AI
1.EfficientNetV2

논문 및 이미지 출처 : 개요 EfficientNetV2는 neural architecture speed (NAS) 와 scailing을 통해 이전 모델들 보다 더 빠르고 적은 파라미터 가지는 Convolution Network 특히 SOTA 모델보다 더 빠르면서
2.An Image Is Worth 16X16 Words: Transformers for image recognition at sacle
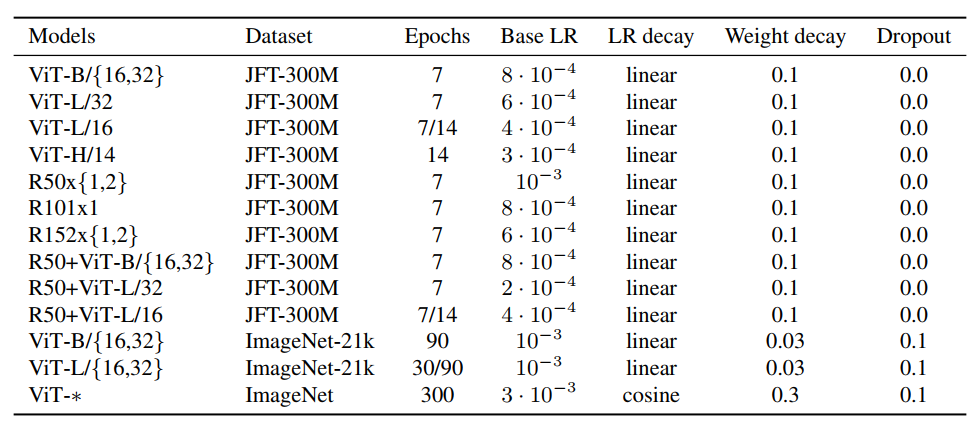
논문 및 이미지 출처 : Abstract NLP task 에서 Transformer Architecture 가 사용되어 오고 있다. 본 논문에서는 vision 의 CNN 구조를 유지하면서 Transformer 를 적용해 훌륭한 결과로 SOTA 를 달성하였다. 이
3.IntructGPT (+ChatGPT)
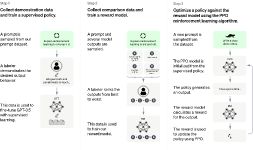
논문 및 이미지 출처 : **논문 제목 : Training language models to follow instructions with human feedback** Abstract 큰 규모의 language 모델은 허위나 toxic 을 유저에게 생성할 수 있다
4.Prismer: A Vision-Language Model with An Esemble of Experts
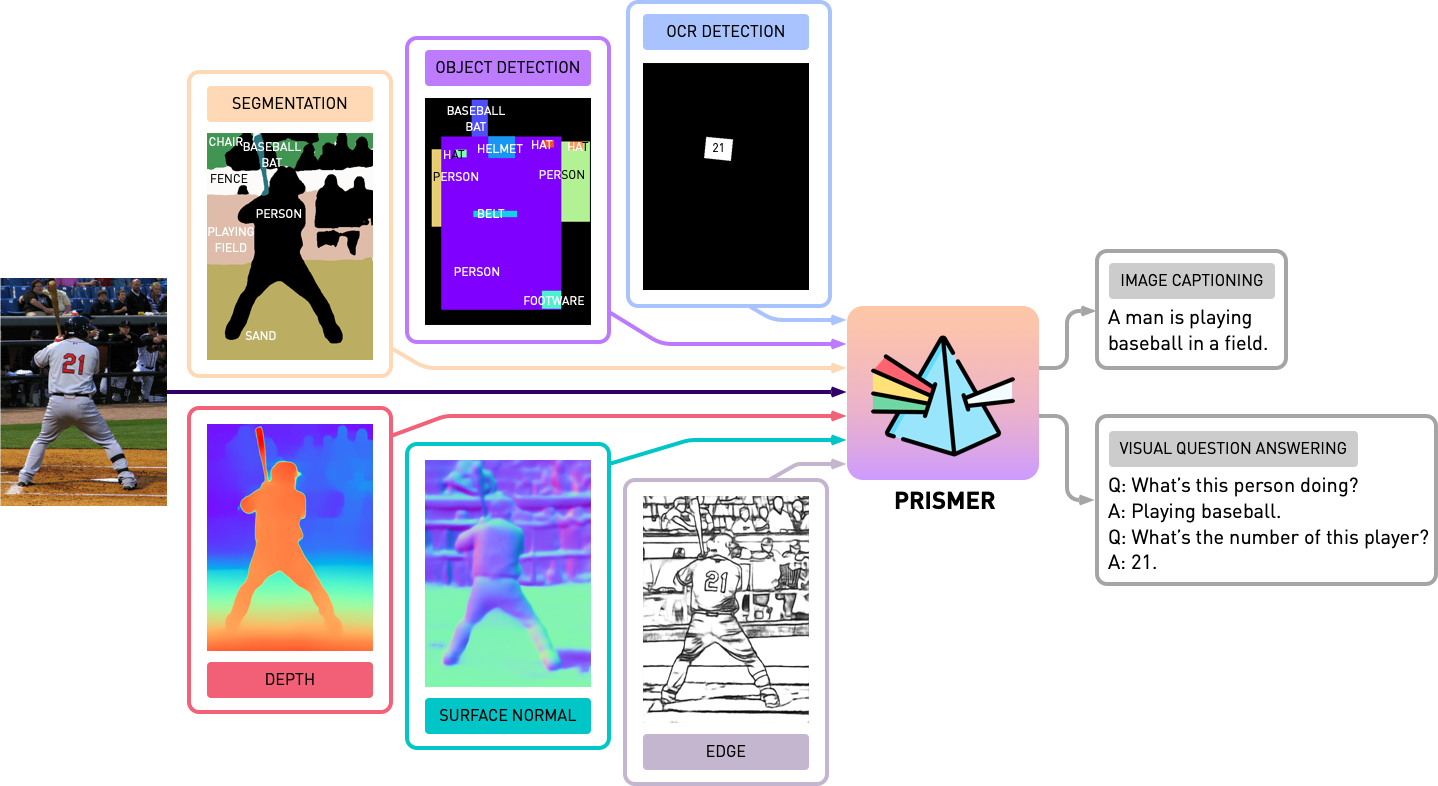
논문 및 이미지 출처 : Shikun Liu, Linxi Fan, Edward Johns, Zhiding Yu, Chaowei Xiao, Anima Anandkumar Imperial College London, NVIDIA, ASU, Caltech Abstrac
5.UNINEXT: Universal Instance Perception as Object Discovery and Retrieval
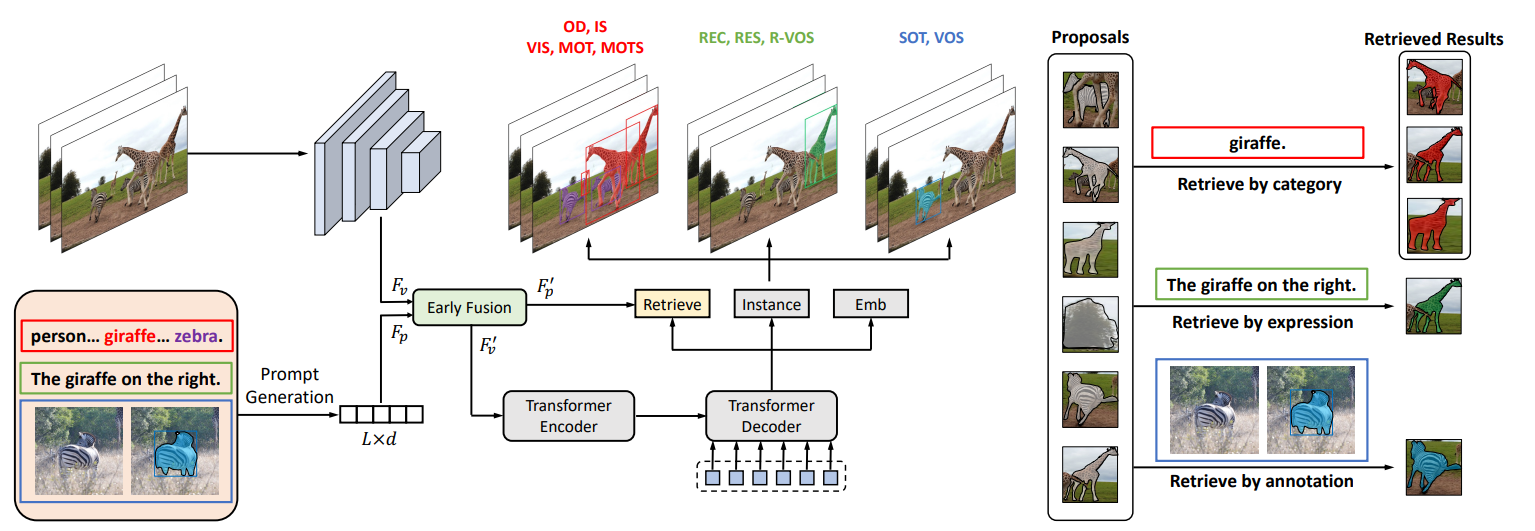
논문 및 이미지 출처 : Bin Yan1*, Yi Jiang2,†, Jiannan Wu3, Dong Wang1,†, Ping Luo3, Zehuan Yuan2, Huchuan Lu1,4 School of Information and Communication Engi
6.Learning to Prompt for Open-Vocabulary Object Detection with Vision-Language Model
논문 및 이미지 출처 : Yu Du1 Fangyun Wei2† Zihe Zhang1 Miaojing Shi3† Yue Gao2 Guoqi Li1 1Tsinghua University 2Microsoft Research Asia 3King’s College London
7.A Unified Sequence Interface for Vision Tasks
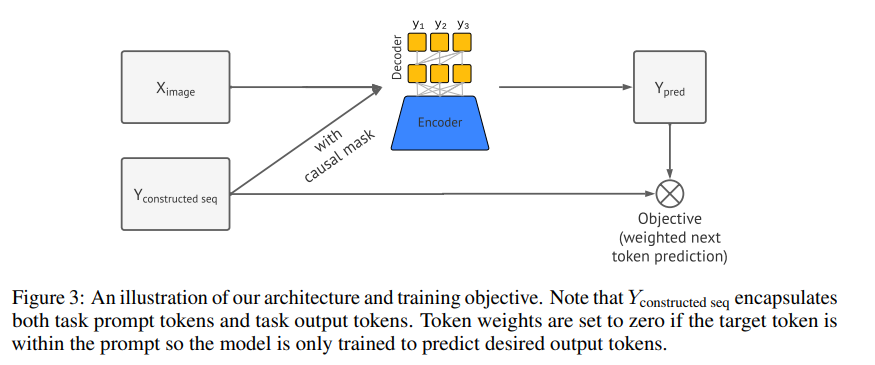
논문 및 이미지 출처 : Ting Chen† Saurabh Saxena† Lala Li† Tsung-Yi Lin∗ David J. Fleet Geoffrey Hinton Google Research, Brain Team Abstract NLP 분야는 단일 통합 모
8.Learning to Prompt for Vision-Language Models
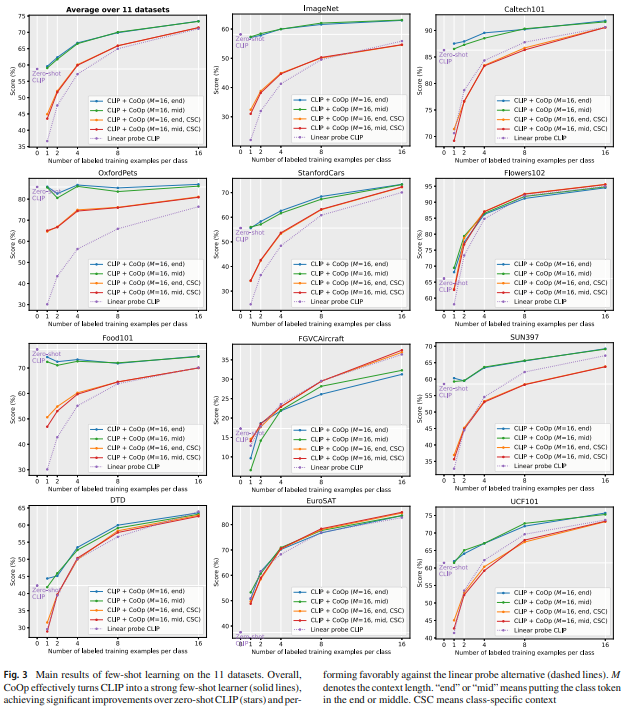
논문 및 이미지 출처 : Kaiyang Zhou1 · Jingkang Yang1 · Chen Change Loy1 · Ziwei Liu1 © The Author(s), under exclusive licence to Springer Science+Business M
9.From Images to Textual Prompts: Zero-shot Visual Question Answering with Frozen Large Language Models
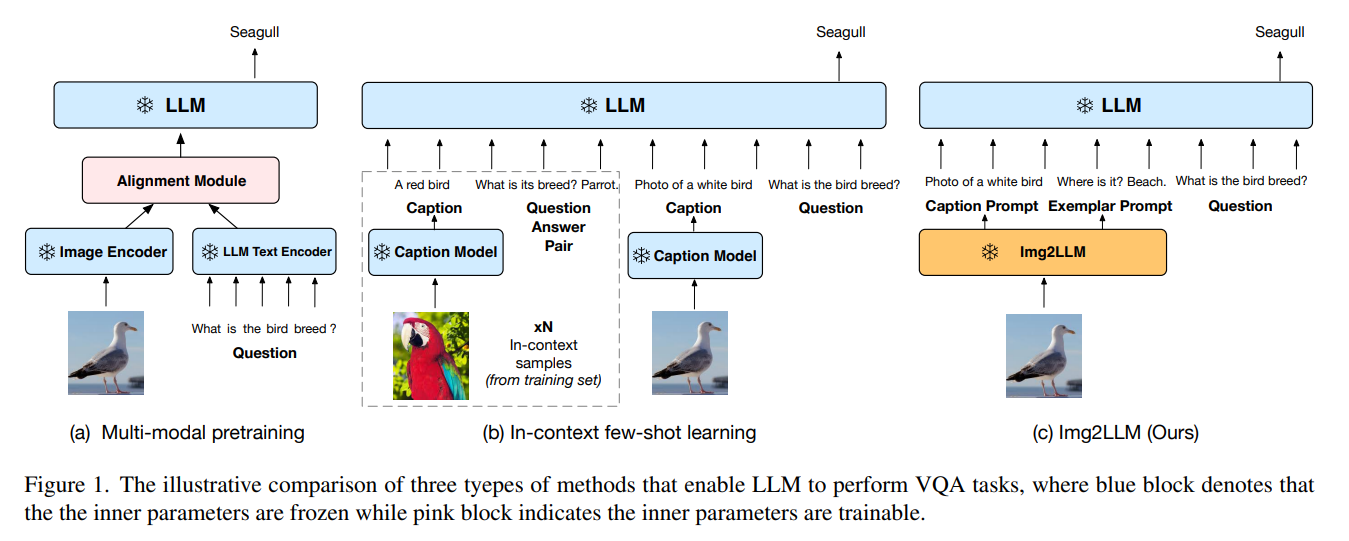
논문 및 이미지 출처 : Abstract Large Language Modes (LLMs) 는 새로운 task 에 대한 zero-shot 일반화가 우수하지만 visual question-answering (VQA) zero-shot 에 활용하는데는 어려운 과제가 있
10.Unsupervised Prompt Learning for Vision-Language Models
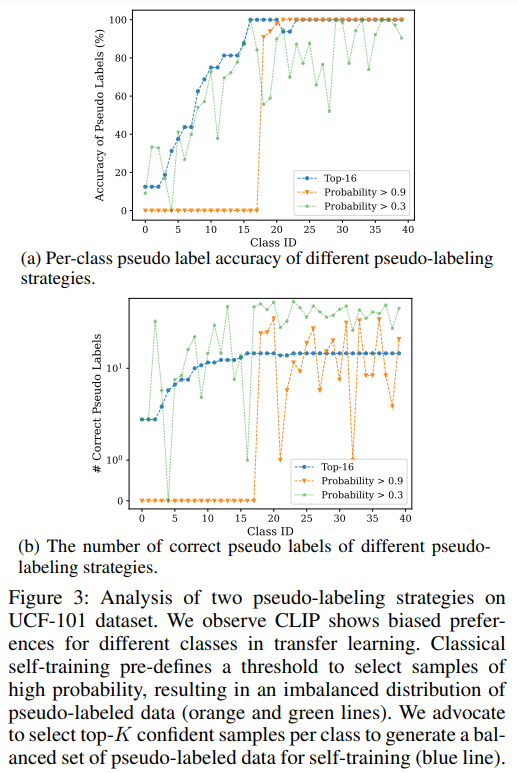
논문 및 이미지 출처 : Abstract CLIP 같은 모델이 visual 과 langauge 간의 Contrastive learning 을 통해 훌륭한 tranasfer learning 을 보이고, 추론 과정에 proper prompt (text descripti
11.Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
논문 및 이미지 출처 : Abstract NLP 의 새로운 패러다임으로 prompt-based learning 이 등장 기존 방식 supervised learning input $x$ 를 사용하여 output $y$ 을 예측하도록 $P(y|x)$ 를 훈련 pr
12.Image to Latex

논문 및 이미지 출처 : http://cs231n.stanford.edu/reports/2017/pdfs/815.pdf수학 공식을 LATEX 로 변환하는 문제는 computer vision (CV) 와 natural language processing (NLP
13.Handwritten Mathematical Expression Recognition via Attention Aggregation based Bi-directional Mutual Learning
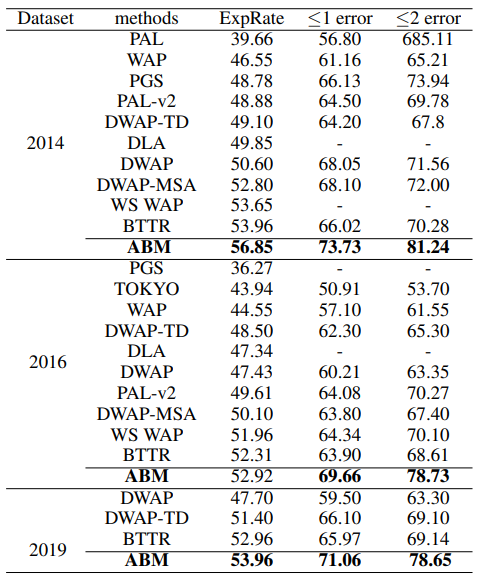
논문 및 이미지 출처 : Abstract Handwritten Mathematical expression Recognition (HMER) 는 이미지로 LaTeX 생성이 목적이며, 최근 attention 기반의 encoder-decoder 모델이 널리 사용. 일반적
14.Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer
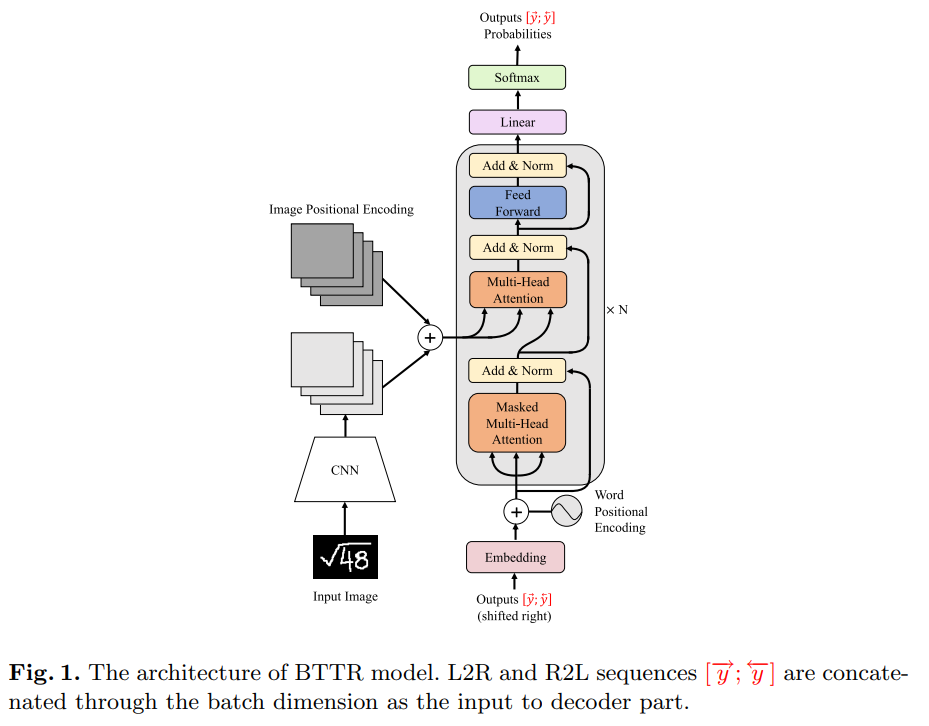
논문 및 이미지 출처 : Abstract Encoder-decoder 로 Handwritten Mathematical expression Recognition (HMER) 에서 좋은 진척을 뵈지만, 여전히 image feature 에 attention 을 align
15.Reflexion: Language Agents with Verbal Reinforcement Learning
최근 LLMs 는 goal-driven agents 로 사용되는 것이 증가하고 있다. 하지만, 기존의 reinforcement learning 은 훈련 샘플이 많이 필요하고 모델의 fine-tuning 으로 비용이 많이 들어, 이러한 language agent 근 시행