[boostcamp-ai-tech][RecSys] RecSys with DL(2) Neural Graph Collaborative Filtering, LightGCN, GRU4Rec
RecSys
Recommender System with GNN
(GNN에 대한 기초는 다음 글에서 더 자세히 설명하였습니다.)
Graph Neural Network
- Graph
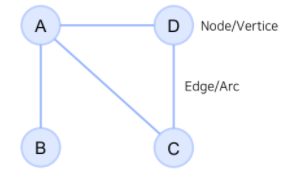
- 꼭지점(Node)들과 그 노드를 잇는 변(Edge)들을 모아 구성한 자료구조
- 그래프 표시 예시
G = ({A,B,C,D}, {{A,B},{A,C},{A,D},{C,D}})
- Graph를 사용하는 이유
- 관계, 상호작용과 같은 추상적인 개념을 다루기에 적합
- 복잡한 문제를 더 간단한 표현으로 단순화
- 소셜 네트워크, 바이러스 확산, 유저-아이템 소비 관계 등을 모델링 가능
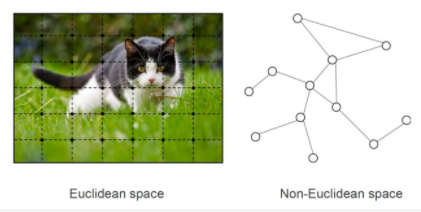
- Non-Euclidean Space의 표현 및 학습이 가능
- 우리가 흔히 다루는 이미지, 텍스트, 정형 데이터는 격자 형태로 표현 가능하지만,
- SNS 데이터, 분자(molecule) 데이터 등은 Non-Euclidean Space임.
- 관계, 상호작용과 같은 추상적인 개념을 다루기에 적합
GNN & GCN
Graph Neural Network (GNN)
- 그래프 데이터에 적용 가능한 신경망
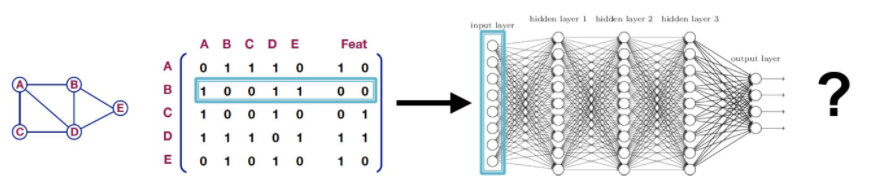
- 데이터를 그래프로 표현하는 아주 기본적인 접근법으로는, 그래프 및 피쳐 데이터를 인접 행렬로 변환하여 MLP에 사용하는 방법 등이 있음(Naive Approach)
-> 이러한 형태의 변환은 다음과 같은 단점이 존재- 노드가 많아질수록 연산량이 기하급수적으로 많아짐
- Graph에서 순서는 사실상 의미가 없지만, Naive Approach에서는 노드의 순서가 바뀌면 의미가 달라질 수 있음
Graph Convolution Network (GCN)
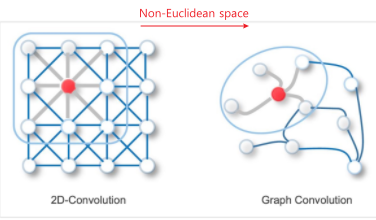
- 우리가 알고 있는 CNN에서의 Convolution 개념을 GNN에 적용한 것
- Local Connectivity, Shared Weights, Multi-Layer를 이용하여 Convolution 효과를 만들면, 연산량을 줄이면서 깊은 네트워크로 간접적인 관계 특징까지 추출 가능
- Local connectivity: 2D-Convolution에서 Filter는 Local Connectivity를 학습(노드 간 관계 특징을 추출)
- Shared Weights: 2D-Convolution에서 Filter를 통해 같은 weight를 공유하는 것과 같음
- Multi-Layer: Layer를 여러 층 쌓는 것. 이전 Layer에서 추출된 임베딩 값을 Input으로 사용함으로써 간접적인 관계 특징까지 추출
Neural Graph Collaborative Filtering (NGCF)
- 유저-아이템 상호적용을 GNN으로 임베딩 과정에서 인코딩하는 접근법을 제시한 논문
- 논문
NGCF 등장 배경
-
기존 CF 모델에서의 키 포인트
- 유저와 아이템의 임베딩
- ex) one-hot encoding -> dense한 enbedding으로 학습
- 상호작용 모델링
- ex) Matrix Factorization에서는 임베딩된 유저-아이템을 내적하여 유저-아이템의 상호작용을 linear하게 표현
--> 기존 CF 모델들은 유저와 아이템 정보를 각각 임베딩 한 후 연산하므로(임베딩과 상호작용이 분리되어 있으므로) 부정확한 추천이 될 수 있음.
(sub-optimal(정보의 누락이 있는)한 임베딩을 사용하여 상호작용하므로 문제 발생)NGCF 기본 아이디어
: Collaborative Signal
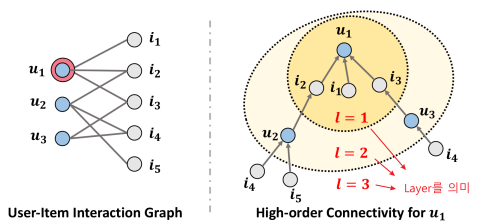
- 유저-아이템의 상호작용이 임베딩 단계에서부터 학습될 수 있도록 접근
- 그러나, 유저/아이템 개수가 많아질수록 모든 상호작용을 표현하기엔 한계가 존재(위 그림에서 좌측)
- -> GNN을 통해 High-order Connectivity를 임베딩(경로가 1보다 큰 연결)
- 그림(우측)에서 알 수 있는 것(1개의 노드()을 기준으로)
- 과 는 를 똑같이 소비했으므로, 둘은 유사성이 존재
- 가 소비한 , 의 시그널이 전달되어서 에 도달할 수 있기 때문에 이들을 에 추천해줄 수 있음
- 가 소비한 의 시그널 또한 에 도달함.
의 시그널은 에 두 번 전달되었으므로 추천해줄 확률이 더 올라갈 것임.
- 그림(우측)에서 알 수 있는 것(1개의 노드()을 기준으로)
- 유저와 아이템의 임베딩
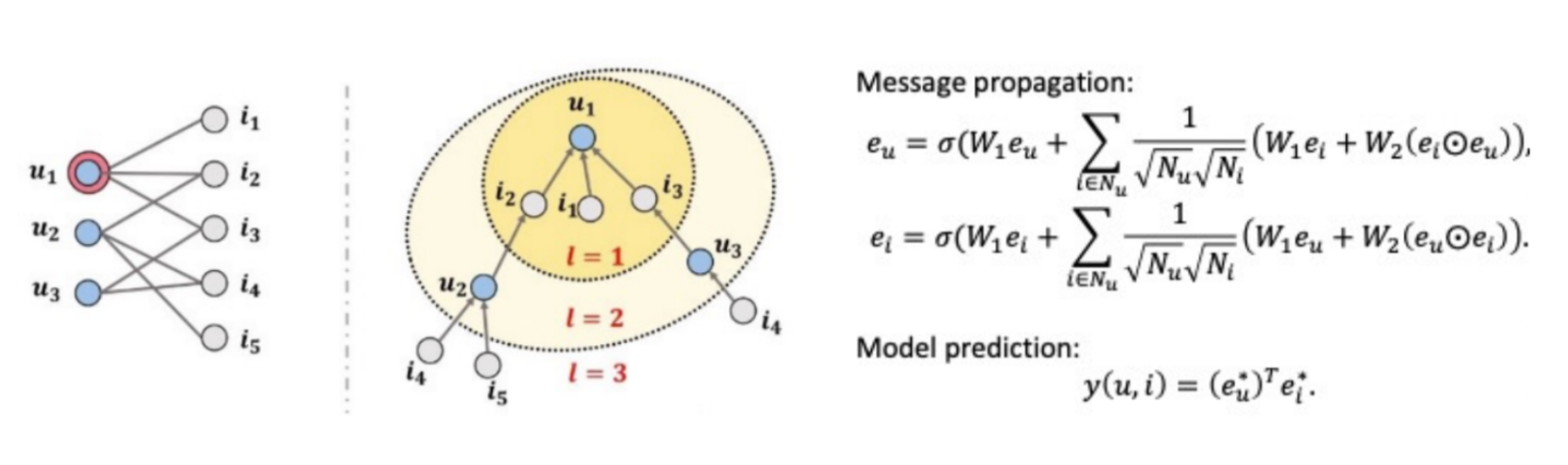
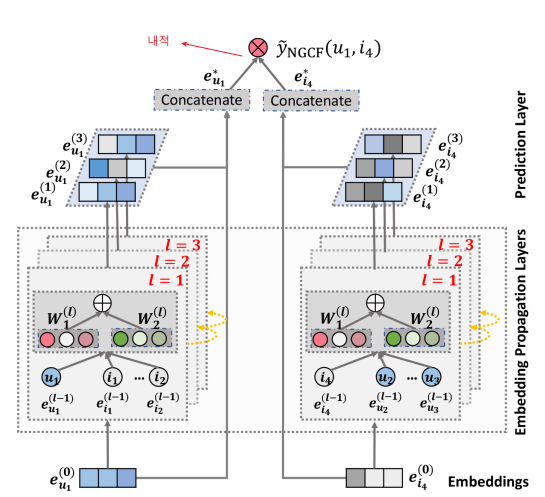
NGCF 전체 구조
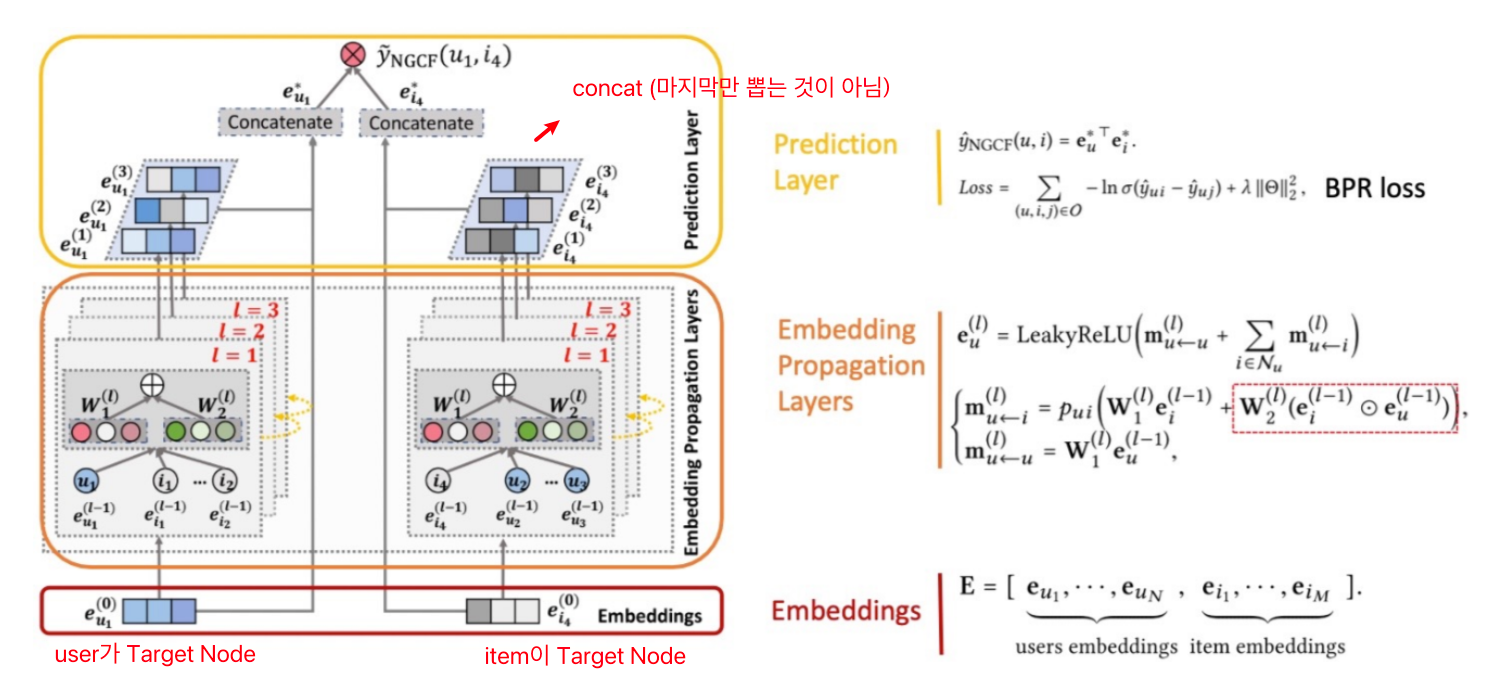
- 임베딩 레이어
: 유저-아이템의 초기 임베딩을 제공 - 임베딩 전파 레이어(Embedding Propagation Layer)
: high-order connectivity 학습 - 유저-아이템 선호도 예측 레이어(Prediction Layer)
: 서로 다른 전파 레이어에서 refine된 임베딩들을 concat
-(concat)->
NGCF 상세 구조
임베딩 레이어

- 기존 Collaborative Filtering과의 비교
- 기존의 MF, Neural CF 모델 등에서는 임베딩이 곧바로 interaction function에 입력됨.
- NGCF에서는 이 임베딩을 GNN 상에서 전파시켜 'refine' 함
- 즉, 임베딩 레이어는 임베딩 전파 레이어를 위해 '초기 임베딩'을 생성하는 단계임
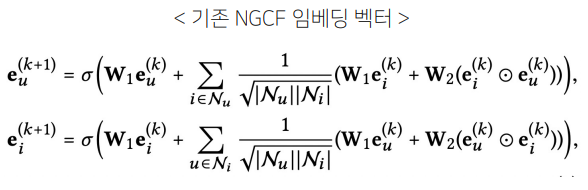
임베딩 전파 레이어
: 유저-아이템의 collaborative signal을 담을 'message'를 구성하고 결합하는 단계
-
Message Construction
: 유저-아이템 간 affinity를 고려할 수 있도록 메세지를 구성(weight sharing)
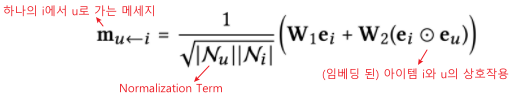
- normalization Term: 유저u를 기준으로 연결되는 아이템이 점점 많아질수록 signal은 계속해서 커지기 때문에 normalization 시킴.(개별 메세지의 크기를 이웃한 노드의 개수로 나눠줌)
- : Weight matrix / : element-wise product /
: 유저, 아이템의 이웃한 유저, 아이템 집합
-
Message Aggregation
: 의 이웃 노드로부터 전파된 message들을 결합하면, 1-hop 전파를 통한 임베딩 완료

-
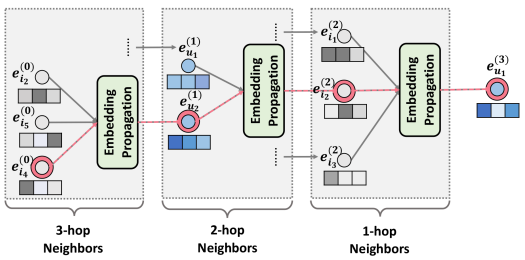
개의 임베딩 전파 레이어를 쌓으면, 유저 노드는 거리만큼 떨어진 이웃으로부터 전파된 메세지 이용 가능(-hop neighbor)
- 단계에서 유저 의 임베딩은 (-1)단계의 임베딩을 통해 재귀적으로 형성됨.(Higher-order propagation)
- 위 식들을 일반화 한 수식( 단계의 임베딩) :

선호도 예측 레이어
: 차까지의 임베딩 벡터를 Concatenate하여 최종 임베딩 벡터를 계산한 후, 유저-아이템 벡터를 내적하여 최종 선호도 예측값 계산(마지막만 뽑는 것이 아님).
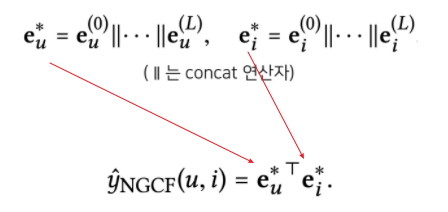
NGCF Summary
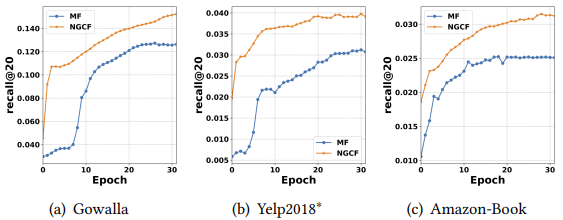
결과
- 임베딩 전파 레이어가 많아질수록 모델의 추천 성능 향상
- 다만 너무 많이 쌓이면 overfitting 발생 가능
- 실험 결과, 대략 = 3~4일 때 가장 좋은 성능을 보임
- MF보다 더 빠르게 수렴하고, recall도 높음
- (Mpdel Capacity가 크기 임베딩 전파를 통해 representation power가 좋아졌기 때문)
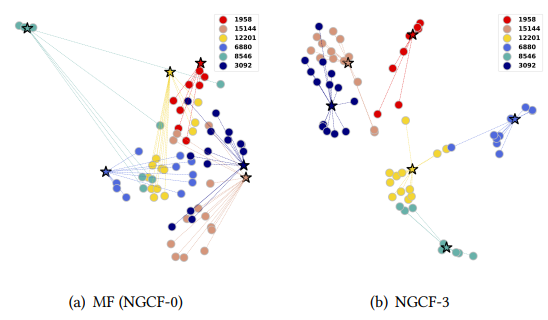
- (Mpdel Capacity가 크기 임베딩 전파를 통해 representation power가 좋아졌기 때문)
LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation
- GCN의 가장 핵심적인 부분만 사용하여, 더 정확하고 가벼운 추천 모델을 제시한 논문
- 논문
LightGCN 아이디어
-
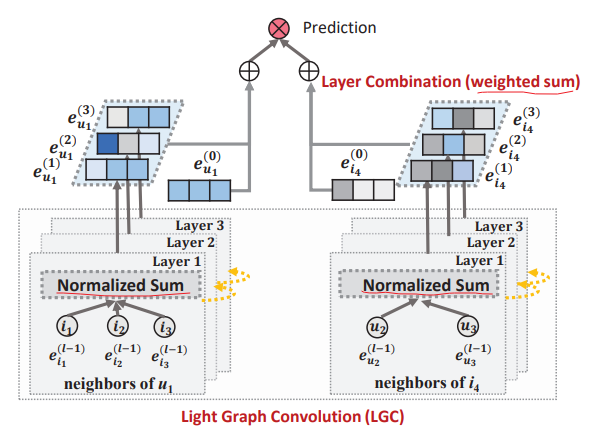
Light Graph Convolution
: 이웃 노드의 임베딩을 가중합 하는 것이 convolution의 전부임 -> 학습 파라미터와 연산량이 감소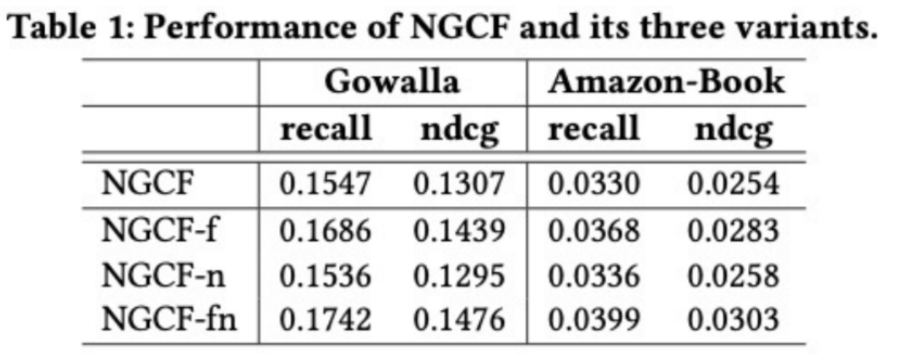
- NGCF-f: feature transformation 제거
- NGCF-n: non-linear activation function 제거
- NGCF-fn: feature transformation과 non-linear activation function 둘 다 제거
-> 논문에서는 실험 결과, non-linear activation만 제거하는 것은 성능에 큰 영향이 없었으나, feature transformation과 non-linear activation function을 둘 다 제거하면 성능이 크게 향상된다고 말함.
-
Layer Combination
: 레이어가 깊어질수록 강도가 약해질 것이라는 아이디어를 적용해 모델을 단순화(즉, Concat 하지 않고 Weighted Sum)
모델 구조(LightGCN, NGCF)
- 기존 NGCF
- LightGCN
LightGCN Propagation Rule
: feature transformation이나 non-linear activation을 제거하고 가중합으로 GCN 적용
- 연결된 노드만 사용했기 때문에 self-connection이 없음
- 학습 파라미터는 0번째 임베딩 레이어에서만 존재

LightGCN Model Prediction
: -층으로 된 레이어의 임베딩을 각각 배 하여 가중합으로 최종 임베딩 벡터 계산
- 는 -층 임베딩 벡터의 가중치로, 하이퍼파라미터 혹은 학습 파라미터 둘 다 가능 (별 차이는 없음).
(논문에선 사용 -> Layer가 깊어질수록 가중치는 점점 작아짐).


결과 및 요약
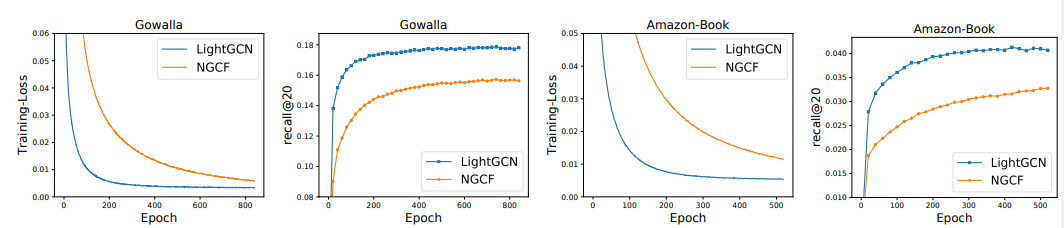
- 학습을 통한 손실 함수와 추천 성능 모두 NGCF모다 뛰어남
-> Generalization 성능이 높음 - 현재 Naver와 와챠 등에서도 활발히 사용되고 있음.
Recommender System with RNN
RNN과 추천시스템
- Session based Recommender System
: 고객의 선호는 고정된 것이 아님.
-> '지금' 고객이 좋아하는 것은 무엇인가?- 유저가 서비스를 이용하는 동안의 행동을 기록한 데이터인 Session을 통해 시퀀스를 파악(쿠키 데이터 등)
GRU4Rec
- '지금' 고객이 원하는 상품을 추천하는 것을 목표로, 추천시스템에 RNN을 적용한 논문
- 논문
GRU4Rec 아이디어
: Session이라는 시퀀스를 GRU레이어에 입력하여 바로 다음에 올 확률이 가장 높은 아이템을 추천
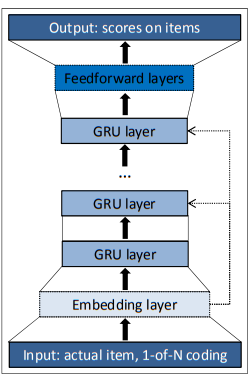
- GRU(Gated Recurrent Unit): LSTM의 변형 중 하나로, 출력 게이트가 따로 없어 파라미터와 연산량이 더 적은 모델
GRU4Rec 상세
구조
- 입력: one-hot encoding된 session
- GRU 레이어: 시퀀스 상 모든 아이템에 대한 맥락적 관계 학습
- 출력: 다음에 골라질 아이템에 대한 선호도 스코어
학습: Session Parallel Mini batches
- 세션들의 길이가 다 다르다는 문제가 있음.
- 길이가 짧은 세션들이 단독 사용되어 idle하지 않도록, 세션을 병렬적으로 구성하여 미니배치 학습
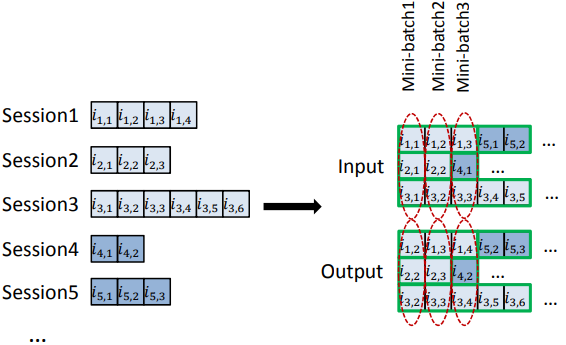
학습: Sampling on the output
-
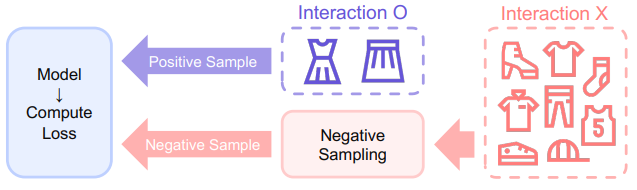
현실에서는 아이템의 수가 많기 때문에 모든 후보 아이템의 확률을 계산하기 어려움.
-> 따라서, 아이템을 negative sampling하여 subset만으로 loss를 계산 -
사용자가 상호작용을 하지 않은 아이템은 존재 자체를 몰랐거나 관심이 없는 것(둘 중 어느 것인가?)
-> 만약, 아이템의 인기가 높은데도 상호작용이 없었다면, 사용자가 관심이 없는 아이템이라고 가정
-> 인기에 기반한 Negative Sampling
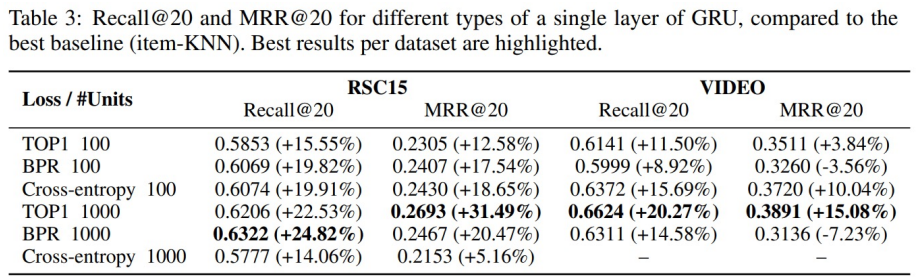
결과 및 요약
- RSC15와 VIDEO 데이터셋에서 가장 좋은 성능을 보인 item-KNN 모델 대비 약 20% 높은 추천 성능을 보여줌
- GRU 레이어의 hidden unit이 클 때 더 좋은 추천 성능을 보임