논문 및 이미지 출처 : https://arxiv.org/abs/2104.00298
개요
-
EfficientNetV2는 neural architecture speed (NAS) 와 scailing을 통해 이전 모델들 보다 더 빠르고 적은 파라미터 가지는 Convolution Network
특히 SOTA 모델보다 더 빠르면서 6.8배 작다 -
빠른 속도를 위해 progressive learning 을 도입하지만 이는 정확도를 떨어뜨려, 개선된 method인 adaptively adjust regularization 을 도입
1. Introduction
- GPT3-3 처럼 엄청 큰 모델과 데이터셋을 통한 훈련은 좋은 성능을 보여주지만, 수 천개의 GPU와 주 단위 학습으로, 재훈련 및 개선이 어려움
따라서 훈련 효율성이 최근 관심도가 높아지고 있다.
| model | aim |
|---|---|
| NFNets | expensive batch normalization 제거 |
| ConNets | attention layer 추가로 훈련 속도 개선 |
| VIT | Transformer 블록으로 큰 데이터셋에 훈련 효율성 개선 |
이전 연구인 EfficientNet 에선 다음 문제점이 존재했다.
- 매우 큰 사이즈 이미지에는 훈련이 느림
- depthwise convolution 이 초기 레이어에선 느림
- 매 단계마다 하는 동일한 scailing up은 차선책이었음
이를 Fused-MBConv 로 설계하고, NAS 와 scailing 으로 정확도, 속도, 파라미터 사이즈를 최적화한다. (파라미터는 6.8배 작아지고 속도는 4배 빨라짐)
- 이전 progressive learning 연구(FixRes, Mix&Match)는 모든 이미지 사이즈를 같은 정규화를 하지만, 이는 이상적이지 못하므로 개선된 progressive learning 제안
초기 epoch에 작은 이미지와 약한 정규화로, 서서히 이미지 사이즈를 증가시켜 큰 이미지엔 강한 정규화 학습키는 방법
이 접근법은 정확도를 떨어뜨리지 않으며 속도를 증가시킴
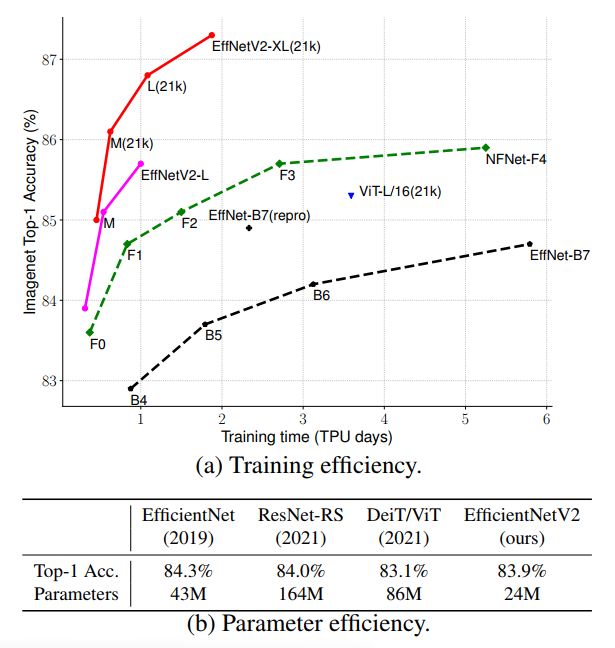
- ImageNet 에서 3~9배 빠르고 이전 모델보다 6.8배 작아졌지만 87.7%의 정확도를 보임
이는 ViT-L/16 보다 5~11배 빠르면서 2% 의 높은 정확도를 가졌다.
2. Related Work
- 훈련 및 파라미터 효율성
| model | aim |
|---|---|
| DenseNet, EfficientNet | 적은 파라미터로 좋은 정확도를 목표 |
| ResNet, ResNetSt, TResNet, EfficientNet-X | inference 속도를 개선 |
| NFNet, BoTNet | 훈련 속도 개선 |
이러한 연구들은 training 이나 inference 속도를 개선했지만 더 많은 파라미터가 생겨났다.
- Progressive training
관련 연구로 Progressive resizing 과 Mix&Match 가 있지만, 이는 accuracy drop 을 야기한다.
curriculum learning 에 영감을 받아, 점점 정규화를 추가함으로써 서서히 학습을 어렵게 한다.
- Neural architecture search (NAS)
image classification, object detection, segmentation 등에선 FLOPs 나 inference 효율 개선으로 주로 연구됐지만, 본 논문에서는 training 및 parameter 효율 개선으로 사용
3. EfficientNetV2 Architecture Design
Understanding Training Efficiency
Training with very large image sizes is slow
EfficientNet 에선 큰 이미지에 대한 학습이 느리다고 했다. (모든 메모리가 GPU/TPU 에 고정 & 큰 이미지로 인한 작은 배치를 사용했어야 했서 속도가 느려졌다고 함)
간단한 개선법으로 작은 이미지 사이즈로 FixRes 를 적용하는 것이다.

위 표와 같이 작은 이미지로 배치를 늘려 2.2배 속도가 빨라지고 약간의 높은 정확도를 얻었다. (어떠한 fine-tuning 을 이용하지 않고도)
Depthwise convolutions are slow in early layers but effective in later stages
EfficientNet 에서 사용한 Depthwise convolution 은 regular convolution 보다 적은 파라미터와 FLOPs 를 가지지만 accelerator 를 활용할 수 없게 된다.
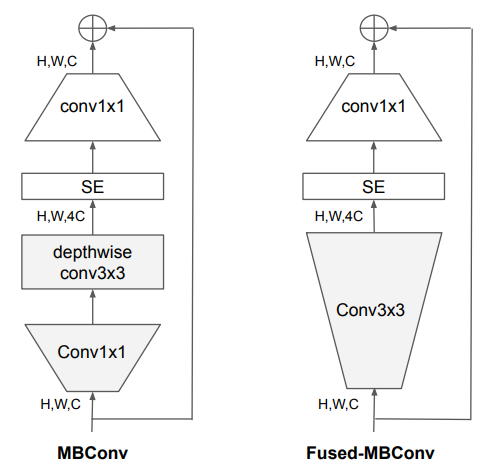
그래서 최근에 MBConv 의 depthwise conv3x3 과 Conv1x1 을 single regular conv3x3 으로 교체한 Fused-MBConv 가 제안되었다.
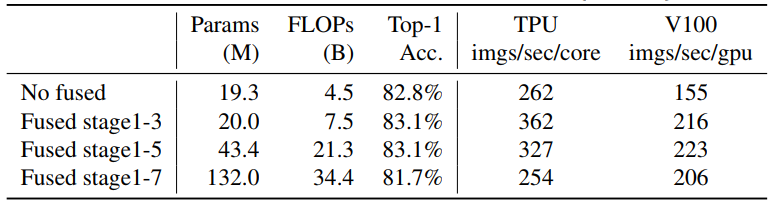
두 블록을 비교하기 위해 MBConv 로 이루어진 EfficientNet-B4 모델에 서서히 Fused-MBConv 로 교체해보았다.
모든 블록을 Fused-MBConv 로 바꾸기 보단, 1-3 초기 단계를 교체하니 Params 와 FLOPs 가 적으면서도 정확도가 높았다.
Equally scailing up every stage is sub-optimal
EfficientNet 에서 매 단계 동일하게 scailing up 하는 것은 차선책이었다.
이는 훈련 속도 및 파라미터 효율성에 기여를 하지 못하여, 본 논문에서는 non-uniform scaliling 전략으로 후기 단계에 서서히 추가하는 것을 제안
추가로 EfficientNet 에서 이미지를 scale up 을 하니 큰 메모리 소비와 훈련 속도 저하를 야기했음
이 이슈 해결을 위해서 scailing 규칙을 약간 수정하고, 최대 이미지 크기를 좀 더 작은 값으로 제한함
Training-Aware NAS and Scailing
NAS Search
accelerator 를 사용하여 정확도, 파라미터 그리고 훈련 효율성을 최적화하기 위해 training-aware NAS 를 사용
EfficientNet 을 사용하며 search space 는 stage 기반의 factorized space 로 구성되며, {MBConv, Fused-MBConv} 의 convolution 과 {3x3, 5x5} 의 커널 사이즈, 확장 비율 {1, 4, 6} 을 포함한다.
반면에,
- 불필요한 작업인 pooling 을 제거
- EfficientNet 에서 이미 연구된 채널 크기를 재사용
하여 search space 사이즈를 줄임
A - model accuracy
S - nomalized training step time
P - parameter size
를 다음과 같이 결합하여 search reward 에 대한 간단한 가중치를 만든다.
A · Sw · Pv - weight
w = -0.007
v = -0.05
EfficientNetV2 Architecture
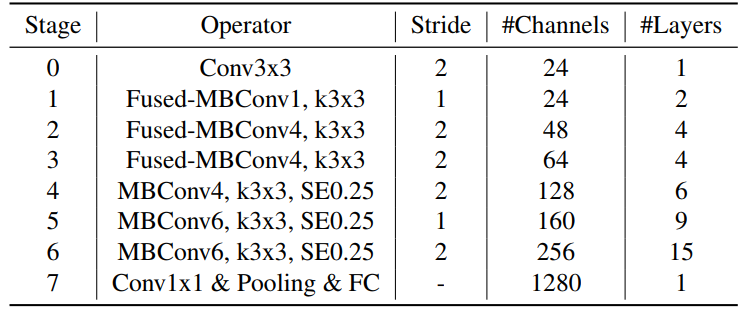
위는 EfficientNetV2-S 의 아키텍처로, 기존 EfficientNet 과의 차이점은 다음과 같다.
- MBConv 와 초기 단계에 fused-MBConv 사용
- MBConv 의 적은 비율을 선호
- 3x3 kernel 사이즈를 선호
- EfficientNet 의 마지막 단계에서 stride-1 을 제거
위 차이점들로 파라미터와 처리시간을 줄임
EfficientNetV2 Scailing
몇 가지 추가적인 최적화로 EfficientNetV2-S 를 scale up 하여 EfficientNetV2-M/L 을 얻었다.
- 매우 큰 이미지는 큰 메모리 비용 및 훈련 속도 오버헤드를 야기하므로 최대 480 으로 제한
- EfficientNetV2-S 처럼 5-6단계에서 서서히 레이어를 더 추가
Training Speed Comparison
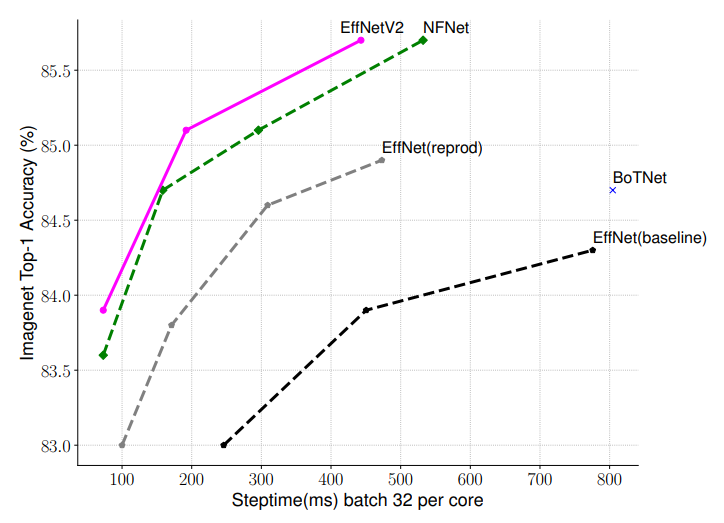
모든 모델을 progressive learning 을 하지 않고 고정된 사이즈 이미지로 훈련한 결과, training-aware NAS 와 scailing 을 적용한 EfficientNetV2 가 다른 모델들 보다 매우 빠른 것을 관찰했다.
4. Progressive Learning
Motivation
이미지 사이즈는 훈련 효율성에 큰 영향을 준다고 했었다. 다른 연구에서 다이나믹하게 이미지 사이즈를 훈련 중에 바꾸는데 (고정된 regularization 으로), 이는 정확도 저하를 야기했다.
이는 unbalanced regularization 으로 인해 생겨난다고 가설을 세운다.
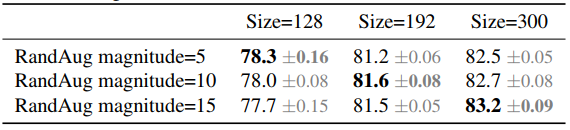
unbalanced regularization 가설을 입증하기 위해 각기 다른 이미지 사이즈와 데이터 augmentation으로, 작은 이미지는 약한 augmentation, 큰 이미지는 강한 augmentation을 사용한 것이 정확도가 좋았다.
따라서 본 논문에서는 작은 이미지에는 약한 regularization 을, 큰 이미지에는 강한 regularization 으로 과적합을 방지하는 것이 중요하다고 주장한다.
위 실험을 통해, progressive learning 을 개선한 method 인 adaptively adjust regularization 을 제안한다.
Progressive Learning with adaptive Regularization

위와 같이 훈련 프로세스에 개선된 progressive learning 을 사용한다.
초기 에폭에 작은 이미지와 약한 정규화를 사용하여 학습을 쉽게하고 빠르게 한다.
이미지 크기를 서서히 증가 시키며, 강한 정규화를 추가하여 학습을 어렵게 한다.
N - 전체 steps
Se - 타깃 이미지 사이즈
Φe - 정규화 magnitude 리스트 = {Φek}
k - dropout rate 또는 maxiup rate value 와 같은 정규화 타입
M - 각 훈련을 M stage 로 나눔
각 stage 는 1 <= i <= M 이고, 모델은 Si 사이즈 이미지와 Φi = {Φik} 의 정규화를 훈련한다.
처음엔 S0 와 Φ0 을 초기화하고, 각 단계의 값을 결정하기 위해 linear interpolation 을 사용한다.
알고리즘은 다음과 같다.

본 논문에서는 다음 3 가지의 정규화를 다룬다.
- Dropout - 무작위로 채널을 dropping 함. magnitude -
- RandAugment - 각 이미지마다 데이터 증강. magnitude -
- Mixup - data augmentation 을 교차시킨다. 라벨이 있는 두 이미지 와 가 주어졌을 때, λ 비율로 섞어 결합한다.
and
magnitude -
5. Main Results
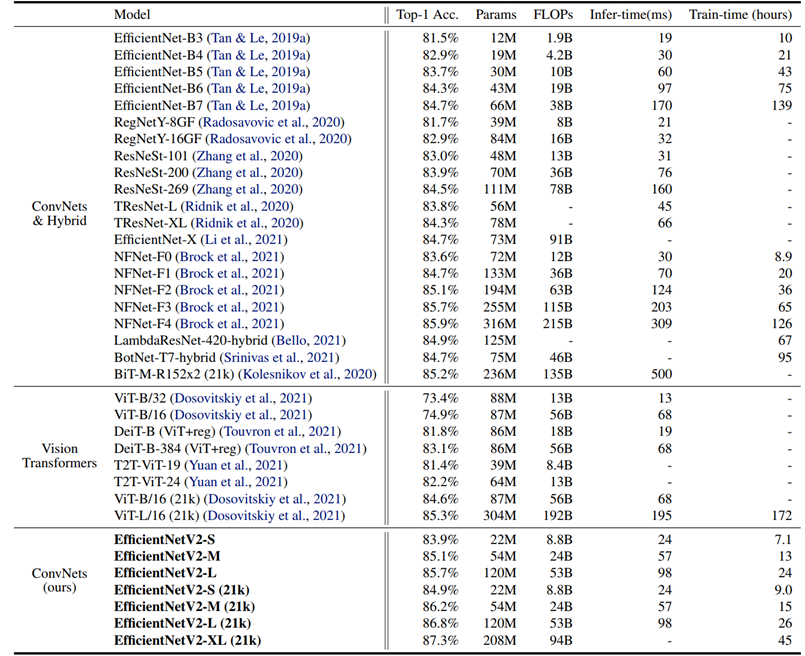
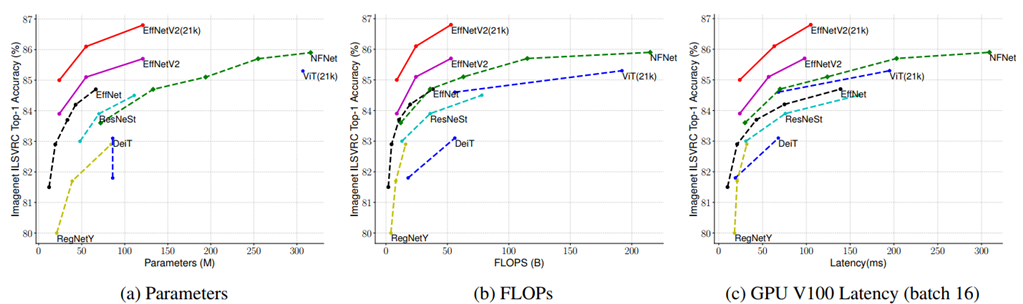
ImageNet ILSVRC2012
Setup
1.28M 훈련셋과 50,000 검증셋의 1000 클래스가 포함된 ImageNet ILSVRC2012 에는 테스트셋이 없으므로 훈련셋에서 25,000 이미지를 남김
훈련 세팅은 EfficientNet 을 따른다.
- RMSProp optimizer ( 0.9 decay, 0.9 momentum )
- 0.99 batch norm momentum
- 1e-5 weight decay
- 350 epoch
- 0.256 lr, decayed 0.97 every 2.4 epoch
- exponential moving average (EMA) 0.9999 decay rate
- Regularization
- RandAgment
- Mixup
- Dropout
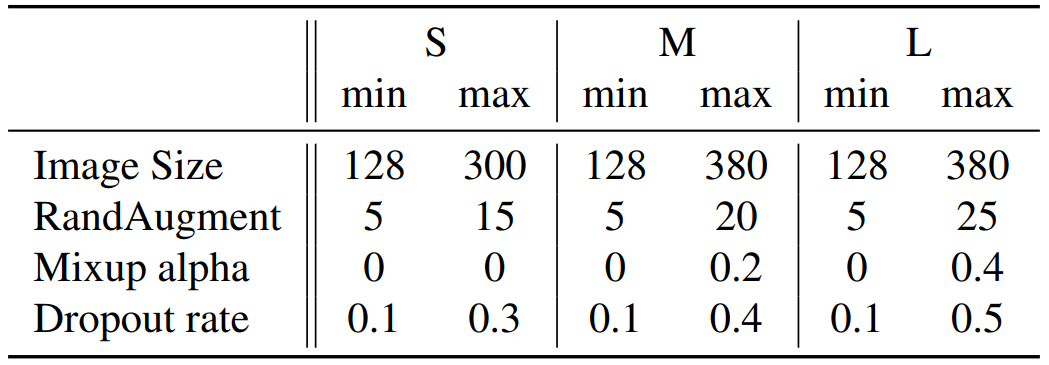
progressive learning 은 4단계로, 약 87 에폭 당 진행했다고 한다.
Results
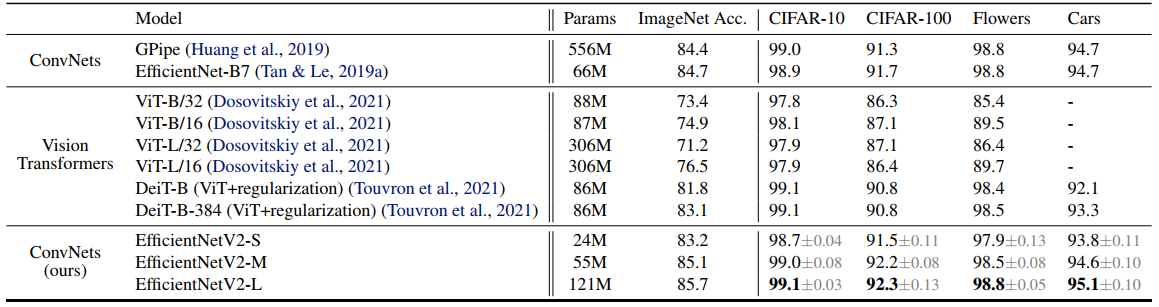
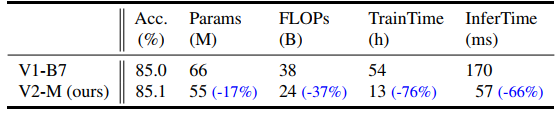
위의 성능표에서 보이듯 같은 computing resource 에서 EfficientNetV2-M 은 EfficientNet-B7 보다 11배 빠르다 한다.
ResNetSt 와 비교하면 EfficientNetV2-M 이 2.8배 더 빠르면서도 0.6% 의 정확도가 높았다.
ImageNet21k
Setup
ImageNet21k 는 21,841 클래스와 13M 훈련셋을 가진다. 테스트와 검증셋이 없으므로 무작위로 100,000개 이미지를 검증셋으로, 나머지는 테스트셋으로 이용한다.
ImageNet ILSVRC2012 의 세팅을 사용하면서도 약간 변화를 주었다.
- 훈련 시간을 줄이기 위해 에폭수를 60 또는 30으로 변경
- 각 이미지는 multiple labels 를 가지므로, softmax loss 계산 전에 1로 합쳐서 정규화 진행
Results
위 성능표에서 보이듯 EfficientNetN2-L 는 Vit-L 보다 2.5배 더 적은 파라미터와 3.6배 더 적은 FLOPs, 그리고 6~7배 빨라진 학습 속도를 보였다.
Transfer Learning Datasets
Setup
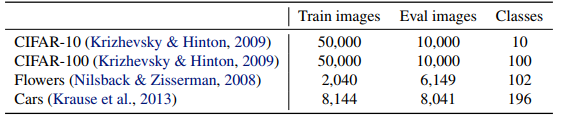
ImageNet ILSVRC2012 을 훈련하여 CIFAR-10, CIFAR-100, Flowers, Cars 데이터셋을 fine-tuning 한다.
훈련 세팅은 ImageNet 과 비슷하며, 약간의 수정이 있다.
- 512 batch size
- 0.001 lr, cosine decay
- fixed 10,000 steps
- disable weigt decay, simple data augmentation
Results
위의 성능표에서 보이듯, CIFAR-100 에서 EfficientNetV2-L 은 이전 모델 GPipe/EfficientNets 보다 0.6%, ViT/DeiT 보다 1.5% 더 좋은 정확도를 보인다.
6. Ablation Studies
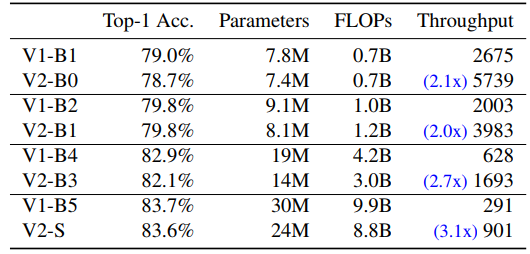
Comparison to EfficientNet
EfficientNetV2 와 EfficientNets 를 비교해보자.
Performance with the same training
Scailing Down
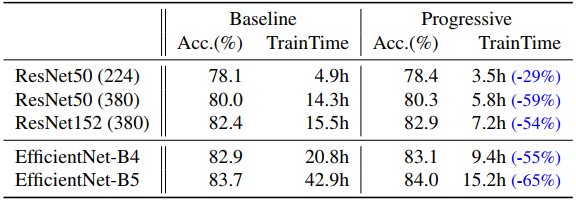
Progressive Learning for Different Networks
progressive learning 을 다른 모델에도 적용하여 비교한다.
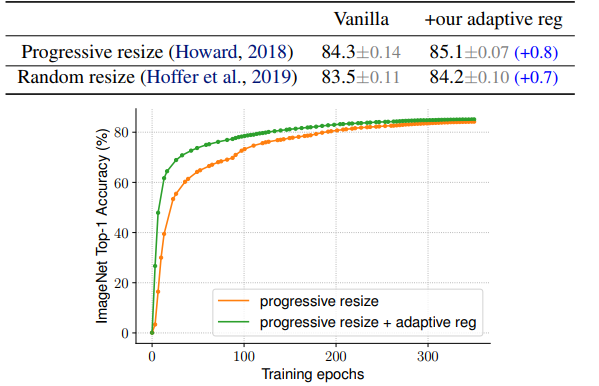
Importance of Adaptive Regularization
이미지 크기에 따른 adaptive regularization 접근법을 이용하여 결과를 관찰한다.
7. Conclusion
training-aware NAS 와 model scailing 으로 최적화
개선된 progressivel learning 인 adaptively adjust learning 으로 이미지 크기를 서서히 증가시키며 강한 정규화를 사용
기존의 EfficientNet 의 아키텍처 초기 단계에 Fused-MBConv 를 교체
위 사항들을 통해 기존 EfficientNet 모델보다 6.8배 작아졌으며 11배 빨라졌다.
Summarization
| Problems | Solutions |
|---|---|
| Training with very large image size is slow | Apply FixRes with small image size |
| Depthwise convolutions are slow in early layers but effective in later stages | Gradually replace MBConv with Fused-MBConv |
| Equally scailing up every stage is sub-optimal | In early stage, Train small image size with weak regularization and gradually increase image size with stronger regularization |
-
Improved method of progressive learning: adaptively adjust regularization
- In the early epoch, train the network with small image size and weak regularization (e.g., dropout, randaugment, mixup) then gradually increase image size and add stronger regularization
- Speed up the training without causing accuracy drop
- use three types of regularization- Dropout
- RandAugment
- Mixup
-
Defference from EfficientNet Architecture
- In the early stage (1-3), replace MBConv with Fused-MBConv
- remove stride-1 in the last stage
- refer kernel of 3x3 size
-
Training-Aware NAS and Scailing
-
Algorithm

Experiments
Setup
- 350 epoch
- 1e-4 lr, 1e-5 weight decay, 0.9 momentum
- RMSProp

Implemented Network Code
