[boostcamp-ai-tech][DL-Basic] Computer Vision Applications(Semantic, Segmentation and Detection)
DL-Basic
목록 보기
4/6

Semantic Segmentation
- 이미지의 모든 픽셀이 어떤 라벨에 속하는가 ?
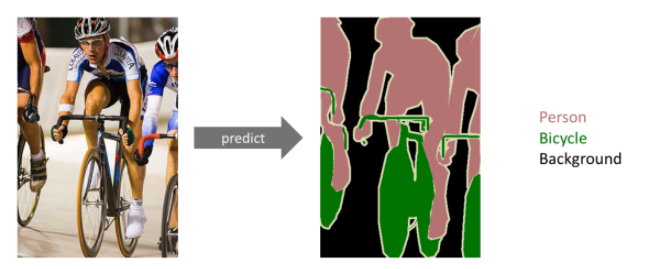
Fully Convolutional Network
-
기존 CNN 모델의 모양은 다음과 같다.
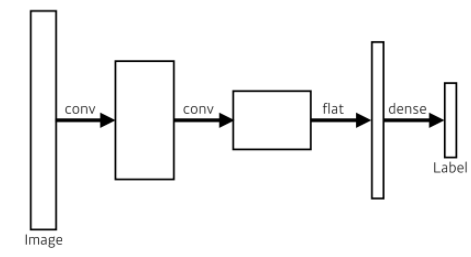
-
우리는 여기서 dense layer를 없애기 위해 Convolutionalization을 시킬 수 있다.
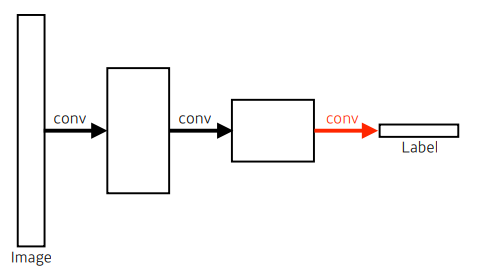
기존 CNN VS Fully Convolutional Network

- 파라미터 수
- left: 4x4x16x10 = 2,560
- right: 4x4x16x10 = 2,560(같음)
- 파라미터 수
-
Why Convolutionalization?
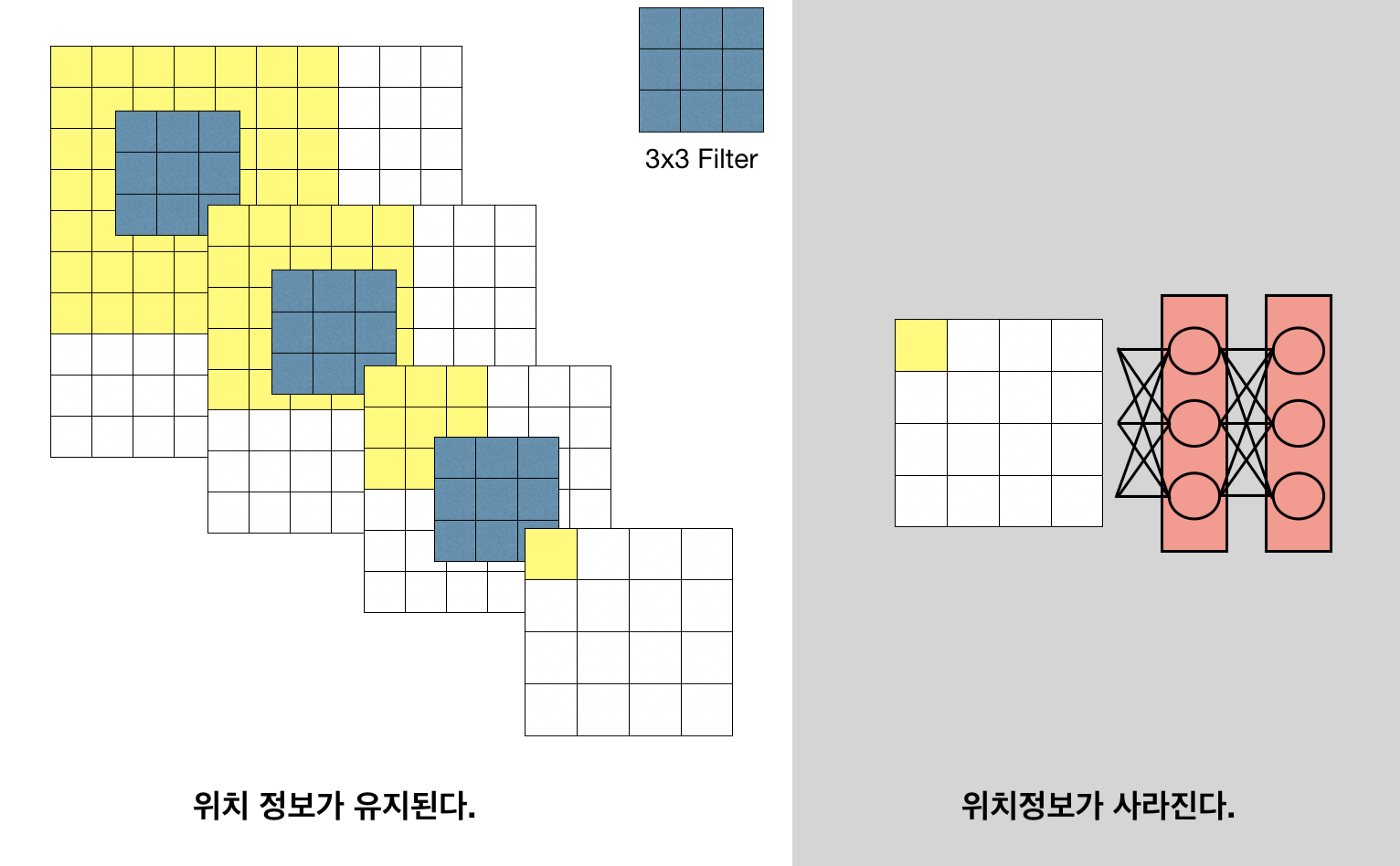
- Semantic Segmentation 관점에서 기존의 fc layer는 다음과 같은 한계점을 가지고 있다.
- 이미지의 위치 정보가 사라짐(전체 이미지를 분류하는 것이기 때문에 각 픽셀이 갖는 위치정보는 중요치 않음)
- 입력 이미지 크기가 고정됨
- Semantic Segmentation 관점에서 기존의 fc layer는 다음과 같은 한계점을 가지고 있다.
-
반면, FCN은
- input dimension(spatial dim)에 independent 함
- 공간 정보가 유지됨
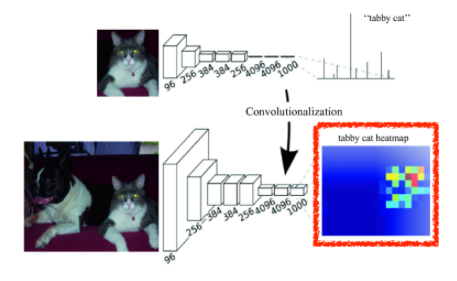
결과를 heatmap으로 그려보면, 공간 정보가 유지되고 있음을 알 수 있음.
-
FCN은 앞에서 이야기 했던 것처럼 input dimension에 independent 하나, Convolutional Layer를 거치면서 output의 dimension은 계속에서 줄어든다는 문제가 있다.
- 이를 해결하는 방법으로 upsampling이 있다.
Deconvolution(conv transpose)
- upsampling 방법 중 하나
- 컨볼루션의 역 연산으로, 줄어들었던 spatial dimension을 다시 늘리는 역할을 한다.
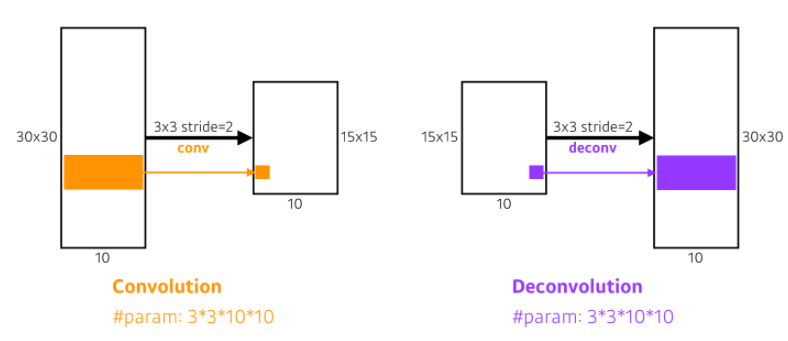
- 패딩을 많이주고 convolution 하는 것과 같음
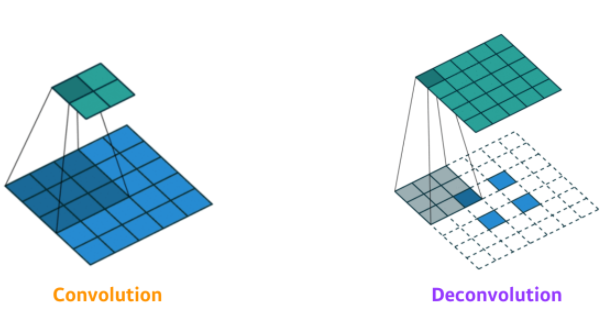
- 이를 해결하는 방법으로 upsampling이 있다.
Detection
- To find Bounding Box
- 이미지 안에 바운딩 박스를 찾고, 해당하는 바운딩 박스에 있는 물체가 어떤 것인지 분류하는 것
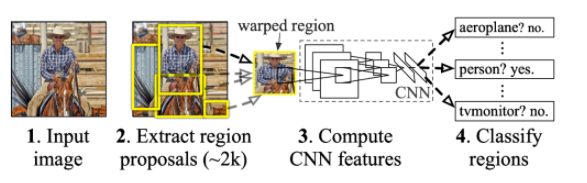
R-CNN
- 가장 기본적인 Detection
- 방법
- selective search를 사용하여 2,000개의 영역을 추출(후보 바운딩 박스)
- CNN에 들어가기 위해 이미지 크기를 같은 크기로 맞추고, AlexNet을 사용하여 features를 계산함
- SVM을 사용하여 분류
- 너무 BruteForce스럽다는 단점이 있다.(시간이 너무 오래걸림)
- CNN을 2,000번 돌리고
- 각 회차마다 분류도 해야 함
SPPNet
- R-CNN의 단점을 극복하기 위해 이미지 내에서 CNN을 한 번만 돌리는 방식
- CNN을 한 번 돌려서 얻어지는 Convolution feature map 위에서 Bounding Box들의 sub-tensor만 가져와서 사용
- 그러나 느린건 여전함
- CNN, SVM, bbox Regressor 모델들이 다 분리되어있어 따로 돌려야 하기 때문에 느림

- CNN, SVM, bbox Regressor 모델들이 다 분리되어있어 따로 돌려야 하기 때문에 느림
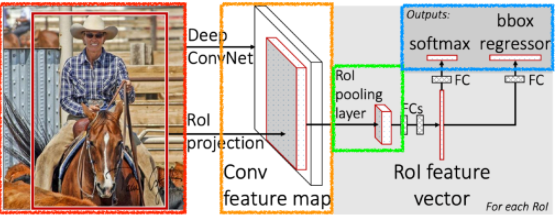
Fast R-CNN
- SPPNet과 비슷한 컨셉을 가짐
- SPPNet과 동일하게 CNN을 한 번 돌려서 Convolution feature map을 생성
- 각각의 region에 대해 일정한 크기의 feature 추출(RoI pooling)
- 각 RoI들을 FC에 통과시킨 후, softmax와 bbox Regressor에 통과시킴(NN)
Faster R-CNN
- RPN(Region Proposal Network) + Fast R-CNN
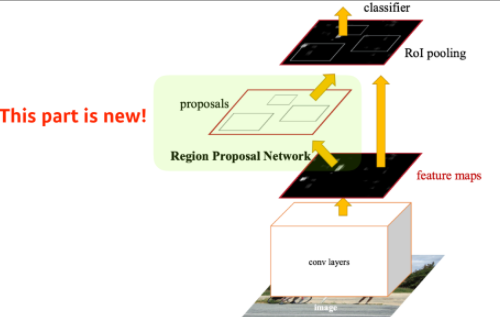
- RPN(Region Proposal Network)
- 특정영역(패치)가 bounding box로 사용가능한지 찾아줌(물체가 무엇인지는 찾지 않음)
- Anchor boxes가 필요함
- 이미지 안에 어떤 사이즈의 물체가 있을지를 알고, 이에 대한 형태를 k개의 anchor box로 미리 지정해두는 것
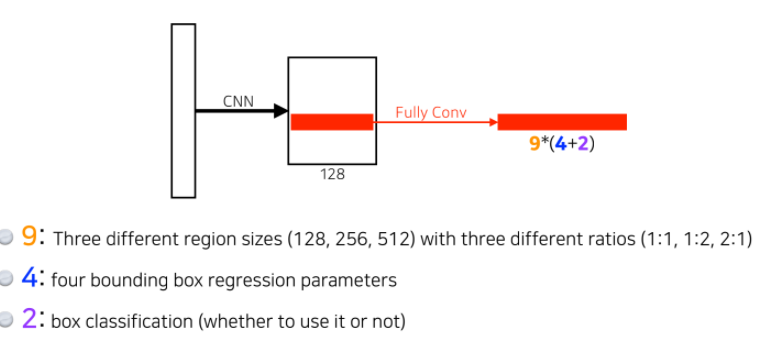
- 9개의 Anchor Boxes type 중 하나를 고름(3개의 사이즈 x 3개의 비율)
- 각 bounding box의 크기를 조정 (width, height, x_offset, y_offset)
- 사용 할 건지, 안 할 건지 분류(yes or no)(2개)
- 이미지 안에 어떤 사이즈의 물체가 있을지를 알고, 이에 대한 형태를 k개의 anchor box로 미리 지정해두는 것
- 이를 통해 작은 물체도 잘 분류(detection)할 수 있게 됨
YOLO
- Bounding box sampling을 따로 하지 않아(복잡한 pipeline이 없음) 속도가 매우 빠름
- 이미지 한 장에서 바로 찍어서 결과를 도출
- 방법
- 이미지를 SxS의 Grid로 나눔
- 객체의 중심이 Grid cell에 맞으면, 그 cell은 객체를 탐지했다고 표기
- 각 Grid cell은 B개의 바운딩 박스와 각 바운딩 박스에 대한 confidence score를 예측
- confidence score란 해당 바운딩 박스 내에 객체가 존재할 확률을 의미하며 0에서 1 사이의 값을 가짐

AI Engineer : Lv 0