
식사하는 철학자 문제(Dining Philosophers problem)에서 고려해야 할 것
- Data Consistency
- Deadlock
- Starvation
- Concurrency
무슨 말인지 모르겠으니까 조금씩 이해해 보자 ,,,,
Process
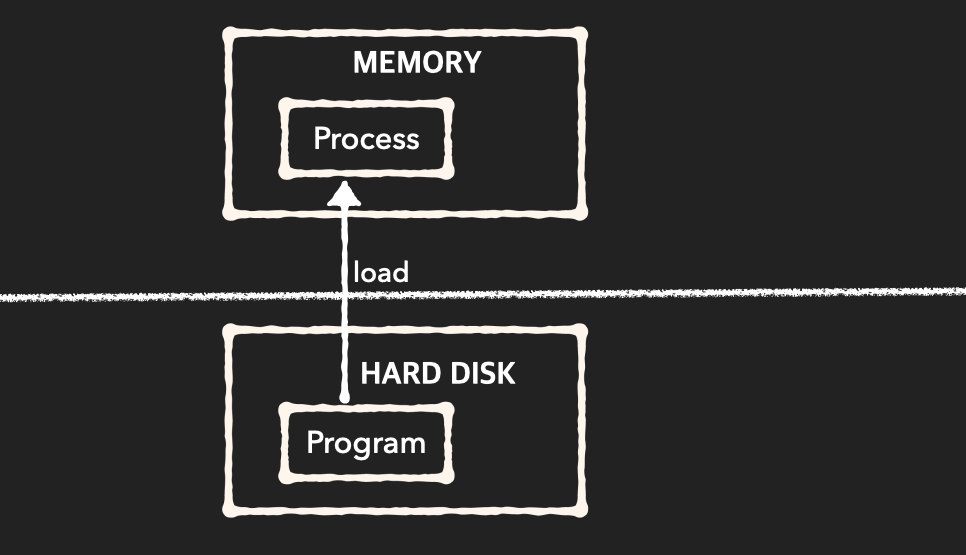
사전적 의미
- 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램
- 메모리에 올라와 실행되고 있는 프로그램의 인스턴스(독립적 개체)
- 운영체제로부터 시스템 자원(CPU 시간/프로그램 운영에 필요한 메모리 공간/Code, Data, Stack, Heap의 구조로 되어 있는 독립된 메모리 영역)을 할당받는 작업의 단위
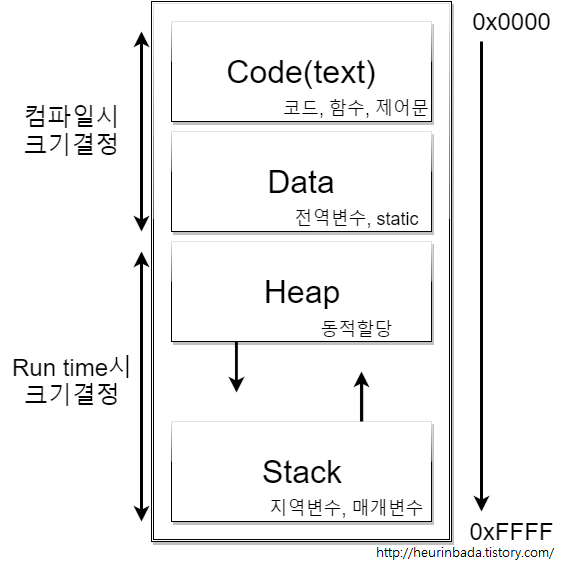
특징
- 프로세스는 각각 독립된 메모리 영역(Code, Data, Stack, Heap)을 가짐
- 각 프로세스가 별도의 메모리 공간에서 실행되므로, 한 프로세스는 다른 프로세스의 변수나 자료구조에 접근할 수 없음
- 다른 프로세스의 자원에 접근하고 싶다면 프로세스 간 통신을 사용해야 함(IPC, inter-process communication)
- 기본적으로 프로세스당 최소 1개의 스레드를 가짐(메인 스레드)
Context Switch
운영체제에 의해 프로세스가 스케줄링되며, 운영체제 동작 환경이 단일 코어라고 가정했을 때 하나의 코어에는 하나의 작업만 존재할 수 있음 !
이때 모든 프로세스를 처리하려면 한 프로세스 처리 후 그 다음 프로세스를 처리하는 식으로 프로세스 간 전환이 요구. 이와 같이 처리되는 프로세스의 전환을 Context Switching이라고 함
그렇담 Context Switching은 언제 일어나는가?
- 프로세스에게 할당된 Time Quantum(프로세스가 한 번에 처리될 수 있는 시간 총량)이 모두 소진된 경우
- I/O 호출과 같은 Interrupt에 의해
Context Switching이 발생하면 기존 수행 작업에서 새 작업으로 넘어가게 되므로, 새로운 작업을 불러올 뿐만 아니라 기존 수행 작업이 추후 이어서 수행되도록 저장할 수도 있어야 한다(Kernel의 Dispatcher에서 담당).
Kernel Mode와 User Mode, 그리고 시스템 콜(System Call)
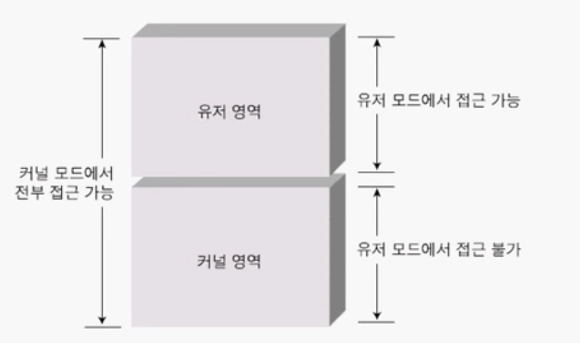
기본적으로 프로세스에서 Instruction을 수행하기 위해 CPU를 사용할 때, 해당 프로세스가 Kernel Mode인지 User Mode인지에 따라 CPU 실행이 달라진다.
Kernel Mode
Kernel Mode의 프로세스는 Instruction에 대해 모든 권한을 가지고 있으며 대표적으로는 운영체제가 이에 해당된다. 이러한 프로세스는 I/O 장치 제어 등 시스템 상에서 처리해야 하는 모든 Instruction을 하드웨어에게 요구할 수 있다.
User Mode
User Mode의 프로세스는 대체로 사용자에 의해 구동된 어플리케이션으로, 범용적 권한만을 가진다.
따라서 User Mode의 프로세스가 Kernel Mode로만 가능한 작업을 수행하고 싶다면 대체로 운영체제에게 요청해 서비스를 제공받게 된다. 이를 실행 모드 전환(Execution Mode Switch)라고 한다.
➡️ 이때 운영체제가 해당 서비스들을 요청할 수 있도록 제공하는 도구가 바로 시스템 콜이다.
시스템 콜
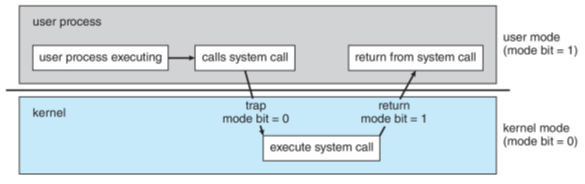
User Mode의 프로세스가 시스템 콜을 호출하면, 운영체제는 요청대로 작업을 수행한 뒤 User Mode로 복귀한다. 이와 같이 시스템 콜로 구현되어 있는 동작에는 open, write, fork, pipe 등이 있다.
Thread
사전적 의미
- 프로세스 내에서 실행되는 여러 흐름의 단위
- 프로세스의 특정한 수행 경로
- 프로세스가 할당받은 자원을 이용하는 실행의 단위
특징
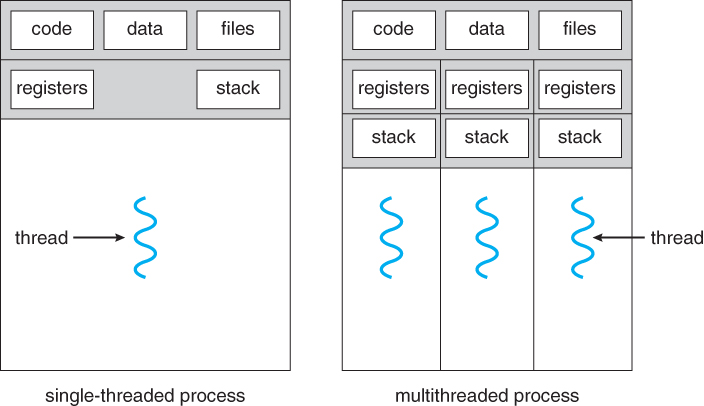
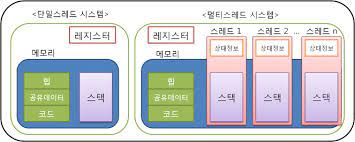
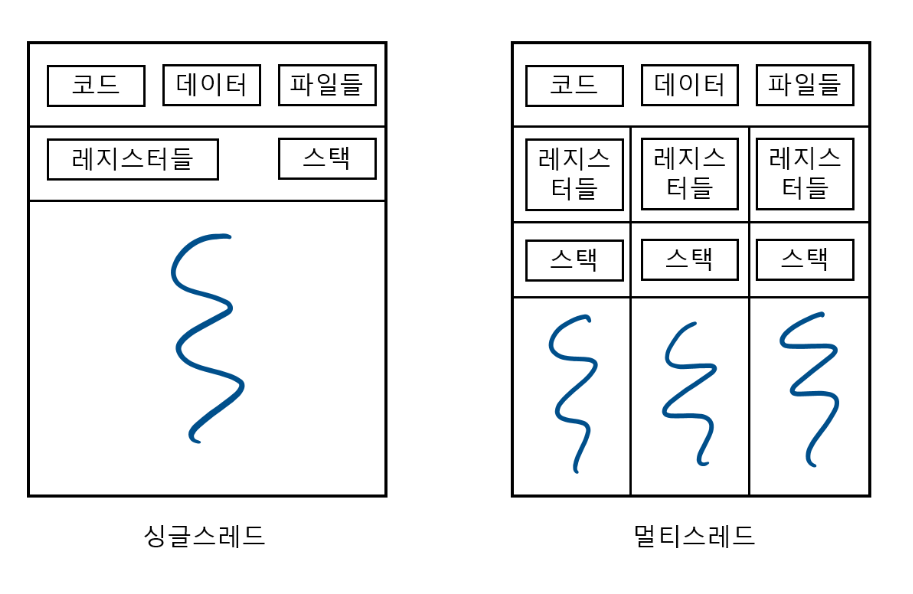
- 각 스레드는 프로세스 내에서 Stack만 따로 할당받고, Code, Data, Heap 영역은 공유
- 다시 말해 프로세스 내 주소 공간이나 자원을 스레드끼리 공유하며 실행됨!
- 각 스레드는 별도의 레지스터와 스택을 가지나 힙 메모리는 서로 읽고 쓸 수 있음 -> 한 스레드가 프로세스 자원을 변경하면 다른 이웃 스레드(sibling thread)도 그 변경 결과를 즉시 볼 수 있음
- 프로세스는 운영체제에 의한 스케줄링의 단위라면, 스레드는 실제 처리 단위를 말함! 프로세스는 스레드 단위로 처리된닷
멀티 프로세스와 멀티 스레드의 차이점
멀티 프로세싱
- 하나의 응용 프로그램을 여러 프로세스로 구성해 한 프로세스가 하나의 작업(Task)를 처리하도록 하는 것
- 장점: 여러 개의 자식 프로세스 중 하나에 문제가 발생하면 그 자식 프로세스만 죽고, 다른 영향이 확산되지 않음
- 단점
1. Context Switching에서의 오버헤드: 캐쉬 메모리 초기화 등 무거운 작업이 진행되고 많은 시간이 소모되는 등 오버헤드가 발생하게 됨 (프로세스는 각각 독립된 메모리 영역을 할당받으므로 공유 메모리가 없어, Context Switching이 발생 시 캐쉬 데이터를 모두 리셋하고 다시 불러와야 함)- 프로세스 사이 통신(IPC)이 어렵고 복잡함
멀티 스레딩
- 하나의 응용 프로그램을 여러 스레드로 구성해 한 스레드가 하나의 작업을 처리하게 하는 것
- 많은 운영체제(윈도우, 리눅스 등)가 멀티 프로세싱을 지원하긴 하나 멀티 스레딩을 기본으로 함
- 장점
- 시스템 자원 소모 적음(자원의 효율적 사용): 프로세스를 생성해 자원을 할당하는 시스템 콜이 줄어들어 자원의 효율적 관리 및 사용 가능
- 시스템 처리량 증가(처리 비용 감소): 스레드 간 데이터를 주고받는 것이 간단해지므로 시스템 자원 소모가 줄어듦, 스레드 사이 작업량이 작아 Context Switching 빠름
- 스레드 간 통신 방법이 간단함
- 단점
- 디버깅이 까다로움 -> 주의 깊은 설계 필요
- 단일 프로세스 시스템의 경우 효과 기대하기 어려움
- 다른 프로세스(프로세스 밖)에서 스레드 제어 불가
- 자원 공유 문제 발생
- 한 스레드에 문제 발생 시 전체 프로세스가 영향을 받음
Kernel-Level과 User-Level
Kernel-Level Thread
운영체제에서 스레딩을 지원하는 경우 이용할 수 있는 스레드로 Kernel 내에서 사용할 스레드를 의미한다.
주로 스케줄링 등을 관리하기 위해 사용된다.
User-Level Thread
Kernel 위에서 지원되는 스레드로, 일반적으로 User-Level 라이브러리를 통해 구현된다.
사용자들이 대체적으로 사용하는 스레드가 바로 이것으로, 별도로 속성 설정을 하지 않은 채로 스레드를 생성하면 User-Level로 생성된다. (스레드 지원 주체에 따라 나뉨)
라이브러리를 통해 스레드가 생성되며 이렇게 생성된 스레드는 동일 메모리 영역을 공유한 채로 생성된다.
