Word2Vec
Word2Vec 개요
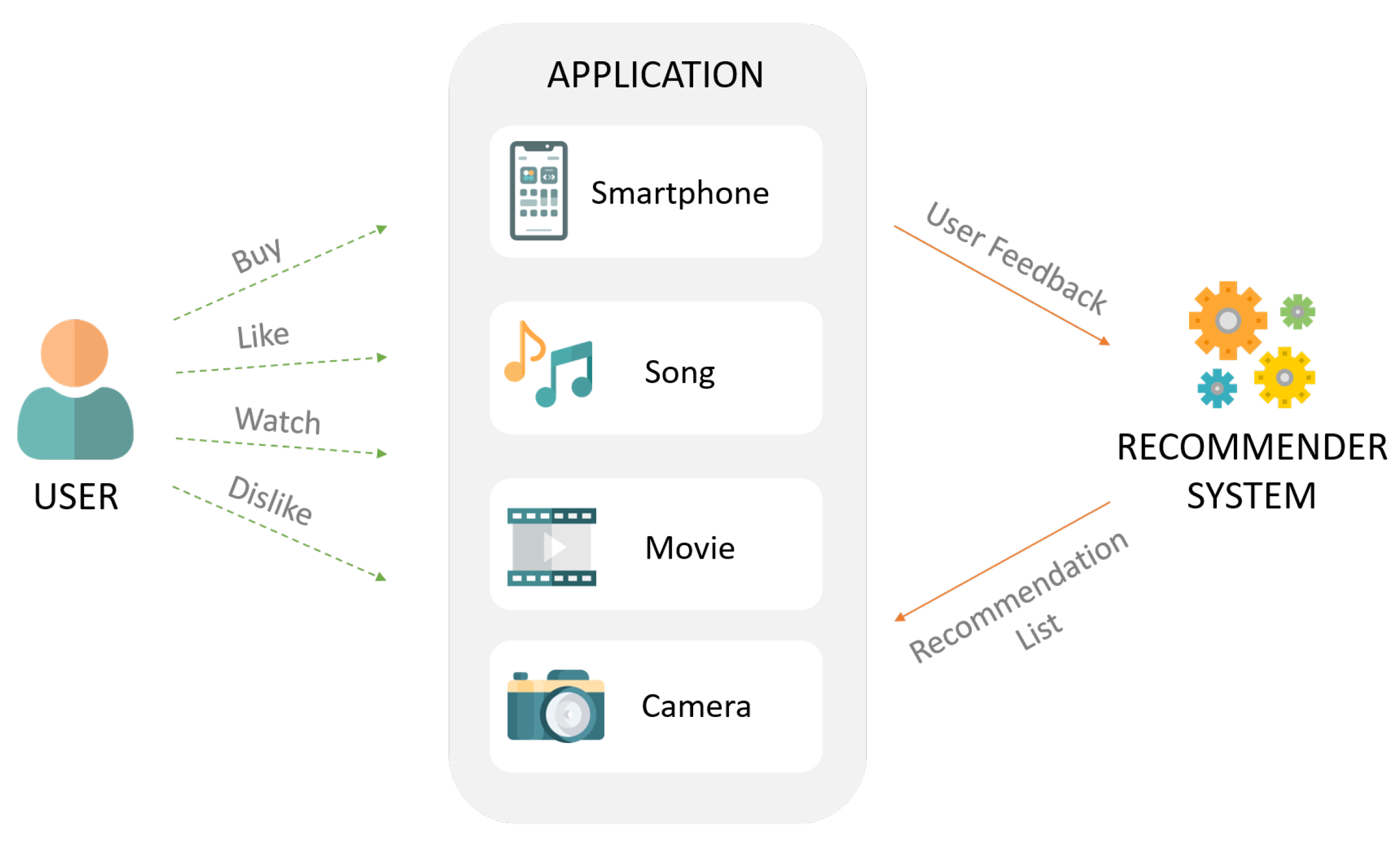
임베딩(Embedding)
주어진 데이터를 낮은 차원의 벡터(vector)로 만들어서 표현하는 방법
- Sparse Representation: 아이템의 전체 가짓수와 차원의 수가 동일
- 이진 값으로 이루어진 벡터로 표현 -> one-hot encoding 또는 multi-hot encoding
- one-hot ex) 면도기 = [1, 0, 0] / 가위 = [0, 1, 0]
- 아이템 개수가 많아질수록 벡터의 차원은 한없이 커지고 공간이 낭비될 수 있음.
- Dense Representation: 아이템의 전체 가짓수보다 훨씬 작은 차원으로 표현
- 실수값으로 이루어진 벡터로 표현
- ex) 면도기 = [0.2, 1.4, -0.4, 1.2] / 가위 = [-0.1, 0.5, 1.1, 0.4]
워드 임베딩(Word Embedding)
텍스트 분석을 위해 단어(word)를 벡터로 표현하는 방법
(sparse representation -> dense representation)
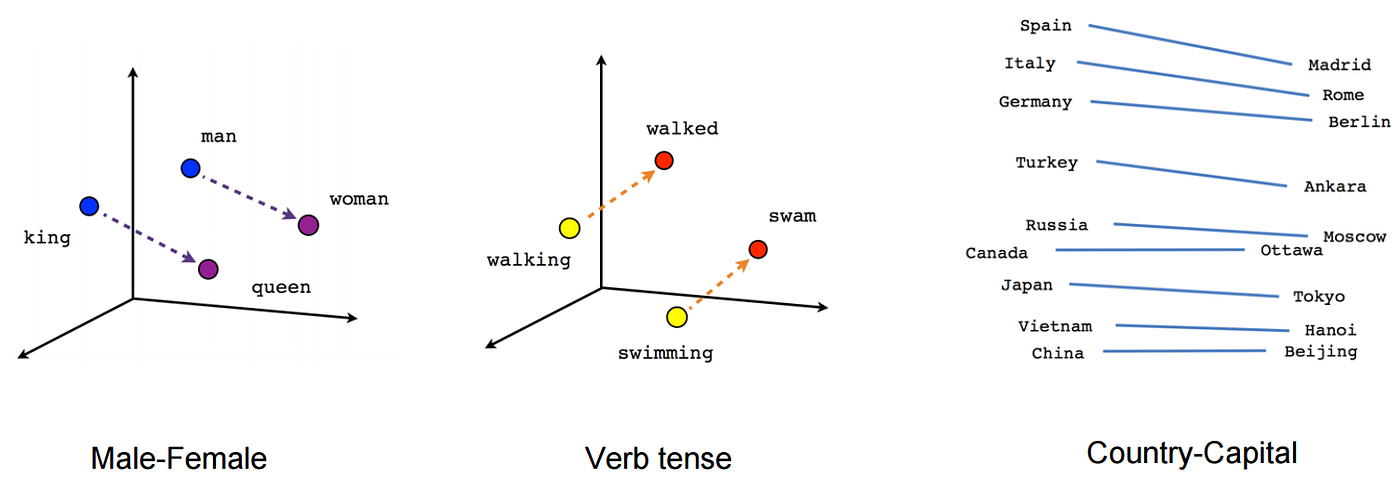
- 단어 간 의미적인 유사도를 구할 수 있음
- 비슷한 의미를 가진 단어일수록 embedding vector가 가까운 위치에 분포
- ex)
나는,그는,그녀는등의 단어는 비슷한 vector 값을 가질 것으로 예상
- 임베딩으로 표현하기 위해서는 학습 모델이 필요함.
- Matrix Factorization도 유저/아이템의 임베딩으로 볼 수 있으며, 데이터로부터 학습한 매트릭스(user-item matrix)가 곧 임베딩임.
Word2Vec
특징
- 뉴럴 네트워크 기반(기존의 NNLM 모델)
- 대량의 문서 데이터셋을 vector 공간에 튜영
- 압축된 형태의 많은 의미를 갖는 dense vector로 표현
- (간단한 구조이므로)효율적이고 빠른 학습이 가능
학습 방법
- CBOW
- Skip-Gram
- Skip-Gram w/ Negative Sampling(SGNS)
Word2Vec 학습 방법
CBOW
주변에 있는 단어를 가지고 센터에 있는 단어를 예측하는 방법
- window: 단어를 예측하기 위해 앞 뒤로 몇 개(n)의 단어를 사용할 것인가?
- ex) window의 크기가 n이라면, 예측을 위해 참고하는 단어는 2n(앞 뒤)개
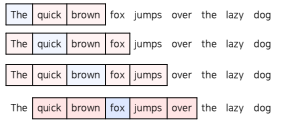
- ex) window의 크기가 n이라면, 예측을 위해 참고하는 단어는 2n(앞 뒤)개
학습
Input(one-hot vector) : quick, brown, jumps, over
Output : fox

- one-hot vector를 embedding
- : 단어의 총 개수
- : 임베딩 벡터의 사이즈
- 학습 파라미터: (임베딩), (output)
- : 은닉층(임베딩 결과들을 2n개의 window로 평균낸 값)
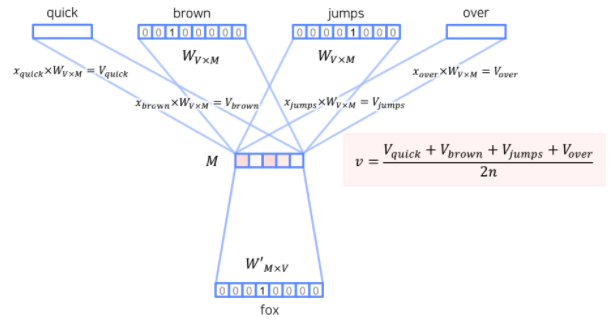
임베딩 변환 예시:
brown
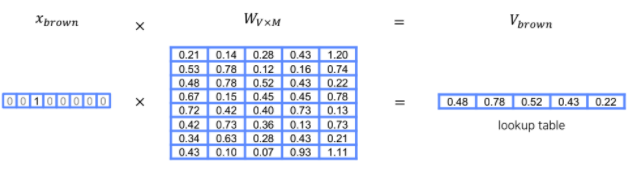
- output
- 예측값 와 one-hot vector 의 차이를 최소화하도록 모델 학습
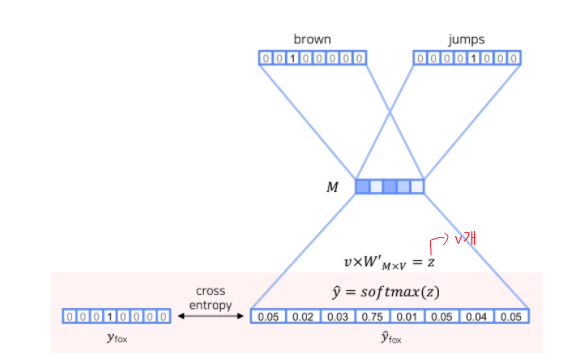
- 예측값 와 one-hot vector 의 차이를 최소화하도록 모델 학습
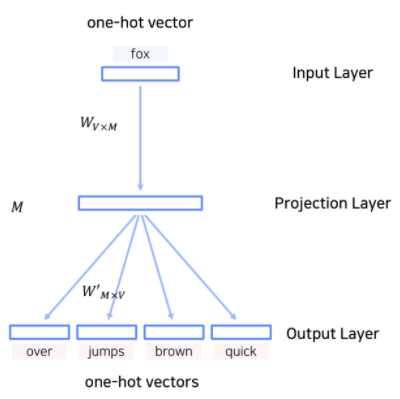
Skip-Gram
CBOW의 입력층과 출력층이 반대로 구성된 모델(계산 방법은 CBOW와 동일)
- 일반적으로 CBOW보다 Skip-Gram의 성능이 더 좋다고 알려져 있음
(학습 이후, 임베딩의 표현력이 일반적으로 더 좋음)
Skip-Gram with Negative Sampling(SGNS)
(Item2Vec의 학습 방법)

- Skip-Gram은 다중분류, SGNS는 이진분류 문제임
- 주변 단어는 레이블 1로 두고,
주변 단어가 아닌 단어들은 sampling하여 레이블 0으로 넣음(Negative Sampling) - Negative Sampling 개수는 모델의 하이퍼 파라미터
- positive sample 하나당 k개 샘플링
(학습 데이터가 적은 경우 5~20, 충분히 큰 경우 2~5가 적당)
- positive sample 하나당 k개 샘플링
학습 방법
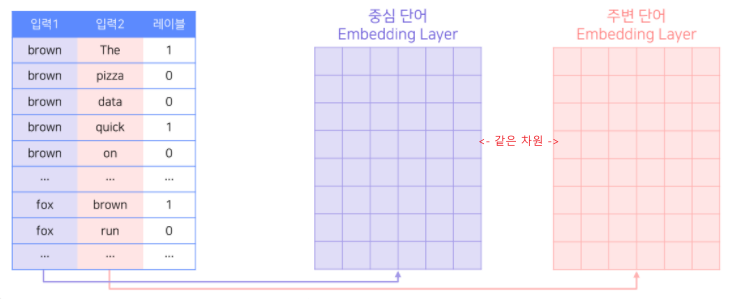
- 중심 단어와 주변 단어가 각각 임베딩 파라미터를 따로 가짐
- 중심 단어와 주변 단어가 서로 다른 lookup table을 통해 임베딩 됨.
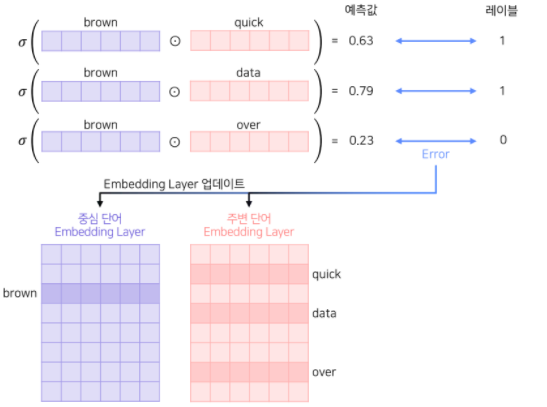
- 중심 단어를 기준으로 주변 단어들(positive, negative)과의 내적의 sigmoid를 예측값으로 하여 0과 1을 분류
- 역전파(backpropagation)을 통해 각 임베딩이 업데이트 되면서 모델이 수렵함
- 최종 생서된 워드 임베딩이 2개이므로, 선택적으로 하나만 사용하거나 평균을 사용
Item2Vec
- Word2Vec의 SGNS에서 영감을 받아, 아이템 기반 CF(IBCF)에 Word2Vec을 적용한 논문
- 논문
Item2Vec 개요
단어가 아닌 추천 아이템에 Word2Vec을 사용하여 임베딩(기존 MF도 유저와 아이템을 임베딩하는 방법 중 하나임)
- 개벼 유저가 소비한 아이템 리스트를 문장으로, 아이템을 단어로 가정하여 Word2Vec사용
- Item2Vec은 유저-아이템 관계를 사용하지 않으므로, 유저 식별 없이 세션 단위로도 데이터 생성 가능
- 앞서 배운 SGNS 기반의 Word2Vec을 사용하여 아이템을 벡터화하는 것이 최종 목표임
-> SVD기반 MF를 사용한 IBCF보다 높은 성능과 양질의 추천 결과를 제공함
Item2Vec 상세
Item2Vec
- 유저 혹은 세션 별로 소비한 아이템 집합을 생성.
- 이 때 시퀀스를 집합으로 바꾸면서 공간/시간적 정보는 사라짐
- 대신 집합 안에 존재하는 아이템은 서로 유사하다고 가정
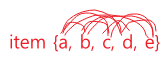
- 공간적 정보를 무시하므로 동일한 집합 내 아이템 쌍들은 모두 SGNS의 Positive Sample이 됨.
- 기존의 Skip-Gram이 주어진 단어 앞 뒤로 n개의 단어를 사용한 것과 달리 모든 단어 쌍을 사용
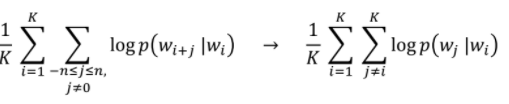
- 기존의 Skip-Gram이 주어진 단어 앞 뒤로 n개의 단어를 사용한 것과 달리 모든 단어 쌍을 사용
Item2Vec 예시
- 하나의 동일한 세션에서 유저가 A, C, B를 소비했다고 가정한다면,
- 아이템 집합: {A, B, C}
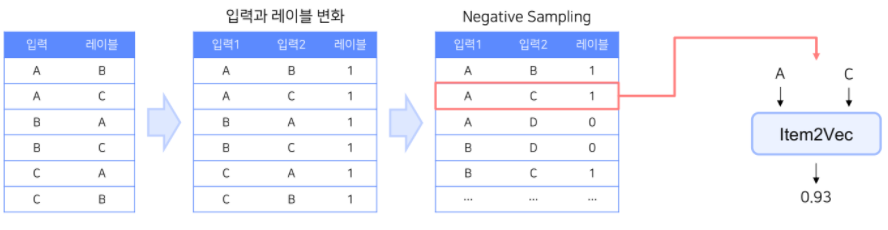
- 아이템 집합: {A, B, C}
Item2Vec 활용 사례
- 아프리카 TV의 Live2Vec
: [문장] 유저의 시청 이력 / [단어] 시청 이력을 구성하는 라이브 방송들 - 스포티파이의 Song2Vec
: [문장] 유저의 플레이리스트 / [단어] 플레이리스트 안에 있는 노래들 - ....
Approximate Nearest Neighbor (ANN)
ANN의 필요성
-
Nearest Neighbor (NN)
- Vector Space에서 내가 원하는 Query Vector와 가장 유사한 Vector를 찾는 알고리즘
-
MF 모델을 가지고 추천시스템을 서빙한다면?
- 유저에게 아이템 추천: 해당 유저 Vector와 후보 아이템 Vector들의 유사도 연산이 필요
- 비슷한 아이템 연관 추천: 해당 아이템 Vector와 다른 모든 후보 아이템 Vector들의 유사도 연산이 필요
-
추천 모델 서빙 Nearest Neighbor Search
- 모델 학습을 통해 구한 유저/아이템의 Vector가 주어질 때, 주어진 Query Vector의 인접한 이웃을 찾아주는 것
-
가장 기본적인 NN 알고리즘: Brute Force KNN
- 나머지 모든 Vector와 유사도 비교를 수행하는 알고리즘
- 정확도는 높지만, Vector의 차원과 개수에 비례한 비교 연산 비용이 필요
-> 대안: 정확도를 조금 포기하고 빠른 속도로 주어진 Vector의 근접 이웃을 찾아보자!
-> Approximate Nearest Neighbor (ANN)
ANN 알고리즘
ANNOY
스포티파이에서 개발한 tree-based ANN 기법
(ANNOY 참고)
- 주어진 벡터들을 여러 개의 subset으로 나누어 tree 형태의 자료구조로 구성하고 이를 활용하여 탐색
- Vector Space에서 임의의 두 점을 선택한 뒤, 두 점 사이의 hyperplane으로 Vector Space를 나눔
- Subspace에 있는 점들의 개수를 node로 하여 binary tree 생성 혹은 갱신
- Subspace 내에 점이 K개 초과로 존재한다면 해당 Subspace에 대해 (1) 과 (2) 반복 진행

-> ANN을 구하기 위해서는 현재 점(Query vector)을 binary tree에서 검색한 뒤 해당 Subspace 안에서 NN을 서치(유사도 연산)
(Query Vector가 속한 Subspace를 시간만에 찾을 수 있음
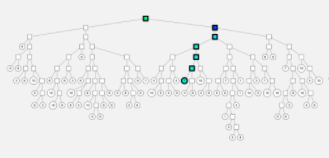
- ANNOY의 hyperparameter
- num_of_trees: 생성하는 binary tree의 개수
- search_k: NN을 구할 떄 탐색하는 NODE의 개수
ANNOY의 문제점 및 해결방안
- 문제1. 가장 근접한 점이 아슬아슬하게 tree의 다른 node에 있을 경우 해당 점은 후보 subset에 포함되지 못함
(Hyperplane을 Random하게 나눴기 때문에 발생할 수 있는 문제)- 해결방안
- priority queue를 사용하여 가까운 다른 node를 탐색
- binary tree를 여러 개 생성하여 병렬적으로 탐색(앙상블)
- 해결방안
ANNOY 요약 및 특징
- Search Index를 생성한느 것이 다른 ANN 기법에 비해 간단하고 쉬움
- 아이템 개수가 많지 않고 벡터의 차원(d<100)이 낮은 경우 사용하기에 적합
- GPU 연산은 지원하지 않음
- Search 해야 할 이웃의 개수를 알고리즘이 보장함
- 하이퍼 파라미터 조정을 통해 accuracy / speed 의 trade-off 조정 가능
- ! 단, 기존 생성된 binary tree에 새로운 데이터를 추가할 수 없음
Hierarchical Navigable Small World Graphs (HNSW)
벡터를 그래프의 node로 표현하고 인접한 벡터를 edge로 연결
- Layer를 여러 개 만들어 계층적 탐색을 진행 -> search 속도 향상
- Layer 0에는 모든 노드가 존재, 최상위 Layer로 갈수록 개수가 적음(Random sampling)
- HNSW
- Small World Graphs: 가까운 노드들이 몇 개만 연결되어 있음
- Navigable: SWG 간 연결을 함으로써 Navigable하게 해줌
- Hierarchical: 계층이 존재
작동 방식
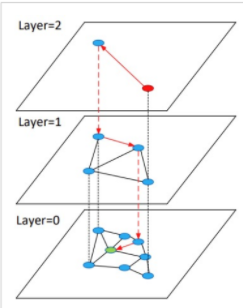
1. 최상의 Layer의 임의의 노드에서 시작
2. 현재 Layer에서 타겟 노드(Query Vector)와 가장 가까운 노드로 이동
3. 현재 Layer에서 더 가까워 질 수 없다면 하위 Layer로 이동
4. 타겟 노드에 도착할 때까지 (2), (3) 반복
5. (2) ~ (4)를 진행할 때 방문했던(traverse) 녿들만 후보로 하여 NN을 탐색
- 대표 라이브러리: nmslib, faiss
Inverted File Index (IVF)
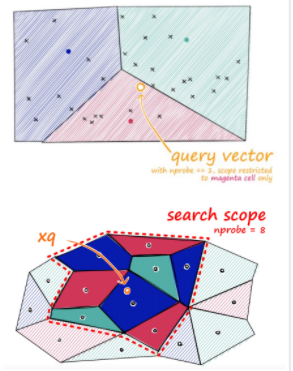
- 작동방식
- 주어진 vecotr를 clustering(K-mean 등)을 통해 n개의 cluster로 나눠서 저장
- vector의 index를 cluster별 inversted list로 저장
-> Query Vector에 대해서 해당 cluster를 찾고, 해당 cluster의 invert list 안에 있는 vector들에 대해서 탐색
Product Quantization - Compression (PQ)
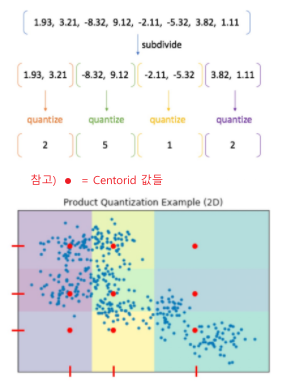
- 작동 방식
- 기존 vector를 n개의 sub-vector로 나눔
- 각 sub-vector 군에 대해 k-means clustering을 통해 centroid를 구함
- 기존의 모든 vector를 n개의 centroid로 압축해서 표현
- 장점
- 두 vector의 유사도를 구하는 연산이 거의 요구되지 않음()
(미리 구한 centroid 사이의 유사도를 활용) - PA와 IVF를 동시에 사용해서 더 빠르고 효율적인 ANN 가능
- 두 vector의 유사도를 구하는 연산이 거의 요구되지 않음()

AI Engineer : Lv 0