
Convolutional Neural Networks
Convolution
-
기존의 Convolution은 신호처리에서 두 개의 함수가 있을 때(f, g), 이들을 섞어주는 연산자로써 사용되었음)
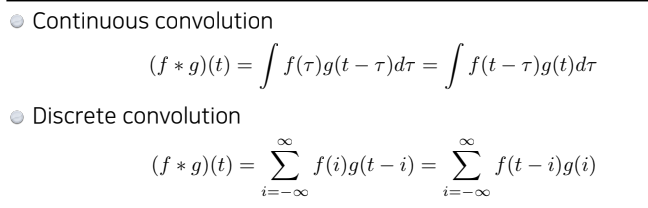
-
2D 이미지 Convolution
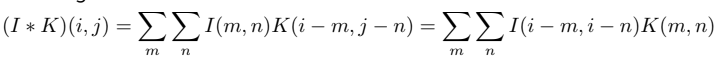
= 전체 이미지 공간
= 컨볼루션 필터 -
기본적인 Convolution 작동 방식
- K(3x3 filter)를 I(7x7 image)에 적용하면(찍으면), K, I값들이 곱해지고 더해져서 해당 위치의 출력으로 나온다.
- 이를 반복하면 output(5x5)가 나오는 것을 알 수 있다.
-
이때 적용하는 필터에 따라, 같은 이미지에 적용하더라도 다른 결과를 가져오게 됨
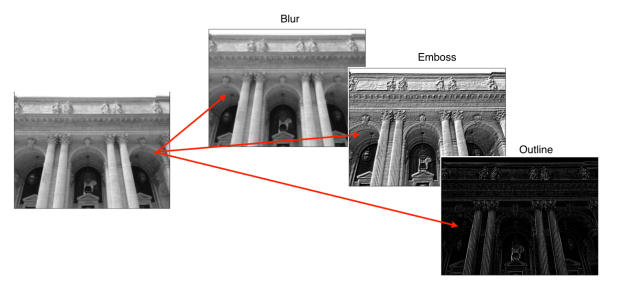
예를 들어, (3x3) 필터를 적용할 때 모든 필터 값에 이 들어가 있다고 한다면, 이미지가 어떤 특정 영역만큼의 픽셀 값들을 합쳐서 평균을 내기 때문에 마치 Blur된 것 같은 효과가 나게 됨.
RGB Image Convolution
-
채널이 3개 있는 RGB 이미지(32x32x3)를 5x5 filter로 Convolution한다고 하면, fileter의 채널은 3이 됨(filter의 채널과 image의 채널은 같음).
-
이때, output은 28x28x1이 됨.
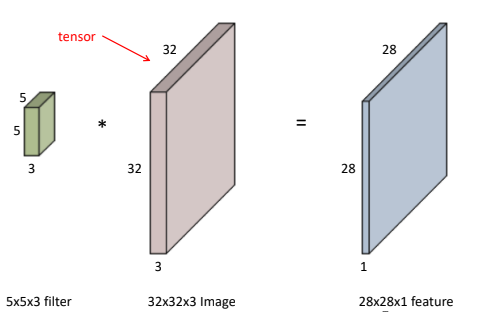
-
만약 filter가 여러층 있다면, output(Convolution feature map)의 채널도 그만큼 늘어나게 됨
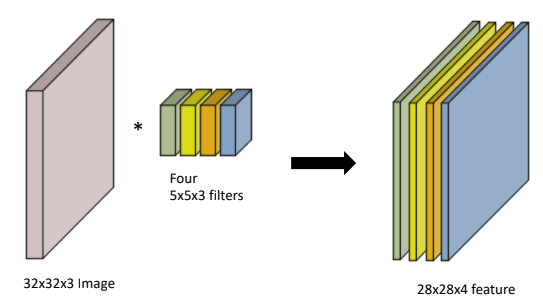
Stack of Convolutions
- Convolution을 여러 번 할 땐, MLP와 같이 activation function을 사용하여 nonlinear transform을 해주어야 함.
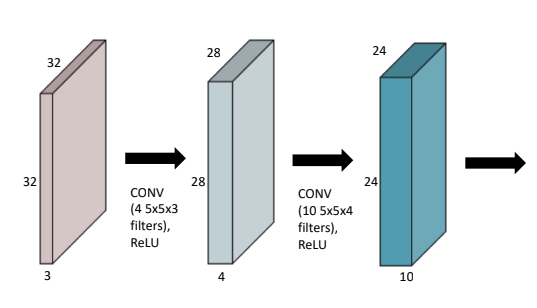
- convolution에서 feature map을 얻기 위한 파라미터의 수를 잘 생각해야 함.(parameter가 많아지면, 그만큼 많음 컴퓨터 자원을 사용케 하며, overfitting이 될 수 있음)
- parameter 개수: 컨볼루션 사이즈(n*m) * input 채널 수 * output 채널 수
- 위 그림에선 (5x5x3x4) + (5x5x4x10) 개가 사용됨
Convolution Neural Networks
- CNN은 convolution layer, pololing layer, fully connected layer로 이루어져 있음
- convolution and pooling layers: 이미지에서 유용한 정보를 추출
- fully connected layer: decision making(분류 등)

- pooling layers: overfitting을 방지하기 위해, feature map의 차원을 축소시키는 과정(max pooling, mean pooling, ...)
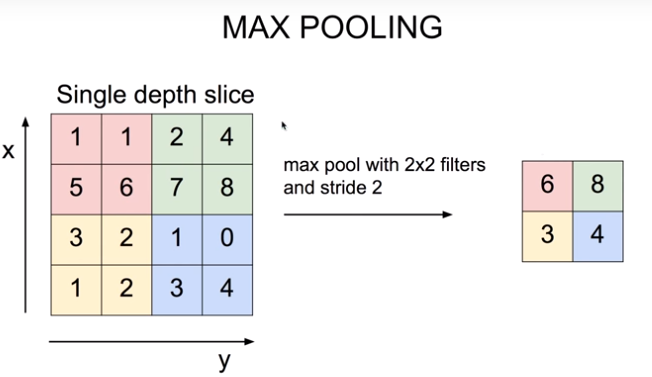
- pooling layers: overfitting을 방지하기 위해, feature map의 차원을 축소시키는 과정(max pooling, mean pooling, ...)
Stride
- stride: filter를 찍고 다음 위치로 옮길 때의 이동 거리
- 차원이 늘어나면, stride의 인자의 수도 늘어남
- 2차원: 1 x 1 stride, 2 x 2 stride
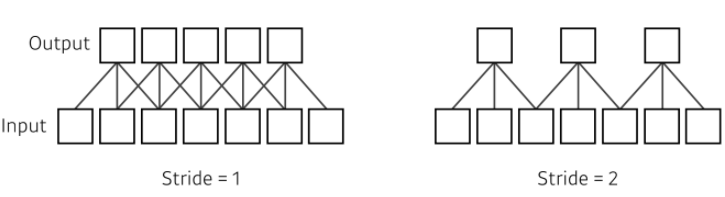
- 2차원: 1 x 1 stride, 2 x 2 stride
Padding
- padding: 커널 크기에 따라 가장자리 정보가 버려지는 문제를 해결하기 위한 것
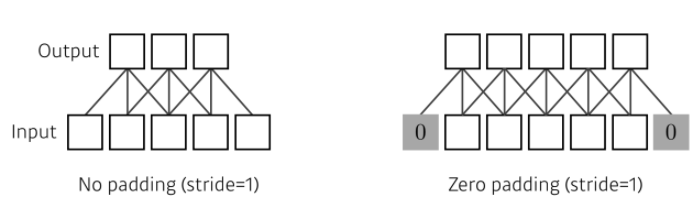
- 어떠한 컨볼루션 필터가 같이 이루어져있을 때, 적절한 크기의 padding과 stride가 들어가면, 입력과 convolution operator의 출력으로 나오는 convolution feature map의 spatial dimension이 같아짐
(원하는 출력값에 맞춰 stride, padding을 조절할 수 있음)
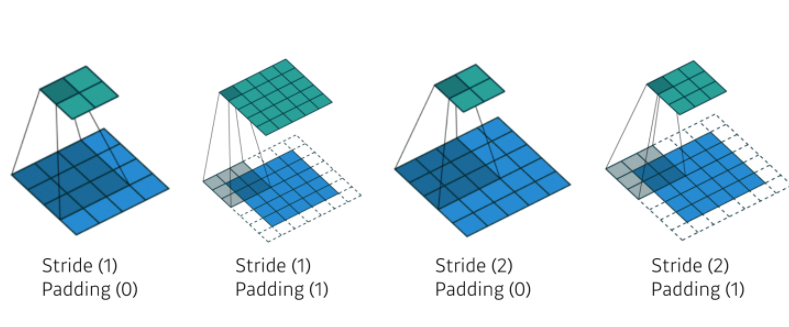
- 어떠한 컨볼루션 필터가 같이 이루어져있을 때, 적절한 크기의 padding과 stride가 들어가면, 입력과 convolution operator의 출력으로 나오는 convolution feature map의 spatial dimension이 같아짐
Convolution Arithmetic
- Padding(1), Stride(1), 3x3 kernel일 때, 해당 모델의 파라미터 개수는?

3 x 3 x 128 x 64 = 73,728
Convolution Arithmetic in AlexNet
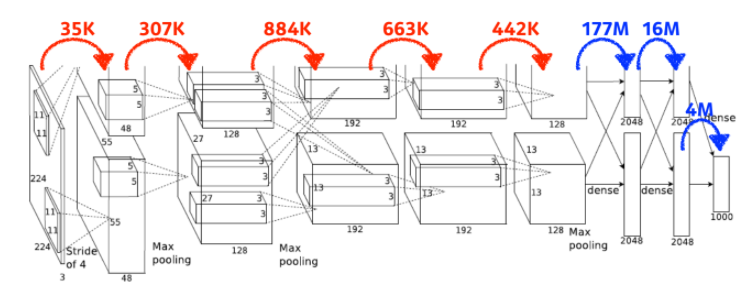
- convolution layer
- 11 x 11 x 3 x 48 * 2 (2개로 나눔) = 35k
- 5 x 5 x 48 x 128 * 2 = 307k
- 3 x 3 x 128 *2 x 129 * 2 = 884k
- 3 x 3 x 192 x 192 * 2 = 663k
- 3 x 3 x 192 x 128 * 2 = 442k
- dense layer(MLP) -> 기하급수적으로 파라미터 수가 늘어남
- 13 * 13 * 128 * 2 * 2048 * 2 = 177M
- 2048 * 2 * 2048 * 2 = 16M
- 2048 * 2 * 1000 = 4M
파라미터 개수를 줄이기 위한 방법
1. 최근에는 뒷단의 FC를 줄이고, 앞단의 CL을 깊게 쌓는 것이 트렌드임
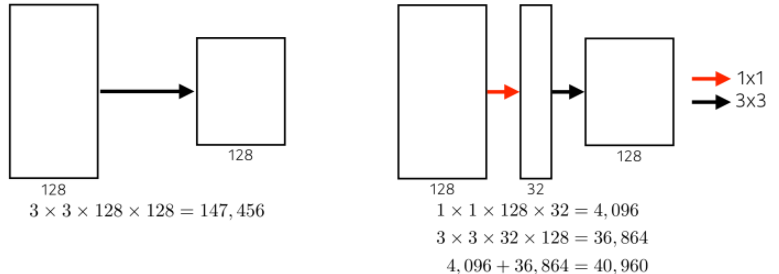
2. 1x1 Convolution
- 1x1 Convolution을 추가로 넣어서 파라미터 수를 감소시키는 것(채널 방향으로 차원을 줄이는 효과가 있음)
- 일반적으로 행과 열의 사이즈를 줄이고 싶다면 Pooling을 사용하면 되지만, 채널의 수를 줄이고 싶다면 1x1 Convolution을 사용.
Modern Convolutional Neural Networks
ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)
- 이미지 인식 경진대회
- 대용량의 이미지셋을 주고 이미지 분류 알고리즘의 성능을 평가하는 대회
- 이 대회에서 우승한 알고리즘들은 컴퓨터 비전 분야 발전에 큰 역할을 했으며, 주요 알고리즘이 됨
- 해가 지날수록 알고리즘들은 네트워크의 깊이(depth)가 점점 깊어지고, 파라미터 개수는 점점 줄어들고, 성능은 점점 상승하는 추세를 보임
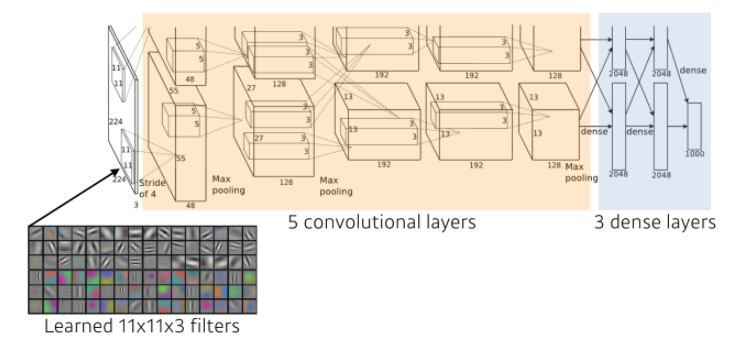
AlexNet
- Rectified Linear Unit(ReLU) Activation
- Relu Activation
- 그레디언트가 0보다 많이 커도, 이를 보존함
- 최적화에 용이
- 일반화 성능이 좋음
- 기울기 소실 문제를 극복함(네트워크를 깊게 쌓을 수 있음)
- Relu Activation
- GPU implementation(2GPUs)
- 당시 2개의 GPU로 병렬연산을 수행함(GPU parallelization)
- Overlapping pooling
- pooling을 overlapping 하여 사용함
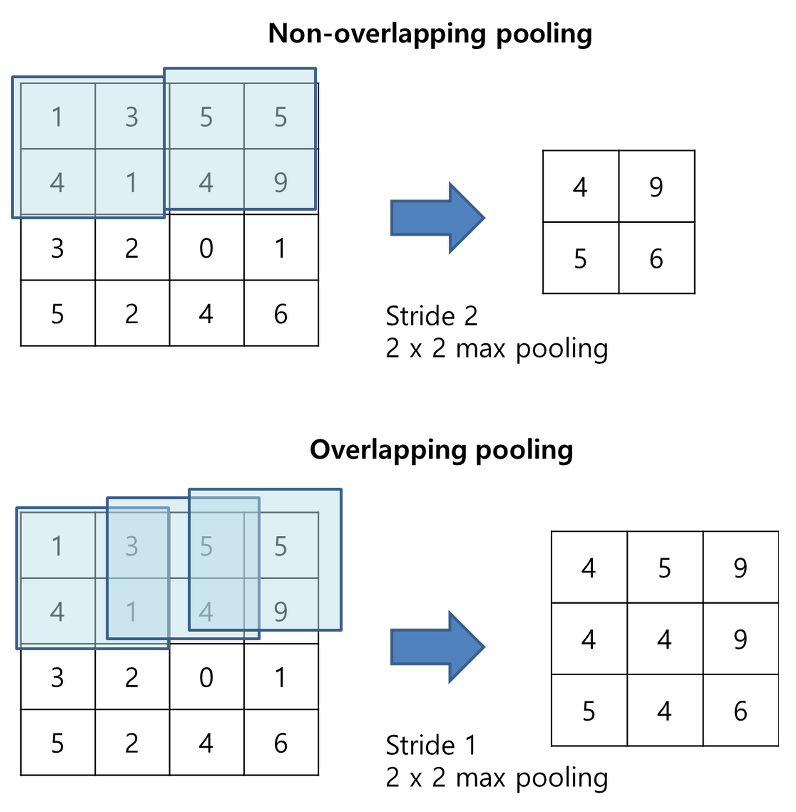
- pooling을 overlapping 하여 사용함
- Local response normalization
- ReLU는 양수값을 받으면 그 값을 그대로 뉴런에 전달하기 때문에 너무 큰 값이 전달되어 주변의 낮은 값이 뉴런에 전달되는 것을 막을 수 있음
- 이것을 예방하기 위한 normalization이 LRN
- Data Augmentation
- Dropout
AlexNet은 현재 사용하는 많은 알고리즘의 기준이 되었음
VGGNet
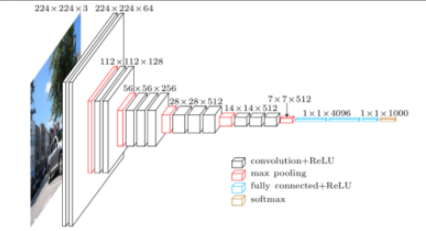
- Increasing depth with 3 x 3 convolution filters (with stride 1)
- 필터는 3x3으로, stride는 1로 고정
- Dropout (p=0.5)
- VGG16(layer 16개), VGG19(layer 19개)
왜 3x3 필터를 사용했을까 ?
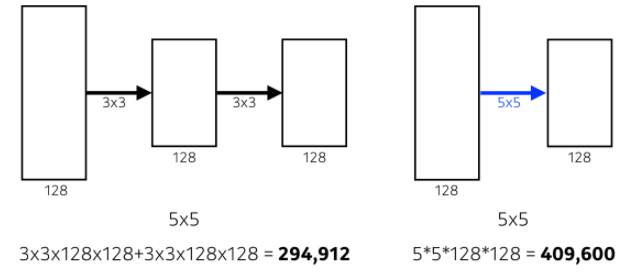
- Receptive field: filter가 한 곳을 찍었을 때 고려되는 input의 크기(spatial dimension)
- 위 그림에서 알 수 있듯이, 3x3 필터를 두 번 사용하는 것과 5x5를 한 번 사용하는 것의 Receptive field는 같음
- 따라서 3x3 필터를 깊게 쌓는 것이 파라미터 개수에 훨씬 유리
GoogLeNet
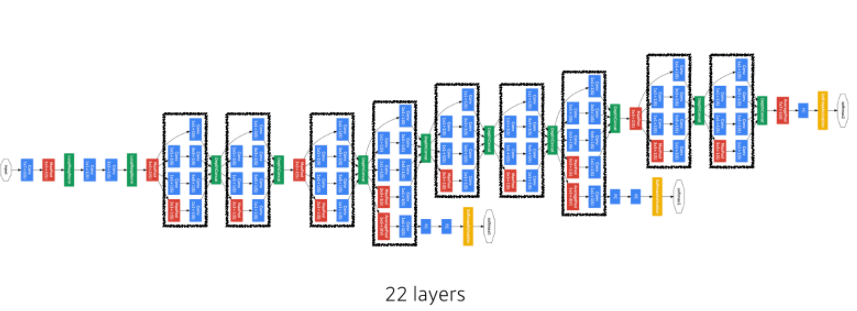
- NiN(Network in Network)구조: 비슷한 Network가 여러번 반복되는 구조
- Inception blocks
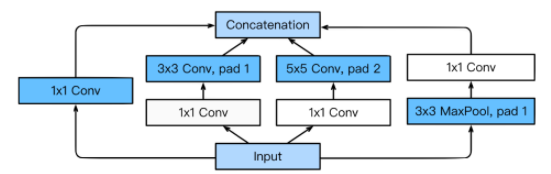
- 입력이 여러개로 퍼졌다가 다시 합쳐지는 형태
- 1x1 Convolution을 사용하여 parameter 개수를 줄임
- 1x1 Convolution을 추가로 넣어서 파라미터 수를 감소시키는 것(채널 방향으로 차원을 줄이는 효과가 있음)
- 일반적으로 행과 열의 사이즈를 줄이고 싶다면 Pooling을 사용하면 되지만, 채널의 수를 줄이고 싶다면 1x1 Convolution을 사용.
지금까지 배운 모델들의 layer수와 파라미터 수
- AlexNet(8-layers) / num of param: 60m
- VGGNet(19-layers) / num of param: 110m
- GoogLeNet(22-layers) / num of param: 4m
ResNet
기울기 소실/폭발
- 신경망이 깊어질수록, 뒷단에 있는 layer의 활성화 함수의 미분값은 점점 작아지거나 혹은 커지는 경우가 있다.
- 작은 미분값이 여러번 곱해지면 0에 가까워지게 되고, 이를 '기울기 소실'이라고 한다.
- 큰 미분값이 여러번 곱해지면 값이 매우 커지게 되고, 이를 '기울기 폭발'이라고 한다.
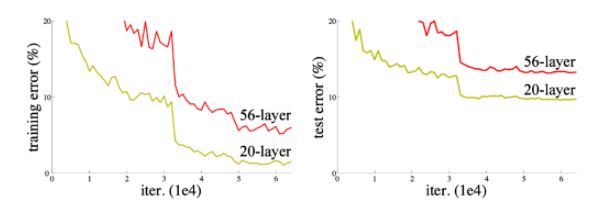
어느 순간부터 학습이 되지 않음을 볼 수 있다.
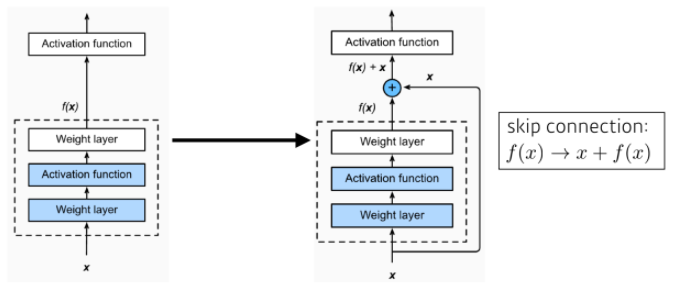
Skip(Shortcut) Connection in ResNet
- ResNet에서는 학습이 안 되는 문제와 기울기 소실/폭발 문제를 막기 위해, 입력 x를Layer 이후의 출력값에 더해주게 된다.
- 기존 신경망은 가 되도록 학습을 했지만, skip connection을 사용하는 ResNet에선 가 된다.
- 는 가 되고, 이를 해석해보면 f(x)를 학습하는 건 잔차(Residual)를 학습한다고 볼 수 있다.
DenseNet
- ResNet은 Skip Connection을 통해 기울시 소실/폭발 문제와 학습이 ㅈ잘 안 되는 문제를 해결하였다. 하지만 '덧셈'으로 결합되기 때문에 신경망에서 정보흐름(information flow)이 지연될 수 있따.
- DenseNet은 더하기가 아닌 concatenation으로 이를 해결한다(정보흐름 향상)

- 문제는 이렇게 Dense Block을 지날 때마다 Concat이 되며 채널의 수가 기하급수적으로 늘어난다는 것이다.
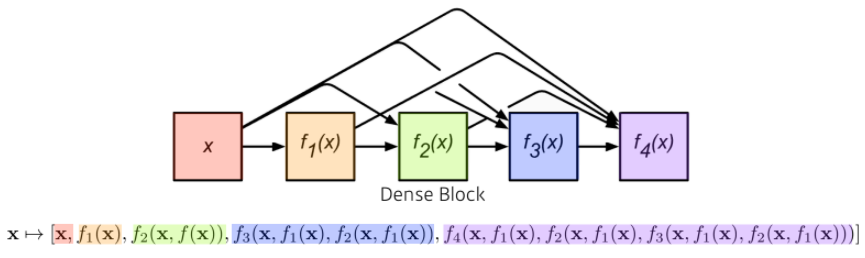
- DenseNet에서는 이를 'Transition Block'으로 차원을 축소시켜 해결한다.
- Transition Block: BatchNorm -> 1x1 Conv -> 2x2 AvgPooling

- Transition Block: BatchNorm -> 1x1 Conv -> 2x2 AvgPooling

AI Engineer : Lv 0