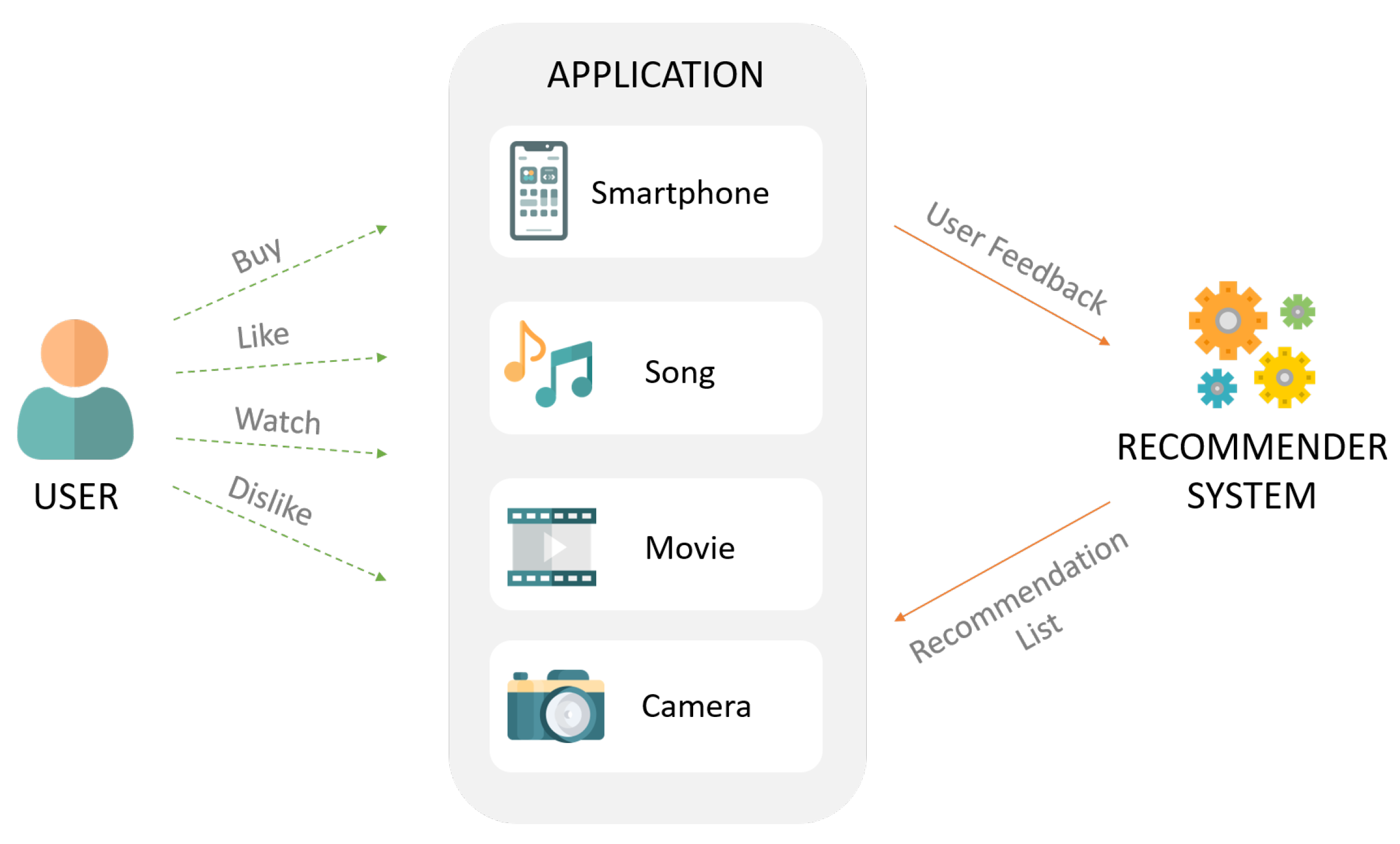
인기도 기반 추천
개요
인기도 기반 추천이란?
- 통계적인 지표들을 활용하여 가장 인기있는 아이템을 추천하는 것
- 인기도의 척도: 조회수, 평균 평점, 리뷰 개수, 좋아요/싫어요 수, ...
- EX) 네이버 쇼핑 랭킹 순, 레딧 hot 추천, ...
어떻게 스코어를 만들어야 할까?
- 조회 수가 가장 많은 아이템을 추천(Most Popular)
- ex) 뉴스 추천: 유저들은 다른 유저들이 많이 관심을 가지는 핫한 이슈를 보고싶어 함
- 평균 평점이 가장 높은 아이템을 추천(Highly Rated)
- ex) 맛집 추천: 평점이 높은 맛집을 선호함
Most Popular
가장 많이 조회된 뉴스를 추천 or 좋아요가 가장 많은 게시글을 추천
- 뉴스의 가장 중요한 속성은 최신성!
Hacker News Formula
- 뉴스 추천 : 조회 수(page view)와 게시 날짜(age)를 고려하여 추천
- 시간이 지날수록 age가 점점 증가아므로 score는 작아짐
- 시간에 따라 줄어드는 score를 조정하기 위해 gravity라는 상수를 사용(예시: gravity = 1.8)
Reddit Formula
- 실제 레딧에서 사용하는 스코어
- 첫 번째 term: popularity
- 두 번째 term: 포스팅이 게시된 절대 시간
- 나중에 게시된 포스팅일수록 절대시간이 크기 때문에 더 높은 score를 가짐
- (log를 취하기 때문에) 첫 번째 vote에 대해 가장 높은 가치를 부여하며, vote가 늘어날수록 score의 증가 폭이 작아짐
- log를 취하여 vote의 폭발적인 증가 방지
Highly Rated
가장 높은 평점을 받은 영화 혹은 맛집을 추천
- 신뢰할 수 있는 평점인가?
- 평가의 개수가 충분한가?
Steam Rating Formula
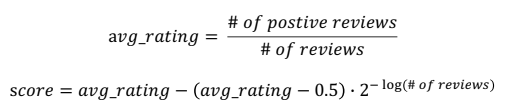
- rating은 평균값을 사용하되, 전체 review 개수에 따라 rating을 보정
- review의 수가 너무 적을 경우, 0.5(중간 값)보다 score가 낮을(or 높을) 경우 조금 높게(or 낮게) 보정
- review의 개수가 많아지면 항이 0에 가까워지므로 score는 평균 rating과 거의 유사해짐
연관 분석
개요
연관 규칙 분석
- 흔히 장바구니 분석 혹은 서열 분석이라고도 불림
- 주어진 transaction(거래) 데이터에 대해서, 하나의 상품이 등장했을 때 다른 상품이 같이 등장하는 규칙을 찾는 것
- 예시)
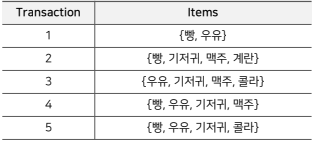
- 규칙- {기저귀} -> {맥주}
- {우유, 빵} -> {계란, 콜라}
- {맥주, 빵} -> {우유}
연관 규칙
연관 규칙과 Itemset
연관 규칙이란?
: 특정 사건이 발생했을 때 함께 빈번하게(frequently) 발생하는 또 다른 사건의 규칙을 의미
- IF (antecedent) THEN (consequent)
Itemset이란?
: antecedent와 consequent 각각을 구성하는 (1개 이상의)상품들의 집합
- antecedent와 consequent는 disjoint(서로소)를 만족한다.
- 다시 말해, 서로 겹치는 상품이 없어야 함
- ex) antecedent: {빵, 버터}, consequent: {우유}
- k-itemset: k개의 item으로 이루어진 itemset
반발 집합(Frequent Itemset)
support count()
: 전체 transaction data에서 특정 itemset이 등장하는 횟수
- ex) ({빵, 우유}) = 3
support
: itemset이 전체 transaction data에서 등장하는 비율
- ex) support({빵, 우유}) = 3/5 = 0.6
반발 집합(Frequent Itemset)
: 유저가 지정한 minimum support 값 이상의 itemset을 의미
- infrequent itemset은 반대로 유저가 지정한 minimum support보다 작은 itemset임
연관 규칙의 척도(평가지표)

support(지지도)
: 두 itemset X, Y를 모두 포함하는 transaction의 비율. 즉, 전체 transaction에 대한 itemset의 확률 값
- 좋은(빈도가 높거나, 구성 비율이 높은) 규칙을 찾거나 불필요한 연산을 줄일 때 사용됨.
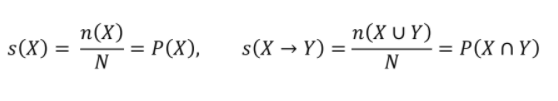
confidence(신뢰도)
: X가 포함된 transaction 가운데 Y도 포함하는 transaction 비율(X가 등장했을 때, Y가 등장할지에 대한 확률(조건부 확률))
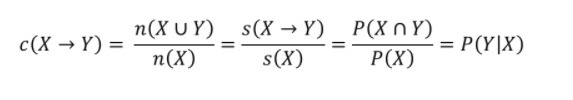
lift(향상도)
: 두 사건이 동시에 얼마나 발생하는지에 대한 비율(Y가 혼자 등장한 확률과 X->Y가 등장한 확률을 비교하여 X, Y 간 상관성을 측정)
- [X가 포함된 transaction 가운데 Y가 등장될 확률] / [Y가 등장할 확률]
- lift = 1 -> X, Y는 서로 독립
- lift > 1 -> X, Y는 양의 상관관계를 가짐 / lift < 1 -> X, Y가 음의 상관관계를 가짐
예시 - support, confidence, lift

연관 규칙 사용
- Item 수가 많아질수록, 가능한 itemset에 대한 rule의 수가 기하급수적으로 많아짐 -> 따라서 이 중 유의미한 rule만 사용해야 함
- 사용자가 지정한 minimum support, minimum confidence로 의미 없는 rule을 없앰
(전체 거래 중에서 너무 적게 등장하거나 조건부 확률이 아주 낮은 rule은 없앰) - lift 값으로 내림차순 정렬을 하여 의미 있는 rule을 평가함
(lift가 크다는 것은 rule을 구성하는 antecedent와 consequent가 연관성이 높고 유의미하다는 뜻임)- ex) 와인, 오프너, 생수가 있을 때
- c = P(오프너|와인) = 0.1 || c = P(생수|와인) = 0.2
-> 와인을 살 때 생수를 살 확률이 더 높아보이지만 - P(오프너) = 0.01 || P(생수) = 0.2 라고 한다면,
-> 와인을 샀을 때 오프너를 살 확률이 그냥 오프너를 살 확률의 10배가 나옴(높은 연관성을 띔)
- c = P(오프너|와인) = 0.1 || c = P(생수|와인) = 0.2
- ex) 와인, 오프너, 생수가 있을 때
연관 규칙의 탐색
: 주어진 transaction에서 모든 연관 규칙을 추출하는 것
Brute-force approach
- 가능한 모든 연관 규칙에 대해 support와 confidence를 계산
- minimum support/confidence를 만족하는 rule만 남기고 모두 가지치기
- (d: #of unique items)
-> M(아이템 수)로 인해 엄청나게 많은 계산량이 요구됨 !
Frequent Itemset Generation Strategies
: brute-force 방식의 문제점을 해결하고자 'minimum support 이상의 모든 itemset을 생성' 하는 부분의 cost를 줄이는 방법들
- Apriori 알고리즘: 가지치기를 활용하여 탐색해야 하는 M을 줄임
- 빈번하지 않은 아이템 셋은 하위 아이템셋 또한 빈번하지 않을 것이라고 가정
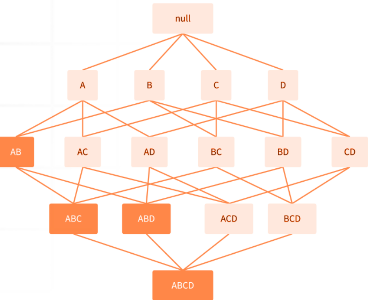
- 빈번하지 않은 아이템 셋은 하위 아이템셋 또한 빈번하지 않을 것이라고 가정
- DHP(Direct Hashing & Pruning) 알고리즘: itemset의 크기가 커짐에 따라 전체 N개 transaction보다 적은 개수를 탁색
- FP-Growth 알고리즘: 효율적인 자료구조(FP 트리)를 사용하여 후보 itemset과 transaction을 저장
- 모든 itemset과 transaction의 조합에 대해 탐색할 필요가 없음
컨텐츠 기반 추천
개요
컨텐츠 기반 추천이란?
: 유저 a가 관거에 선호한 아이템과 비슷한 아이템을 유저 a에게 추천
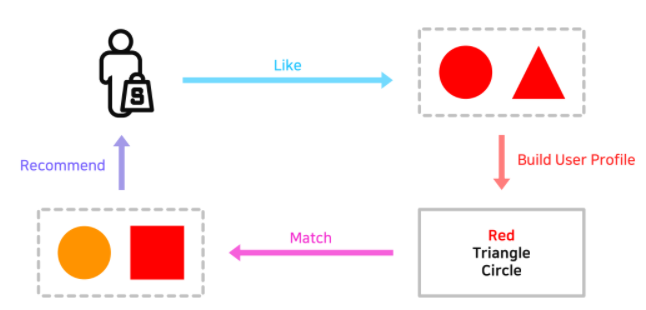
- 예시 - 비슷한 아이템 기준들)
- 영화: 배우, 감동, 영화 장르, ..
- 음악: 아티스트, 장르, 리듬, 무드, ...
- ...
컨텐츠 기반 추천의 장단점
장점
- 추천을 할 때 다른 유저의 데이터가 필요하지 않음
- (collaborative filtering에 비해)새로운 아이템 혹은 인기도가 낮은 아이템을 추천할 수 있음
- 추천 아이템에 대한 설명이 가능함(user profile을 만들기 때문에)
단점
- 아이템의 적합한 feature를 찾는 것이 어려움
- 한 분야/장르의 추천 결과만 계속해서 나올 수 있음
Item Profile
- 추천 대상이 되는 아이템의 feature들로 구성된 item profile을 만들어야 됨
- 아이템이 가진 다양한 feature를 Vector 형태로 표현
Item Profile: TF-IDF for Text Feature
: 단어에 대한 중요도를 나타내는 스코어
- 문서 d에 등장하는 단어 w에 대해서,
- 단어 w가 문서 d에 많이 등장하면서(Term Frequency, TF)
- 단어 w가 전체 문서(D)에서는 적게 등장하는 단어라면(Inverse Document Frequenct, IDF)
- 단어 w는 문서 d를 설명하는 중요한 feature로, TF-IDF 값이 높음!
TF-IDF Formula
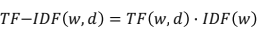
- TF: 단어 w가 문서 d에 등장하는 횟수

- IDF: 전체 문서 가운데 단어 w가 등장한 비율의 역수

- ex)
- TF
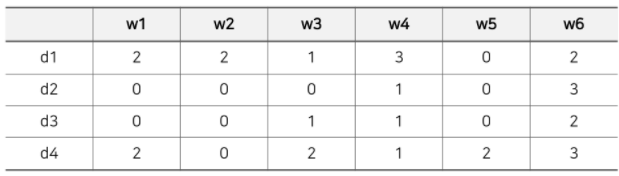
- TF-IDF
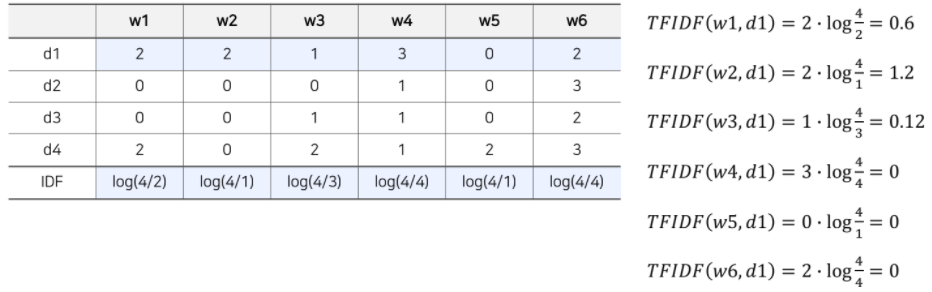
-> = (0.6, 1.2, 0.12, 0, 0, 0)
(문서 내 등장하는 단어의 개수가 총 6개인 경우, 문서를 표현하는 item profile vector는 6차원이 됨)
- TF
User Profile 기반 추천
User Profile
- 유저가 과거에 선호했던 item list가 있고, 개별 item은 TF-IDF를 통해 벡터로 표현됨.
- 각 유저의 item list 안에 있는 item의 Vector들을 통합하면 User Profile이 됨.
- 통합하는 방법
- simple: 유저가 선호한 item vector들의 평균값을 사용
- variant: 유저가 아이템에 내린 선호도로 정규화(normalize)한 평균값을 사용(가중 평균)
- 통합하는 방법
- ex) 유저가 d1, d3를 선호했다면,

Cosine 유사도
: 두 벡터의 각도를 이용하여 구할 수 있는 유사도(두 벡터의 차원이 같아야 함)
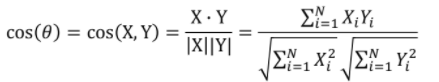
- 직관적으로 두 벡터가 가리키는 방향이 얼마나 유사한지를 의미
유저와 아이템 사이의 거리 계산(Cosine 유사도) : Ranking
- 코사인 유사도를 이용하여 유저 벡터u와 아이템 벡터 i에 대해서 다음과 같이 거리를 계산
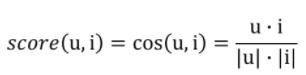
- 둘의 유사도가 클수록 해당 아이템이 유저에게 관련성이 높음
-> 따라서 유사도가 높은 아이템부터 유저에게 추천(Ranking)
Rating 예측
유저가 선호하는 아이템의 vactor를 활용하여 정확한 평점을 예측한다.
- (새로운 아이템)와 (과거 선호했던 아이템)에 속한 아이템의 유사도
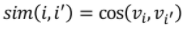
- 를 가중치로 사용하여 의 평점을 추론
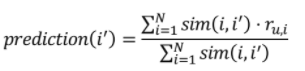
ex) 영화 평점 예측
- 특정 유저가 선호한 영화 3개가 있을 때
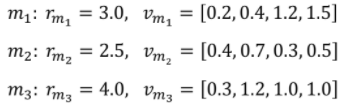
- 예측하려는 영화 의 = [0.4, 1.4, 3.1, 1.0] 이라면,
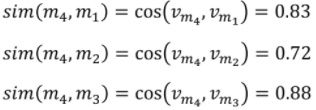
=>

