추천 시스템
1.[추천 시스템] @K

추천 시스템의 랭킹 기반 평가에서 '@K'는 자주 등장하는 개념이다. '@K'는 추천한 아이템의 개수를 의미한다. 예를 들어 '@3'라고 표현하면, 이는 추천 시스템이 추천한 아이템 상위 3개를 가리킨다. 왜 상위일까? 추천 시스템은 당연히 사용자에게 상호작용할 확률이
2.[추천 시스템] Hit Rate@K

Hit Rate@K 는 추천 시스템의 성능을 평가하기 위해 사용되는 지표 중 하나이다. 이 지표는 사용자가 관심을 가질 만한 항목이 추천 리스트의 상위 K개 항목에 포함되어 있는지를 측정한다. Hit Rate는 사용자가 실제로 관심을 보인 항목이 추천 리스트에 포함되는
3.[추천 시스템] Precision@K

Precision@K는 추천 시스템의 성능을 평가하기 위해 사용되는 지표로, 추천된 상위 K개의 항목 중 실제로 사용자가 관심을 가진 항목의 비율을 측정한다. 추천 시스템에서 Precision@K는 "추천 시스템이 추천한 아이템 K개 중 실제 사용자가 관심 있는 아이템
4.[추천 시스템] Recall@K

Recall@K는 추천 시스템의 성능을 평가하기 위한 지표로, 사용자가 관심을 가진 항목들 중에서 추천된 상위 K개의 항목에 포함된 비율을 측정한다. Recall@K는 추천 시스템이 사용자가 관심을 가진 항목을 얼마나 잘 포착하는지 평가하는 데 사용된다. Precisi
5.[추천 시스템] MAP

Mean Average Precision (MAP)은 정보 검색 및 추천 시스템의 성능을 평가하는 데 사용되는 중요한 지표이다. MAP는 여러 쿼리나 사용자의 검색 결과에 대해 평균적인 정밀도를 계산하여 전체 시스템의 성능을 평가한다. 이는 특히 다수의 검색 쿼리나 추
6.[추천 시스템] NDCG

NDCG는 랭킹 추천 시스템에서 많이 사용되는 평가 지표로, 기존 정보 검색에서 널리 사용되던 지표이다. 이 지표는 랭킹 리스트의 정확성을 평가하며, 특히 더 관심 있거나 관련성이 높은 아이템을 얼마나 잘 포함하고 있는지 평가한다. 예를 들어, 검색창에 10개의 아이템
7.[추천 시스템] 협업 필터링이란?
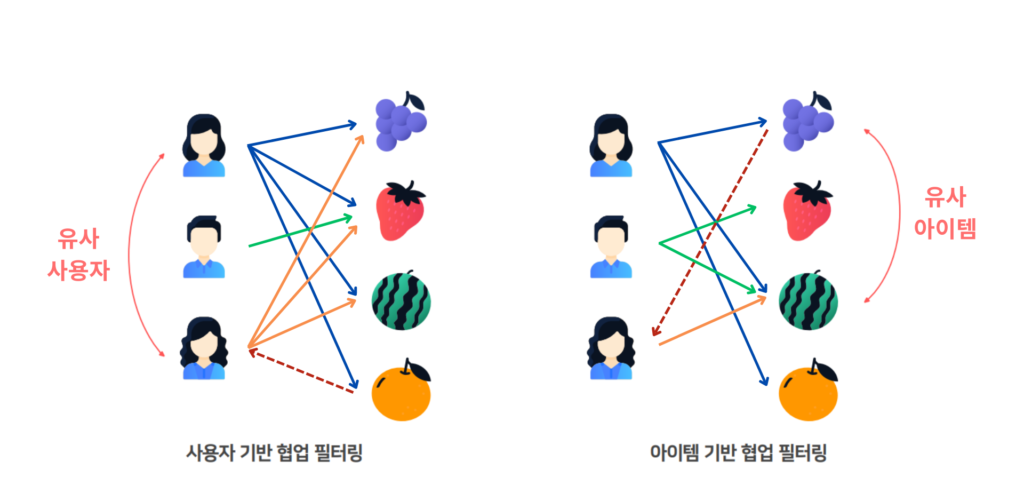
이번 글에서는 추천 시스템에서 자주 사용되는 협업 필터링(Collaborative Filtering)에 대해 이야기해보려고 합니다. 넷플릭스에서 영화를 추천받거나 쿠팡에서 쇼핑할 때 "이거 너 좋아할 것 같은데?"라는 느낌으로 제안이 오곤 합니다. 그 배경에는 바로 협
8.[추천 시스템] MovieLens 데이터셋으로 추천 시스템 기초 다지기
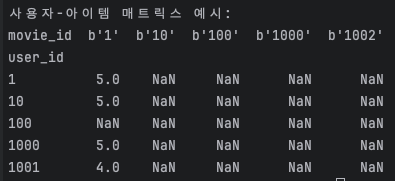
추천 시스템을 만들기 위해서는 먼저 데이터가 필요합니다. 이번 글에서는 MovieLens 데이터셋을 활용해 추천 시스템의 기본적인 흐름을 이해해보려고 합니다. 이 데이터셋은 사용자들이 영화에 매긴 평점을 모아놓은 것으로, 추천 시스템을 연습하기에 아주 좋은 자료입니다.
9.[추천 시스템] KNN(K-Nearest Neighbors) 알고리즘과 추천 시스템
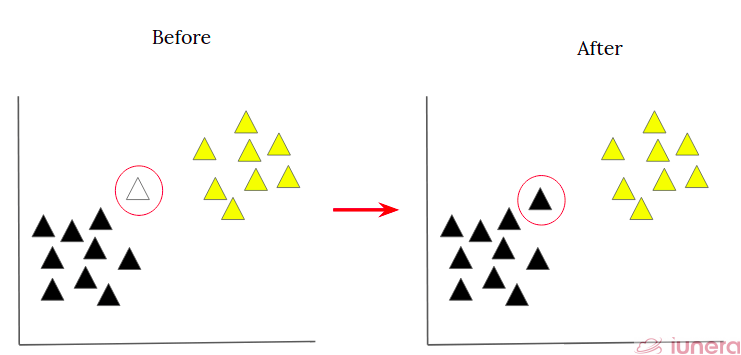
이번 글에서는 추천 시스템의 핵심 알고리즘 중 하나인 KNN(K-Nearest Neighbors)에 대해 알아보겠습니다.KNN은 "가장 가까운 이웃 K명을 찾아 그들의 정보를 활용한다"는 직관적인 머신 러닝 알고리즘입니다. KNN은 인스턴스 기반 학습 또는 lazy l
10.[추천 시스템] 코사인 유사도
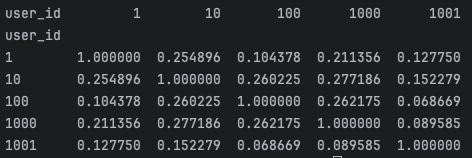
이전 단계에서 MovieLens 데이터셋을 불러와 사용자-아이템 매트릭스를 만드는 과정을 살펴봤습니다. 이제 이 매트릭스를 활용해 추천 시스템을 한 단계 더 발전시켜볼 건데, 여기서 중요한 개념이 바로 코사인 유사도입니다. 이번 글에서는 코사인 유사도가 무엇인지, 왜
11.[추천 시스템] MSD 유사도
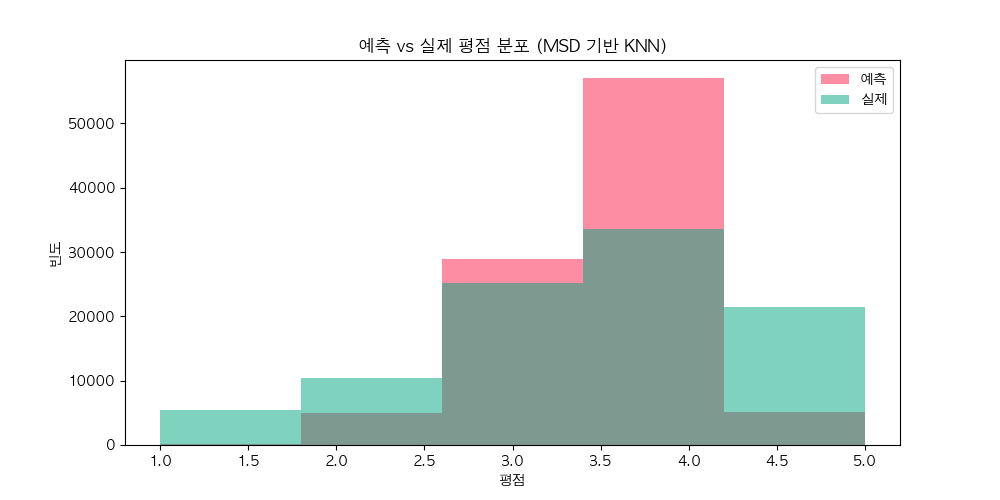
이전 글에서 MovieLens 데이터셋을 사용해 사용자-아이템 매트릭스를 만들고, 코사인 유사도를 활용해 사용자 간 유사성을 계산하는 과정을 살펴봤습니다. 이번 글에서는 또 다른 강력한 유사도 메트릭인 Mean Squared Difference (MSD)를 소개하려고