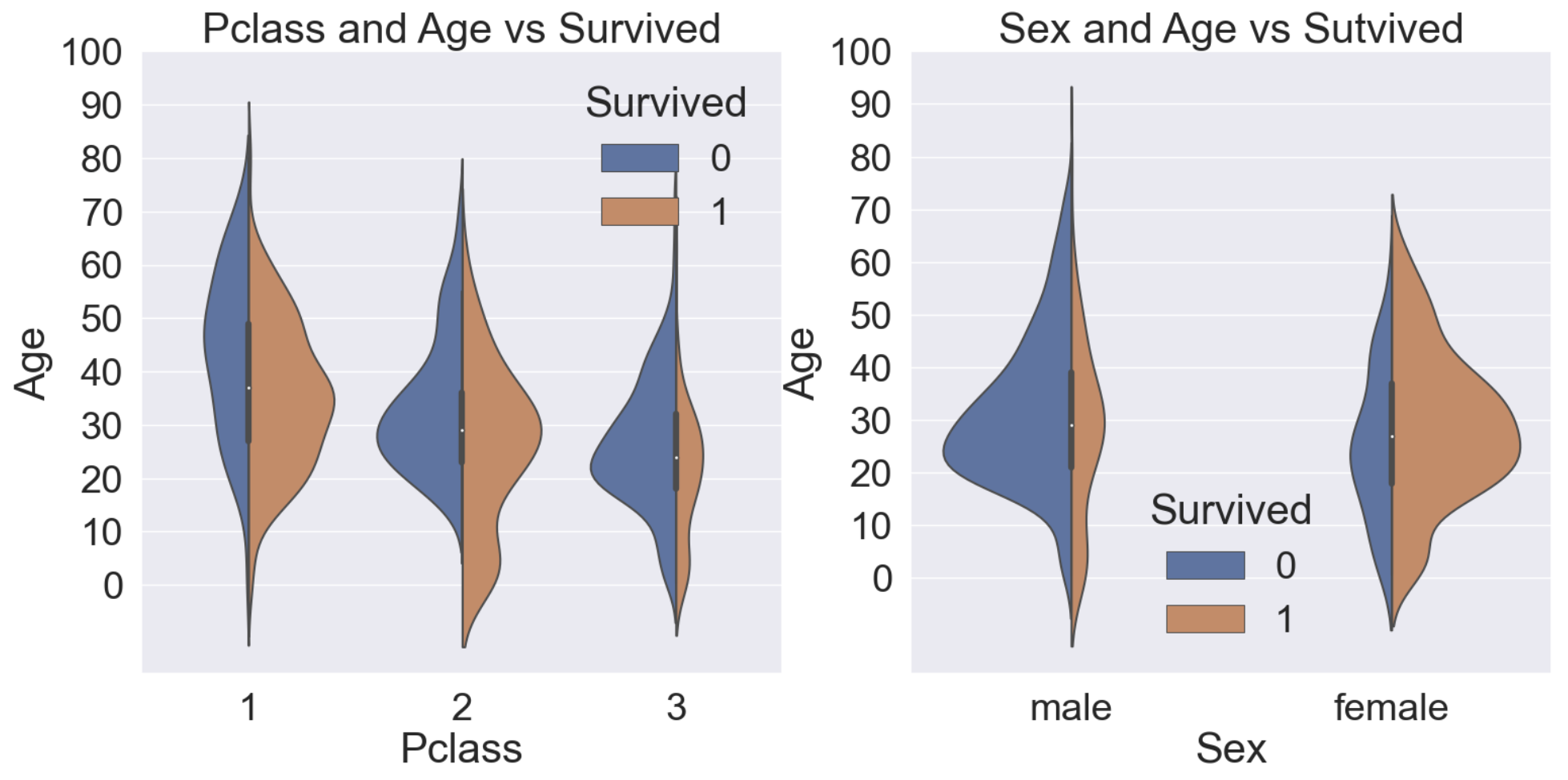
위 그래프를 보았을 때 Pclass가 낮을수록 생존자수는 적고, 여성일수록 생존자 수는 월등히 많다. 또한 나이가 적을수록 생존확률은 높다. (Pclass=2, Sex=female에서 확인가능한 부분)
2.6 Embarked
이번엔 항구에 따른 생존률을 살펴보려고 한다.
f, ax = plt.subplots(1, 1, figsize=(7, 7))
df_train[['Embarked', 'Survived']].groupby(['Embarked'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar(ax=ax)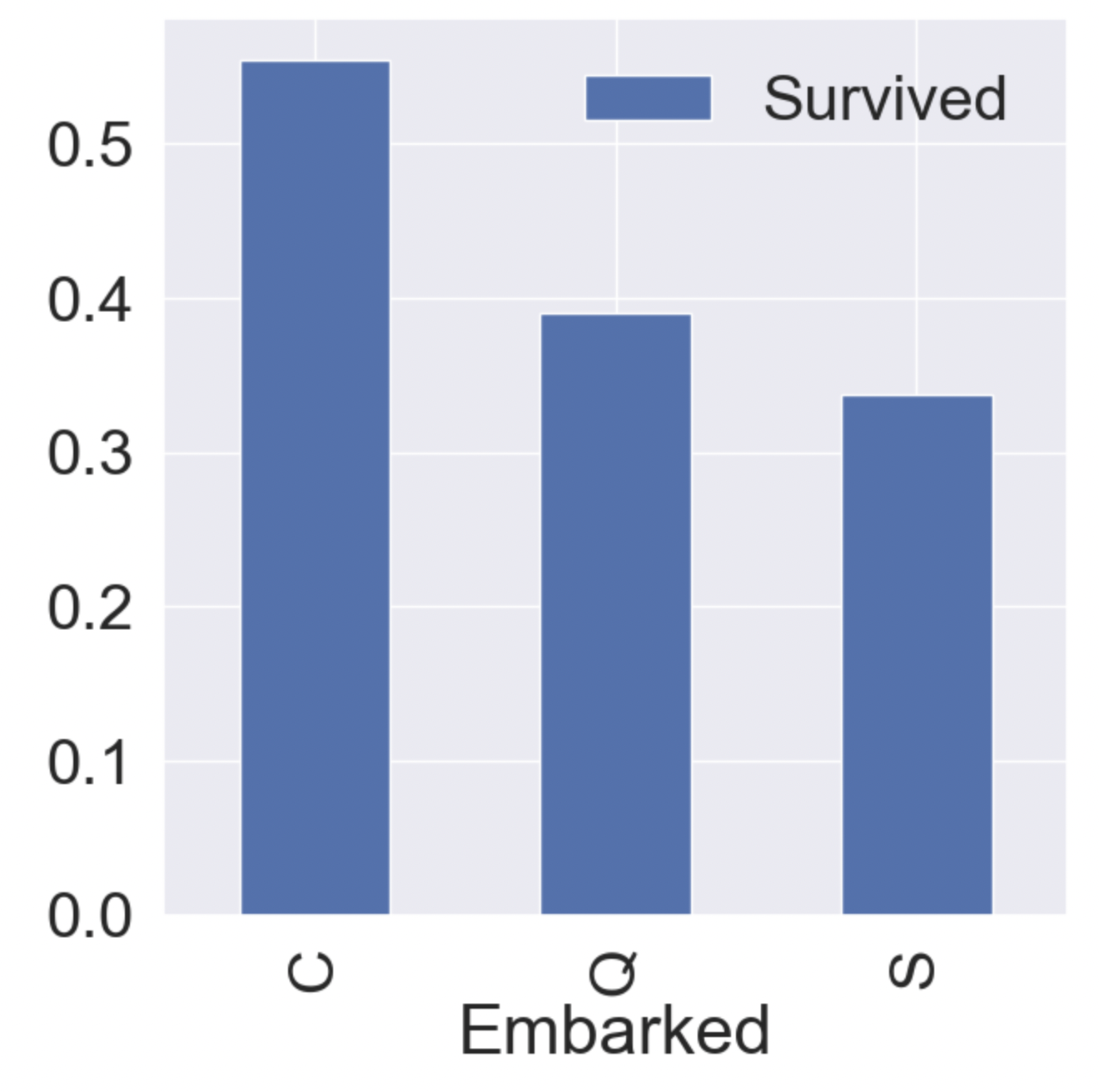
Embarked 사이에서 차이는 있지만 유의미한 결과를 도출할지는 의문이다.
이는 추후에 모델을 만들고 Feature가 얼마나 중요한 영향을 끼치는지 확인할 수 있는데 그 때 다시 봐보자
이번엔 Embarked를 각 범례별 나누어서 그래프를 그려보자
f, ax = plt.subplots(2, 2, figsize=(20, 15))
#탑승객 명수를 Countplot으로 그래프화
sns.countplot(data=df_train, x='Embarked', ax=ax[0, 0])
ax[0, 0].set_title('(1) No. Of Passengers Boarded')
#성별에 따라 탑승객 수를 나눠 Countplot으로 그래프
sns.countplot(data=df_train, x='Embarked', hue='Sex', ax=ax[0, 1])
ax[0, 1].set_title('(2) Male-Female Split for Embarked')
#탑승객의 생존자수를 Countplot으로 그래프
sns.countplot(data=df_train, x='Embarked', hue='Survived', ax=ax[1, 0])
ax[1, 0].set_title('(3) Embarked Vs Survived')
#탑승객 별 Pclass를 나누어 Countplot으로 그래프
sns.countplot(data=df_train, x='Embarked', hue='Pclass', ax=ax[1, 1])
ax[1, 1].set_title('(4) Embarked Vs Pclass')
#아마 그래프 사이의 간격을 조절
plt.subplots_adjust(wspace=0.3, hspace=0.5)
plt.show()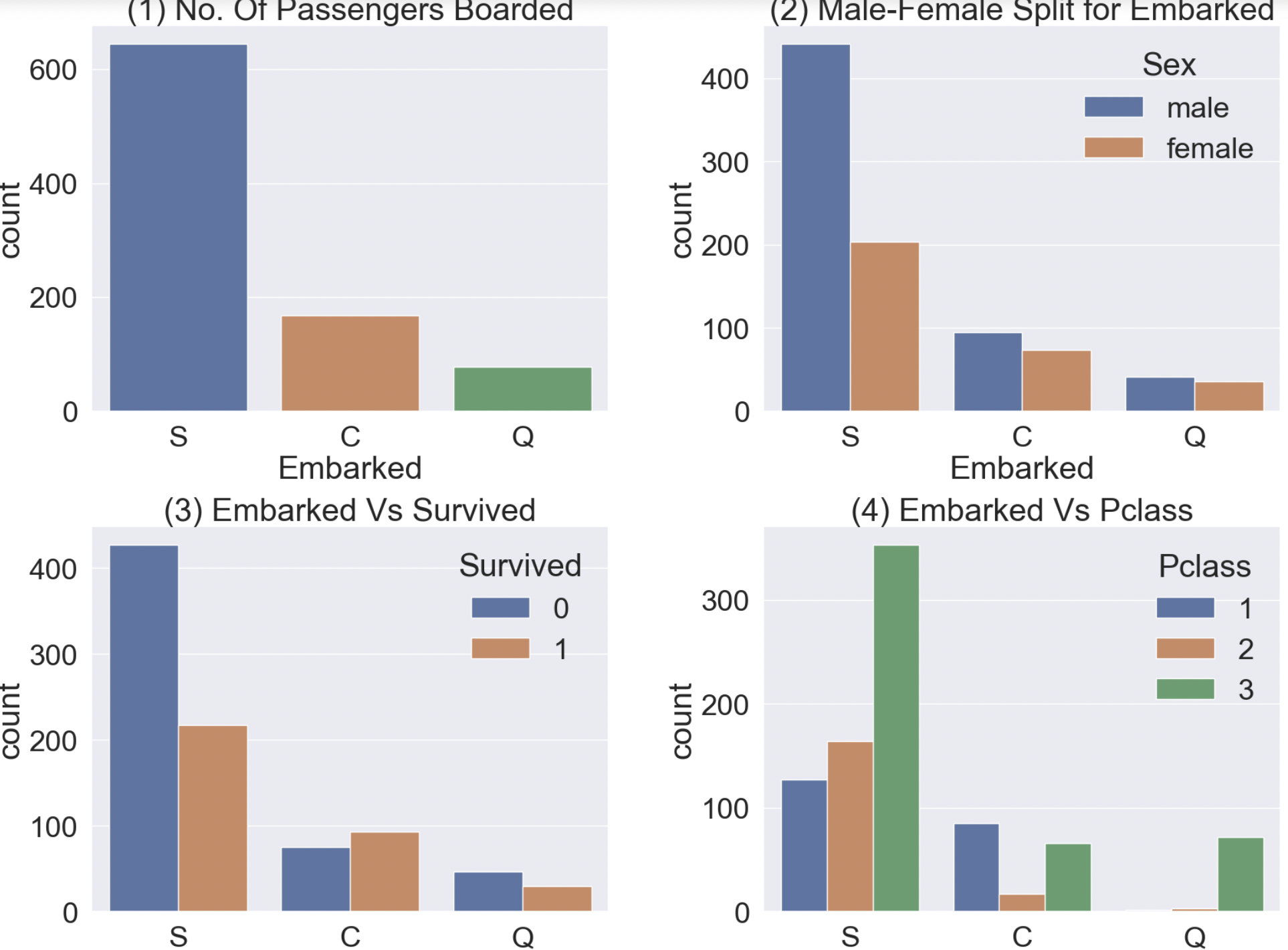
- (1) :
S에서 가장 탑승객이 많다. - (2) :
C,Q에서는 남녀 비율이 비슷하나S에서는 남자의 비율이 월등히 높다. - (3) :
S에서의 생존률이 가장 낮다. - (4) :
C의 생존률이 높은 이유는 First Class 비율이 높아서이고,S에서의 생존률이 낮은 이유는 Third Class의 비율이 월등히 높아서이다.
2.7 Family - SibSp(형제 자매) + Parch(부모, 자녀)
df의 Parch와 Sibsp를 합쳐 전체 가족 수를 구해보자
df_train['FamilySize'] = df_train['Parch'] + df_train['SibSp'] + 1 #본인 추가
df_test['FamilySize'] = df_train['Parch'] + df_train['SibSp'] + 1
print('Maximum size of Family : ', df_train['FamilySize'].max())
print('Minimum size of Family : ', df_test['FamilySize'].min())
이번엔 FamilySize와 Survived의 관계를 파악해보자
f, ax = plt.subplots(1, 3, figsize=(40,10))
sns.countplot(data=df_train, x='FamilySize', ax=ax[0])
ax[0].set_title('(1) No. Of Passengers Boarded', y=1.02)
sns.countplot(data=df_train, x='FamilySize', hue='Survived', ax=ax[1])
ax[1].set_title('(2) Survived countplot depending on FamilySize')
df_train[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=True).mean().sort_values(by='Survived', ascending=False).plot.bar(ax=ax[2])
ax[2].set_title('(3) Survived rate depending on FamilySize')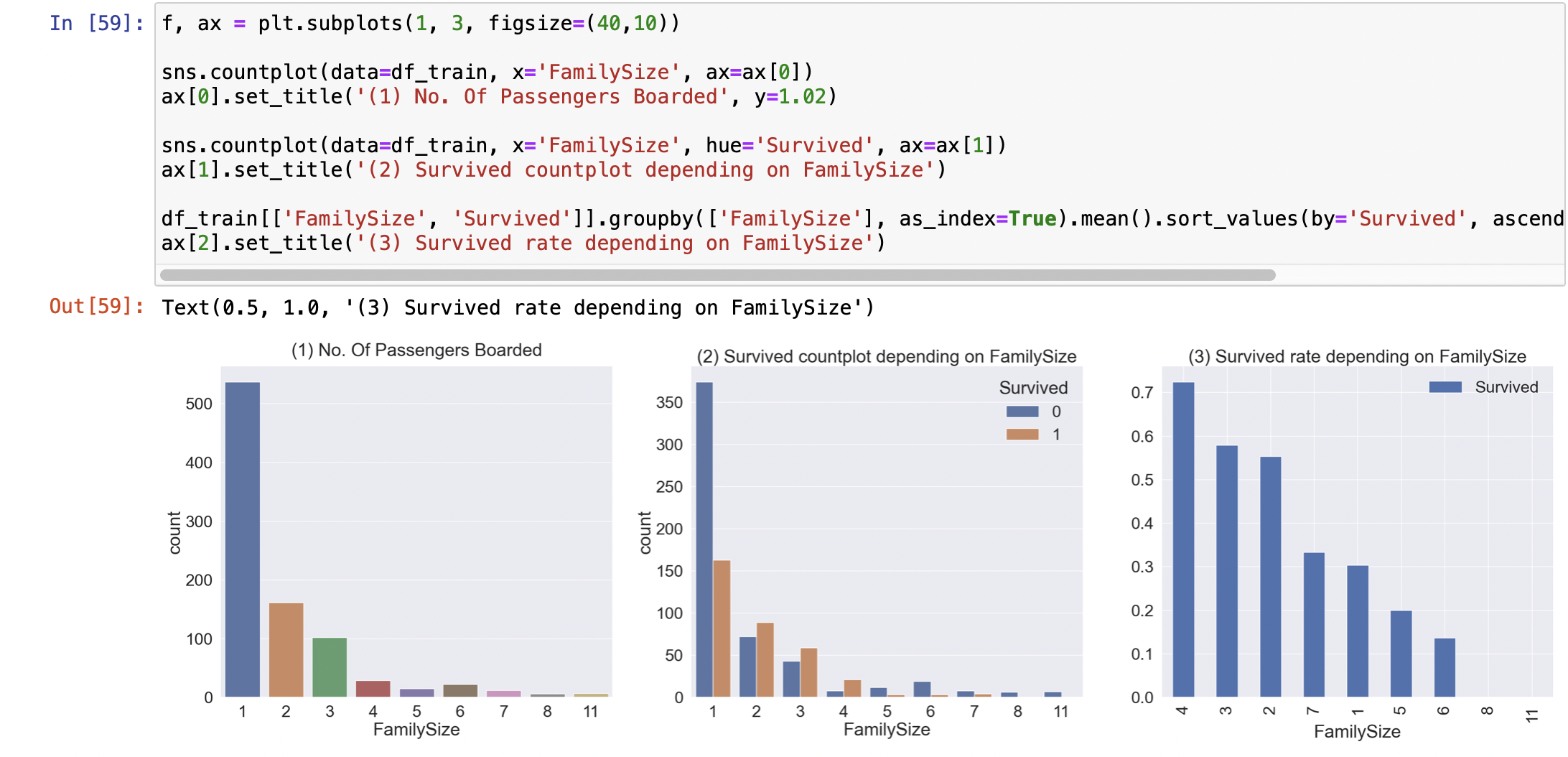
- (1) : 혼자 온 사람이 가장 많고 대체로 2~4명까지 온 탑승객이 많다
- (2)~(3) : 혼자 오거나 5명 이상 같이 온 탑승객의 생존률은 낮은 편, 2~4명에서 같이 온 탑승객의 생존률이 높다.
2.8 Fare
이번엔 요금에 대해 알아보자. 요금은 연속적 변수이다.
f, ax = plt.subplots(1, 1, figsize=(8, 8))
g = sns.distplot(df_train['Fare'], color='b', label='Skewness : {:.2f}'.format(df_train['Fare'].skew()), ax=ax)
g = g.legend(loc='best')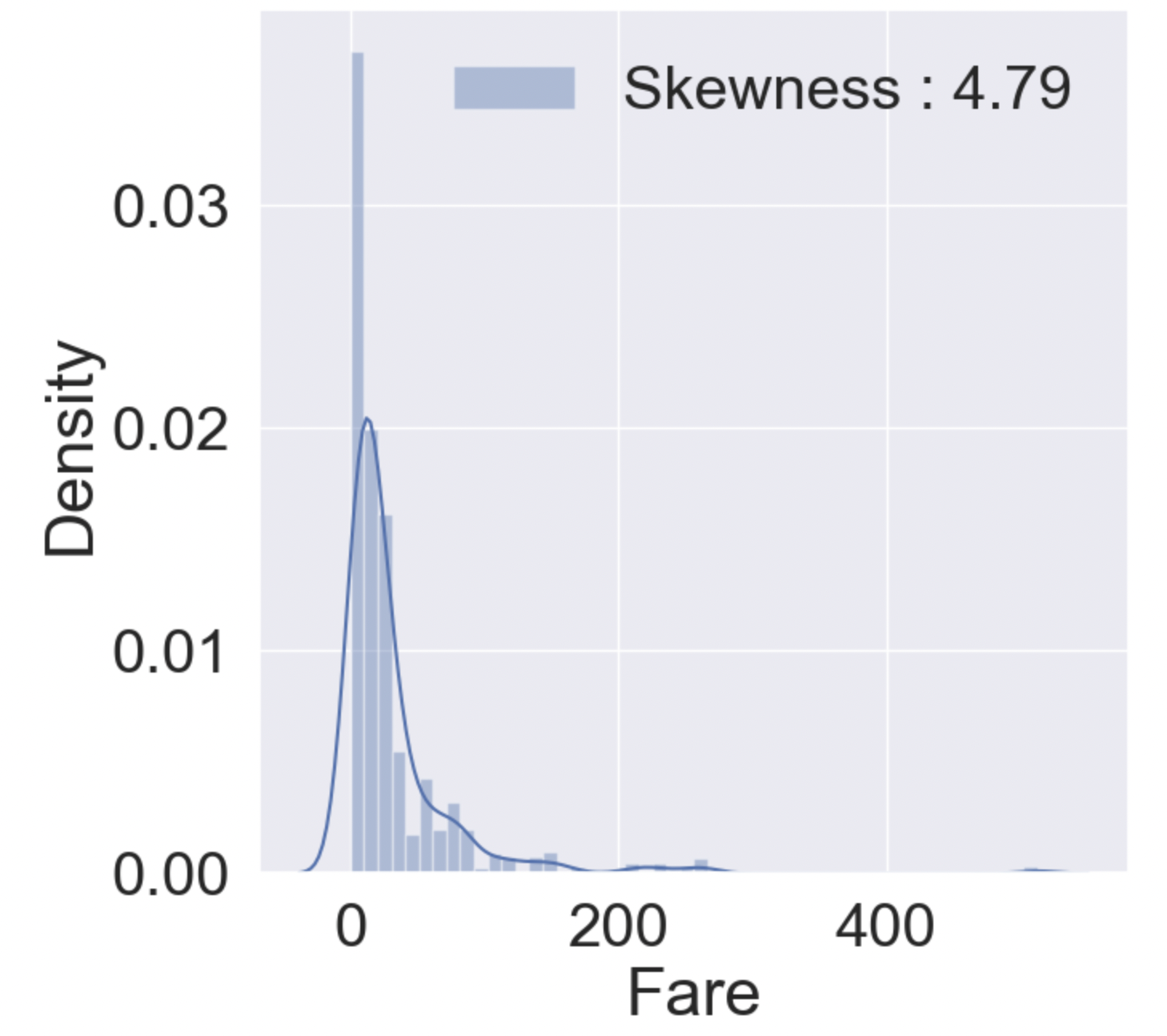
Skewness는 비대칭도(왜도)이다. 왜도가 음수일 경우 왼쪽으로 꼬리가, 양수일 경우 오른쪽으로 꼬리가 생긴다. 중앙값이랑 평균값이 동일할 경우 0으로 나타난다. 위 경우 왜도는 4.79로 오른쪽으로 꼬리가 긴 그래프 형태이다.
high Skewness일 경우 모델 학습할 때 모델이 잘못 학습할 수도 있다.
만약 그대로 학습할 경우 꼬리부분이 모델에 영향력이 없다. 만약 꼬리부분도 유믜미한 데이터면 데이터를 변환하여 모델학습을 시켜야한다.
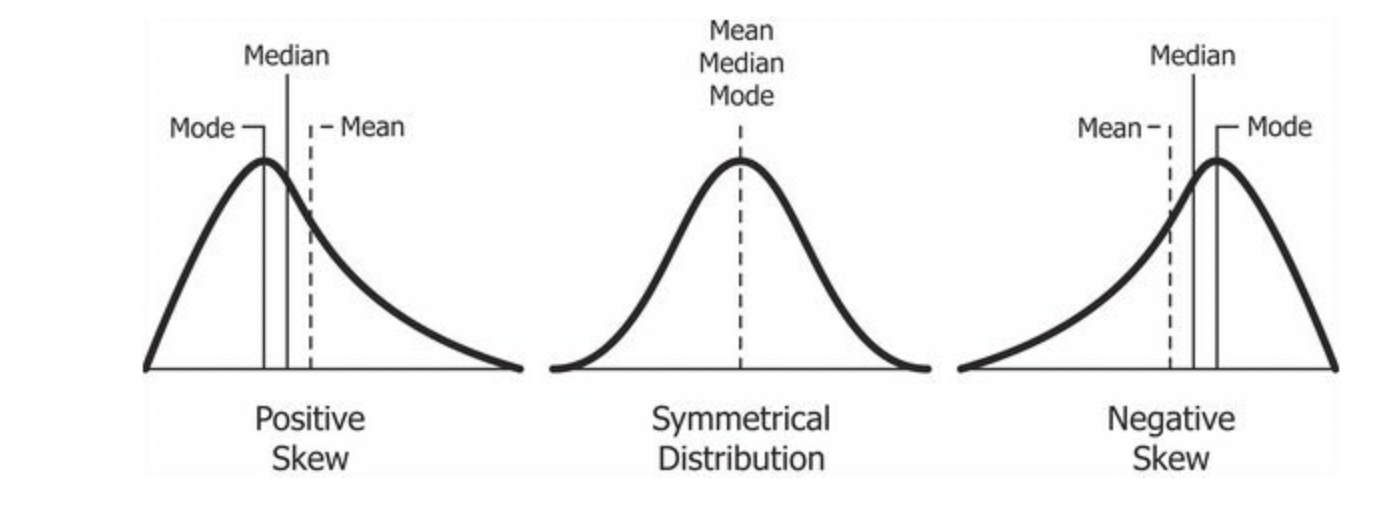
High Skewness 데이터 변환
데이터 학습 시 예측변수와 목표 변수가 정규분포를 따를 때 더 신뢰할 수 있는 에측이 가능하다. 따라서 왜도가 큰 경우 데이터를 변환시켜줘야 한다.
1. Log 치환
log로 변환하는 것은 왜도를 없애기 위한 가장 기초적인 방법이다.
만약 log로 치환하기 전에 최솟값이 음수값일 경우 최솟값 + 1로 양수로 만들어주자.
df_test.loc[df_test.Fare.isnull(), 'Fare'] = df_test['Fare'].mean()
df_train['Fare'] = df_train['Fare'].map(lambda i : np.log(i) if i > 0 else 0)
df_test['Fare'] = df_test['Fare'].map(lambda i : np.log(i) if i > 0 else 0)여기선 음수일 경우 0으로 변환해줬다.
f, ax = plt.subplots(1, 1, figsize=(7, 7))
g = sns.distplot(df_train['Fare'], color='r', label='Skewness : {:.2f}'.format(df_train['Fare'].skew()), ax=ax)
g = g.legend(loc='best')
위에 처럼 모델을 학습시키기 위해, 그리고 그 모델의 성능을 높이기 위해 feature 들에 여러 조작을 가하거나, 새로운 feature를 추가하는 것을 feature engineering 이라고 한다.
2. Square Root Transform
3. Box-Cox Transform / Box-Cox 변환
4. Negative(Right) Skewed Data일 경우
Positive(Left) Skewed Data로 변형해 준후 동일한 변환한다.
y'= -y - min(-y)
y'= -y - min(-y) + c(상수)
2.9 Cabin & Ticket
Cabin은 80%가 NaN값이다. 그러니 모델에 영향을 끼치긴 어렵다.
Ticket은 String으로 다양한 값을 가지고 있어 모델에 적용하기 위핸 아이디어가 필요하다.
