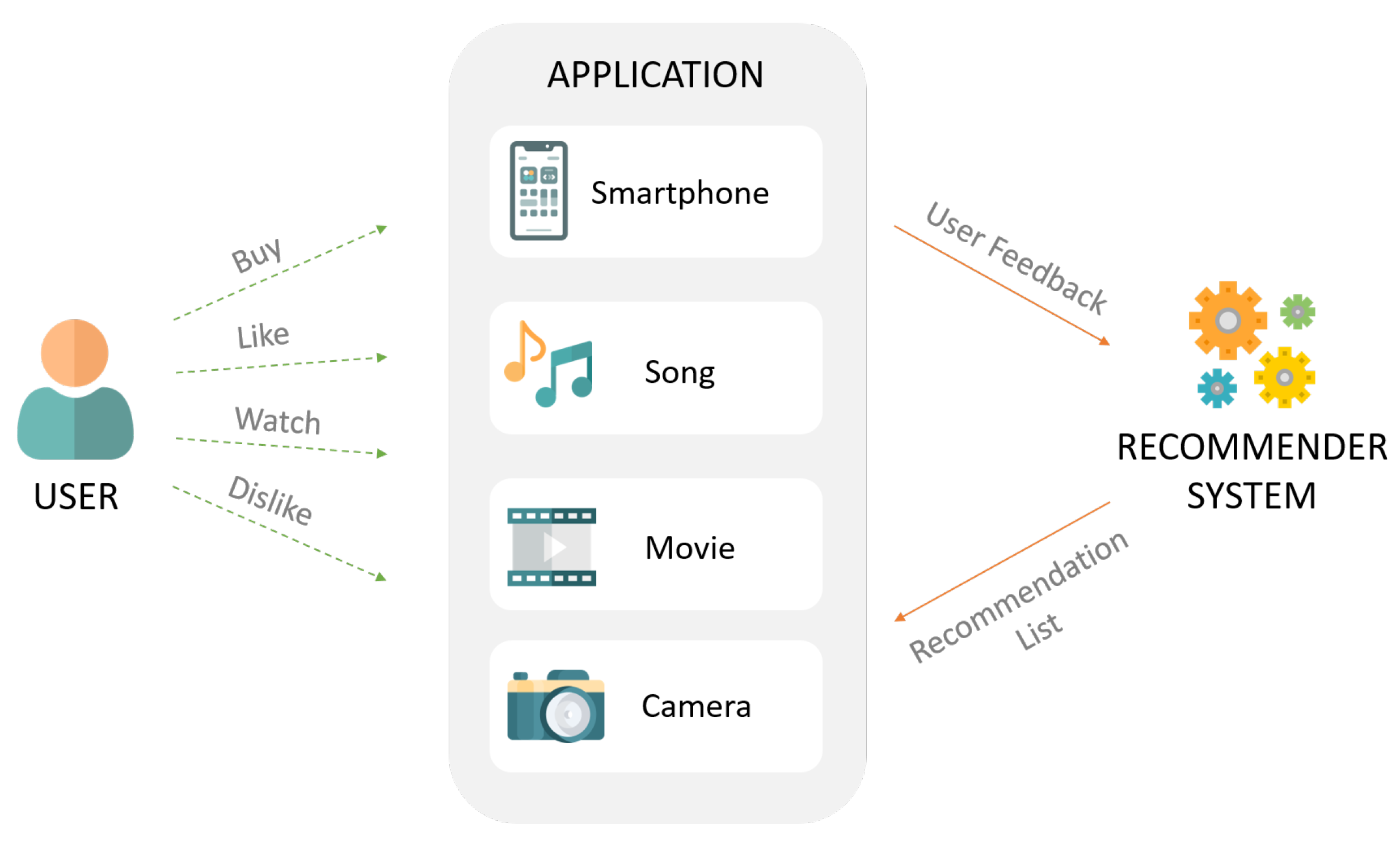
추천 시스템이란
개요
Search vs Recommendation
- Search: 사용자가 어떠한 의도를 가지고 찾는 것(pull)
- Recommend: 사용자가 어떤 의도를 갖지 않더라도 상품을 노출시키는 것(push)
추천시스템의 필요성
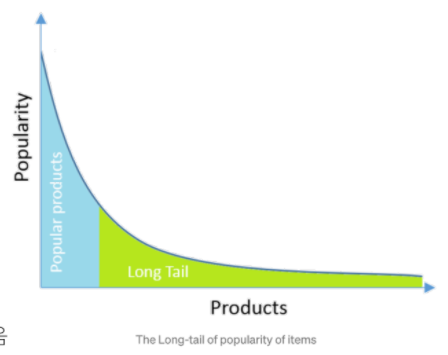
- 웹/모바일 환경은 다양한 상품, 컨텐츠를 등장하게 하였고, 이는 정보를 과다하게 생산해내고 있음
- 파레토 법칙(2080법칙)의 패러다임은 Long Tail Phenomenon으로 점점 바뀌어 감
-> 정보를 찾는데 시간이 너무 오래 걸리며, 유저가 원하는 걸 어떤 키워드로 찾아야 하는지 모를 수 있음
사용 데이터
추천 시스템에서 사용하는 정보
- 유저 관련 정보
- 아이템 관련 정보
- 유저-아이템 상호작용 정보
1. 유저 관련 정보
- 유저 프로파일링: 추천 대상 유저와 관련된 정보를 구축하여, 개별 유저 혹은 유저 그룹별로 추천
- 식별자(Identifier): 유저ID, 디바이스 ID, 브라우저 쿠키 등을 사용
- 데모그래픽 정보
- 성별, 연령, 지역, 관심사
- 데모그래픽 정보수집과 관련하여 많은 고민도 필요함
- 0자 데이터: 유저로부터 직접 받는 데이터
- 1자 데이터: 자사의 채널을 통해 데이터를 수집
- 2자 데이터: 다른 기업(타겟 층이 비슷한)과 데이터를 주고 받는 것
- 3자 데이터: 애드테크 기업 등이 발행하는 데이터(쿠키 등)
-> 숫자가 낮아질수록 데이터룰 구하기 어려워지지만, 품질은 좋아짐
- 유저 행동 정보
- 페이지 방문 기록, 아이템 평가, 구매 등의 피드백 기록
2. 아이템 관련 정보
- 추천 아이템의 종류: 도메인마다 다름
- 포탈: 뉴스, 블로그, 웹툰 등 콘텐츠 추천
- 미디어: 영화, 음악, 동영상 등을 추천
- 아이템 프로파일링(Item's Meta Data)
- 아이템 ID
- 아이템의 고유 정보(도메인마다 다름)
- EX) 영화: 장르, 출연 배우 및 감독, 개봉년도 등
3. 유저-아이템 상호작용 정보
- 유저와 아이템의 상호작용 데이터
- 유저 아이템과 상호작용 할 때 로그로 남음(체류 시간, 클릭 등)
- 이러한 데이터는 추천시스템을 학습하는 Feedback이 됨
- Explicit Feedback vs Implicit Feedback
- Explicit Feedback: 유저가 아이템에 대한 직접적인 피드백을 '준' 경우
- ex) 유저가 영화에 대한 평점을 남김
- Implicit Feedback: 유저가 아이템에 대한 간접적인 피드백을 '남긴' 경우
- ex) 유저가 a라는 영화를 시청함(평점은 남기지 않음)
- ex) 유저가 b라는 영화를 인지했지만, 보지 않고 지나침
- Explicit Feedback: 유저가 아이템에 대한 직접적인 피드백을 '준' 경우
추천 아이템이 풀어야 할 문제
랭킹(Ranking) 문제
- 유저에게 적합한 아이템 Top K개를 추천하는 문제
- Top K개를 선정하기 위한 기준 혹은 스코어는 필요하지만, 유저(x)가 아이템(y)에 가지는 정확한 선호도 값을 구할 필요는 없음.
(우선순위만 알 수 있다면(정량적 자료가 아닌 순서형 자료만 있다면), 아이템을 sorting하여 적합한 아이템 Top K개를 추천할 수 있음)
- Top K개를 선정하기 위한 기준 혹은 스코어는 필요하지만, 유저(x)가 아이템(y)에 가지는 정확한 선호도 값을 구할 필요는 없음.
- 평가 지표: Precision@K, Recall@K, MAP@K, nDCG@K
예측(Prediction) 문제
- 유저가 아이템을 가질 선호도를 정확하게 예측한는 문제(평점 or 클릭/구매확률 등)
- Explicit Feedback
- ex) x가 a라는 영화에 대해 내릴 평점 값을 예측
- Implicit Feedbaxk
- ex) x가 a라는 영화를 조회하거나 시청할 확률 값을 예측
- 유저-아이템 행렬을 채우는 문제
- Explicit Feedback
- 평가 지표: MAE, RMSE, AUC
추천 시스템의 평가지표
모델의 성능평가는 어떻게 해야하는가?
비즈니스/서비스 관점
- 추천 시스템 적용으로 인해 매출, PV의 증가
- 추천 아이템으로 인해 유저의 CTR의 상승
품질 관점
- 연관성: 추천된 아이템이 유저에게 관련이 있는가?
- 다양성: 추천된 Top-K 아이템에 얼마나 다양한 아이템이 추천되는가?
- 새로움: 얼마나 새로운 아이템이 추천되고 있는가?
- 참신함: 유저가 기대하지 못한 뜻밖에 아이템이 추천되는가?
offline Test
Offline Test란?
새로운 추천 모델을 검증하기 위해 가장 우선적으로 수행되는 단계
- 유저로부터 수집한 데이터를 train/valid/test로 나누어 모델의 성능을 객관적인 지표로 평가하는 것
- offline test와 online 서빙의 결과는 다를 수 있음(serving bias 존재)
성능 지표
- 랭킹 문제: Precision@K, Recall@K, MAP@K, nDCG@K, ...
- 예측 문제: MAE, RMSE, AUC, ...
Precision/Recall @K
쉽게 말해 분류에서의 precision, recall을 k개로 확장한 것
- Precision@K : 우리가 추천한 k개 아이템 가운데 실제 유저가 관심있는 아이템의 비율
- Recall@K : 유저가 관심있는 전체 아이템 가운데 우리가 추천한 아이템의 비율
- 예시)

Mean Average Precision(MAP) @K
Precision@K에서 한 단계 더 발전한 형태의 지표
- AP@K: (유저 하나에 대한) Precision@1부터 Precision@K 까지의 평균 값
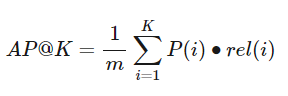
- Precision@K와 달리, 관련 아이템을 더 높은 순위에 추천할수록 점수가 상승함(순서가 반영됨)

- Precision@K와 달리, 관련 아이템을 더 높은 순위에 추천할수록 점수가 상승함(순서가 반영됨)
- MAP@K: 모든 유저에 대한 Average Precision 값의 평균
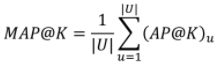
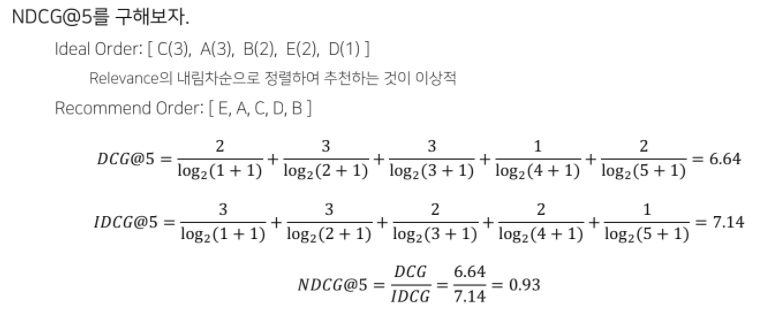
Normalized Discounted Cumulative Gain(NDCG)
추천 시스템에 가장 많이 사용되는 지표 중 하나(원래는 검색에서 등장한 지표임)
-
(공통점) Precision@K, MAP@K와 마찬가지로 Top K 리스트를 만들고 유저가 선호하는 아이템을 비교하여 값을 구함
-
(공통점) MAP@K와 마찬가지로 추천의 순서에 가중치를 두어 성능을 평가하며, 1에 가까울수록 좋음
-
(차이점) MAP와 달리, 연관성을 이진(binary)값이 아닌 수치로도 사용할 수 있기 때문에, 유저에게 얼마나 더 관련 있는 아이템을 상위로 노출시키는지 알 수 있음
- 순서별로 가중치 값(관련도)을 다르게 적용하여 계산
- 관련도: 사용자가 특정 아이템과 얼마나 관련이 있는지를 나타내는 값(관련도는 정해진 값이 아니라, 추천의 상황에 맞게 정해야하는 값임)(클릭여부, 잔류시간 등)
- 순서별로 가중치 값(관련도)을 다르게 적용하여 계산
-
NDCG Formula
- Cumulative Gain
: 상위 K개 아이템에 대하여 관련도를 합친 것(순서에 따라 Discount하지 않고 동일하게 더한 값)
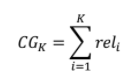
- Discounted Cumulative Gain
: 순서에 따라 Cumulative Gain을 Discount 함
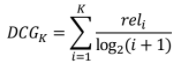
- Ideal DCG
: 이상적인 추천이 일어났을 때의 DCG값(가능한 DCG 값 중 가장 큰 값)
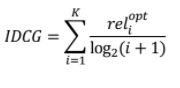
- Normalized DCG
: 추천 결과에 따라 구해진 DCG를 IDCG로 나눈 값
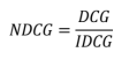
- Cumulative Gain
-
NDCG 예시
그 외(accuracy 외) 성능 지표
-
Coverage
: 전체 사용자 및 아이템 중에서 추천시스템이 놓치고 있는 부분이 없는지를 판단- 전체 사용자 및 아이템 중에서 한 번이라도 추천 결과가 생성된 사용자 또는 추천 결과에 포함된 아이템의 비율을 의미
- ex) 총 50 개의 아이템 카탈로그 중 추천 결과에 포함된 아이템의 개수가 30 이라면,
item-space coverage = 30/50 = 0.6 - accuracy와 coverage는 Trade-Off 관계임.
-
Confidence & Trust
: Confidence는 추천 결과를 제공하는 시스템의 신뢰성을 의미- 예측된 평균값이 같더라도 표준편차가 더 적으면, 더 높은 confidence 값을 가짐
: Trust는 사용자가 추천 결과에 대해 가지고 있는 믿음을 의미
- 사용자가 좋아했던 아이템을 다시 추천하는 것은 새로움 측면에서는 유용하지 않을지는 몰라도 trust를 증가시키는 효과가 있다
-
Novelty
: 사용자가 알지 못하거나 이전에 본 적이 없는 새로운 추천을 사용자에게 제공할 가능성을 의미- Novelty가 높은 추천은 종종 사용자가 이전에는 알지 못했던 취향에 대한 새로운 발견을 제공한다.
-
Serendipity
: "lucky discovery". 성공적인 추천 결과로부터 사용자가 느끼는 놀라움(unexpectedness)의 정도를 의미- Serendipity = novelty + relevance + unexpectedness
- ex) Spotify's "Discover Weekly"
-
Diversity
: 추천 결과가 얼마나 다양한 아이템들로 이루어졌는지를 의미 -
Robustness & Stability
: 추천시스템에 가해질 수 있는 적대적인 공격(fake ratings, ...)에 대한 견고함과 안정성을 평가하는 기준 -
Scalability
: 추천시스템이 대용량 데이터 및 트래픽을 효과적이고 효율ㅈ거으로 처리할 수 있는지를 평가- training time, inference time, memory requirements, ...
Online Test
Online Test란
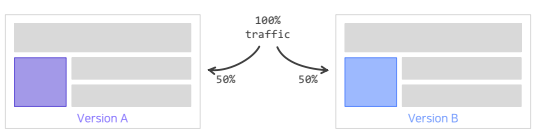
Offline Test에서 검증된 가설이나 모델을 이용해 실제 추천 결과를 서빙하는 단계
- 추천 시스템 변경 전/후의 성능을 비교하는 것이 아니라, 동시에 대조군(A)과 실험군(B)의 성능을 평가(A-B테스트)
(대조군과 실험군의 환경은 최대한 동일해야 함(외생변수를 최대한 제거)) - 실제 서비스를 통해 얻어지는 결과를 통해 최종 의사결정이 이루어짐
- 지표: 모델 성능이 아닌 매출, CTR 등의 비즈니스/서비스 지표
- 지표: 모델 성능이 아닌 매출, CTR 등의 비즈니스/서비스 지표
추천 시스템 기법(개요)
1. RecSys Basic
- 인기도 기반
- 연관 분석
- 콘텐츠 기반(TF-IDF)
2. Collaborative Filtering(1)
- Collaborative Filtering(CF)
- Similarity Function
- Neighborhood-based CF
- K-Nearest Neighbors CF
- Rating Prediction
- UBCF, IBCF, Top-N Recommendation
3. Collaborative Filtering(2)
- Model Based Collaborative Filtering(MBCF)
- Singular Value Decomposition(SVD)
- Matrix Factorization(MF)
- MF for Implicit Feedback
- Bayesian Personalized Ranking(BPR)
4. Item2Vec Recommendation and ANN
- Word2Vec
- Item2Vec
- Approximate Nearest Neighbor(ANN)
5. Deep Learning-based Recommendation(1)
- Recommender System with DL
- Recommender System with MLP
- Recommender System with AE(Auto-Encoder)
6. Deep Learning-based Recommendation(2)
- Recommender System with GNN(Graph Neural Network)
- Recommender System with RNN(Recurrent Neural Network)
7. Context-aware Recommendation
- What is Context-aware Recommendation
- Factorization Machine(FM)
- Field-aware Factorization Machine(FFM)
- Gradient Boosting Machine(GBM)
- 부록
: General Predictor, FM의 시간 복잡도, GBM 계열 모델과 타 모델 간 성능 비교, XGBoost, LightGBM, CatBoost
8. DeepCTR
- CTR Prediction with Deep Learning
- Wide & Deep
- DeepFM
- Deep Interest Network
- Behavior Sequence Transformer(BST)
9. Multi-Armed Bandit(MAB)-based Recommendation
- Multi-Armed Bandit(MAB)
- MAB 알고리즘 - 기초
- MAB 알고리즘 - 심화
