논문 및 이미지 출처 : https://link.springer.com/article/10.1007/s11263-022-01653-1
Kaiyang Zhou1 · Jingkang Yang1 · Chen Change Loy1 · Ziwei Liu1
© The Author(s), under exclusive licence to Springer Science+Business Media, LLC, part of Springer Nature 2022
Abstract
CLIP 처럼 큰 vision-language model (VLM) 은 downstream task 를 넓은 범위로 할 수 있는 representation learning 에서 큰 잠재력이 있다.
discretized label 을 기반으로 한 representation learning 과 다르게, prompt 로 downstream task 를 가능하게 zero-shot 을 하는, image 와 text 간의 align 을 학습한다.
본 논문에서, domain expertise 나 약간만 변해도 성능에 큰 영향을 주어 word tuning 에 많은 시간을 투자해야 하는, prompt engineering 에 대한 모델 사용을 연구한다.
natural language processing (NLP) 분야에서 진보하는 prompt learning 에 영감을 받아 다음을 제안한다.
- 저자는 downstream image recognition 에 대해, CLIP 같은 VLM 을 채택한 간단한 접근법인 Context Optimization (CoOp) 를 제시한다
- CoOp 은 전체 pretrained parameter 를 유지하면서, learnable vector 가 있는 prompt 의 context words 를 모델링한다.
서로 다른 이미지 인식 작업을 처리하기 위해, 저자는 CoOp 의 unified context 와 class-specific context 두 가지 구현을 제시한다.
11 가지 dataset 에서 실험을 진행하여, CoOp 가 hadnd-crafted prompt 를 이기기 위해 최소 1~2 shot 이 필요하여, 16 shots 으로 평균 약 15% (가장 높은 건 45%)의 이득을 얻어, prompt engineering 을 크게 향상시켰음을 입증한다.
1. Introduction
visual recognition 에서 SOTA 모델을 구축하는 일반적인 접근법은 discrete label 로 object categories 의 고정된 셋을 예측하도록 모델링하는 것이다.
이 기술에 대한 포인트로는 ResNet 이나 ViT 같은 비전 모델로 image feature 를 매칭하는 것이다.
이런 categoriy 학습에는 goldfish 나 toilet paper 처럼 textual 형태를 가지긴 하지만, cross-entropy loss 계산에 용이하도록 discrete label 로 변환한다.
결국 이런 visual recognition 시스템은 새로운 데이터에 대한 새로운 classifier 가 필요하기 때문에, 새로운 category 를 처리하기 힘들다.
최근, CLIP 및 ALIGN 같은 모델이 visual representation learning 으로 새로 나타났으며, 주 아이디어는 image 와 text 를 각 encoder 를 통해 align 하는 것이다.
위 두 모델은 image 와 text 에 대해, unmatched pair 는 멀리하고 matched pair 은 가까이 하도록 하는 contrastive loss 를 통해 학습 목표를 정의한다.
이러한 모델을 large scale 에서 pretraining 하면, 다양한 visual concepts 를 학습하고 prompt 를 통해 어떠한 downstream 작업도 용이하게 한다.
특히, category 를 설명하는 문장을 text encoder 에 전달하고, image encoder 를 통해 제공받은 image feature 간의 비교를 통해 new classification task 는 기존의 classification weight 와 합성할 수 있다.
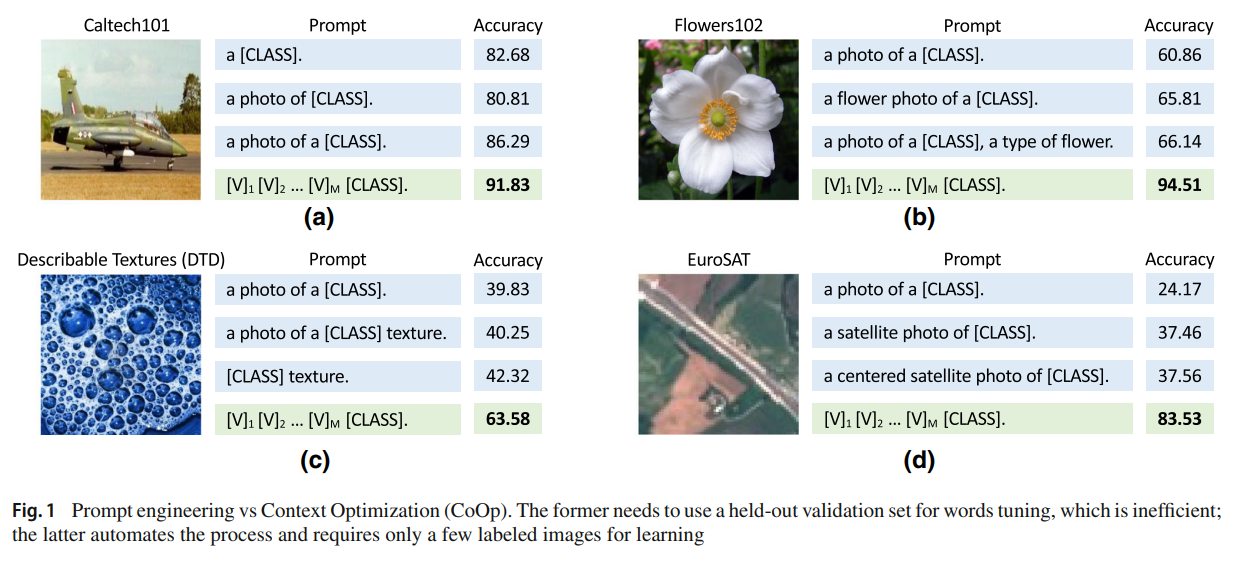
저자는 VLM 에서 downstream dataset 의 주요 역할을 하는, prompt 로 알려진 text input 에 대해 관찰을 했다.
올바른 prompt 식별은 단순한 작업이 아니며, word tuning 에 상당한 시간이 필요하며, 약간의 변화에도 큰 성능 차이를 만든다.
Fig.1 의 (a) 부분으 1~3 prompt 는 "a" 를 추가하는 것 만으로 5% 이상의 정확도 증가가 있었다.
(b)~(d) 에서는 "flower" 나 "staellite" 처럼 task 와 관련한 context 를 추가하면 성능 향상이 있었다.
문장 구조를 더 튜닝하여 "a type of flower" 처럼 하는 것 또한 약간의 성능 향상이 있었다.
위 처럼 튜닝을 확장한 prompt 는 downstream task 를 위한 최적인 것은 아니다.
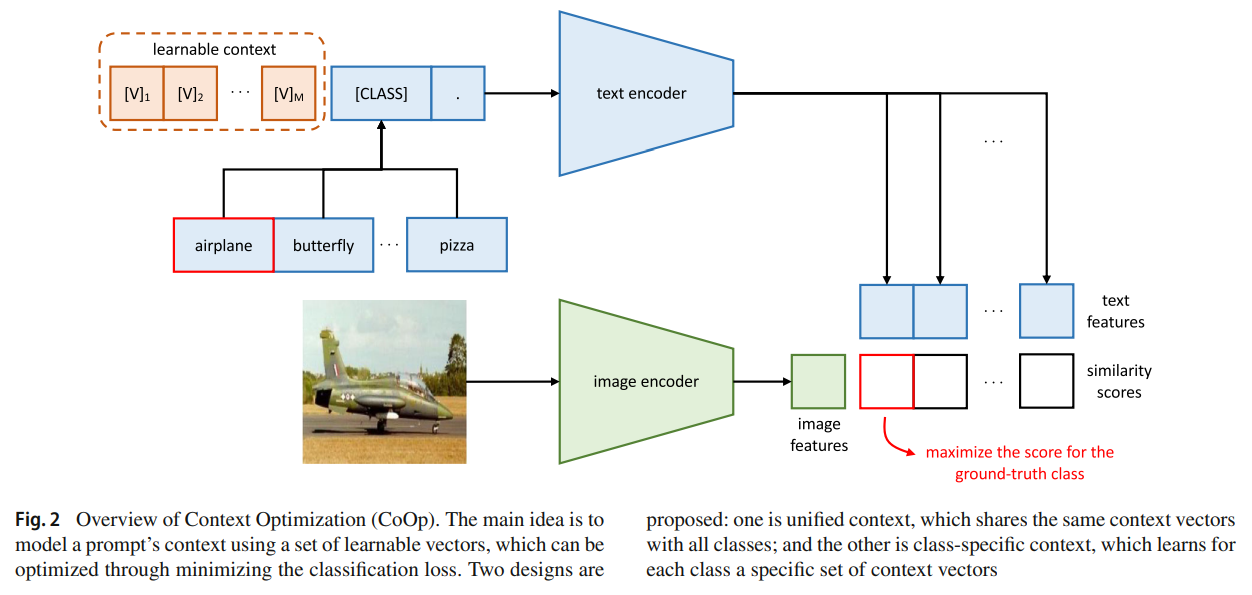
최근 NLP 분야의 prompt learning 에 영감을 받아, prompt engineering 을 자동으로 하는 Context Optimization (CoOp) 라는 간단한 접근법을 제안한다.
구체적으론, random value 나 pretrained word embedding 이 될 수 있는 learnable vector 가 있는 prompt 의 context words 를 모델링하는 것으로, 두 가지 구현으로 서로 다른 특성의 task 를 처리한다.
- unified context
- share the same context with all classes
- works well on most categories
- class-specific context
- learns a specific set of context tokens for each class
- found to be more suitable for some fine-grained categories
훈련 중, learnable context 에 관하여 cross-entropy loss 를 사용해 prediction error 를 최소화하는 동시에, 고정된 전체 pre-trained parameter 를 유지한다.
gradient 는 text encoder 를 통해 역전파될 수 있으며, task-relevant context 를 학습하기 위해 parameter 에 인코딩된 rich knowledge 를 distilling 한다.
CoOp 의 효율성을 입증하기 위해 11 dataset 에서 실험을 진행한다.
16 shot 처럼 많은 shot 에서 성능이 더욱 boosting 될 수 있으며, hand-crafted prompt 보다 평균적으로 15% 성능이 좋으며, 최고는 45% 도달했다.
또한 강력한 few-shot learning baseline 인 linear probe model 모다 좋은 성능을 냈다.
이에, CoOp 은 learning-based approach 임에도 불구하고 zero-shot 모델보다 더 강한 robustness 를 보여준다.
- downstream application 에서 최근 제안되는 VLM 의 adaptation 에 관한 연구를 present
- pretrained VLM 에 관한 automate prompt engineering 을 위해, continuous prompt learning 을 기반한 간단한 접근법을 제안하며, 서로 다른 recognition task 를 다룰 수 있는 두 가지 구현을 제공
- 저자가 제안하는 prompt learning-based approach 는 hand-crafted prompt 와 downstream 에 좋은 성능을 내는 linear probe model 보다 성능이 좋은 것과 VLM 에 대한 domain shift 의 robustness 를 보여준다.
- 소스는 https://github.com/KaiyangZhou/CoOp 에서 확인
2. Related Work
3. Methodology
3.1 Vision-Language Pre-Training
CLIP 에 특히 초점을 맞춘 VLM 학습을 간략하게 소개한다.
저자의 접근방식은 CLIP와 같은 광범위한 VLM 에 적용할 수 있습니다.
Models
CLIP 은 image 와 text 각각의 encoder 가 있다.
image encoder 는 고차원 image 를 저차원 임베딩 공간으로 매핑하는 것이 목표다.
image encoder 의 아키텍처는 ResNet-50 이나 ViT 같은 CNN 같은 형태를 사용할 수 있다.
text encoder 는 Transformer 의 top 부분으로 구축하고, natural languange 에서 text representation 을 생성하는 것이 목표다.
구체적으로, CLIP 은 "a photo of a dog" 같은 단어 sequence (token) 이 주어지면, token (구분 포함) 각각을 고유한 숫자 ID 인 소문자 바이트쌍 인코딩 (lower-cased byte pair encoding, BPE) representation 으로 변환한다.
CLIP 의 vocabulary 크기는 49,152 이다.
minibatch 처리에 용이하도록, 각 text sequence 는 [SOS] 및 [EOS] token 을 포함하고, 고정된 길이 77 로 crop 한다.
그 후, ID 들은 512-D word embedding vector 로 매핑되고, Transformer 를 통과한다.
마지막으로, [EOS] token 부분의 feature 은 layer normalized 후, linear projection layer 로 처리한다.
Training
CLIP 에선 image, text 각각에 대해 학습된 두 임베딩 공간에 align 하도록 훈련됐다.
구체적인 학습 목표는 contrastive loss 로 나타낸다.
image-text 쌍이 주어지면, CLIP 은 매칭되는 쌍은 코사인 유사도를 최대화하면서, 매칭되지 않는 쌍은 코사인 유사도를 최소화한다.
downstream task 에 이식 가능하도록하는 다양한 visual concept 을 학습하기 위해, 400 million 의 image-text 쌍에서 훈련했다.
Zero-Shot Inference
CLIP 은 image 와 text 가 매칭하는 지 예측하도록 pretrain 되었기 때문에, zero-shot recognition 에 자연스럽게 맞춘다.
관심 클래스를 지정하는 텍스트 설명을 입력으로 사용하는 text encoder 를 통해 합성된 classification weight 와 image feature 를 비교하여 달성한다.
- image 를 image encoder 로 추출하여 image feature 를 얻는다.
- 는 클래스 수이고 각 는 "a photo of a [CLASS]" 형태를 가지는 prompt 에서 추출
- 여기서 class token 은 "cat", "dog" 같은 class name 을 지정하여 교체
- 는 CLIP 에서 학습된 파라미터이며, 형태는 코사인 유사도이다.
close-set 의 기존 접근법과 비교했을 때, vision-language pretraining 은 text encoder 로 open-set 을 좀 더 의미있는 space 로 이어지고, downstream task 를 좀더 쉽게 이식할 수 있다.
3.2 Context Optimization
저자는 CoOp 을 제안하며, pretrained 거대한 parameter 를 동결시키면서 데이터의 end-to-end 로 학습된 continuous vector 로 context word 를 모델링함으로써, 수동 prompt 튜닝을 피한다.
Unified Context
먼저 unified context 를 도입하며, 모든 class 에 대해 동일한 context 를 공유한다.
구체적으로, text encoder 에 제공되는 prompt 형태는 다음과 같다.
여기서 () 은 word embedding (예; CLIP 의 512) 와 같은 동일인 차원의 벡터이다.
그리고 은 context token 의 수를 지정하는 hyperparameter 다.
prompt 를 text encoder 을 지나, visual concept ([EOS] token 부분) 을 나타내는 classification weight vector 를 얻을 수 있으며 다음을 계산하여 예측할 수 있다.
여기서 각 prompt 안의 class token 은 -th class name 에 해당하는 word embedding vector 로 교체된다.
(2) 식처럼 class token 을 시퀀스 끝에 배치한 것 외에, 저자는 다음과 같이 중간에도 배치할 수 있다고 한다.
위는 학습 유연성을 증가시킨다.
prompt 는 latter cells 을 보충 설명으로 채우거나 full stop 과 같은 종료 신호를 사용하여 문장을 더 읽찍 끊을 수 있다.
Class-Specific Context
다른 옵션은 class-specific context (CSC) 을 설계하는 것이며, 여기서 context vector 는 각 클래스에 독립적이다. (예; for )
unified context 의 대안으로, CSC 는 일부 세분화된 classification task 에 특히 유용하다는 것을 저자는 발견했다.
Training
훈련은 cross-entropy 에 기반한 표준 classification loss 를 최소화하는 것으로 수행하며, gradient 는 text encoder 을 통해 backpropagation 을 할 수 있으며 parameter 에 인코딩된 rich knowledge 를 사용하여 context 에 최적화한다.
continuous representation 의 설계는 또한 word embedding space 에 대한 완전한 탐색을 가능하게 하여 task-relevant context 의 학습을 용이하게 한다.
3.3 Discussion
저자의 approach 는 CLIP 같은 최근 대규모 VLM 의 적응이란 새로운 문제를 구체적으로 해결한다.
언어 모델을 위해 NLP 의 prompt learning(예; GPT-3)과 구별하는 몇 가지 차이점이 있다.
- 백본 아키텍처는 CLIP 과 유사한 모델과 언어 모델에 대해 분명 다르다.
전자는 visual 과 textual data 를 모두 입력으로 사용하여 image classification 에 사용되는 align 점수를 생성한다.
후자는 textual data 만 처리하도록 조정된다. - pre-training 목표는 contrastive learning 과 autogressive learning 이 다르다. 이로 인해 모델 동작이 달라지므로 모듈 설계가 필요하다.
4. Experiments
4.1 Few-Shot Learning
Dataset
- ImageNet
- Caltech101
- OxfordPets
- StanfordCars
- Flowers102
- Food101
- FGVCAircraft
- SUN397
- DTD
- EuroSAT
- UCF101
저자는 위 11가지 데이터셋에서 실험을 진행한다.
object, scene, action 등 다양한 vision task 들이 있으며, CLIP 에서 채택된 few-shot evaluation protocol 을 따라 1, 2, 4, 8, 16 shots learning 으로 전체 데이터셋에서 모델을 배치한다.
Training Details
CoOp 엔 4 가지 버전이 있다.
- class token 을 end vs middle 에 위치
- unified context vs CSC
특별한게 없다면, ResNet-50 을 image encoder 의 백본으로 사용되며, context token 의 수 은 16 으로 설정한다.
모든 모델은 CLIP 의 open-source 에서 구축된다.
CoOp 의 context vector 는 표준 편차가 0.02 인 zero-mean Gaussian distribution 을 사용하여 무작위로 초기화된다.
훈련은 SGD 및 0.002 의 lr 로 수행하며, 이는 cosine annealing 으로 최적화된다.
최대 epoch 은 16/8 shot 은 200, 4/2 shots 은 100, 1 shot 은 50 으로 설정한다 (최대 epoch 이 50 으로 고정된 ImageNet 은 제외).
early training 반복에서 관찰된 explosive gradients 를 완화하기 위해, 첫 epoch 동안에만 로 고정하여, warmup trick 을 사용한다.
Baseline Methods
두 baseline 과 CoOp 을 비교해보자.
먼저 hand-crafted prompt 에 기반한 zero-shot CLIP 이다.
CLIP 에서 도입된 prompt engineering 의 guideline 을 따른다.
- objects 와 scenes 의 경우 "a photo of a [CLASS]"
- fine-grained categories 의 경우
- OxfordPet 에선 "a type of pet"
- Food101 에선 "a type of food"
- specialized task 의 경우
- DTD 에선 "[CLASS] texture"
linear probe model 훈련을 위해 CLIP 에서 사용된 것과 동일한 훈련법을 따른다.
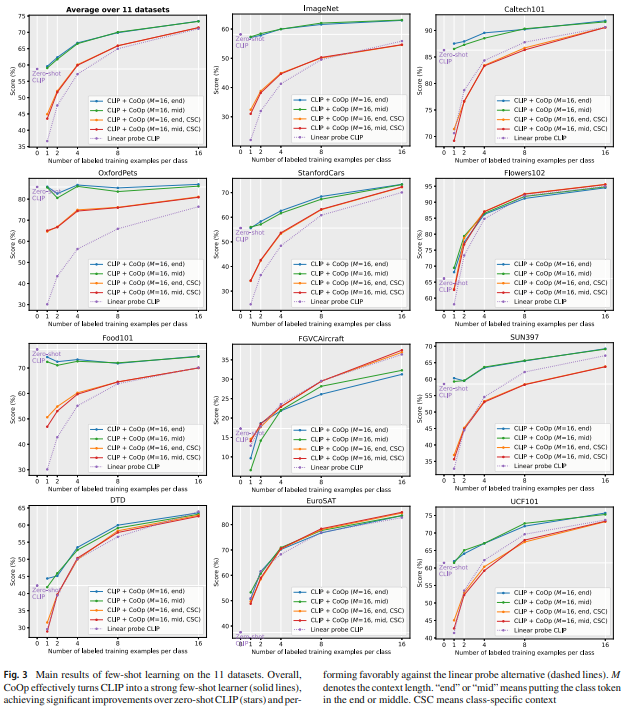
Fig. 3 에서 Hand-Crafted Prompt 와 비교한다.
default model 은 CLIP + CoOp 이며 class token 을 끝에 위치한다.
class token 의 두 가지 배치 방법은 곡선이 겹칠 때 유사한 성능을 달성한다.
CLIP + CoOp 은 강력한 few-shot learner 이며, zero-shot CLIP 보다 적절한 margin 을 얻기 위해 2 개의 shot 만을 필요로한 것을 관찰했다.
16 shots 일 때는 CoOp 이 평균 15% 까지의 격차가 증가했다.
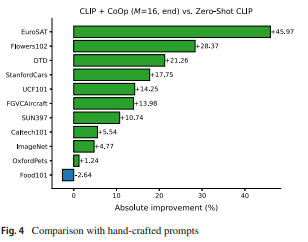
위 랭크는 hand-crafted prompt 보다 16 shots 에서 얻은 absolute improvement 를 보여준다.
성능증가가 45% 나 20% 이상에 이르는 specialized task (EuroSAT, DTD)에서 큰 성능 향상을 보인다.
Fowers102, StanfordCars, FGVCAircraft 를 포함한 세분화된 데이터셋이나 object, scene, action 인식 데이터셋 (SUN397, UCF101) 에서도 큰 성능 향상을 얻었다.
ImageNet 은 1000 개의 클래스를 포함한 까다로운 데이터셋이므로 4.77% 성능 향상도 주목할만 하다.
대조적으론 OxfordPets 나 Food101 의 증가에 대해선 아쉽다.
Fig. 3 에서 더 많은 shots 을 사용하더라도 성능 개성의 추진력이 손실된 다는 것을 발견했는데, 겉보기엔 과적합 문제인 것으로 보인다.
잠재적인 해결책은 weight decay 를 증가시키는 것과 같이 더 높은 정규화를 하는 것이다.
그럼에도 전반적인 결과는 CoOp 이 task-relevant prompt 를 데이터 효율적인 방식으로 학습할 수 있다는 증거가 될 정도로 충분히 강력하다.
Comparison with Linear Probe CLIP
전체 성능 (Fig. 3 좌상단)에서, CLIP + CoOp 은 linear probe model 비해 이점이 있음을 보여준다.
후자는 zero-shot 의 성능과 일치하기 위해 평균적으로 4 shots 이상이 요구되지만 CoOp 은 1, 2 shots 같은 낮은 데이터에서 크게 효과적이다.
또한 linear probe model 이 specialized task (EuroSAT, DTD) 및 몇 가지 세분화된 데이터셋 (Flowers102, FGCAircraft) 에서 CLIP+CoOp 과 유사한 것을 관찰했다.
pretrained CLIP space 가 강력하여 linear probe model 도 경쟁력이 있지만, CoOp 의 CSC 버전은 위 데이터셋에서 linear probe CLIP 을 이기며, 더 많은 shots 에서 큰 잠재력을 보여준다.
이로써, 추후 CoOp 이 domain generalization 에서 linear probe model 보다 훨씬 강력하단 것을 보여준다.
4.2 Domain Generalization
