0. 서론
글을 시작하기에 앞서 이번 푸쉬스왑을 함께한 seunpark님(깃헙)님께 감사의 인사를 드리고 싶다.
깐부코딩 그거 괜찮더라,,, 괜히 42가 동료학습 동료학습 하는 게 아니라는 생각이 들었다.

그리고 다른 가이드 글이나 코드는 거의 참고하지 않았지만 정말 유용하게 쓴 테스터는 하나 있는데 이걸 만들어주신 제작자분께도 감사,,
테스터 링크는 여기
아 그리고 들어가기 전에 주의할 점이 있는데, 여기 작성되어 있는 알고리즘은 과제 기준으로 만점을 받은 건 아니라는 점이다. 만약 100점으로 통과하고 싶다면 여기 있는 알고리즘을 그대로 차용하지 말고 조금 더 생각해보고 최적화해보길 권한다.
1. push_swap 뭐하는 과제인가?
- A와 B라는 두 개의 스택이 주어진다.
- 스택 A에는 임의의 개수의 정수들이 중복 없이 채워져 있다.
- 스택 B는 비어 있다.
- 스택 A와 B, 그리고 적절한 "연산"을 통해 A의 숫자들을 오름차순으로 정렬해야 한다.
- 과제에서 사용할 수 있는 연산은 다음과 같다.
sa: A의 가장 위에 있는 두 원소(혹은 첫 번째 원소와 두 번째 원소)의 위치를 서로 바꾼다.sb: B의 가장 위에 있는 두 원소(혹은 첫 번째 원소와 두 번째 원소)의 위치를 서로 바꾼다.ss:sa와sb를 동시에 실행한다.pa: B에서 가장 위(탑)에 있는 원소를 가져와서 A의 맨 위(탑)에 넣는다. B가 비어 있으면 아무 것도 하지 않는다.pb: A에서 가장 위(탑)에 있는 원소를 가져와서 B의 맨 위(탑)에 넣는다. A가 비어 있으면 아무 것도 하지 않는다.ra: A의 모든 원소들을 위로 1 인덱스만큼 올린다. 첫 번째 원소(탑)는 마지막 원소(바텀)가 된다.rb: B의 모든 원소들을 위로 1 인덱스만큼 올린다. 첫 번째 원소(탑)는 마지막 원소(바텀)가 된다.rr:ra와rb를 동시에 실행한다.rra: A의 모든 원소들을 아래로 1 인덱스만큼 내린다. 마지막 원소(바텀)는 첫 번째 원소(탑)가 된다.rrb: B의 모든 원소들을 아래로 1 인덱스만큼 내린다. 마지막 원소(바텀)는 첫 번째 원소(탑)가 된다.rrr:rra와rrb를 동시에 실행한다.
- 최소한의 연산만을 사용해 A의 숫자들을 정렬해보자!
2. 복잡도(Complexity)를 고려해 알고리즘 선택하기
Sorting values is simple.
To sort them the fastest way possible is less simple, especially because from one integers configuration to another, the most efficient sorting algorithm can differ.값 정렬은 간단하다. 가능한 한 가장 빠르게 값을 정렬하는 것은 덜 간단하다. 특히 정수 구성마다 가장 효율적인 정렬 알고리즘이 다를 수 있기 때문이다.
push_swap 서브젝트로부터
복잡도(Complexity)라는 개념은 알고리즘의 효율성을 나타내는 지표로, 개발자에게 매우 중요한 개념이다.
우리는 push_swap에서 최소한의 연산만을 사용해 스택 A의 숫자들을 정렬해야 하므로 복잡도라는 개념에 대해 먼저 알아보고 이를 고려해 알고리즘을 설계해야 한다 !!
+) 복잡도에 대해 조금 더 자세히 알고 싶다면 이다음 포스팅인 복잡도(Complexity): 시간 복잡도와 공간 복잡도, 그리고 빅오(Big-O) 표기법을 읽어보시길 권한다. push_swap 과제 했는데 이 정도는 알아야겠다 싶어서 열심히 정리함,,,
⏰ 정렬 알고리즘별 시간 복잡도
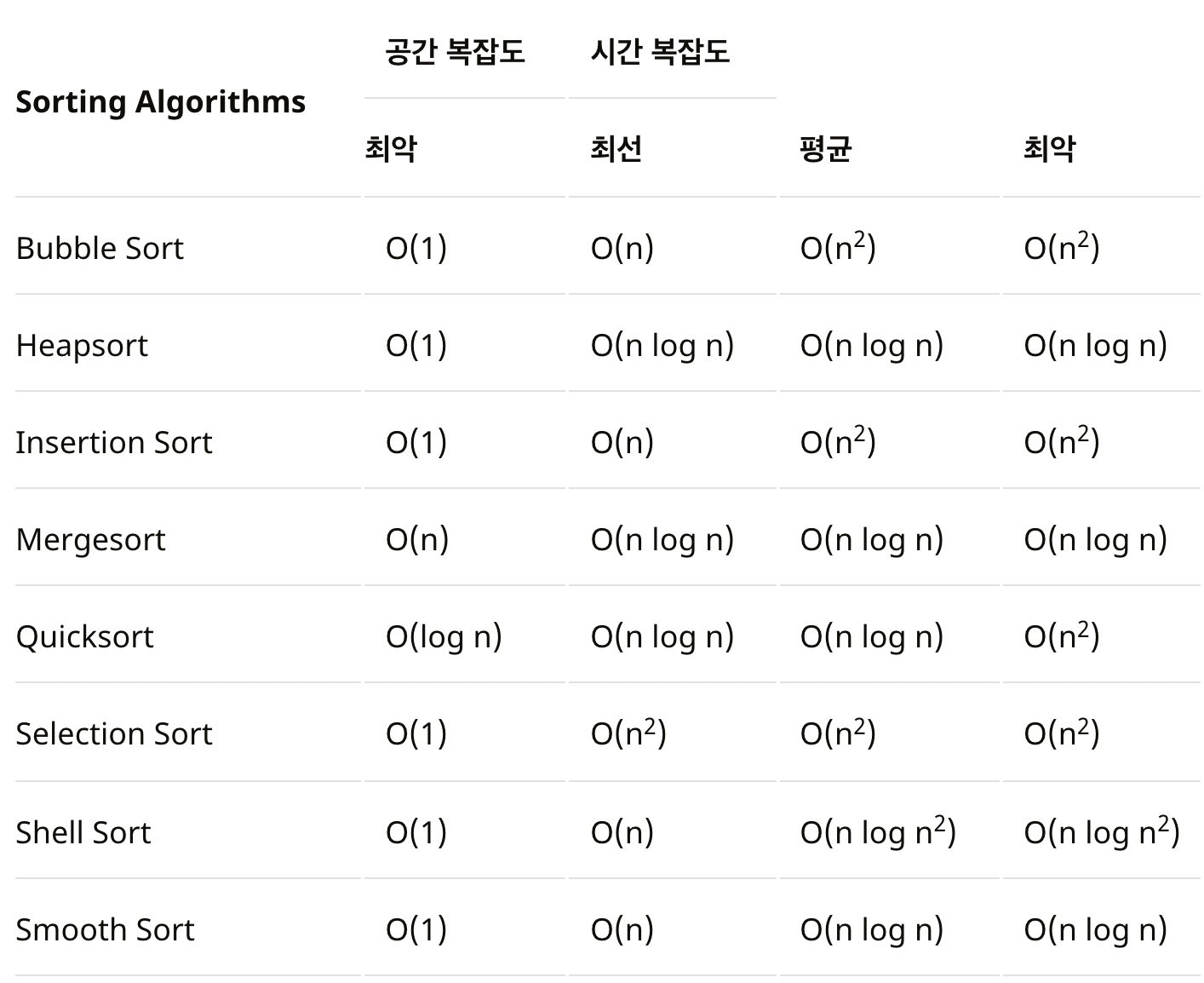
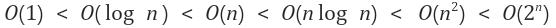
위의 표와 부등식(오른쪽으로 갈수록 효율이 나쁨)을 보았을 때,
평균의 경우를 고려하면 가장 효율이 좋은 알고리즘은 O(n log n)인 Heap Sort, Merge Sort, Quick Sort, Smooth Sort임을 알 수 있다.
물론 정렬 알고리즘 그대로를 문제 해결에 적용할 수는 없지만(사용할 수 있는 연산이 정해져 있어서🥲) 어떤 정렬 알고리즘을 기반으로 나만의 알고리즘을 설계할 것인지 생각해 두는 것이 좋다.
🤖 알고리즘 선택하기
평균의 경우를 고려했을 때 Heap Sort, Merge Sort, Quick Sort, Smooth Sort가 O(n log n)으로 가장 효율이 좋음을 위에서 확인했다.
그리고 내가 선택한 정렬 알고리즘은 이 넷 중 바로바로 Quick Sort이다 ⭐️
💡 Quick Sort를 선택한 이유
- 스택 2개만 사용할 수 있다는 제약이 있어 트리로 구현해야 하는 Heap Sort, Smooth Sort는 제외했다.
- Merge Sort와 비교했을 때 pivot이라는 기준이 되는 값이 있어 구현이 쉽다.
- pivot 기준으로 값을 비교하여 정렬하기에, pivot을 효율적으로 선택하면 알고리즘 효율을 개선할 수 있을 것 같았다! ➡️ 그런데 그것이 실제로 일어났습니다. 피벗정렬에 따른 퀵정렬의 속도
어떤 알고리즘으로 정렬할지 결정했다면 반은 끝난 것이다. 이제 노가다 그리고 노가다를 하면 된다!
3. 전처리 작업 🔨 (스택 구현, 인자 파싱, 예외처리)
노가다의 시작
알고리즘대로 값을 정렬하기 전에 먼저 해주어야 할 일들이 있다.
해야 할 일들을 나열해 보면 다음과 같다.
-
과제 설명은 스택 A와 B가 이미 있는 상태에서의 일들을 설명하고 있지만 사실 우리에겐 아무것도 없으므로 스택 먼저 구현해야 한다.
-
구현한 스택을 사용하기 위해 Push, Pop 등의 기본 함수를 구현해야 한다.
-
우리가 작성한 프로그램이 인자(argv)를 받을 때 여러 개의 인자가 들어오는 경우 (인자가 없는 경우 예외처리 필요), 하나의 문자열에 여러 개의 값이 포함되어 있는 경우를 고려해 파싱하는 함수를 만들어야 한다. 예를 들면:
$ ./push_swap "1 3 7 2" "3 9"
$ ./push_swap 8 2 "1 5" 63 "70 12 3"-
파싱한 인자들을 검사하여 예외처리를 해야 한다. (정수가 아닌 경우, 중복이 있는 경우 등)
-
인자들을 스택 A에 순서대로 Push해야 한다.
나는 이렇게 했다는 것일 뿐 꼭 이 순서대로 수행할 필요는 없다. 하지만 예외처리 같은 경우 서브젝트에 예시가 나와 있으니 꼭 꼼꼼하게 처리해주자 !!
💽 스택 구현 및 스택 관련 함수 작성
스택을 어떤 자료구조로 구현해야 하는지에 대한 고민이 있었다 🤔
-
배열
: 어차피 전체 스택의 크기는 처음 인자를 파싱할 때 알 수 있으니 (받은 인자를 따로 저장해두고 크기를 세면 될 거 같다는 생각) 배열로 구현해도 되지 않을까?!
➡️ 스택의 최대 크기는 정해져 있지만, 스택에서 원소를 Push/Pop 하면 다른 원소들을 한 칸씩 이동시켜주어야 한다는 귀찮음이 있어 기각 -
단방향 연결리스트
: 스택 크기만큼 node를 할당해 값을 넣어주면 되고, Push/Pop도 node를 free해주거나 생성해서 연결해주면 되니까 이거 괜찮을 거 같다!
➡️ 단방향으로 구현했을 시 node의 오른쪽 값밖에 볼 수 없어 값 비교나 타 연산에 제약이 생기므로 기각 -
양방향 연결리스트
: 공간 복잡도가 단방향 연결리스트에 비해 크지만, 연산에 제약이 줄고 알고리즘 설계할 때 편하므로 채택 !!
위와 같은 이유로 양방향 연결리스트로 스택을 구현하기로 했고, 헤더 파일에 다음과 같이 코드를 작성했다.
// push_swap.h
typedef struct s_node
{
int val;
struct s_node *left;
struct s_node *right;
} t_node;
typedef struct s_stack
{
struct s_node *top;
struct s_node *bottom;
} t_stack;stack 구조체에서 top과 bottom은 의미 없는 임의의 값을 가진 node로, 스택의 top과 bottom을 가리킨다. 스택 순회를 조금 더 간편하게 하기 위해 넣어 주었다.
그리고 스택 관련 함수들을 작성했다.
// push_swap.h
/*util_stack.c*/
t_node *get_new_node(int num);
void init_stack(t_var *var);
void push_top(t_stack *stack, t_node *new_node);
void push_bottom(t_stack *stack, t_node *new_node);
t_node *pop_top(t_stack *stack);
t_node *pop_bottom(t_stack *stack);
스택은 큐와 다르게 후입선출이지만, push_swap에서는 정해진 연산을 사용해 스택을 정렬하므로 연산 사용의 편의성을 위해 push, pop을 top과 bottom에서 둘다 가능하도록 했다.
🥸 인자 파싱 및 예외 처리
$ ./push_swap "1 3 7 2" "3 9" -> 1 3 7 2 3 9
$ ./push_swap 8 2 "1 5" 63 "70 12 3" -> 8 2 1 5 63 70 12 3어떻게 하면 멋지게 argv를 파싱해 정수값을 스택에 넣을 수 있을까?
나는 argv에서 해답을 찾았다. 각 인자 하나하나(문자열)에 대해 정수값을 찾아주면 된다고 생각했다.
그래서 생각한 전처리 로직을 간단하게 작성해 보면 다음과 같다.
i = 0; // 첫 인자는 프로그램의 이름이므로 그 다음 인자부터
while (++i < argc)
{
j = -1;
while argv[i][++j]가 널 문자가 아닌 경우
{
if argv[i][j]가 널 문자가 아니고 공백 문자도 아닌 경우, 즉 숫자나 문자인 경우
{
from = argv[i][j];
while argv[i][j]가 숫자나 문자인 경우
j++; // 다음 공백 문자를 찾기 위함
to = argv[i][j]; // 널 문자 혹은 공백 문자를 가리킴
ft_atoi(from, to); // atoi 함수로 정수로 변환
변환한 정수의 개수를 count
변환한 정수를 스택에 push
}
}
}들어온 값이 숫자가 아닌 경우의 예외 처리는 atoi 함수 내에서 해줘도 되고, atoi 함수의 반환값을 이용해 바깥에서 해도 된다.
INT_MAX, INT_MIN의 경우도 예외처리해야 하니 주의할 것!
중복 검사는 스택에 모든 값들을 다 push한 후 스택을 순회하며 수행했다.
☑️ pivot을 선택하기 위해 정렬된 배열 만들기
아까 위에서 잠깐 언급했듯 Quick Sort는 pivot 설정에 따라 효율이 달라질 수 있다.
그 중에서도 pivot을 중앙값으로 설정할 경우 가장 효율적으로 정렬할 수 있기에 pivot을 똑똑하게 선택할 수 있도록 하고 싶었다.
고민해 본 결과, 내가 그렇게 하기 위해 선택한 방법은 스택 이외 다른 메모리 공간에 같은 값들을 저장하고, 이 값들을 정렬해 가지고 있도록 하는 것이었다. 스택의 값들을 배열에 복사하고, 이 배열에 있는 값들을 퀵정렬 함수를 이용해(여기에서는 어떤 정렬 알고리즘을 사용해도 상관없다) 정렬해 스택이 들어 있는 구조체에 넣어 주었다.
참고로 스택이 들어 있는 구조체는 아래와 같이 생겼다.
// push_swap.h
typedef struct s_var
{
int max_size;
int *pivot_arr; // pivot을 뽑기 위해 정렬해 둔 배열
struct s_stack *stack_a;
struct s_stack *stack_b;
struct s_list *list;
int a_size;
int b_size;
} t_var;tmi를 하나 덧붙이자면 원래는 배열 정렬할 때 기수정렬 적용하려다가 음수까지 한 번에 처리하는 게 안 된다는 사실을 알게 되어 퀵정렬로 바꿨다,,,
아무튼 여기까지 했다면 이제 스택을 정렬하기 위한 준비는 완료되었다.
이제 주어진 연산들을 이용해 스택 A를 정렬하면 된다!
4. 스택 정렬하기
자료구조와 정렬할 때 사용할 수 있는 연산이 정해져 있다. 즉 제약이 제법 많다..!
이 제약들 안에서 내가 선택한 알고리즘을 어떻게 적용하여 나만의 알고리즘을 만들지 생각해보아야 한다.
⚠️ 주의! 이 뒤의 내용에는 글쓴이의 주관적인 알고리즘이 담겨 있습니다.
나는 Quick Sort를 사용하기로 결정했고, 내가 접해 본 퀵소트는 단 하나의 피벗을 사용하는 Single Pivot Quick Sort였기에 이것을 적용해보기로 마음먹었다. 다시 말하지만 내 주관적인 알고리즘이고 나는 100점을 받지는 못했다는 점을 기억해 주시길 바란다 ,,,!!
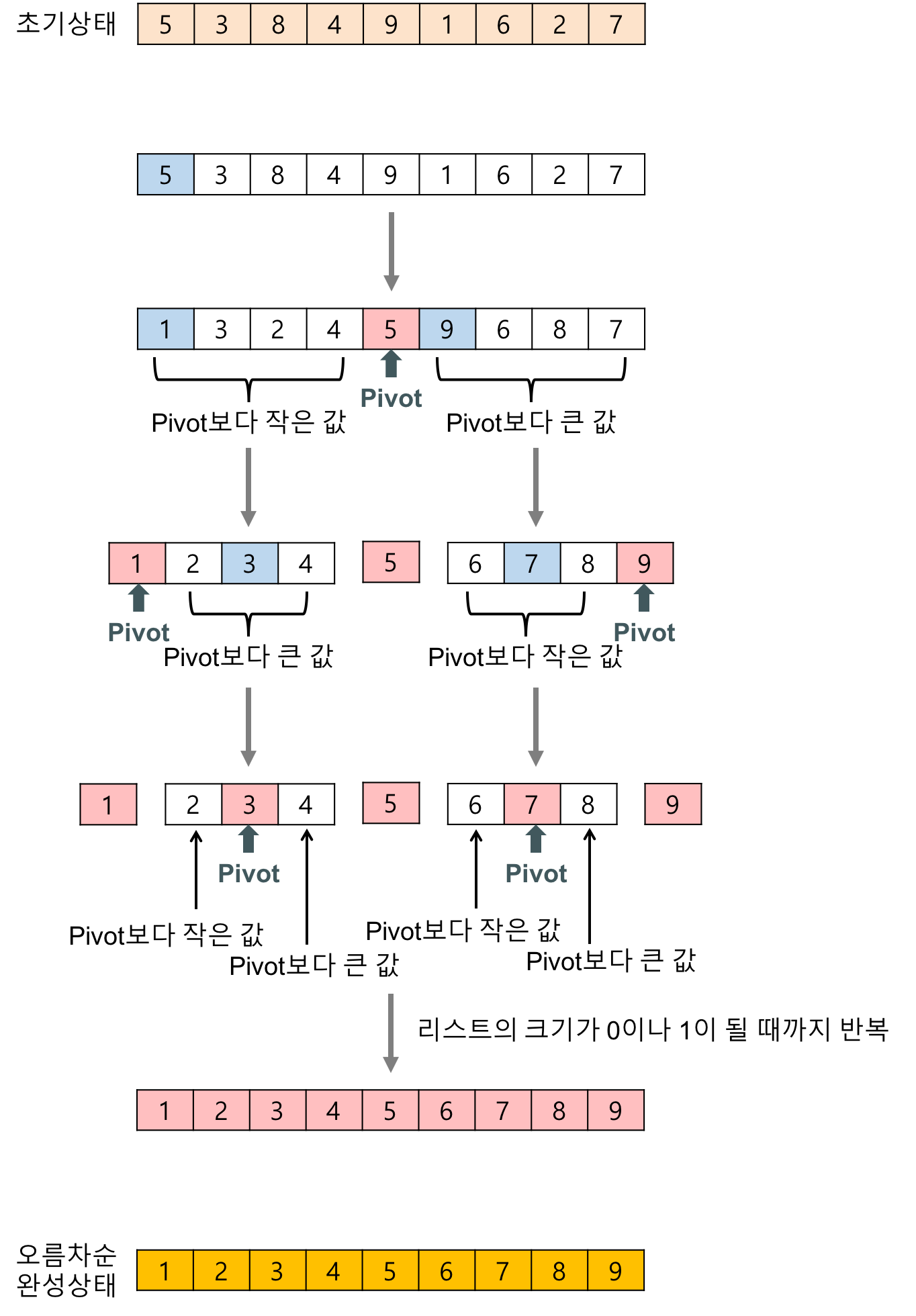
일반적인 퀵소트는 피벗을 설정할 때 랜덤으로 설정하지만, 내가 하려는 퀵소트에서는 피벗을 중앙값으로 설정하므로 위 그림과 같다. 위 그림과 다른 점은, 나는 피벗을 기준으로 절반은 다른 스택에 보내고 나머지 절반에서 다시 피벗을 잡아 정렬한다는 점?!
💬 Pseudo Code
전체적으로는 재귀함수를 사용해 A를 정렬한 뒤 B를 정렬하고 B에서 A로 원소를 보내주는 방식이다.
pseudo code로 나타내 보면 다음과 같다.
re(재귀에 필요한 파라미터) // 최초로 재귀함수를 호출하는 함수
{
if (현재 스택의 가변 크기가 일정 크기 이하)
정렬하고 return ;
reA(재귀에 필요한 파라미터); // A를 정렬하는 재귀함수
reB(재귀에 필요한 파라미터); // B를 정렬하는 재귀함수
while (B에서 A로 보내야 할 원소의 수--)
pb();
}🎨 도식화해보기
- 정렬하기 전 상태

- 피벗을 잡아 절반을 다른 스택으로 보냄
- 나의 경우 피벗보다 같거나 작은 값은 B에서 내림차순 정렬, 큰 값은 A에서 오름차순 정렬함 - 마지막에 스택 B에서 pb 명령어로 원소들을 스택 A에 보내줄 때 용이하도록
- 피벗보다 같거나 작은 값은 pb로 B에 보내고, 큰 값은 ra로 뒤로 넘겨줌
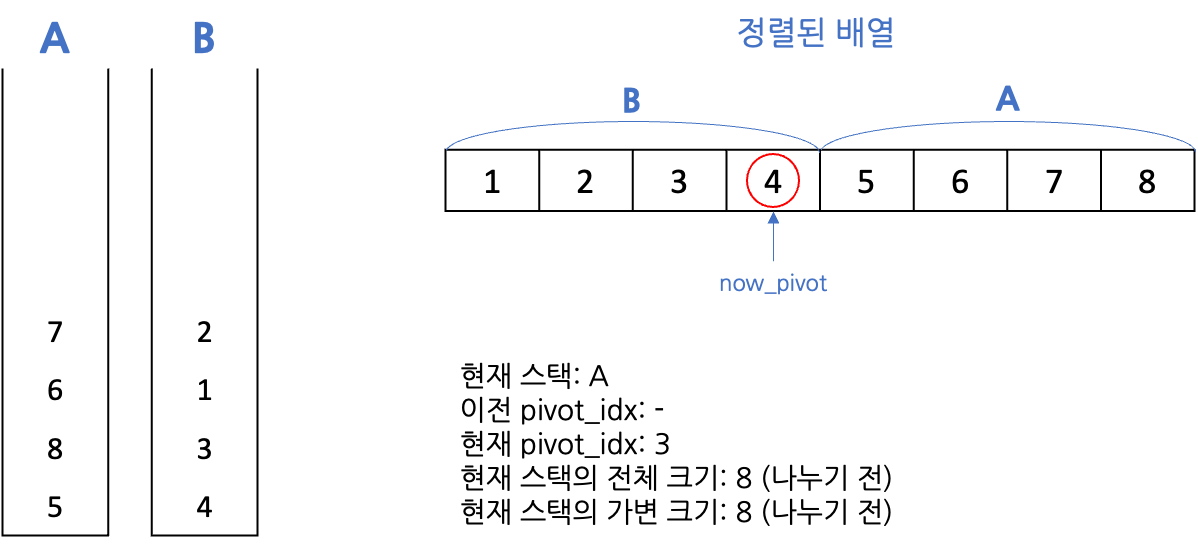
- 현재 스택의 가변 크기가 일정 크기 이하일 때까지(여기에서는 2) 재귀함수 안으로 들어가며 절반을 다른 스택으로 보냄
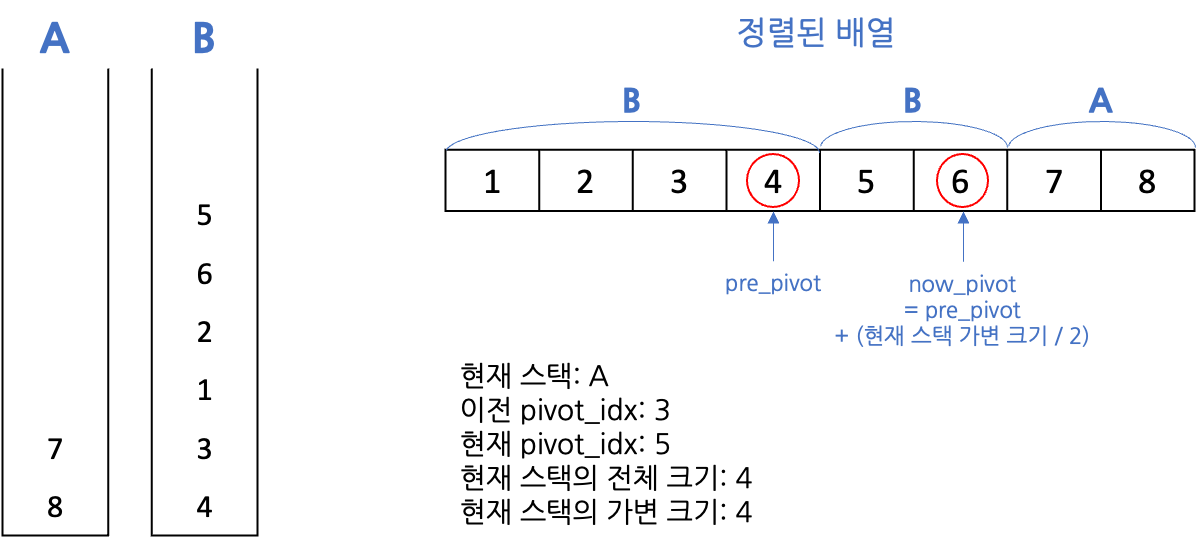
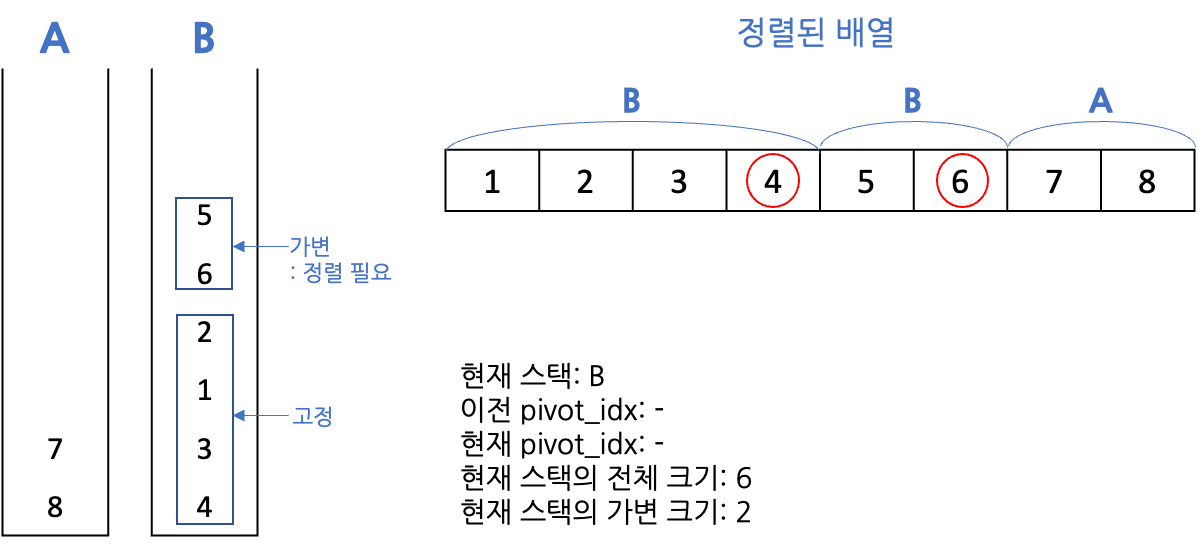
-
현재 스택의 가변 크기가 일정 크기 이하가 되면 정렬, 위의 경우 A가 이미 오름차순 정렬되어 있으므로 생략
-
정렬 완료했다면 다른 스택으로 넘어감, 마찬가지로 가변 크기가 일정 크기 이하이면 정렬
- 정렬 완료 후 현재 스택이 B였다면 정렬 완료된 원소들을 A로 보냄
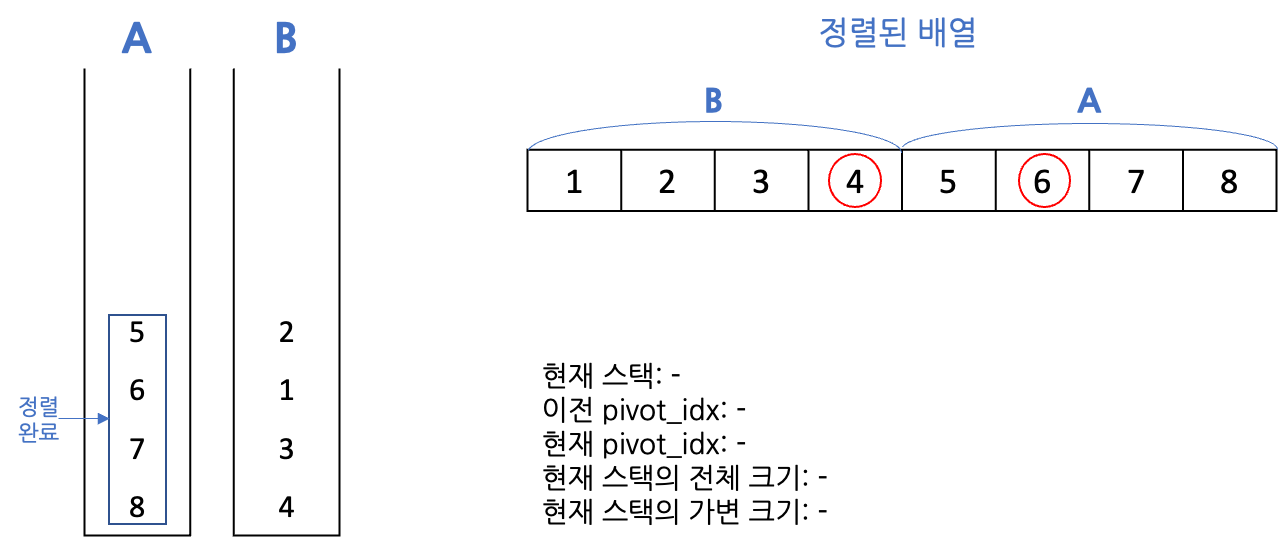
- 크기 4일 때 A의 정렬은 완료되었으므로, 다시 B로 넘어와 피벗을 잡아 절반을 다른 스택으로 보냄
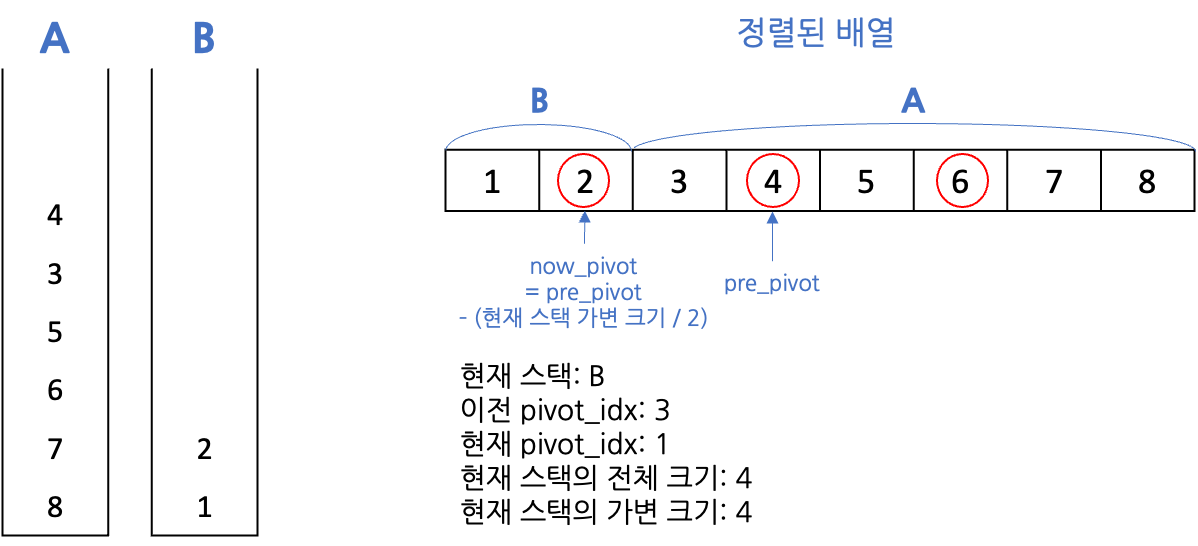
- 위와 비슷하게 잘 반복
이런 식으로 정렬했다. 나름 열심히 정리해 봤지만 그래도 혹시 이해가 잘 안 되신다면 댓글 남겨주세요 ..!
🤔 몇 개까지 쪼갠 후 정렬할 것인가?
이 부분은 많은 분들에게 조언을 얻어 본 결과 보통 5개부터 정렬을 하드코딩으로 처리하시는 것 같았다.
그치만 나는 4개부터 처리했고, 그나마도 하드코딩으로 했을 때 확실히 명령어가 더 적게 나오는 경우에만 따로 정렬해 주었다. 3개 이하부터는 무조건 하드코딩으로 처리했다.
이 부분은 아무래도 직접 해보면서 최적화하는 게 가장 좋은 것 같다.
5. 사용한 연산(명령어) 최적화하기
push_swap 과제를 진행하면서 내가 마지막으로 한 일은 바로 스택을 정렬하기 위해 사용한 연산들을 (물론 최소한의 연산을 사용하기 위해 노력했지만) 최적화해보는 것이었다.
리마인드해보자면 스택을 정렬하기 위해 우리에게 주어진 연산은 다음과 같았다.
sa: A의 가장 위에 있는 두 원소(혹은 첫 번째 원소와 두 번째 원소)의 위치를 서로 바꾼다.sb: B의 가장 위에 있는 두 원소(혹은 첫 번째 원소와 두 번째 원소)의 위치를 서로 바꾼다.ss:sa와sb를 동시에 실행한다.pa: B에서 가장 위(탑)에 있는 원소를 가져와서 A의 맨 위(탑)에 넣는다. B가 비어 있으면 아무 것도 하지 않는다.pb: A에서 가장 위(탑)에 있는 원소를 가져와서 B의 맨 위(탑)에 넣는다. A가 비어 있으면 아무 것도 하지 않는다.ra: A의 모든 원소들을 위로 1 인덱스만큼 올린다. 첫 번째 원소(탑)는 마지막 원소(바텀)가 된다.rb: B의 모든 원소들을 위로 1 인덱스만큼 올린다. 첫 번째 원소(탑)는 마지막 원소(바텀)가 된다.rr:ra와rb를 동시에 실행한다.rra: A의 모든 원소들을 아래로 1 인덱스만큼 내린다. 마지막 원소(바텀)는 첫 번째 원소(탑)가 된다.rrb: B의 모든 원소들을 아래로 1 인덱스만큼 내린다. 마지막 원소(바텀)는 첫 번째 원소(탑)가 된다.rrr:rra와rrb를 동시에 실행한다.
예를 들면 sa를 수행하고 이후에 바로 sb를 수행했다면, 이 두 명령어는 ss라는 명령어 하나로 압축될 수 있다.
또 다른 예를 들면 ra를 수행하고 이후에 바로 rra를 수행했을 경우에는 두 명령어가 상쇄되므로 삭제할 수 있다.
이런 경우의 수들을 잘 생각해 보고 상황에 맞게 잘 최적화해주면 연산 최종 개수가 정말 많이 줄어드는 것을 확인할 수 있다. 단, 이렇게 최적화를 하려면 연산을 하나 수행할 때마다 바로바로 명령어를 출력해서는 안 된다. 나의 경우에는 메모리 공간 어딘가에 명령어 리스트를 잘 저장해 뒀다가 스택 정렬이 끝나고 나서 리스트를 최적화해 한꺼번에 출력하였다.
명령어 리스트는 다음과 같이 구현했다.
// push_swap.h
typedef struct s_list_node
{
char *val;
struct s_list_node *left;
struct s_list_node *right;
} t_list_node;
typedef struct s_list
{
struct s_list_node *top;
} t_list;이 또한 스택을 구현했을 때처럼 노드 탐색에 용이하도록 양방향 연결리스트로 구현하였다.
6. 마치며
push_swap 마치고 평가 받은 지는 꽤 됐는데 막상 글로 정리하려니 힘들어서 생각보다 오래 걸렸다 😝
다시 한 번 강조하지만 내가 여기에 쓴 알고리즘으로는 평가표 기준 100점을 받을 수 없다,,,
다만 나는 알고리즘을 뜯어 고치려면 다시 처음부터 해야 하다 보니 엄두가 안 나서 그냥 제출한 것일 뿐,,,
그러니 이 글을 읽으시는 분들은 100점을 받고 보너스까지 하고 싶으시다면 꼭 자신만의 알고리즘을 잘 생각해보시고 최적화도 열심히 해보셨으면 좋겠다...!! 예를 들면,
- 피벗 기준으로 값을 보내거나 뒤로 돌릴 때, 이미 보내야 할 값들이 다 보내졌다면 더이상 돌리지 않도록 최적화하면 더 명령어 개수를 줄일 수 있을 것 같다.
- 피벗 기준으로 값을 다 보내고 뒤로 돌린 원소들을 다시 앞으로 가져올 때, 아래에 고정되어 있는 원소들이 없다면 굳이 앞으로 가져오는 명령어를 쓰지 않게 하면 더 줄일 수 있을 것 같다.
이런 식으로 많은 생각들을 해보시면서 자신만의 push_swap을 멋지게 만들어 보셨으면 좋겠다!
모든 42서울 카뎃 화이팅 💪🏻💪🏻
