
sequential Model
Naive sequence model
- 가장 기본적인 sequential model
- 이전의 입력값들을 고려하여 다음 데이터를 예측
- 한계: 이전 데이터를 가지고 다음 데이터를 예측할 때, 시간이 지날수록 고려해야 할 과거의 변수들이 계속 늘어나게 됨
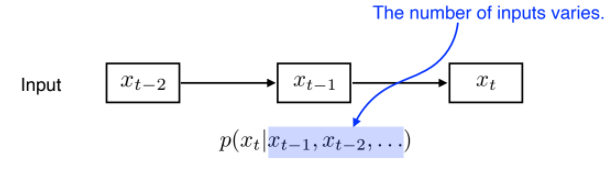
Autoregressive model
- Naive sequence model의 한계를 극복하기 위해 고안된 모델
- 이전 데이터 중 고정된 시간(하이퍼파라미터)만큼만을 고려
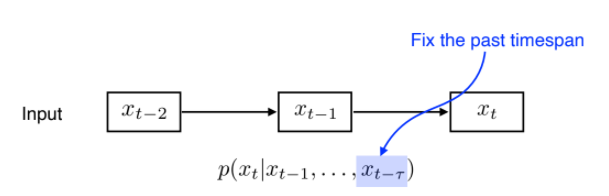
Markov model(first-order autoregressive model)
- 현재는 바로 전 과거에만 의존한다는 특징을 가져온 모델
- 대과거 데이터는 다 제외하므로 많은 정보를 버리게 됨. 그러나 간단하기는 함)
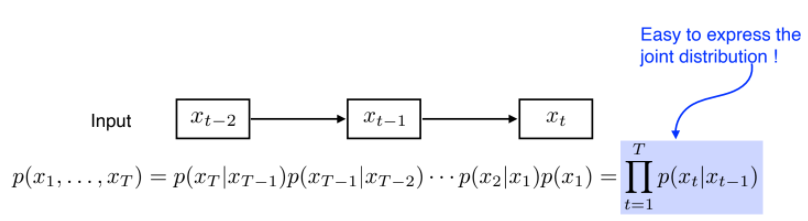
- 대과거 데이터는 다 제외하므로 많은 정보를 버리게 됨. 그러나 간단하기는 함)
Latent autoregressive model
- 과거의 정보를 요약하여 가지고 있는 hidden state가 있는 형태
- output은 1개의 과거 정보(hidden state)에만 dependent 함

RNN(Recurrent Neural Network)
-
RNN을 풀어서 보면, 입력과 hidden layer가 많은 FCL(Fully Connected Layer) 형태임
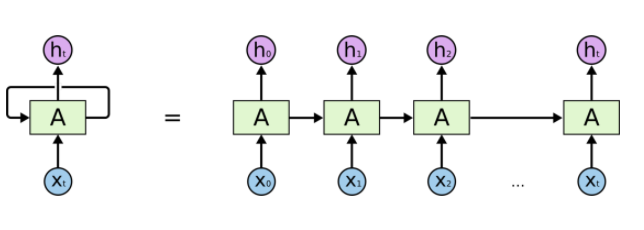
-
Short-term dependencies
- 과거의 정보가 취합되어 현재로 전달되는데, 이렇다보니 먼 과거의 정보는 살아남기 힘들게 됨(짧은 기간의 정보에만 의존)

기울기 소실/증폭 문제
- RNN은 가까운 정보는 잘 반영되지만, 멀리 있는 정보는 잘 반영되지 않는다는 단점이 있음
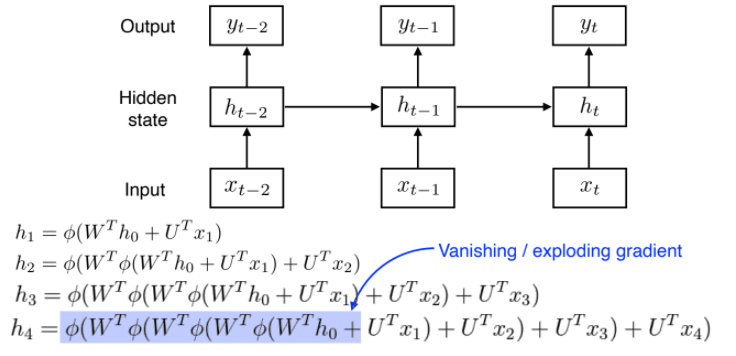
- RNN은 가까운 정보는 잘 반영되지만, 멀리 있는 정보는 잘 반영되지 않는다는 단점이 있음
- 과거의 정보가 취합되어 현재로 전달되는데, 이렇다보니 먼 과거의 정보는 살아남기 힘들게 됨(짧은 기간의 정보에만 의존)
-
이러한 RNN의 문제점을 보완하기 위해 LSTM이 고안됨
Long Short Term Memry
기존 RNN
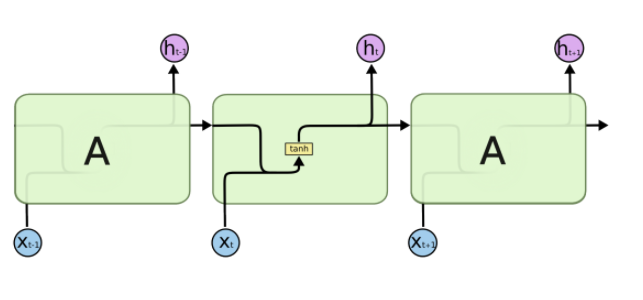
LSTM
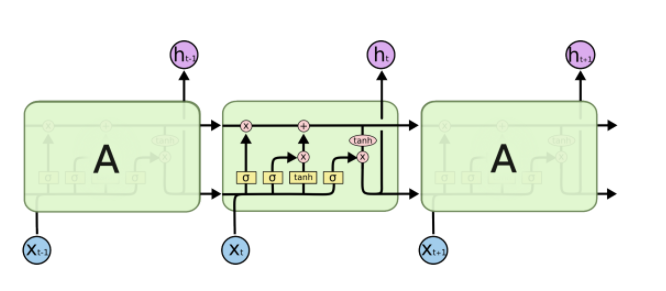
-
LSTM 입출력
- 입력
- Input: 현재의 input vector
- Previous hidden state: 이전의 output
- Previous cell state: 0~t까지의 요약된 과거 정보. 밖으로 나가지 않고 컨베이어처럼 내부로만 흐르는 정보.
- 출력
- Output(hidden state): 실제로 출력되는 값
- Next cell state, Next hidden state: 다음 state로 전달되는 값
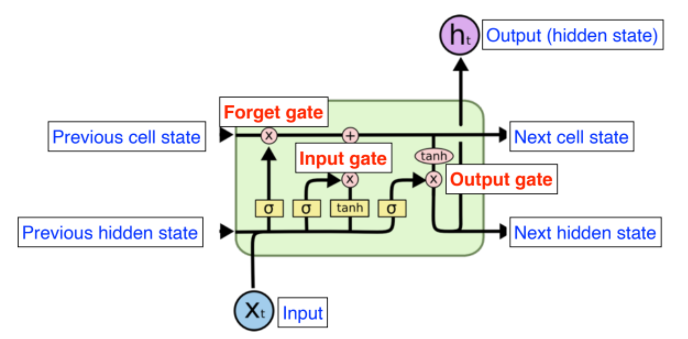
- 입력
-
LSTM 구조
- Forget Gate: 입력값 와 가중치 를 통해 cell state에서 나온 정보 중 무엇을 버릴지 선택
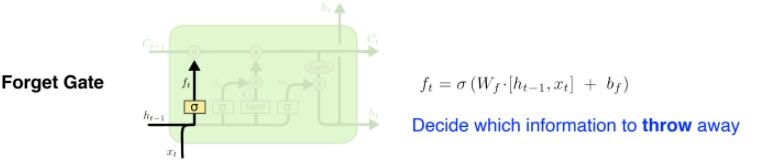
- Input Gate
- : cell state에 어떤 정보를 추가할지 선택
- : 현재 정보와 이전 출력값을 가지고 만들어지는 cell state 예비군. 이전에 취합했던 cell state와 현재정보, 그리고 이전 output으로 얻어지는 (예비군)을 잘 섞어서 cell state에 올리게 됨

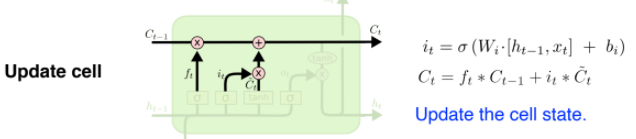
- Update cell
- : 버릴 건 버리고(과거 정보)
- : 쓸 건 쓰고(현재 정보)
- Output Gate
- 업데이트 된 cell state에서 어떤 값을 내보낼 지 정하는 output Gate를 만들고, output Gate만큼 곱해서 로 현재 output이 나오게 됨

- 업데이트 된 cell state에서 어떤 값을 내보낼 지 정하는 output Gate를 만들고, output Gate만큼 곱해서 로 현재 output이 나오게 됨
- Forget Gate: 입력값 와 가중치 를 통해 cell state에서 나온 정보 중 무엇을 버릴지 선택
Gated Recurrent Unit(GRU)
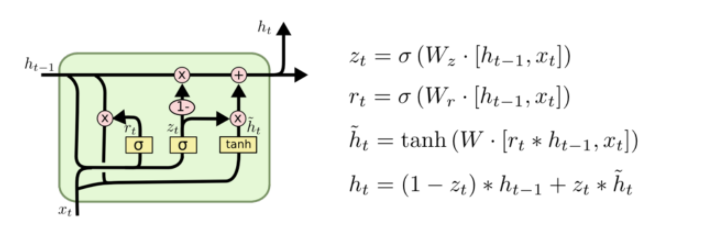
- LSTM에서 parameter를 줄인 형태
- reset gate(forget gate in LSTM)와 update gate(input + output in LSTM)만으로 구성되어 있음
- No cell state, just hidden state(output_
- parameter가 줄어들어, generalization 성능이 올라갈 수 있음
- 일반적으로 LSTM보다 GRU가 성능이 좋다고 알려져 있음

AI Engineer : Lv 0