이전 단계에서 MovieLens 데이터셋을 불러와 사용자-아이템 매트릭스를 만드는 과정을 살펴봤습니다. 이제 이 매트릭스를 활용해 추천 시스템을 한 단계 더 발전시켜볼 건데, 여기서 중요한 개념이 바로 코사인 유사도입니다. 이번 글에서는 코사인 유사도가 무엇인지, 왜 추천 시스템에서 유용한지, 그리고 이를 코드에 적용하는 방법을 예시와 함께 알아보겠습니다.
1. 코사인 유사도란?
코사인 유사도는 두 벡터 간의 유사성을 측정하는 방법으로, 벡터의 방향성을 비교합니다. 수학적으로는 두 벡터
𝐴와 𝐵의 코사인 유사도가 1에 가까울수록 두 벡터가 비슷한 방향을 가리키고, 0에 가까울수록 관련이 없으며, -1에 가까울수록 반대 방향을 가리킵니다. 추천 시스템에서는 사용자의 평점 패턴을 벡터로 보고, 이 벡터들 간의 유사도를 계산해 비슷한 취향을 가진 사용자를 찾는 데 사용합니다.
코사인 유사도를 구하는 공식은 다음과 같습니다.
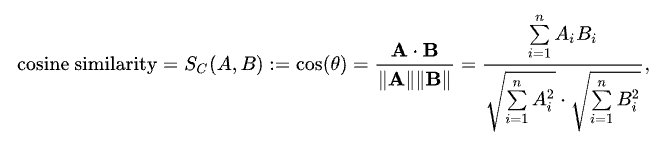
𝐴⋅𝐵는 내적, ∥𝐴∥와 ∥𝐵∥는 각각 벡터의 크기입니다.
2. 추천 시스템에서 코사인 유사도를 사용하는 이유
사용자-아이템 매트릭스는 희소하기 때문에(평가하지 않은 영화가 많기 때문에), 단순히 평점의 차이만으로 유사도를 계산하면 빈칸(평가하지 않은 영화)이 많아 정확도가 떨어질 수 있습니다. 반면, 코사인 유사도는 다음과 같은 장점 때문에 추천 시스템에서 널리 사용됩니다.
- 방향성 중점: 평점의 절대적인 크기보다 사용자가 영화를 평가하는 패턴(예: 어떤 장르를 좋아하는지)을 비교합니다.
- 희소성 처리: 평가하지 않은 영화(NaN)를 0으로 채운 뒤 계산하더라도, 방향성을 통해 유사성을 잘 파악할 수 있습니다.
- 효율성: sklearn의
cosine_similarity와csr_matrix을 결합하면 대규모 데이터에서도 빠르게 계산 가능합니다.
예를 들어, 사용자 A가 영화 1에 5점, 영화 2에 4점을 주고, 사용자 B가 영화 1에 4점, 영화 2에 3점을 줬다면, 평점 크기는 다르지만 평가 패턴이 비슷하다는 걸 코사인 유사도가 잘 잡아냅니다.
3. 코사인 유사도 적용
이제 사용자-아이템 매트릭스에서 코사인 유사도를 계산하는 과정을 코드로 구현해 보겠습니다. 이전 코드에서 매트릭스를 만든 뒤, 이를 기반으로 사용자 간 유사도를 계산하는 단계로 넘어갑니다.
import pandas as pd
from datasets import load_dataset
from tqdm import tqdm
from sklearn.model_selection import train_test_split
from sklearn.metrics.pairwise import cosine_similarity
from scipy.sparse import csr_matrix
# MovieLens 데이터셋 로드
data = load_dataset("nbtpj/movielens-1m-ratings")["train"].shuffle(seed=10)
# 데이터를 청크 단위로 처리
n_chunks = 100
chunk_size = len(data) // n_chunks
if len(data) % n_chunks != 0: chunk_size += 1
movielens_df = pd.DataFrame()
for start in tqdm(range(0, len(data), chunk_size)):
end = start + chunk_size
chunk_df = pd.DataFrame(data[start:end])
movielens_df = pd.concat([movielens_df, chunk_df], ignore_index=True)
# user_id를 문자열로 변환 및 필요한 열만 선택
movielens_df["user_id"] = movielens_df["user_id"].apply(lambda x: x.decode('utf-8') if isinstance(x, bytes) else str(x))
movielens_df = movielens_df[["user_id", "movie_id", "user_rating"]]
# 데이터 분할
train_data, _ = train_test_split(movielens_df, test_size=0.02, random_state=10)
# 사용자-아이템 매트릭스 생성
user_item_matrix = train_data.pivot_table(index="user_id", columns="movie_id", values="user_rating")
# 코사인 유사도 계산 (NaN을 0으로 채움)
user_similarity = cosine_similarity(csr_matrix(user_item_matrix.fillna(0)))
user_similarity_df = pd.DataFrame(user_similarity, index=user_item_matrix.index, columns=user_item_matrix.index)
# 결과 확인 (상위 5개 사용자 간 유사도)
print("사용자 간 코사인 유사도 예시:")
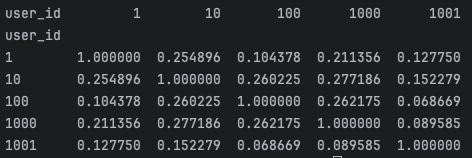
print(user_similarity_df.iloc[:5, :5])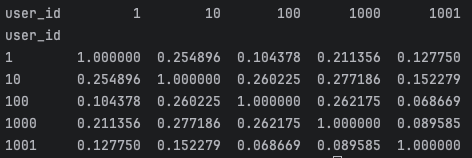
- 데이터 로드 및 매트릭스 생성: 이전 코드와 동일하게 MovieLens 데이터를 불러와 사용자-아이템 매트릭스를 만듭니다.
- 희소 행렬 변환:
csr_matrix로 매트릭스를 변환해 메모리 효율성을 높이고, fillna(0)으로 NaN을 0으로 채웁니다. - 코사인 유사도 계산:
cosine_similarity를 사용해 사용자 간 유사도를 계산하고, 결과를 데이터프레임으로 변환합니다. - 결과 출력: 상위 5개 사용자 간 유사도를 출력했는데, 대각선 값이 1인 건 자기 자신과의 유사도이고, 다른 값은 사용자 간 평점 패턴의 유사성을 나타냅니다.
4. 코사인 유사도의 역할
이렇게 계산된 user_similarity_df는 추천 시스템의 핵심입니다. 여기서 사용자 "1"과 "10"의 유사도가 0.254896으로 나타났는데, 이는 두 사용자가 약간 비슷한 취향을 가지고 있다는 뜻입니다. 0에 가까울수록 관련성이 적고, 1에 가까울수록 매우 유사한 취향을 가진다고 볼 수 있습니다. 예를 들어, 사용자 "10"과 "1000"의 유사도가 0.277186으로 더 높으니, 이들이 더 비슷한 영화 평점 패턴을 보일 가능성이 높습니다. 이후 KNN 알고리즘에서 이 유사도를 활용해 비슷한 사용자의 평점을 참고하여 특정 영화의 평점을 예측하거나 추천 영화를 제안하게 됩니다.
5. 마무리
코사인 유사도는 사용자-아이템 매트릭스의 희소성을 다루면서도 사용자의 취향 패턴을 효과적으로 비교할 수 있는 강력한 도구입니다. 이번 글에서 데이터를 불러와 매트릭스를 만들고, 코사인 유사도를 계산하는 과정을 코드로 살펴봤습니다. 다음 단계에서는 이 유사도를 활용해 KNN 기반 추천 시스템을 만들어보겠습니다.
