이전 글에서 MovieLens 데이터셋을 사용해 사용자-아이템 매트릭스를 만들고, 코사인 유사도를 활용해 사용자 간 유사성을 계산하는 과정을 살펴봤습니다. 이번 글에서는 또 다른 강력한 유사도 메트릭인 Mean Squared Difference (MSD)를 소개하려고 합니다. MSD가 무엇인지, 추천 시스템에서 왜 유용한지, 그리고 이를 코드로 구현하는 방법을 예시와 함께 알아보겠습니다.
1. MSD란?
MSD(Mean Squared Difference)는 두 사용자 또는 두 아이템 간 평점 차이를 기반으로 유사성을 측정하는 간단하면서도 효과적인 메트릭입니다. MSD는 두 벡터 간 평점 차이의 제곱 평균을 계산한 뒤, 이를 유사도로 변환합니다. 수학적으로 MSD는 아래 이미지와 같은 공식으로 정의됩니다.
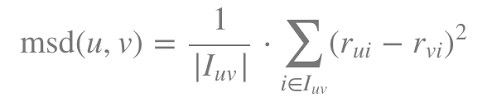
- u, v : 두 사용자.
- I_{uv} : 두 사용자가 모두 평점을 준 아이템 집합.
- r{ui}, r{vi} : 사용자 (u)와 (v)가 아이템 (i)에 준 평점.
- |I_{uv}| : 공통으로 평점을 준 아이템 수.
MSD 값이 작을수록 두 사용자의 평점 패턴이 비슷하다는 뜻입니다.
2. 추천 시스템에서 MSD를 사용하는 이유
사용자-아이템 매트릭스는 매우 희소하기 때문에, 공통 평점이 적은 사용자 쌍의 유사도를 계산하는 데 어려움이 있습니다.
MSD는 다음과 같은 이유로 추천 시스템에서 널리 사용됩니다.
- 직관적이고 간단: MSD는 평점 차이의 제곱 평균을 계산하므로 이해와 구현이 쉽습니다.
- 희소 데이터에 안정적: 코사인 유사도는 벡터의 노름이 0이 되면 계산이 실패할 수 있지만, MSD는 공통 평점이 있는 경우에만 계산하므로 0으로 나누기 문제가 없습니다.
- 효율성: surprise 라이브러리와 같은 도구를 사용하면 대규모 데이터에서도 빠르게 계산 가능합니다.
- 평점 차이에 민감: MSD는 평점 값의 차이를 직접적으로 반영하므로, 사용자 간 평점 패턴의 미세한 차이를 잘 포착합니다.
예를 들어, 사용자 A가 영화 1에 5점, 영화 2에 4점을 주고, 사용자 B가 영화 1에 4.8점, 영화 2에 4.2점을 줬다면, MSD는 두 평점 차이의 제곱 평균(작은 값)을 계산해 이들이 매우 유사한 취향임을 나타냅니다.
3. MSD 적용
이제 MovieLens 데이터셋을 사용해 MSD를 계산하고, 이를 기반으로 KNN 추천 시스템을 구현하는 과정을 코드로 살펴보겠습니다. MSD는 surprise 라이브러리에서 기본적으로 지원하는 유사도 메트릭이므로, 이를 활용해 사용자 간 유사도를 계산하고 평점을 예측해 보겠습니다.
import pandas as pd
from datasets import load_dataset
from surprise import Dataset, Reader, KNNBasic
from surprise.model_selection import train_test_split
from surprise import accuracy
import matplotlib.pyplot as plt
# 한글 폰트 설정 (macOS에서 AppleGothic 사용)
plt.rcParams['font.family'] = 'AppleGothic'
plt.rcParams['axes.unicode_minus'] = False
# MovieLens 데이터셋 로드 (50만 개 샘플 사용)
data = load_dataset("nbtpj/movielens-1m-ratings")["train"].shuffle(seed=10).select(range(500000))
movielens_df = pd.DataFrame(data)[["user_id", "movie_id", "user_rating"]]
# 사용자와 영화 필터링 (최소 평점 수 기준)
min_user_ratings = 20
min_movie_ratings = 10
user_counts = movielens_df['user_id'].value_counts()
movie_counts = movielens_df['movie_id'].value_counts()
filtered_df = movielens_df[
movielens_df['user_id'].isin(user_counts[user_counts >= min_user_ratings].index) &
movielens_df['movie_id'].isin(movie_counts[movie_counts >= min_movie_ratings].index)
].copy()
# Surprise 데이터셋 준비
reader = Reader(rating_scale=(1, 5))
dataset = Dataset.load_from_df(filtered_df[['user_id', 'movie_id', 'user_rating']], reader)
train_data, test_data = train_test_split(dataset, test_size=0.2, random_state=10)
# MSD 기반 KNN 모델 설정
sim_options = {
"name": "msd", # Mean Squared Difference
"user_based": True, # 사용자 기반 추천
"min_support": 5 # 최소 공통 평점 수
}
algo = KNNBasic(k=20, sim_options=sim_options)
# 모델 학습
algo.fit(train_data)
# 예측 및 평가
predictions = algo.test(test_data)
rmse = accuracy.rmse(predictions)
print(f"MSD 기반 KNN RMSE: {rmse}")
# 예측 vs 실제 평점 시각화
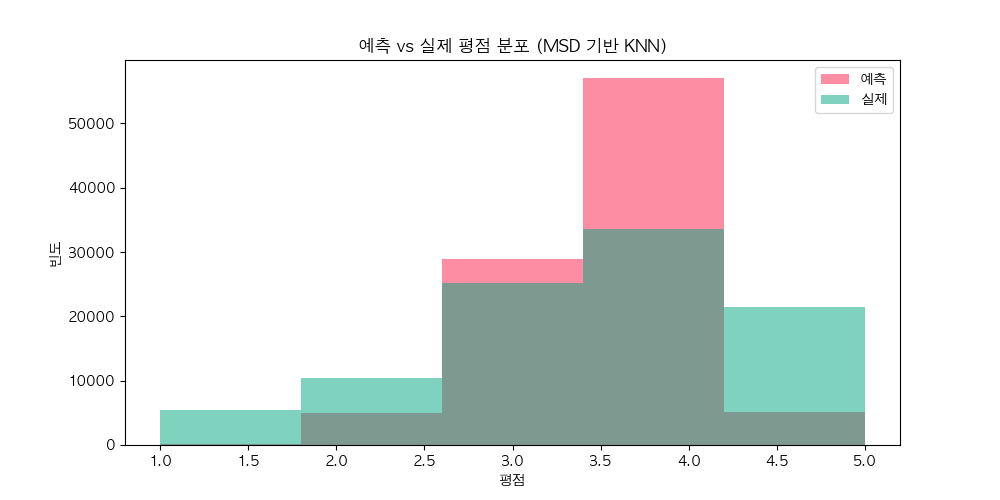
actual_ratings = [pred.r_ui for pred in predictions]
predicted_ratings = [round(pred.est) for pred in predictions]
plt.figure(figsize=(10, 5))
plt.hist(predicted_ratings, bins=5, alpha=0.5, label="예측", color="#fc1c49")
plt.hist(actual_ratings, bins=5, alpha=0.5, label="실제", color="#00a67d")
plt.title("예측 vs 실제 평점 분포 (MSD 기반 KNN)")
plt.xlabel("평점")
plt.ylabel("빈도")
plt.legend()
plt.savefig("msd_knn_rating_distribution.png")
plt.show()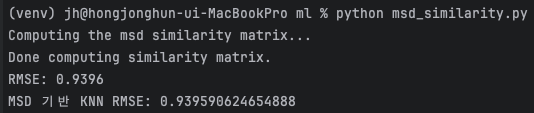

4. MSD의 역할
MSD는 추천 시스템에서 사용자 간 평점 차이를 직접적으로 측정하며, 다음과 같은 역할을 합니다.
- 유사한 사용자 식별: MSD 값이 작은 사용자 쌍은 평점 패턴이 비슷하다는 뜻입니다. 예를 들어, 사용자 A와 B의 MSD가 0.1이라면, 이들은 매우 유사한 영화 취향을 가지고 있을 가능성이 높습니다.
- 평점 예측: KNN 알고리즘에서 MSD 기반 유사도를 활용해, 비슷한 사용자의 평점을 참고하여 특정 영화의 평점을 예측합니다. 예를 들어, 사용자 A가 영화 X를 보지 않았다면, A와 MSD가 작은 사용자 B의 영화 X 평점을 참고할 수 있습니다.
- 추천 생성: 유사한 사용자가 좋아한 영화를 추천하거나, MSD를 바탕으로 새로운 영화를 제안합니다.
5. MSD vs. 코사인 유사도
코사인 유사도는 벡터의 방향성을 비교하는 반면, MSD는 평점 값의 차이를 직접 계산합니다. 두 메트릭의 장단점은 다음과 같습니다.
5-1. MSD의 장점
희소 데이터에서 0으로 나누기 문제가 없어 안정적이며, 평점 차이에 민감해 미세한 취향 차이를 잘 포착합니다. 또한, 계산이 간단하고, surprise 라이브러리에서 기본 유사도 메트릭으로 사용됩니다.
5-2. MSD의 단점
평점의 절대적인 크기나 스케일을 고려하지 않으므로, 사용자 간 평점 스케일이 크게 다를 경우(예: 한 사용자는 1~2점, 다른 사용자는 4~5점) 유사도가 왜곡될 수 있습니다.
5-3. 코사인 유사도의 장점
평점 패턴의 방향성을 강조하므로 스케일 차이에 덜 민감하며, 희소 데이터를 0으로 채운 뒤 방향성을 비교해 유사성을 파악합니다.
5-4. 코사인 유사도의 단점:
벡터 Norm이 0이 되면 계산이 실패할 수 있어, 희소 데이터에서 추가 전처리가 필요합니다.
6. 마무리
MSD는 추천 시스템에서 사용자 간 유사성을 계산하는 간단하면서도 강력한 도구입니다. 이번 글에서는 MovieLens 데이터셋을 사용해 MSD 기반 KNN 추천 시스템을 구현하고, RMSE와 히스토그램을 통해 성능을 평가해봤습니다. MSD는 희소 데이터에 안정적이며, 평점 차이를 직관적으로 반영해 추천의 정확성을 높이는 데 기여합니다.
