논문 및 이미지 출처 : https://arxiv.org/abs/2010.11929v2
Abstract
NLP task 에서 Transformer Architecture 가 사용되어 오고 있다.
본 논문에서는 vision 의 CNN 구조를 유지하면서 Transformer 를 적용해 훌륭한 결과로 SOTA 를 달성하였다.
이를 Vision Transformer (ViT) 로 명명한다.
1. Introduction
- 비전 분야에서, CNN-like 아키텍처 와 self-attention 을 결합하는 여러 시도가 있었고, 일부에서는 CNN 을 완전 교체
- 후자 모델은 이론적으로는 효율적이지만 GPU 에서 효과적으로 확장되지 않았음
위 사항들로 여전히 ResNet 과 같은 아키텍처가 여전히 SOTA 를 달성
본 논문은, 이에 가능한 한 적은 수정으로 표준 Transformer 를 직접 이미지에 적용하기 위해 실험을 진행
- 이미지를 패치 단위로 분할
- 분할된 패치의 선형 임베딩 시퀀스를 NLP 의 토큰처럼 처리하여 Transformer 에 입력으로 제공
중간 규모 데이터셋(ImageNet)으로 학습했을 때는 ResNet 보다 정확도가 낮은데, Transformer 는 equivariance 와 locality 같은 inductive bias 가 부족하여 일반화가 잘 되지 않기 때문으로 보인다.
큰 규모의 데이터셋(14M-300M 이미지)에서 훈련되면, 위 단점이 보완되어 다른 데이터셋에 transfer learning 을 한 결과 뛰어난 정확도를 보였다.
inductive bias inductive bias 란 머신 러닝이 학습할 때, 어떤 가정이나 제한을 통하여 문제 공간을 탐색하는 방식
모델이 데이터로부터 일반화를 하는 데 중요한 역할
딥 러닝에서 inductive bias 의 예로 Layer 의 수, 각 Layer 의 뉴런 수, activation function 등의 구조적 제한이 있다.
적절한 inductive bias 로 일반화 성능을 올릴 수 있지만, 부적절하면 과적합을 발생한다.
Trnasformer 에서 이러한 inductive bias 가 부족한 이유는 논문의 방법론 설명에 나온다.
2. Related Work
Transformer 를 이미지 처리에 적용하려면 각 픽셀이 다른 모든 픽셀에 대한 self-attention 을 적용해야 했기 때문에 실질적으론 힘들다.
- self-attention
따라서 각 쿼리 픽셀의 지역 이웃에 대해서 self-attention 을 적용하거나, Sparse Transformer, block 크기 가변적 조정 등 다양한 방법으로 self-attention 을 적용하였지만 GPU 에서 효율적이지 못하였다.
- patch
이어, Cordonnier 모델은 2x2 크기 패치로 self-attention 을 적용하였는데, ViT 와 유사하지만, 패치가 작아 작은 해상도에서만 적용이 가능하나 본 연구는 중간 해상도에도 적용이 가능하다.
- combination CNN with self-attention
Bello 등은 feature map 에 self-attention 을 추가, Hu 등은 CNN 의 출력 결과를 self-attention 으로 추가 처리하며 다양하게 CNN 과 self-attention 을 결합한 연구가 이루어지고 있다.
본 연구에서는 ImageNet 보다 큰 ImageNet-21k 와 JFT-300M 과 같은 대규모 데이터셋에서, 데이터셋 크기에 따른 CNN 성능이 어떻게 변화하는 지 연구하며 Transformer 를 훈련시킨다.
3. Method
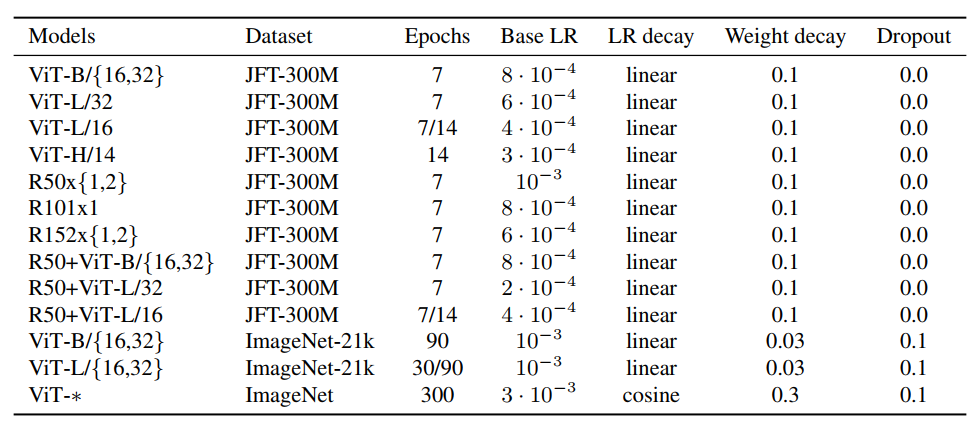
3.1 Vision Transformer (ViT)
표준 Transformer (NLP) 에서는 token embedding 의 1D sequence 를 받는다.
2D 인 이미지를 다루기 위해, 이미지를 다음과 같이 처리한다.
- 이미지 입력 Embedding
- 이미지 를 flattened 2D patch 의 sequence 인 로 재배치한다.
- : 원본 이미지 해상도
- : 채널 수
- : 각 이미지 패치의 해상도
- : 생성된 패치의 수, Transformer 의 효과적인 input sequence 길이
Transformer 는 모든 레이어에서 일정한 latent vector 사이즈 를 사용하므로, 패치를 flatten 하고 linear projection (아래의 식 1) 으로 차원으로 매핑한다.
이 projection 의 출력을 patch embedding 이라 칭한다.
latent vector latent vector 는 데이터를 압축하고 잠재적인 특징을 추출하는 데 사용되는 벡터이다.
일반적으로 입력 데이터를 저차원 벡터 공간으로 매핑하여 유용한 정보를 추출하고, 해당 정보를 바탕으로 다양한 테스크를 수행하는 데 사용된다.
- Token
- BERT 의
[ class ]token 과 유사하게, embedding patch 에 학습 가능한 embedding ( ) 을 추가 - Transformer encoder 의 출력 상태 ( ) 는 이미지 표현 로 사용 (아래의 식 4)
- pre-training 및 fine-tuning 을 수행할 때 Classification Head 를 에 부착
- BERT 의
- Classification Head
- pre-training : 1-hidden layer 인 MLP
- fine-tuning : 1-linear layer
- Position embedding
- position 정보 유지를 위해, Position embedding 을 patch embedding 에 추가
- 2D-aware position embedding 의 성능 향상은 관찰되지 않음
→ 1D position embedding 사용 - embedding vector 의 sequence 를 encoder 에 입력
- Transformer encoder
- Multi-Head self-attention 와 MLP Block 을 교차하는 Layer 를 포함
- Layernorm (LN) 을 모든 Block 이전에 적용
- Residual Connection 을 모든 블록 끝에 적용
- MLP 는 GELU non-linearity 가 있는 두 개의 레이어를 포함
(1)
- 입력에 해당하는 수식으로, patch 로 나눈 각 이미지 시퀀스다.
- 마지막 는 각 시퀀스의 순서를 나타내는 Positional Encoding 이다.
(2)
- Transformer Encoder 의 수식으로, Layer Normalization (LN) 후, Multi-head Attention (MSA) 을 적용
- 이후, Residual 로 을 더한다
(3)
- MLP head 의 수식으로, 위와 동일하다.
(4)
- 마지막으로, classification 으로 target 값을 찾는다.
Intuctive bias
CNN 은 locality, 2D 이웃 구조체를 내재
반면, ViT 는 MLP 레이어만 지역성을 가지고, self-attention 레이어는 전역적이기 때문에 CNNs 보다 inductive bias 가 적다.
Transformer 에서는 이 2D 이웃 구조체는 극히 드물게 사용한다.
- 모델 시작 부분에서 이미지를 패치로 자르는 것
- fine-tuning 시 이미지의 position embedding 조절
- position embedding 은 초기화 시 패치들의 2D position 정보가 없으며, 패치 간의 모든 관계를 처음부터 학습 해야함
Hybris Architecture
원시적인 Image patch 대안으로, sequence 는 CNN 의 feature map 으로 구성하는 것이 가능하여 Hybrid model 을 만든다.
patch embedding projection (식 1) 은 CNN feature map 으로 추출된 patch 에 적용한다.
특별한 경우, patch 는 1x1 사이즈도 가능 한데, 이는 sequence 가 feature map 의 차원을 flatten 하고 projecting 하여 Transformer 차원으로 얻을 수 있다는 것을 의미한다.
CNN feature map 으로 patch 추출 → Flatten → embedding projection (식 1)
3.2 fine-tuning and higher resolution
일반적으로 ViT 를 큰 데이터셋에 pre-training 하고 downstream task 로 fine-tuning
이를 위해 다음 사항들을 진행한다.
- prediction head 제거
- 0 으로 초기화된 를 feedforward layer 에 부착 (여기서 는 downstream class 수)
- pre-training 보다 높은 해상도로 fine-tune 하는 것이 이득
- 높은 해상도로 할 땐, patch size 를 동일하게 해야함 → 더 큰 effective sequence length 가 생성
- fine-tune 시, pre-trained 의 position embedding 은 의미가 없음
- 따라서 pre-trained 의 position embedding 을 2D 보간 (interpolation) 해야 함
위의 해상도 조정 및 패치 추출은 ViT 에 대한 이미지 구조의 inductive bias 를 삽입하는 방법
4. Experiments
Resnet, ViT, hybrid 를 각각 평가한다.
4.1 Setup
Datasets
- train dataset
- ILSVRC-2012 ImageNet-1k (1.3M images)
- ImageNet-21k (14M images)
- JFT-18k (303M high resolution images)
- transfer dataset
- transfer learning 평가
- ImageNet
- ImageNet ReaL
- CIFAR-10/100
- Oxford-IIIT Pets/-Flowers102
- VTAV
- 또한 19-task VTAB 분류 평가로 여러 그룹의 작은 데이터셋 transfer 평가
- Natural : Pets, CIFAR
- Specialized : medical, satellite imagery
- Structured : geometric, localization
- transfer learning 평가
Model Variants
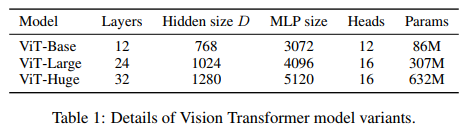
Table 1 의 Base, Large, Huge 는 BERT 를 기반으로한 ViT 의 구성이다.
간단한 표기법으로 모델 사이즈 및 input patch 사이즈를 다음과 같이 나타낸다.
- ViT-L/16 : 16x16 input patch 및 "Large" 모델
- sequence length 는 patch 크기 제곱에 반비례 → patch 가 작을수록 계산량 증가
CNN 베이스라인은 ResNet 으로, 다음과 같이 수정을 더하였다.
- Batch Normalization → Group Normalization & Standardized Convolution
- 이렇게 수정한 ResNet 을 BiT 라 표시
- transfer learning 의 성능 향상
Hybrid 모델의 경우, 중간 feature map 으로 ViT 에 한 픽셀 (1x1) 의 patch 사이를 입력
- 각기 다른 sequence length 로 실험
- ResNet50 - stage 4
- ResNet50 - stage 3 (단, Layer 수 유지) → 4배 더 긴 sequence length (stage 3 의 output 이 확장되므로)
Training & Fine-tuning
train model
- include ResNet
- Adam ( , )
- batch size 4096
- weight decay 0.1
fine-tune
- SGD
- batch size 512
- 고해상도 변경 : 512 - ViT-L/16, 518 - ViT-H/14
Metrics
few-shot 정확도는 다음과 같이 얻는다.
- 고정된 훈련 이미지의 representation 추출
- target vector 로 매핑
- 위 과정으로 regularized least-squares regression 문제를 해결하여 얻음
주로 fine-tuning 성능에 초점을 두지만, 비용이 많이 들어 linear few-shot 정확도를 빠르게 평가
4.2 Comparison to State Of The Art
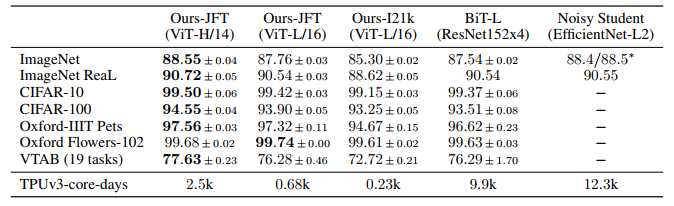
ViT-H/14 와 ViT-L/16 를 CNN SOTA 모델들과 비교 한다.
- BiT
- Large EfficientNet 으로 semi-supervised 훈련한 Noisy Student
모든 모델은 TPUv3 로 훈련을 진행하였고, 결과는 위 Table 에서 나타난다.
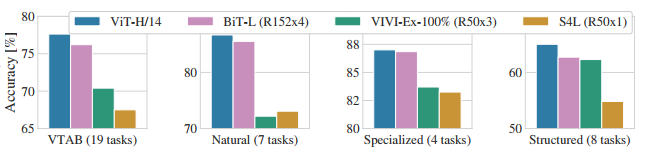
위 그림은 각 VTAB 작업 그룹에 따른 결과 비교이다.
4.3 Pre-trained Data Requirements
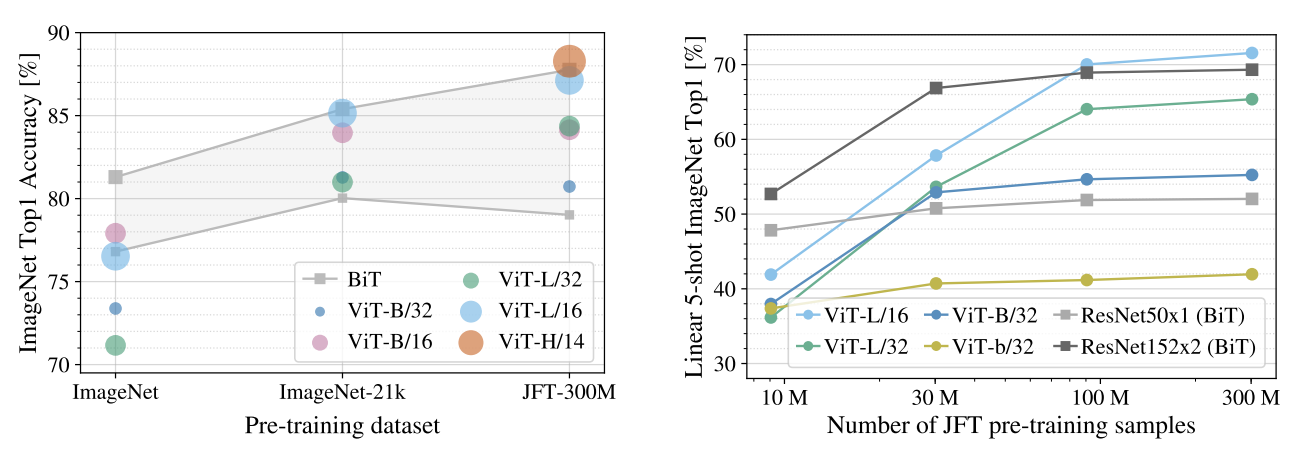
각각 ImageNet, ImageNet-21k, JFT-300M 데이터셋으로 pre-train 한 결과 JFT-300M 이 가장 좋았다.
이는 ResNet 보다 inductive bias 가 적기 때문에 많은 데이터가 있어야 하기 때문이다.
각 pre-train 후 작은 데이터셋에서 성능을 올리기 위해, 세 가지 regularization 을 설정한다.
- weight decay
- dropout
- label smoothing
두 번째로, JFT-300M 의 하위집합으로 9M, 30M, 90M 및 전체를 학습하여 비교한다.
하위 집합에는 추가적인 정규화를 수행하지 않고 모든 하이퍼파라미터를 동일하게 사용한다.
여기서 fine-tuning 정확도 대신 linear few-shot 정확도를 관찰한다.
위 그래프에서 보이듯 작은 데이터셋에는 ResNet 보다 오버피팅 발생한다.
이 결과로 다음을 알 수 있다.
- transfer learning 시 작은 데이터셋에는 convolution inductive bias 가 유리
- transfer learning 시 ViT 는 큰 데이터셋에 유리
4.4 Scailing Study
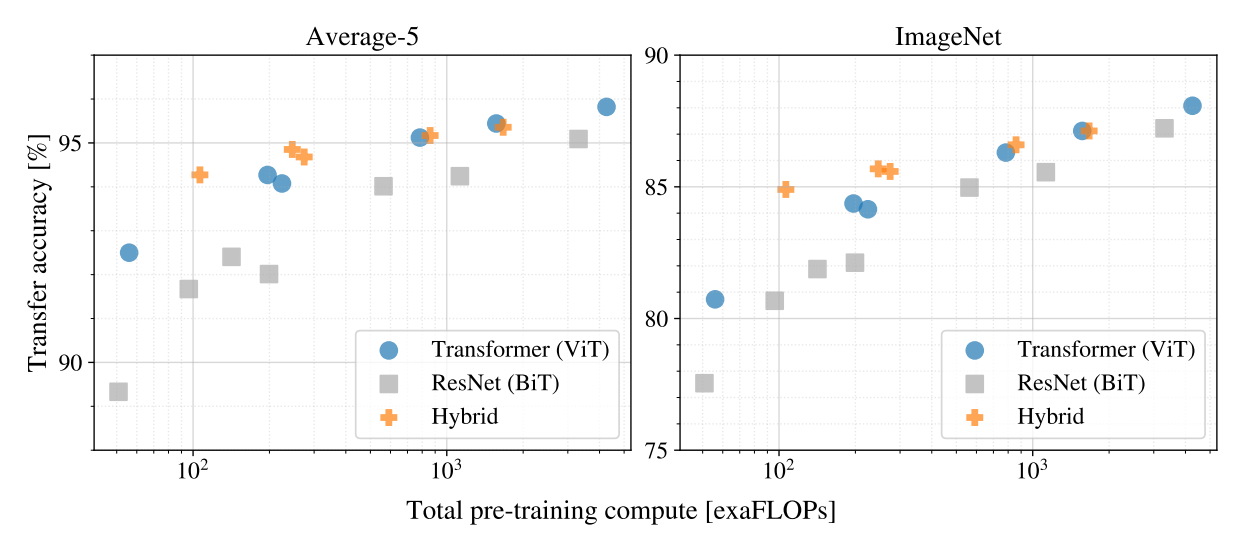
각 Transformer, BiT, Hybrid 의 크기에 대한 실험
모델은 다음과 같다
- ResNets, R50x1, R50x2 R101x1, R152x1, R152x2 pre-train for 14 epochs
R152x2, R200x3 pre-train for 14 epochs - ViT-B/32, B/16, L/32, L/16 pre-train for 7 epochs
L/17, H/14 pre-train for 14 epochs - R50+ViT-B/32, B/16, L/32, L/16 pre-train for 7 epochs
R50-ViT-L/16 pre-train for 14 epochs
이 실험에서 다음을 관찰할 수 있다.
- ViT 는 성능/계산 적으로 BiT 보다 뛰어남
- 적은 비용에선 Hybrid 가 ViT 보다 약간 더 좋음
- ViT 는 포화되지 않아, 성능이 더 좋아질 수도 있다.
4.5 Inspecting Vision Transformer
ViT 가 이미지를 처리하는 법을 이해하기 위해 internal representation 을 분석한다.
internal representation이미지 처리 과정에 모델은 입력 이미지의 다양한 특징을 추출하며, 이러한 특징을 모델 내부의 데이터에 맞는 representation 으로 변환한다.
Transformer 에서는 이미지 정보를 2D attention 메커니즘으로 1D embedding 으로 변환한다.
이 embedding 이 Transformer 의 internal representation 이다.
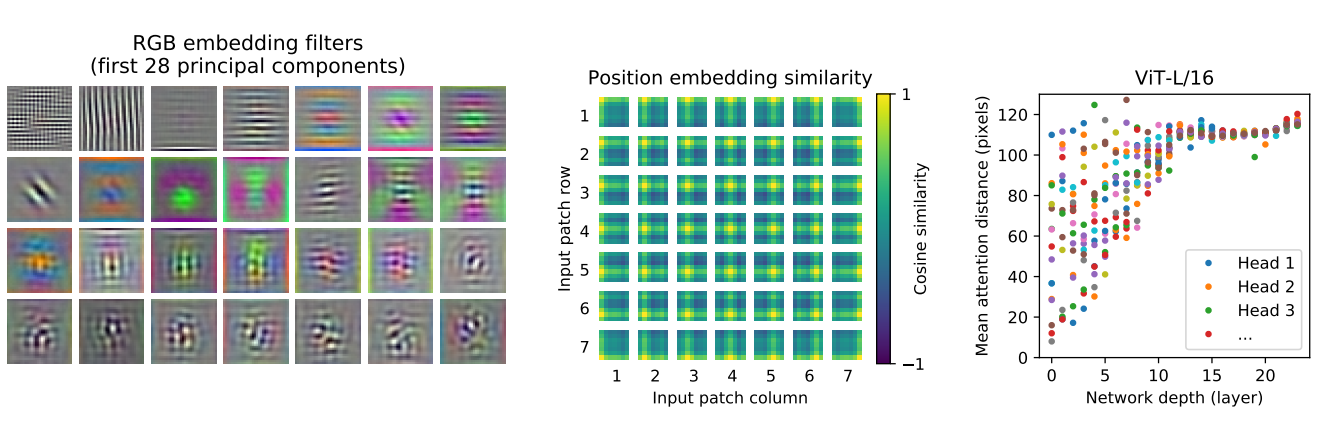
- 왼쪽 : ViT-L/32 로 RGB 의 initial linear embedding 로 Filter
- 각 Filter 는 저차원의 CNN filter 와 유사
- 중앙 : ViT-L/32 의 position embedding 유사도
- Projection 후 position embedding 이 patch representation 에 추가
- 즉, 더 가까운 패치 (같은 행/열 등)는 더 유사한 position embedding 을 가짐 → patch 간의 공간정보가 잘 학습
- 오른쪽 : head 와 network depth 에 따른 attened area 사이즈
self-attention 으로 전체 이미지 정보를 통합 가능한지 조사
- attention weight 를 기반으로 image space 간 평균 거리 계산
- 이 attention distance 는 CNN 의 receptive field 와 유사
- 낮은 layer 의 self-attention head (낮은 attention distance 지님) 는 CNN 의 초기 convolutional layer 와 유사한 기능을 가짐 → localization 효과

나아가 이미지 분류에 의미있는 영역에 attention 하는 것 발견
receptive fieldreceptive field 는 입력된 이미지의 어떤 부분에서 반응을 보이는지를 나타내는 개념
4.6 self-supervision
NLP task 에서 self-supervision 을 시도
- 예로, BERT 에서의 masking
- ViT 에선 masked patch 를 예측함으로 self-supervision
ViT 에서 self-supervision 한 결과
- ViT-B/16 모델은 ImageNet 에서 79.9% 정확도 달성
- Supervised Learning 보다는 4% 떨어짐
5. Conclusion
- patch 추출 단계에서 image-specific inductive bias 를 도입하지 않음
- 대신, 이미지를 sequence 처럼 해석하여 표준 Transformer encoder 로 진행
- 큰 데이터셋으로 pre-train 하면 잘 작동 (위 실험의 JFT-300M)
- 남은 과제
- detection, segmentation 에서는 ViT 를 어떻게 적용할 것인가
- self-supervised 와 큰 규모의 supervised pre-training 간의 갭
- ViT 의 scailing 으로 성능 향상 기대
