
Attention is All You Need
Sequence-to-Sequence & Attention
Sequence-to-Sequence
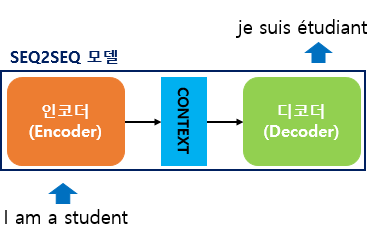
- 어떤 연속된 데이터를 다른 연속된 데이터로 Mapping 시키는 알고리즘
- 챗봇, 기계 번역, 내용 요약 등
- Seq2Seq 모델의 구조
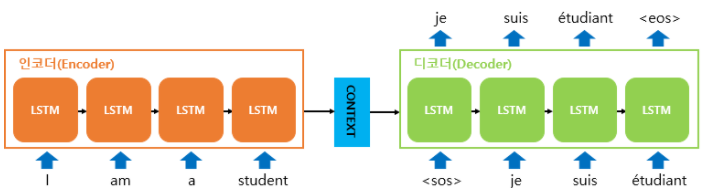
- 인코더: 입력으로 받은 정보를 압축하여 하나의 벡터(context vector)로 만들고, 이를 디코더로 보냄
- 디코더: 인코더로부터 컨텍스트 벡터를 받아서 번역된 단어를 한 개씩 순차적으로 출력시킴
- 하지만 RNN에 기반한 seq2seq 모델은
- 하나의 고정된 벡터에 모든 정보를 압축하다보니 정보 손실이 발생함.
- RNN의 고질적인 문제인 기울기 소실 문제가 발생함
- 이와 같은 문제를 해결하기 위해 Attention이 대안으로 나옴
Attention
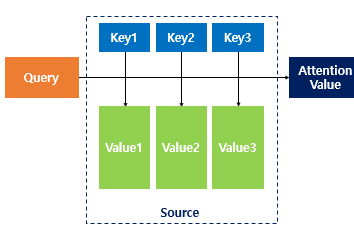
-
디코더에서 출력 단어를 예측하는 매 시점마다, 인코더에서의 전체 입력 문장을 다시 보고 중요한 부분을 참고하여 output을 생성하는 방식
- 출력 단어를 만들어낼 때 마다 문장의 출력 정보 중 어떤 정보가 가장 중요한지에 대한 가중치를 부여
-
Transformer는 이러한 Attention 구조를 활용한 sequence transduction model임.
Transformer
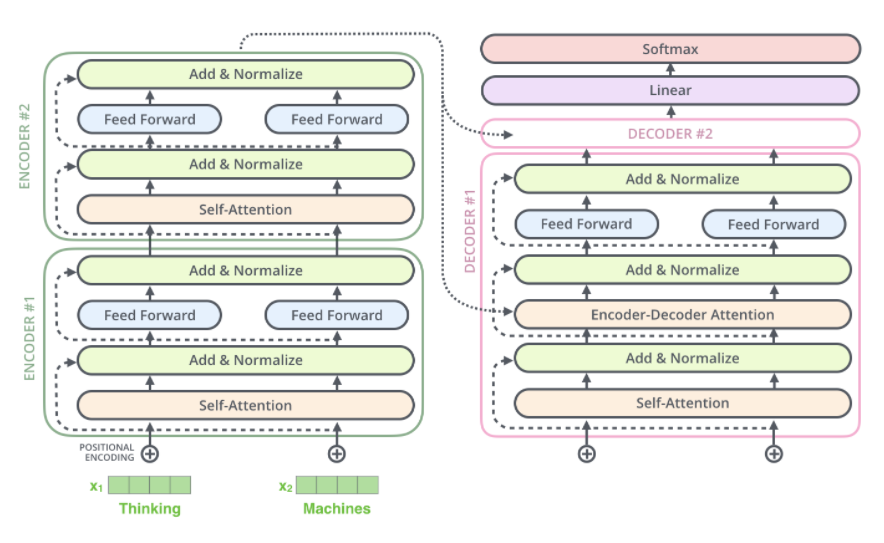
Trnasformer 구조
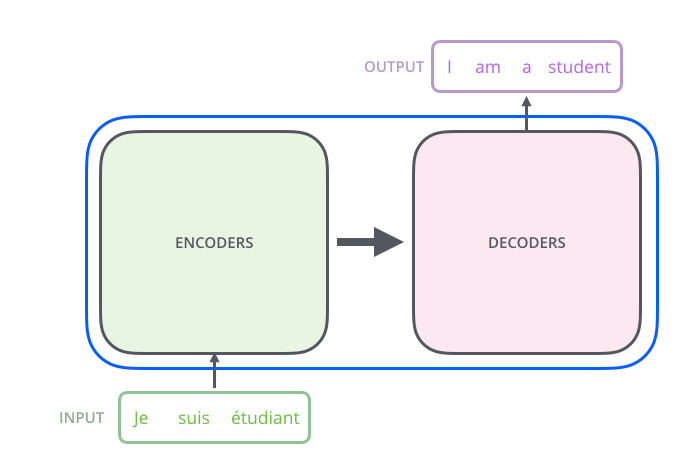
- Transformer는 크게 encoding 부분과 decoding 부분으로 나뉨
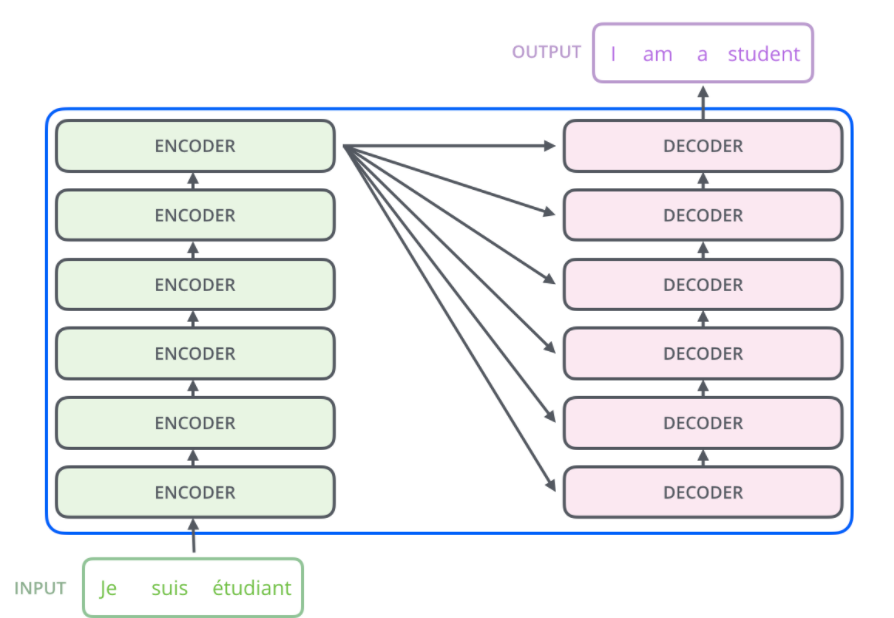
- 이때 encoding은 여러 개의 encoder를 쌓아 올린 형태가 되며, 각 encoder들은 모두 같은 구조를 가지고 있다.
- 그러나 weight는 independent 함
- decoding은 encoder와 동일한 개수만큼의 decoder를 쌓은 형태이다.
Embedding
Embedding
- 단어 임베딩이란, 단어를 R차원의 벡터로 매핑시켜주는 것을 말한다.
- CountVectorizer, TfidfVectorizer, Word2Vec, ....

- 논문에선 각 단어들을 크기 512의 벡터 하나로 embed 시켰으며, 이는 위와 같은 간단한 박스로 나타낼 수 있다(예시로 쓸 그림).
- 모든 encoder들은 크기 512의 벡터 리스트를 입력으로 받는다.
- 이때 어떤 encoder의 입력은 바로 전 encoder의 출력이 된다(첫 encoder 제외)
- (embedding 작업은 가장 처음으로 마주치는 encoder에서만 일어난다)
Positional Encoding
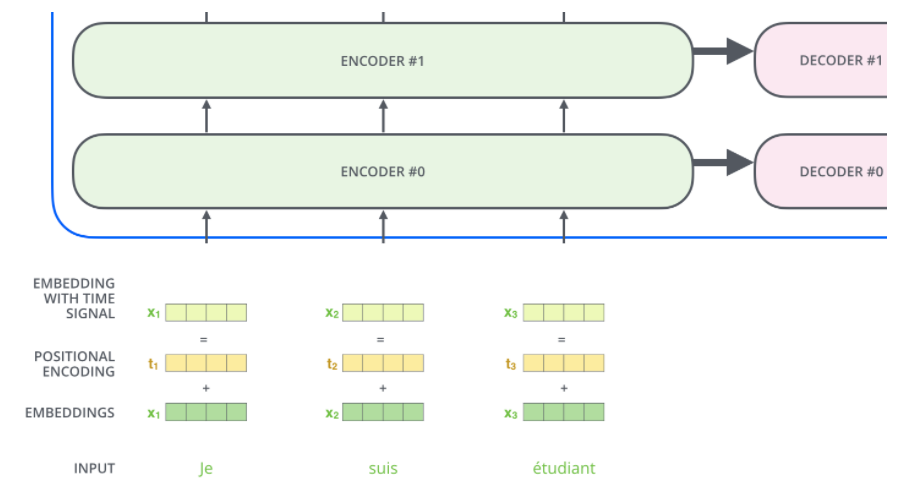
- Positional Encoding이란 입력 문장에서 각 단어들의 순서(위치)에 대한 정보를 알 수 있게 해주는 작업이다.
- transformer 모델에서는 각각의 입력 embedding에 'positional encoding'이라고 불리는 하나의 벡터를 추가하는 식으로 위치를 보존한다.
- 모델에게 단어의 순서에 대한 정보를 주기 위해, 위치별로 특정한 패턴(사인함수와 코사인함수 형태)을 따르는 positional encoding 벡터들을 추가
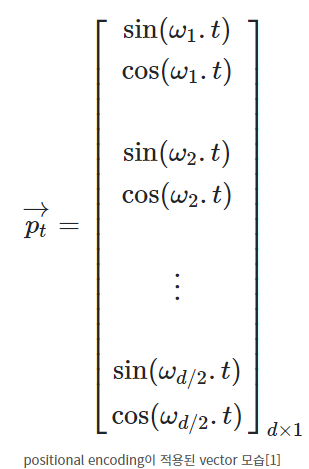
- 모델에게 단어의 순서에 대한 정보를 주기 위해, 위치별로 특정한 패턴(사인함수와 코사인함수 형태)을 따르는 positional encoding 벡터들을 추가
encoding
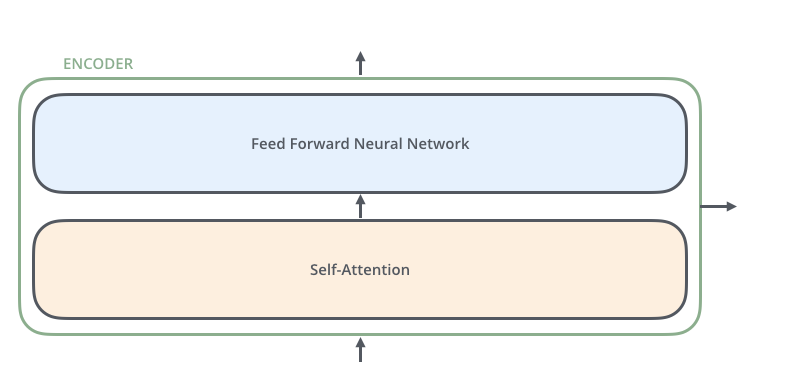
- encoder는 self-attention layer와 feed-forward 신경망으로 이루어져 있다.
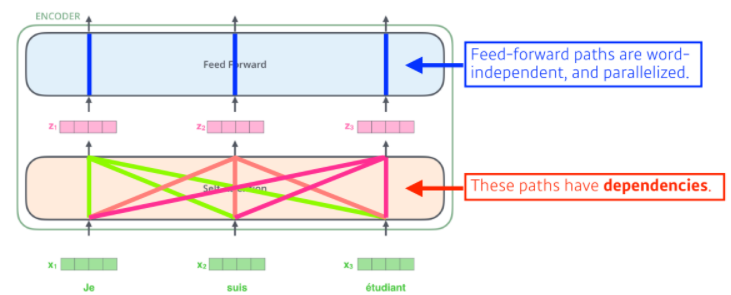
- 이때, self-attention layer에서는
- n개의 벡터()가 주어지고 n개의 를 찾을 때, 는 이외의 모든 벡터도 같이 고려를 한다
- 즉 모든 벡터들은 dependencies를 가진다
- 반대로 Feed-forward에서는
- 각 벡터가 서로 independent 하며 parallelized되어 있다.
Self-Attention

- 'The animal didn't cross the street because it was too tired' 라는 문장이 있을 때, 사람은 'The animal'과 'it' 사이에 높은 관계가 있음을 직관적으로 알 수 있다.
- 하지만 모델은 'it'을 처리할 때 'it'을 'The animal'과 직관적으로 연결지을 수 없다.
- 이때 우리는 self-Attention 알고리즘을 사용하여 모델이 각 단어들 사이의 관계를 학습할 수 있도록 할 수 있다.
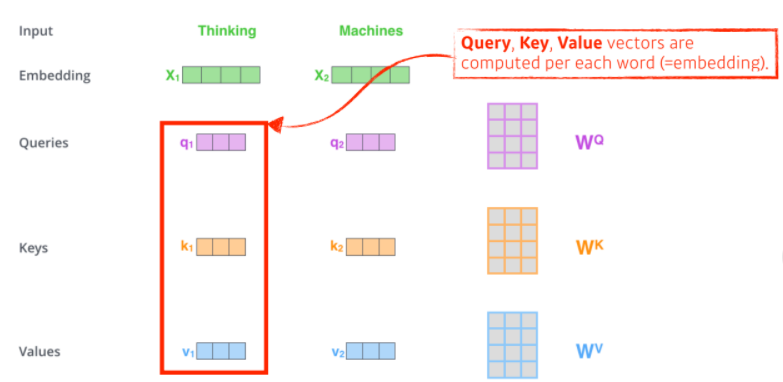
- Self-Attention에서 각 단어(벡터)는 3가지 벡터를 만들어 낸다.
- Query, key, value 벡터
- 입력 벡터(단어)에 대해서 세 개의 학습 가능한 행렬들(을 각각 곱하여 Q, K, V 벡터를 만들어 냄
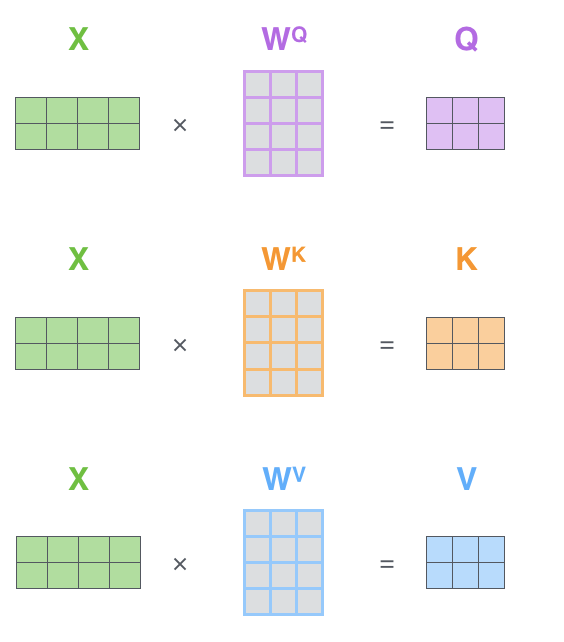
- 우리는 이 Query, key, value 벡터를 이용하여 각 단어의 점수를 계산할 수 있다.
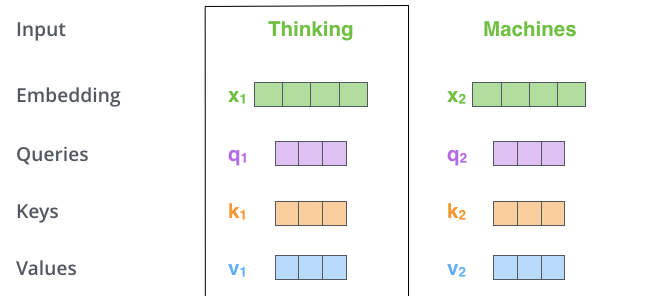
- 'Thinking'과 'Machines'라는 단어가 주어졌을 때, 'Thinking'의 점수를 내는 과정을 살펴보자.
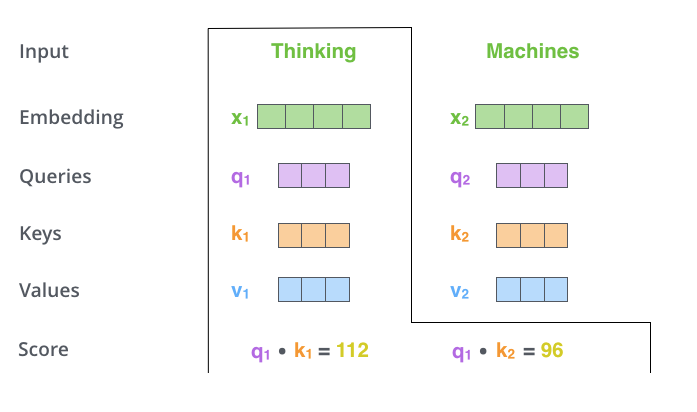
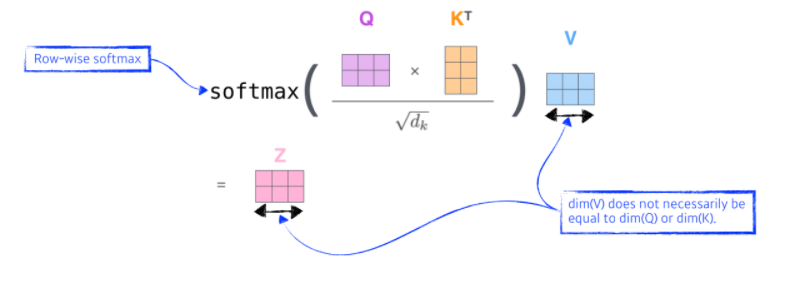
- 의 query 벡터와(예시에서는 'thinking) 자신을 포함한 모든 n개에 대한 key vector를 구한 후, 이들을 내적하여 score를 계산한다. (i번째 단어가 나머지 n개의 단어들과 얼마나 align이 잘 되어 있는지(유사도)를 계산 함)
-> Thinking을 encoding 할 때, 어떤 단어들과 interaction이 더 일어나야되는지를 표현
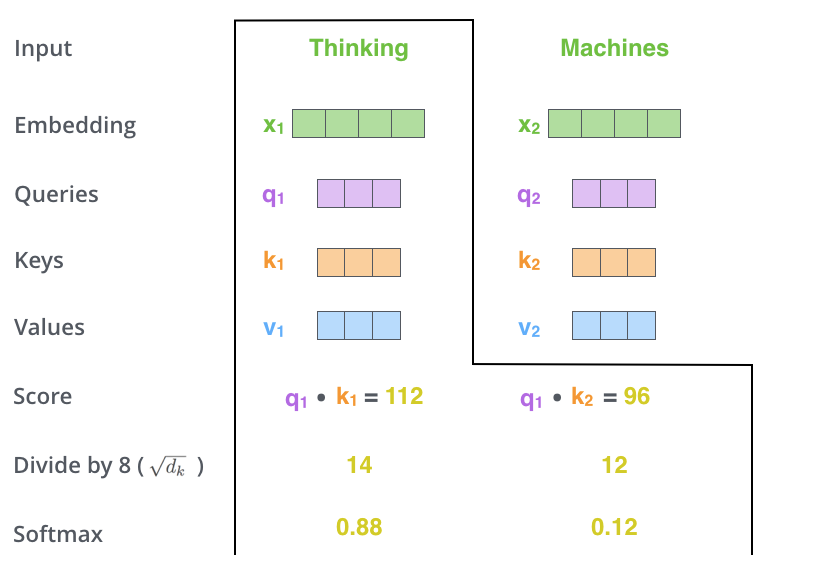
- 이후 score vector를 표준화시킨다.
- Score를 로 나눠줌( = key vector의 차원)
- 나눠준 값에 softmax를 취하여 모든 점수들을 양수로 만들고 그 합을 1로 만들어 줌
-> thinking에 대한 각 단어들의 attention weights들이 나오게 됨
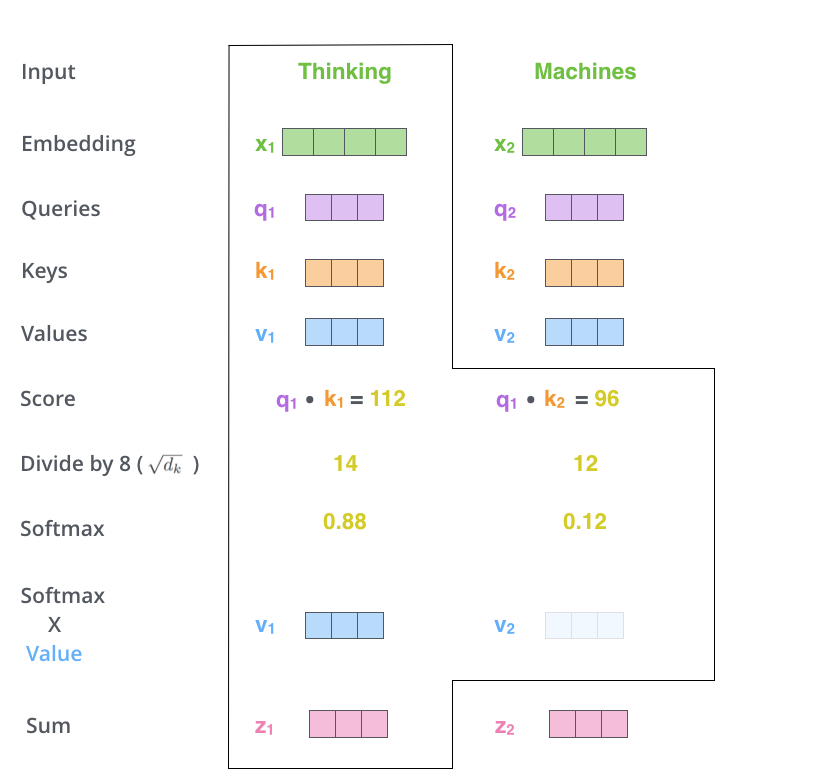
- 마지막으로 thinking의 value 벡터와 각 attention weights들을 곱하고, 이들을 다 더해준다(가중합).
-> thinking의 encoding된 값 z가 출력으로 나오게 됨
❗주의
- query와 key벡터는 항상 차원이 같아야 함(내적을 위해)
- value는 같지 않아도 됨
왜 self-attention이 잘 될까?
- 이미지를 예로 들어서, 입력을 CNN이나 MLP로 차원을 바꾸면, 입력이 고정될 때 출력도 고정됨(filter나 weight가 고정되어 있기 때문)
- transformer는 input이 고정되고, 네트워크가 고정되어 있다 해도 해당 단어와 옆에 있는 단어들에 따라서 출력(encoding) 값이 달라지게 됨
- 따라서 기존 모델들보다 좀 더 flexible하게 더 많은 걸 표현할 수 있음
Multi-headed attention(MHA)
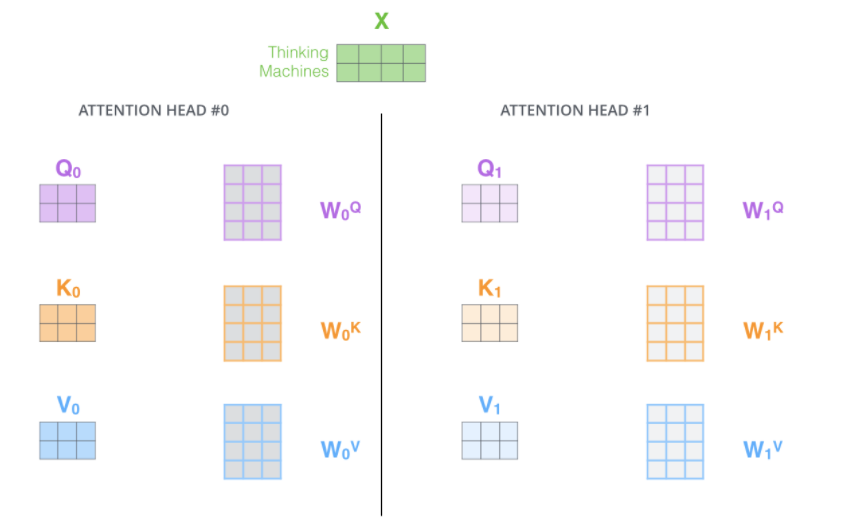
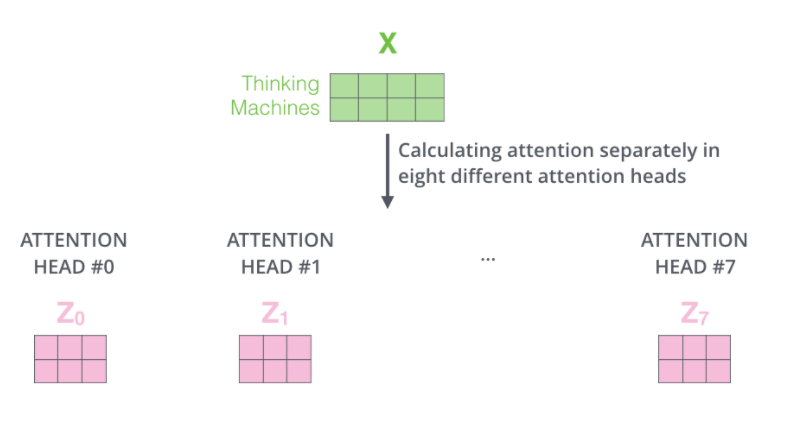
- 논문에서는 앞서 계산해보았던 Attention을 n번 하는 'multi-headed attention'을 통해 성능을 향상시킨다.
- MHA는 모델이 다른 위치에 집중하는 능력을 확장시킨다.
위 계산에서 봤듯이, ENCODING하는 과정에서 자기 자신에게 너무 높은 점수를 주는 경향이 있다. MHA는 이를 완화시킨다. - attention later가 여러 개의 'representation 공간'을 가지게 해준다.
각 encoder는 서로 다른 query, key, value weight를 가지게 된다. 이러한 qkv weight가 여러 개 있다는 것은 모델의 표현력을 좀 더 풍부하게 만들어준다.
- MHA는 모델이 다른 위치에 집중하는 능력을 확장시킨다.
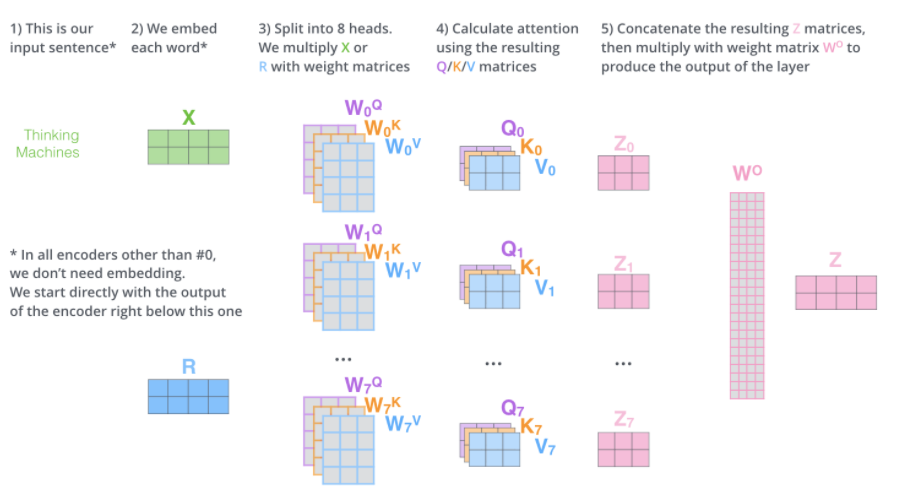
- 문제는 n개의 z행렬을 바로 Feed-forward layer로 보낼 순 없다는 것이다.
- feed-forward layer는 한 위치에 대해 오직 한 개의 행렬만들 input으로 받음

- 이를 해결하기 위해, 앞서 나온 n개의 행렬을 이어 붙여서(concat) 하나의 행렬로 만들고, 또 다른 weight 행렬을 곱하여 선형변환 시켜줌으로써 출력값 z를 만들어낸다
self-attention 요약
The Residuals
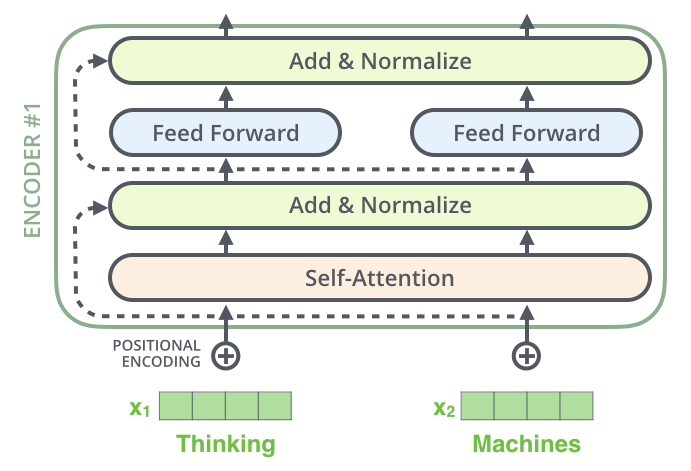

- 추가로, 각 encoder내의 sub-layer는 residual connection으로 연결되어 있으며, 그 후에는 layer-normalization을 거친다.
decoding
![]()
-
가장 윗단(마지막) encoder의 출력은 attention 벡터들인 K와 V로 변형된다.
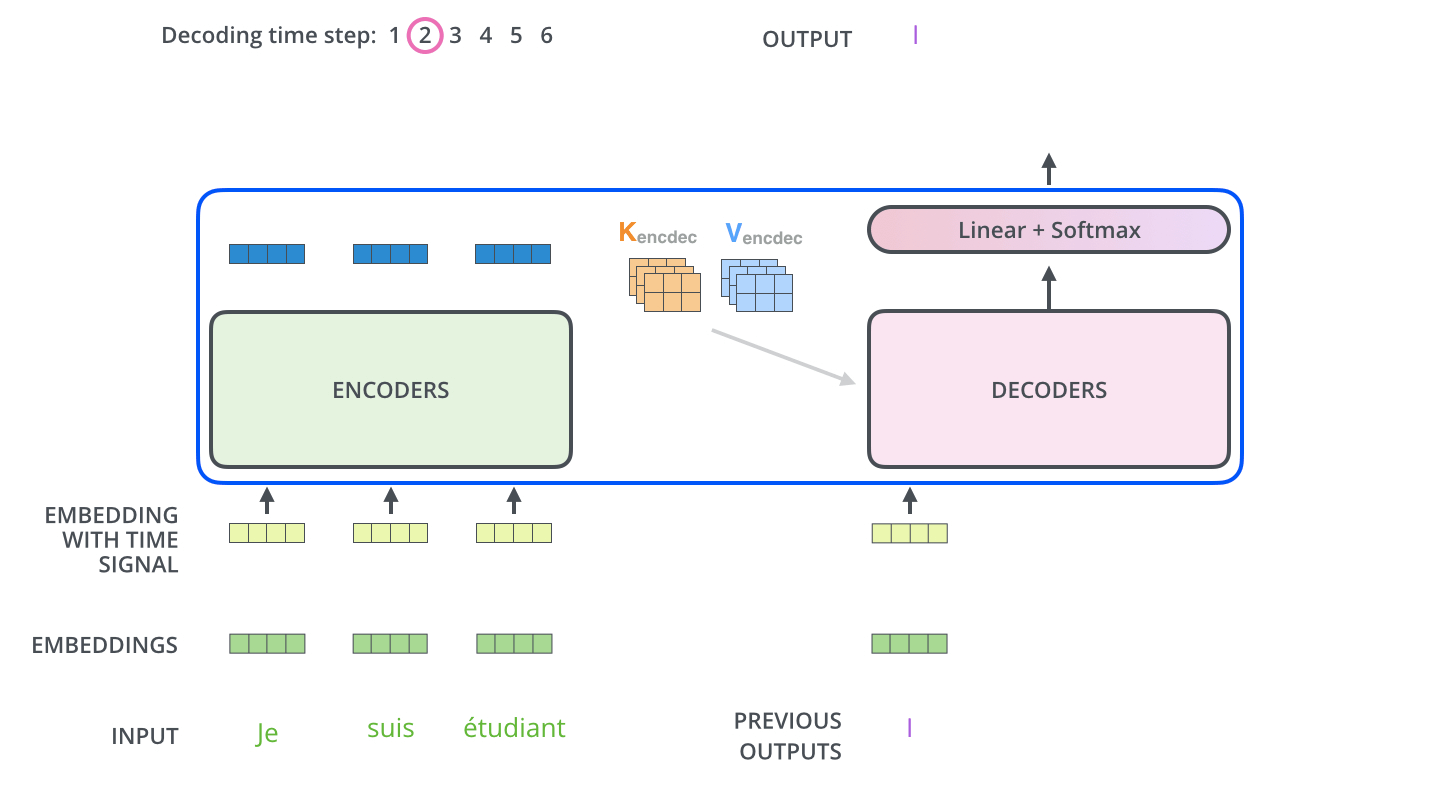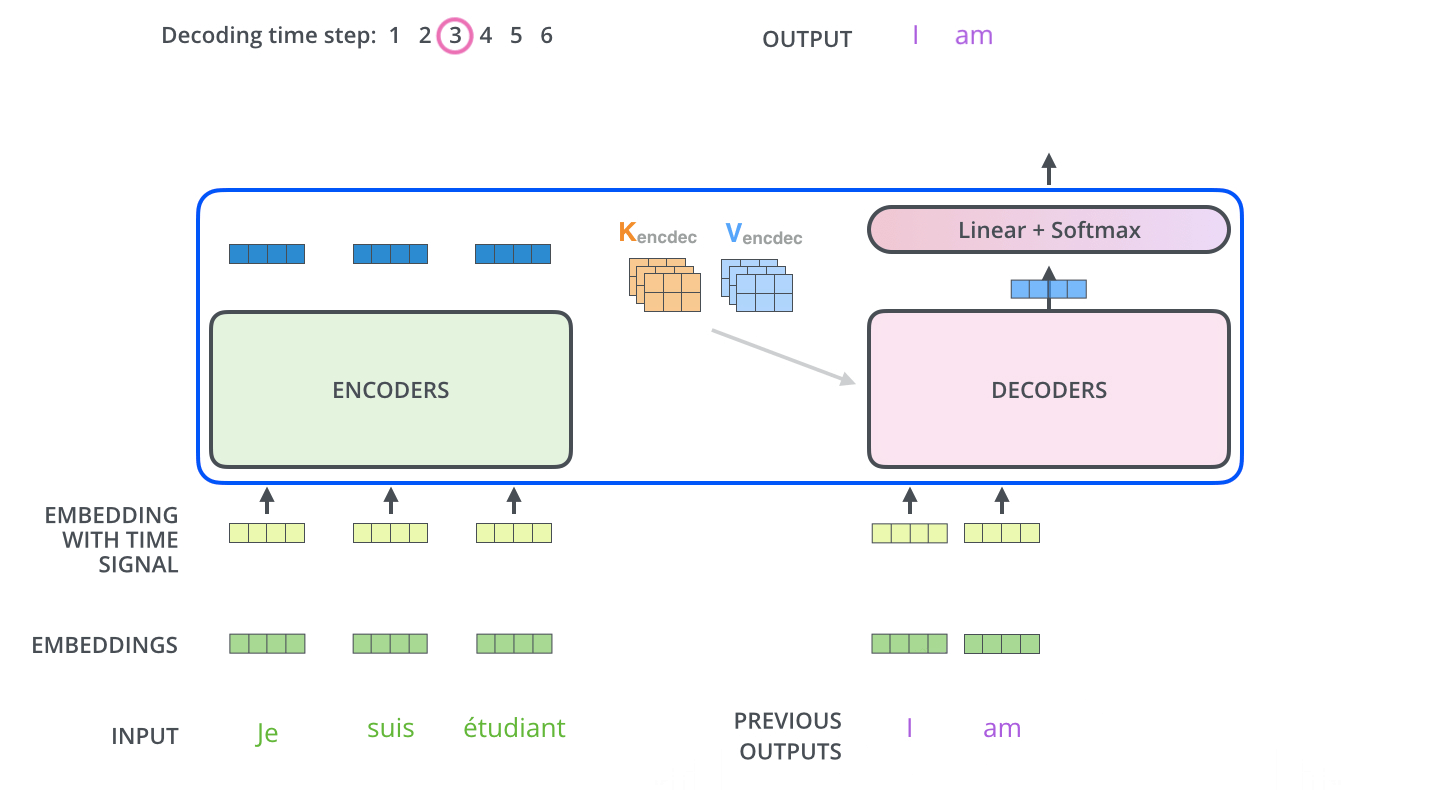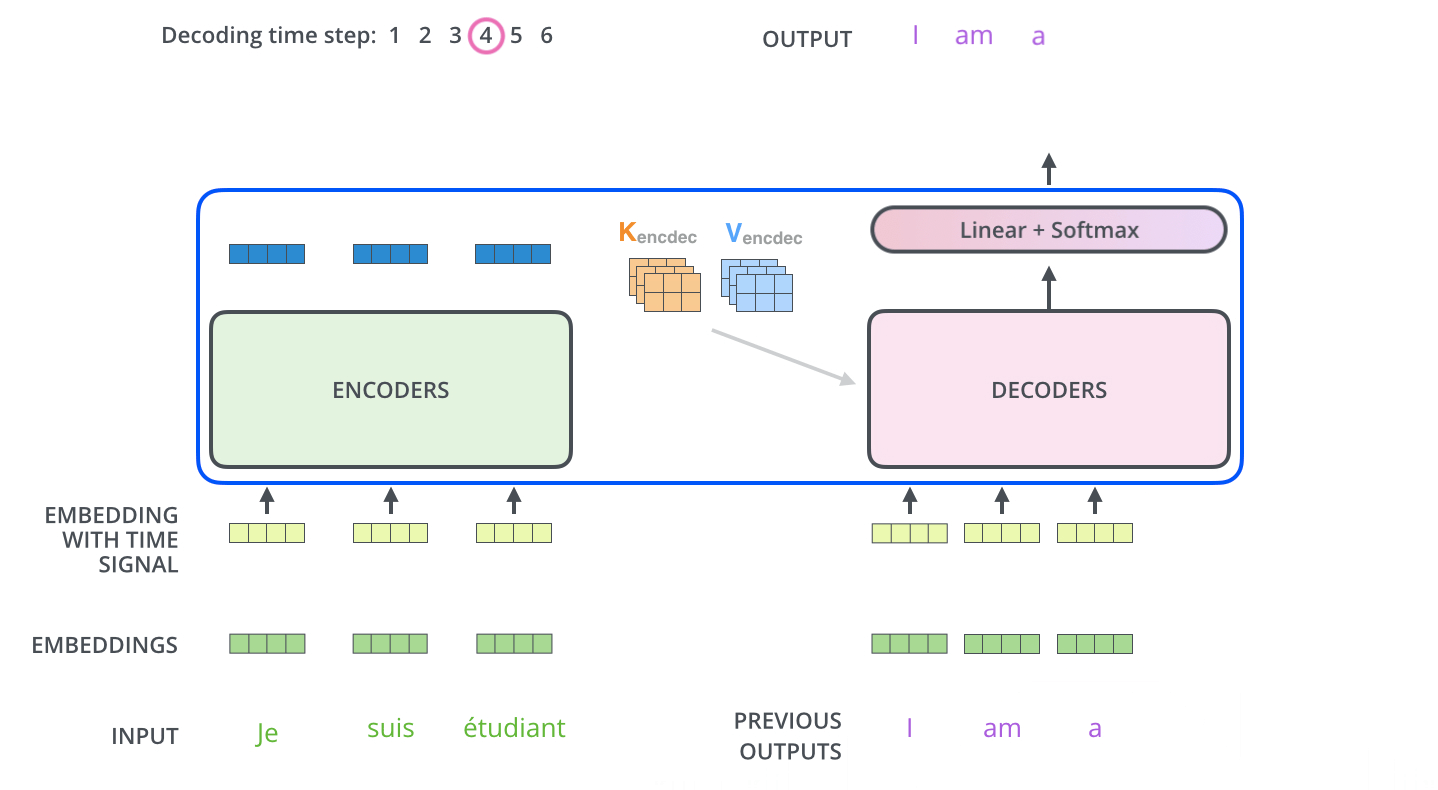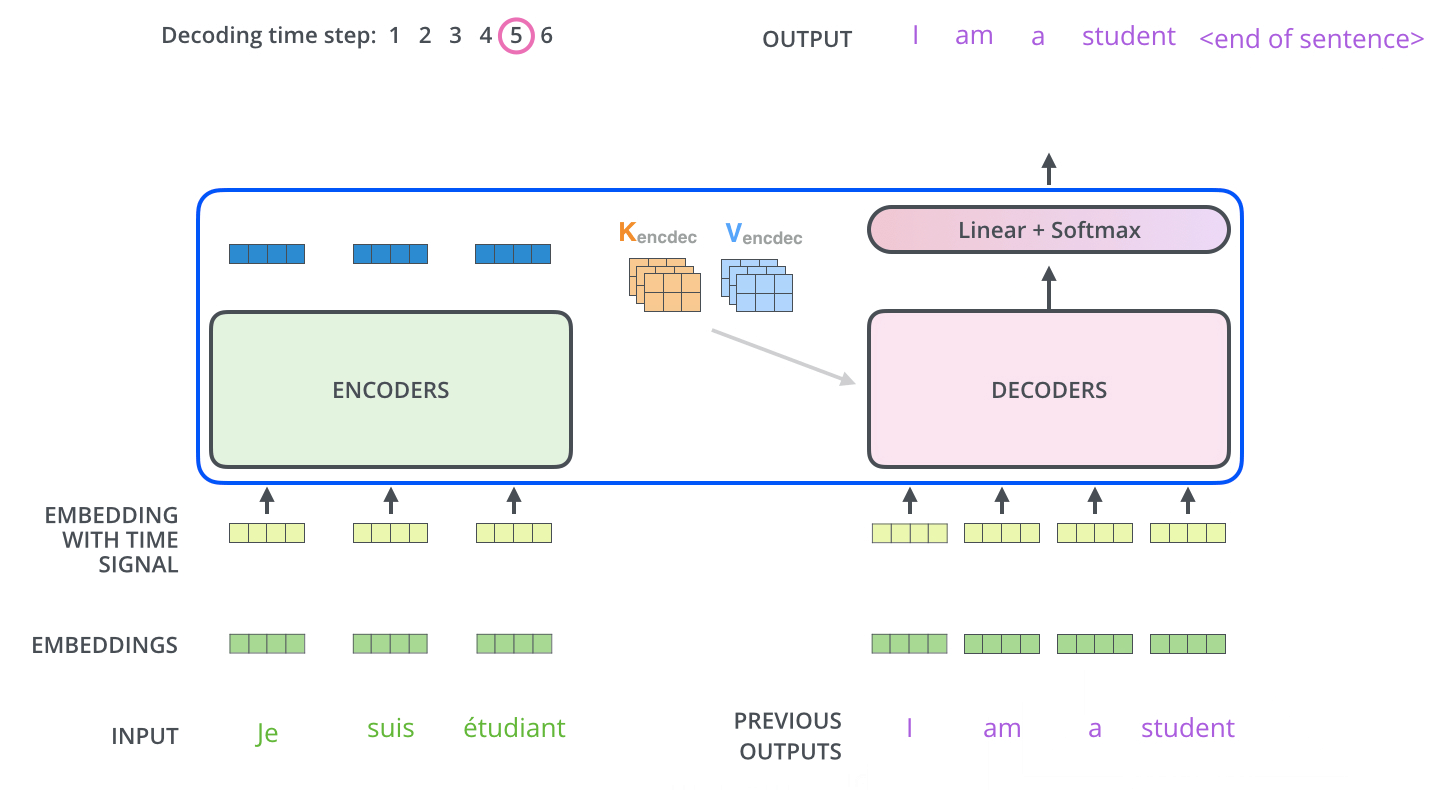
-
이후 디코딩은 <end of sentence, eos>를 출력할 때까지 반복된다.
-
임베딩된 단어는 가장 밑단의 decoder에 들어가고, encoder와 마찬가지로 여러 개의 decoder를 거쳐 올라간다.
- encoder와의 차이점은 Query행렬들은 그 밑의 layer에서 가져오고, Key, Value 행렬들은 encoder의 출력에서 가져온다.
-
이때, decoder에서의 self-attention layer는 미리 있던 정보를 활용하지 않기 위해, 미래 정보들에 해당하는 Attention score들에는
-inf로 치환하여 가려준다(이후 softmax를 거치면 값이 0이 됨(반영 x)). -
이후 Linear & Softmax를 거치며 최종 출력 단어로 변환된다.
참고자료
Further Reading: Vision-Transformer
- Alexey Dosovitskiy et. al., An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2019
- 코드리뷰
- 강의
- CLS_Token이란

AI Engineer : Lv 0