Title: A Simple Framework for Contrastive Learning of Visual Representations
Journal: 2020 ICML
Github: https://github.com/google-research/simclr
Abstract
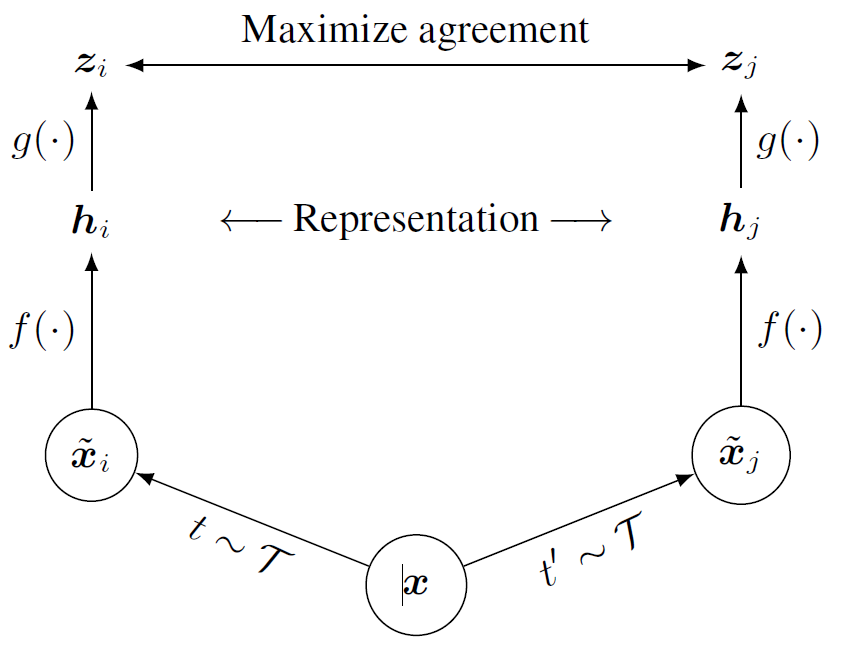
Visual representation을 학습하는 contrastive learning 기법이며, 특별한 구조나 메모리 뱅크를 필요로 하지 않는 단순한 프레임워크다. SimCLR의 특징은 다음과 같다:
- 여러 data augmentation의 조합이 pretext task의 효과에 매우 큰 영향을 미친다.
- Representations와 contrastive loss 사이에 learnable nonlinear trasnformation은 학습되는 feature들의 퀄리티를 높인다.
- Contrastive learning은 큰 배치사이즈와 training step이 있어야 높은 퍼포먼스를 기대할 수 있다.
1. Introduction
Discriminative learning은 supervised learning과 비슷한 objective function을 가지고 representations를 학습한다. 프레임워크의 주요 요소는 다음과 같다:
- 여러 data augmentation의 조합은 효과적인 representation들을 학습하기 위한 task를 정의하는데 매우 중요하다. 그리고 강한 data augmentation을 가할수록 더 성능이 높다.
- Representation과 contrastive loss 간 learnable nonlinear trasnformation은 학습되는 representations의 퀄리티를 높인다.
- Contrastive CE loss를 사용한다면 normalized embeddings와 temperature 파라미터 조정이 효과적이다.
- 큰 배치사이즈와 긴 학습시간을 줄수록 성능이 좋고, 지도학습처럼 깊고 넓은 네트워크를 사용할 수록 성능이 좋다.
2. Method
Contrastive Learning Framework
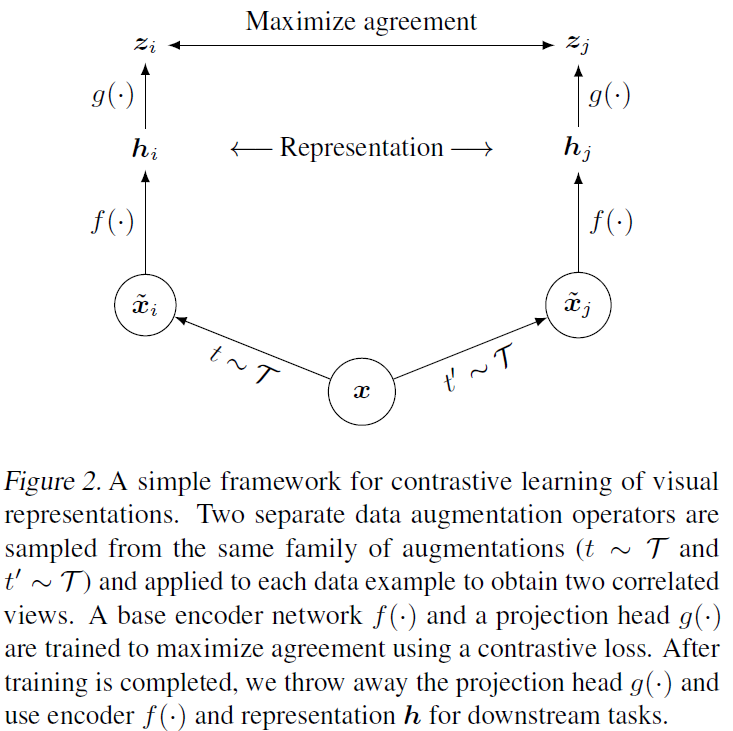
프레임워크는 4가지 주요 구성 요소로 이루어진다:
- Stochastic data augmentation 모듈 - 하나의 입력 이미지에 대해 두 개의 서로 다른 view를 생성한다. 논문에서는 3가지 간단한 augmentation이 사용되었다: random crop, random color distortion, random Gaussian blur.
- Base encoder f(.) - Augment된 이미지들로부터 representation 벡터를 추출하는 뉴럴 네트워크다. 네트워크의 구조에 구애받지 않으며, 논문에서는 ResNet을 사용했다.
- Projection head g(.) - Contrastive loss가 있는 공간으로 매핑을 해주는 작은 뉴럴 네트워크다. 논문에서는 단일 hidden 레이어로 된 MLP를 사용했다. Base encoder 출력(h)보다 projection head 출력(z)에서 contrastive loss를 계산하는 것이 더 좋은 성능을 낸다.
- Contrastive loss function - Contrastive prediction task에서 사용된다.

N개의 샘플을 무작위로 샘플링하고 prediction task를 위해 augmentation을 해서 2N개의 샘플이 탄생하며 2개씩 이루어진 한 쌍의 positive pair를 구성한다. Negative sample은 전체에서 positive pair 한 쌍을 뺀 나머지인 2(N-1)개다. 샘플 간 유사성은 cosine similarity를 이용해 측정한다. → Normalized Temperature-scaled cross entropy loss (NT-Xent)
Large Batch Size
간단한 모델 구조를 유지하기 위해서 메모리 뱅크는 사용하지 않는 대신, 학습 시 배치사이즈 N을 매우 크게 잡았다 (256 ~ 8192). 예를 들어, 배치사이즈 N=8192면 → negative sample 16,382개가 각각의 positive pair마다 생긴다. 옵티마이저가 SGD/Momentum + linear lr scaling인 경우 큰 배치사이즈로 학습하면 결과가 불안정하다. 그래서 논문은 모든 배치사이즈에 대해 LARS 옵티마이저를 사용했다.
Evaluation Protocol
학습한 representation들을 평가하기 위해서는 보편적으로 사용되는 linear evaluation protocol을 따랐다. Base network는 frozen 시키고 linear classifier를 얹어서 학습시킨다. Linear evaluation 외에도 SOTA semi-supervised, transfer learning과도 비교했다. Data augmentation으로는 random crop, random resize, random flip, color distortion, Gaussian blur를 사용했다. Base encoder로는 ResNet-50, projection head로는 2-layer MLP를 썼다.
| loss | optimizer | learning rate | batch size | epochs | linear warmup | scheduler |
|---|---|---|---|---|---|---|
| NT-Xent | LARS | 4.8 (= 0:3 BatchSize=256) | 4096 | 100 | first 10 epochs | cosine decay schedule without restarts |
3. Data Augmentation
옛날에는 data augmentation보다는 모델 구조 자체를 바꿔서 global-to-local view prediction 같은 pretext task를 정의했다. 그리고 현재는 간단한 random crop + resize 만으로도 이런 복잡한 task 정의를 대체할 수 있다. 즉, data augmentation이 predictive task를 정의한다.
Composition of data augmentation
Augmentation 종류:
- Spatial/geometric transformation → cropping, resizing + horizontal flip, rotation, cutout.
- Appearance transformation → color distortion (color dropping, brightness, contrast, saturation, hue), Gaussian blur, Sobel filtering.
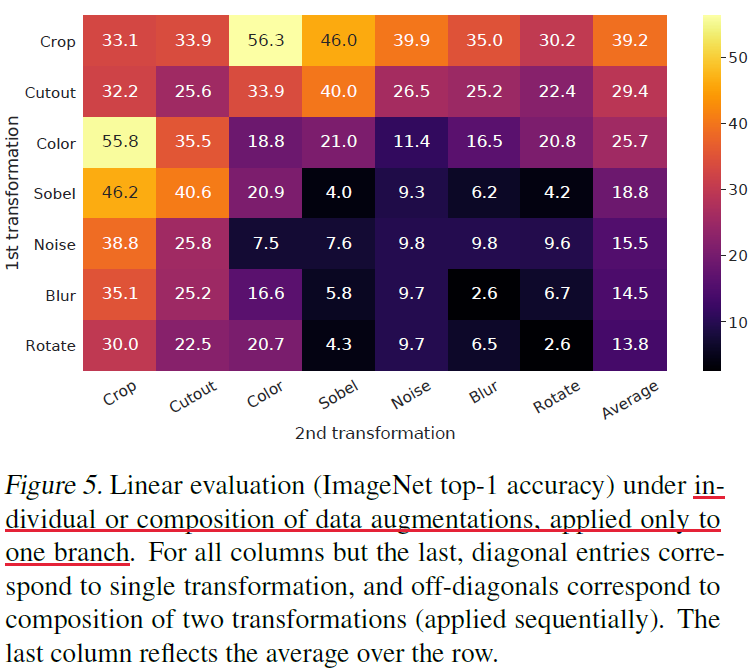
데이터 내 이미지들이 서로 다른 사이즈를 가지고 있어서 모두 필히 crop과 resize를 적용해야만 했다. 먼저 입력 이미지에 대해 무작위로 crop후 resize하고, 위 그림에서처럼 하나의 branch에만 타겟하는 transformation을 적용한다. 이때 나머지 하나의 branch는 idenetity로 둔다. 이렇게 하는걸 asymmetric augmentation이라고 한다.
Augmentation composition의 중요성을 알아보기 위해 augmentation을 단일로 적용했을 때와 pair로 적용했을 때의 프레임워크 퍼포먼스 차이를 실험했다. 그 결과 single보다는 composition했을 때가 더 좋은 representation을 학습했다. Composition하면 contrastive prediction task는 어려워지지만 그 대신 학습하는 representation의 퀄리티가 매우 향상됐다. 가장 좋은 조합은 random crop과 random color distortion 이었다. 즉, 좋은 representation을 학습하기 위해선 data augmentation composition이 매우 중요하다.
Stronger data augmentation
Color augmentation에 대해 더 이야기해보자면, 지도학습과 비교해봤을 때 강도를 높일수록 SimCLR은 정확도가 올랐고, 지도학습은 정확도가 내려갔다. 그리고 둘 다에 AutoAugment를 적용해봤더니 단순하게 crop하고 강력한 color distortion을 줬던 SimCLR이 AutoAugment를 적용한 SimCLR보다 더 좋았고, 지도학습에는 AutoAugment가 효과적이었다. 이를 통해 contrastive learning에는 강력한 data augmentation이 효과적임을 확인했다. 더하여 지도학습에서는 별다른 성능 향상이 없던 augmentation 일지라도 contrastive learning에서는 효과적일 수 있음도 알았다. 즉, contrastive learning에서는 지도학습과 비교했을 때 더 강력한 data augmentation이 필요하다.
4. Architectures for Encoder and Head
Bigger models
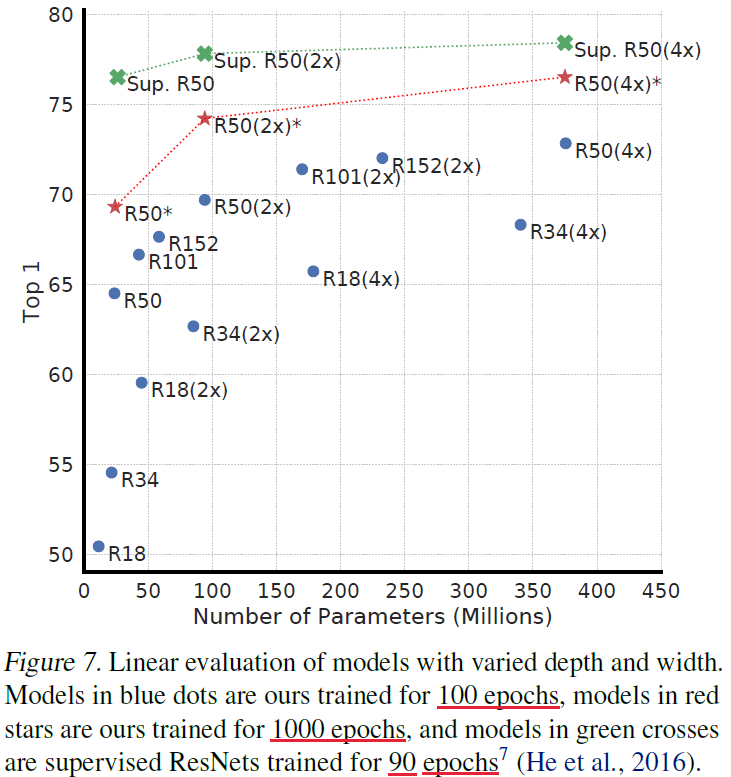
비지도학습의 정확도를 지도학습과 비교해봤을 때 당연히 지도학습의 정확도가 더 높았지만, 모델 사이즈를 키울수록 그 둘의 성능 차이 간격이 좁아짐을 확인했다. 둘 다 모델이 커지면 당연히 퍼포먼스가 올라가지만, 비지도 학습이 성능 향상의 정도가 더 크다는 걸 알 수 있다. 즉, contrastive learning은 큰 모델일수록 효과적이다.
Nonlinear projection head
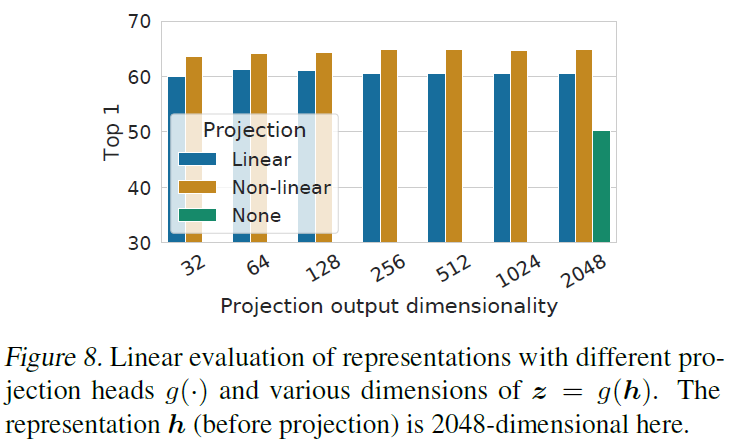
Projection head의 중요성을 알아보기 위해 서로 다른 3가지의 head 구조마다의 퍼포먼스를 비교했다. 1) Identity mapping, 2) Linear projection, 3) Nonlinear projection (with 1 hidden layer). 결과는 Nonlinear projection > Linear projection > No projection 이었고, head가 사용되기만 했다면 출력 차원이 몇이든 상관없이 비슷한 결과를 보였다. 그리고 projection head 기준으로 이전 레이어인 h가 이후 레이어인 z보다 더 좋은 representation이었다 → h > z. 즉, projection head 이전에 있는 hidden layer에서 더 좋은 representation이 나온다. Nonlinear projection head 이전에 있는 representation을 사용하는게 더 좋은 이유는 → contrastive loss로 인한 정보 손실 때문이라고 보고 있다.
x는 transform된 입력 이미지고 base encoder f(.)와 projection head g(.)가 있을 때:
- Base encoder 출력 h = f(x), → nonlinear transformation g(.)를 적용하면 h에 더 많은 정보가 학습된다.
- Projection head 출력 z = g(h) → 데이터 transform에도 invariant 하도록 학습하기 때문에 projection head가 downstream task에 유용한 정보를 제거할 수도 있다.
즉, nonlinear projection head 이전 레이어가 representation의 퀄리티를 향상시킨다.
5. Loss Functions and Batch Size
Normalized CE Loss and Temperature parameter
논문에서 사용한 NT-Xent를 다른 보편적인 contrastive loss인 logistic loss, margin loss와 비교했다 ⇒ NT-Xent, NT-Logistic, Margin Triplet. 각 loss는 positive sample과 negative sample들에 대해 각기 다른 가중치를 부여하는 함수이다. 이로부터 알 수 있는 것은:
- L2 normalization (i.e. cosine similarity) + temperature 파라미터 조정은 서로 다른 샘플에 효율적으로 가중치를 부여한다. 그리고 적절하게 temperature 파라미터를 조정했을 때 모델이 hard negative를 더 잘 학습할 수 있게 된다.
- CE loss와 다르게 상대적인 hardness로 negative들에 가중치를 주지 않기 때문에 semi-hard negative mining이 적용되어야한다.
Larger batch sizes & Longer training
학습 에폭이 적을수록 (예를 들어 100에폭) 큰 배치사이즈가 훨씬 더 효과적이다. 그러나 에폭이 커질수록 큰 배치사이즈와 작은 배치사이즈 사이의 성능 차이는 확연히 줄어든다. Contrastive learning에서는 배치사이즈가 클수록 negative sample 수가 많아지고, 더 잘 수렴하도록 촉진한다. 긴 학습시간 역시 negative sample 수가 많아지게 한다.
