Gradient Descent
- 경사 하강법은 머신러닝 및 딥러닝 알고리즘을 학습시킬때 사용하는 방법 중 하나이며, 1차 근삿값 발견용 최적화 알고리즘이다. 기본 개념은 함수의 기울기(경사)를 구하여 기울기가 낮은 쪽으로 계속 이동시켜 극값(최적값)에 이를 때까지 반복하는 것이다.
- 경사하강법(순한맛, 매운맛)
Important Concepts in Optimization
- Generalization
- Under-fitting & Over-fitting
- Cross validation
- Bias-variance trade off
- Bootstrapping
- Bagging and boosting
Generalization
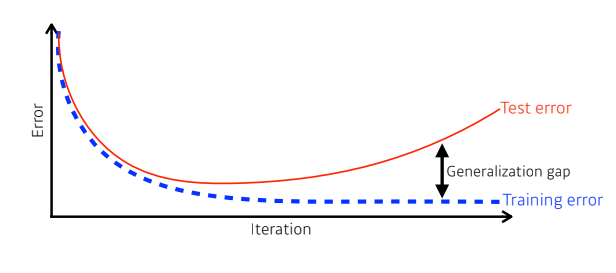
- 일반화 성능이란 Training error와 Test error간 차이에 대해 이야기한다.
- 차이가 작을수록 일반화 성능이 좋다고 말함.
- (Training error와 상관없이 Test error가 낮게 낮다고 해서 일반화 성능이 안 좋다고 할 수는 없음)
Under-fitting & Over-fitting
- 과소적합: 모형이 너무 단순한 것
- 과대적합: 모형이 데이터의 패턴을 너무 과도하게 반영한 것
- 훈련 데이터에 대한 성능은 좋지만, 새로운 데이터에서의 일반화 성능이 나빠질 수 있음
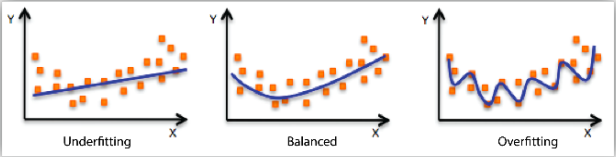
- 훈련 데이터에 대한 성능은 좋지만, 새로운 데이터에서의 일반화 성능이 나빠질 수 있음
Cross Validation
- 교차검증(CV: Cross Validation)
- 데이터가 충분치 않아 검증용 데이터를 따로 할당하기 어려운 경우 사용
- 훈련 데이터를 여러 번 반복해서 나누고 여러 모델을 학습하고 평가하는 방법
- 대표적인 방법: k-fold CV
- 전체 데이터를 k등분하여 K-1개 그룹은 훈련용으로, 나머지 한 그룹은 검증용으로 사용하는 과정을 반복하여 평균을 구함
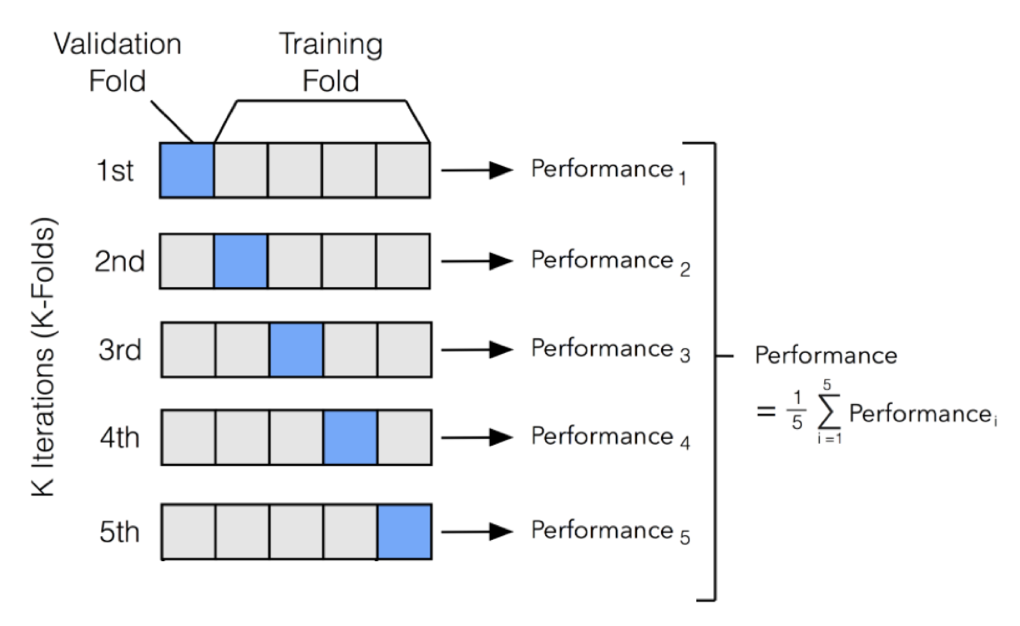
- 전체 데이터를 k등분하여 K-1개 그룹은 훈련용으로, 나머지 한 그룹은 검증용으로 사용하는 과정을 반복하여 평균을 구함
Bias-variance trade off
- Bias: 평균적으로 봤을 때, 주요 타겟에 근접해있는가?
- Variance: 출력이 얼마나 일괄되게 나오는가?
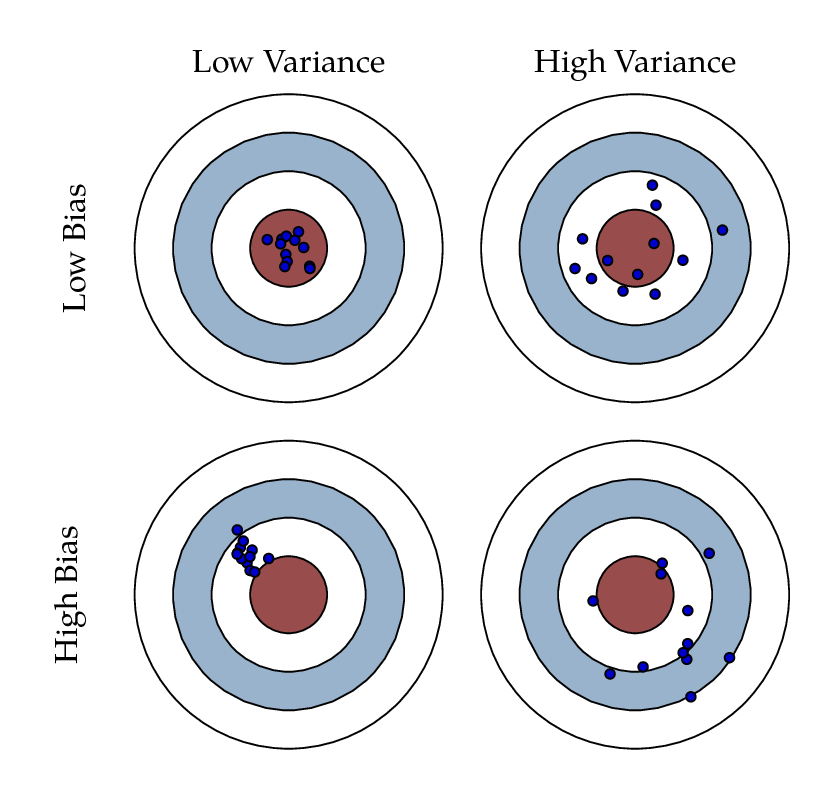
- bias와 variance는 동시에 줄일 수 없음(trade-off 관계)

- bias와 variance는 동시에 줄일 수 없음(trade-off 관계)
Bootstrapping
- 무작위 샘플링을 사용하는 여러 모델을 만들어서 무언가 하겠다는 것
- 학습 데이터가 고정되어 있을 때, 그 안에서 샘플링을 통해 학습 데이터를 여러 개 만들고, 이를 통해 모델, metrics를 만드는 것
- 모델의 전체적인 불확실성(uncertainty)를 예측함
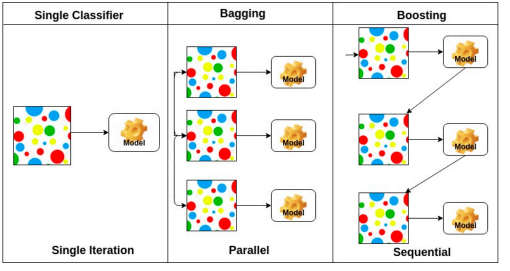
Bagging and boosting
- Bagging(Bootstrapping aggregating)( boostrapping)( 앙상블)
- 학습데이터를 여러 개 만들고, 독립적인 모델들을 여러 개 만들어 output을 내고, 그것들의 평균을 구하는 것
- Boosting
- 여러 개의 week learner를 합쳐, strong model을 만드는 것
- 앞선 week learner의 실수로부터 배움(sequence 형태)
Practical Gradient Descent Methods
경사하강법을 적용하는 방법
- Stochastic gradient descent
- a single sample
- Mini-batch gradient descent
- a subset of data
- 많이 사용됨
- Batch gradient descent
- whole data
- gpu 과부화가 일어날 수 있음
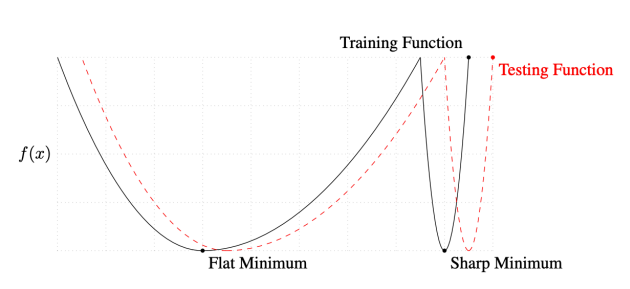
Batch-size Matters
- batch size는 중요한 하이퍼파라미터 중 하나임
- 큰 batch size -> sharp minimum
- 작은 batch size -> flat minimum(일반화 성능이 더 좋음(실험적 결과))
Gradient Descent Methods
.png)
https://www.slideshare.net/yongho/ss-79607172?from_action=save
Regularization
- 규제: 학습을 방해하여 Generalization 성능을 높일 수 있도록 해주는 역할
- 규제를 위한 도구들
- Early stopping
- Parameter norm penalty
- Data augmentation
- Noise robustness
- Label smoothing
- Dropout
- Batch normalization
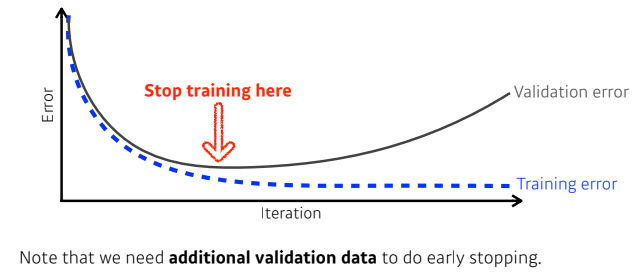
Early Stopping
- validation error가 커지기 시작할 때(일반화 성능이 나빠지기 시작할 때) 학습을 의도적으로 멈춤
Parameter norm penalty
- 파라미터가 너무 커지지 않도록 하는 것
- 파라미터가 작을수록 성능도 좋고 효율도 좋을 것이라고 가정함
- 파라미터를 제곱하여 더한 값을 cost function에 추가하여 같이 줄임(부드러운 함수로 만듦)

Data Augmentation
- 데이터는 많을수록 좋음
- 딥러닝보다 다른 AI방법론(ML 등)들의 성능이 더 좋을 때도 많음
- 하지만 데이터가 많아질수록, 기존 ML 방법론들은 많은 수의 데이터를 표현할 수 있는 표현력이 부족해짐
- 따라서 우리는 좋은 성능을 얻기 위해 어떻게든 데이터를 증강시키기 위한 방안을 고려해야 함
- 기존 데이터를 활용한 회전, 크기 증강/축소, 뒤집기 등등
- 기존 데이터를 활용한 회전, 크기 증강/축소, 뒤집기 등등
Noise Robustness
- Random noise를 input과 weight에 주면, test에서 더 좋은 결과를 얻는다는 것(실험적인 결과)

Label Smoothing
- 데이터들을 섞어 데이터를 증강시키는 것(비용 대비 성능향상이 괜찮다고 알려짐)
- Mix-up: 데이터 2개를 뽑아서 섞는 것

- CutMix: 데이터와 label을 둘 다 섞음

- Mix-up: 데이터 2개를 뽑아서 섞는 것
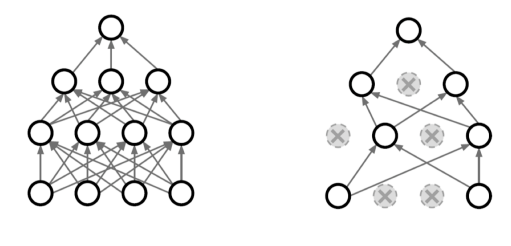
Dropout
- forward를 할 때, 정해진 비율만큼의 뉴런을 zero로 만드면 일반화 성능이 좋아진다는 것(실험적 결과)
Batch Normalization
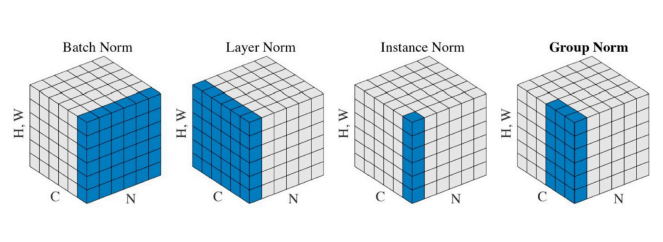
- Internal Covariate Shift: 학습 과정에서 계층 별로 입력의 데이터 분포가 달라지는 현상
- Batch 단위로 학습을 하게 되면 Batch 단위 간 데이터 분포의 차이가 발생할 수 있음
- 현재 layer의 입력은 모든 이전 layer의 파라미터의 변화에 영향을 받게되며, 층이 깊어짐에 따라 이전 layer에서의 작은 파라미터 변화가 증폭되어 뒷잔에 큰 영향(분포가 변하는 현상 등)을 끼치게 될 수 있음.
- Batch Normalization: Internal Covariate Shift를 피하기 위해 각 layer에 배치 정규화 과정을 통해 가중치의 차이를 완화하여 보다 안정적인 학습이 이루어지도록 하는 것
- hidden layer의 활성화함수 입력값(or 출력값) 상태인 배치(입력)의 평균과 분산을 계산
- 해당 배치를 평균 0, 표준편차 1이 되도록 정규화함(-1 ~ 1)
- 이후 배치 데이터들을 감마로 scale하고, 베타로 shitf하여 데이터를 다시 흩뿌려놓음
- 감마 베타는 learnable parameter임
- 감마, 베타는 활성화 함수(예를 들어 시그모이드)에서 대부분의 데이터(약 95%)가 가운데 지점에 몰리게 되어 비선형 함수가 의미 없어지는 것을 방지함
- (감마, 베타는 각각 1, 0에서 시작(표준정규분포와 비슷하게 시작)하기 떄문에 학습이 이뤄져도 그 근처로 업데이트될 것으로 기대)


AI Engineer : Lv 0