논문 및 이미지 출처 : https://arxiv.org/pdf/2303.11366v3.pdf
깃허브 : https://github.com/noahshinn024/reflexion/tree/main
Abstract
최근 LLMs 는 goal-driven agents 로 사용되는 것이 증가하고 있다.
하지만, 기존의 reinforcement learning 은 훈련 샘플이 많이 필요하고 모델의 fine-tuning 으로 비용이 많이 들어, 이러한 language agent 근 시행착오로부터 빠르고 효율적으로 학습하는 것은 어려운 과제다.
저자는 Reflexion 을 제안한다.
weight 업데이트하는 대신 언어적 피드백으로 language agent 를 강화하는 것이다.
Reflexion 은 feedback signal 을 반영한 후, 이러한 reflective text 를 episodic memory 에 유지하여 subsequent trial 에서 더 나은 의사결정을 유도한다.
Reflexion 은 다양한 타입 (scolor value / free-form language) 및 소스 (외부/내부적 시뮬레이션) 의 feedback signal 을 유연하게 통합하며, 다양한 task (sequential decision-making, coding, language reasoning) 에서 baseline agent 에 비해 상당한 개선을 보인다.
HumanEval coding bachmark 에서 91% pass@1 정확도를 달성하여, 이전 SOTA 인 GPT-4 의 80% 를 뛰어 넘었다.
또한, feedback signal, feedback incorporation 및 agent type 에 대한 분석 및 ablation 실험으로 성능을 비교한다.
1 Introduction
최근 연구에선 LLM core 로 구축한 자동 의사결정 agent 의 가능성을 입증한다.
이 방법은 LLMs 를 사용하여 API 호출 및 환경에서 실행할 수 있는 text 및 'action' 을 생성할 수 있다.
하지만 방대한 파라미터 수를 가진 거대한 모델에 의존하여, 기존의 강화학습과 경사하강을 이용한 최적화 방법같은 전통적인 방식은 계산량과 시간이 많이 소비되어 문맥 내의 예제로 agent 에게 가르치는 방식으로 제한되어 있다.
본 논문은 agent 가 이전의 실패로부터 배우는 것을 돕기위해 언어적 강화를 사용하는 Reflexion 이란 대안적 접근법을 제안한다.
이는 환경으로부터 binary 또는 scalar feedback 을 텍스트 요약 형태의 verbal feedback 으로 변환하며, 이는 다음 에피소드에서 LLM agent 에 대한 additional context 로 추가된다.
이 self-reflective feedback 은 'semantic' gradient signal 역할을 하며, 구체적인 개선 방향을 제시하여 과제를 더 잘 수행하도록 도와준다. 이는 인간이 몇 번의 시도로 실패를 반영하여 개선하며 복잡한 작업을 달성하는 것과 유사하다.

예로, Figure 1 에서 Reflexion agent 는 trial, error, self-reflection 을 통해 decision-making, programming 및 reasoning task 를 해결하기 위해 자신의 동작을 최적화하는 방법을 배우게 된다.
유용한 reflective feedback 생성은 어디서 실수했는지를 잘 이해하는 능력과 개선을 위한 통찰을 담은 요약을 생성하는 능력이 필요하여, 매우 어려운 과제이다.
저자는 이러한 수행을 위해 3 가지 방법을 탐구한다.
- simple binary enviroment feedback
- pre-defined heuristics for common failure cases
- LLMs 을 이용한 binary classification 또는 self-written unitests (programming) 과 같은 self-evaluation
모든 구현에서, evaluation signal 은 long-term memory 에 저장될 수 있는 자연어 요약으로 증폭된다.
Reflexion 은 policy 또는 value-based learning 같은 기존의 강화학습과 비교하여 몇몇 이점이 있다.
- 가벼우며 LLM finetuning 불필요
- scalar 또는 vector reward 와 비교했을 때, 보다 더 정교한 형태의 feedback (예; action 에 대한 targeted changes)이 가능하며, 정확한 credit assignment 가 어려운 경우에도 수행
- 이전 경험보다 더 명시적이며 episodic memory 의 해석 가능한 형태
- 미래 에피소트의 action 에 대한 더 명시적인 힌트를 제공
동시에 LLM 의 self-evaluation capabilities (or heuristics) 의 힘에 의존하는 단점이 있으며, 성공에 대한 정규적 보증이 없다.
다음과 같은 실험 진행
- decision-making task : 긴 경로를 통해 sequential action choice test
- reasoning task : knowledge-intensive, single-step generation improvement test
- programming task : compiler 및 interpreter 같은 외부 도구로 효과적으로 가르침
세 가지의 task 결과, decision-making task 인 AlfWorld 에선 22%, reasoning task 인 HotPotQA 에선 20%, programming task 인 HumanEval 에선 최대 11% 까지 개선되었다.
주요 contribution 은 다음과 같다.
- 'verbal' 강화를 위한 새로운 Reflexion 패러다임을 제안. 이는 policy 를 agent 의 memory encoding 과 LLM parameter 의 선택과 결합하는 방식으로 parameterize
- LLM 에서 나타나는 self-reflection 의 특성을 탐구하고, self-reflection 이 소수의 시도로도 복잡한 작업을 학습하는 데 매우 유용하다는 것을 경험적으로 보여줌
- LeetcodeHardGym 을 도입하며, 19개의 프로그래밍 언어로 구성된 40개의 어려운 Leetcode 문제로 구성된 코드 생성 RL gym 환경이다.
- Reflexion 이 강력한 baseline 모델에 비해 여러 작업에서 개선을 이루며, 다양한 code generation benchmarks 에서 SOTA 달성
2 Related work
3 Reflexion: reinforcement via verbal reflection
활용할 세 가지 모델을 다음과 같이 공식화
- Actor model : text 및 action 을 생성할
- Evaluator model : 로 생성된 output 의 score 를 나타내는
- Self-Reflection model : self-improvement 로 Actor 를 도와주기 위해 verbal reinforcement cues 를 생성할
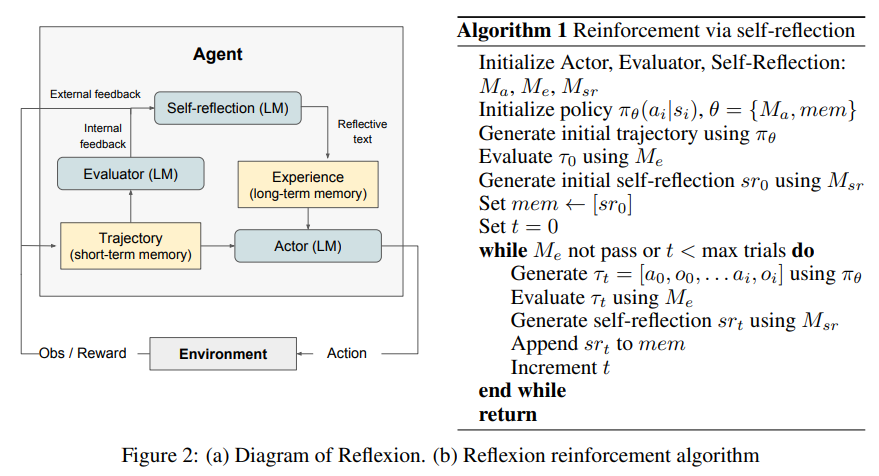
Actor
Actor 는 state 관찰에 필요한 text 및 action 생성을 위해 특별히 prompted LLM 에 기반하여 만든다.
기존의 policy-based RL 설정과 유사하게, time 에서의 current policy 로부터의 action 또는 generation 을 샘플링 하고, environment 로부터 관찰을 얻는다.
Chain of Thought 및 ReAct 를 포함한 다양한 Act 모델을 탐구한다. 이러한 다양한 generation model 은 Relfexion framework 내의 text 및 action generation 의 다른 측면을 탐색하여 성능과 효과에 대한 유용한 통찰력을 제공
또한, agent 에게 추가적인 context 를 제공하는 memory component 을 추가한다.
Evaluator
Reflexion framework 의 Evaluator component 는 Actor 로 생성한 output 의 퀄리티를 평가하는 데 중요한 역할을 함
생성된 trajectory 를 입력으로 받아, 주어진 task context 내의 성능을 반역하는 reward score 를 계산
semantic space 에 적용되는 효율적인 value 나 reward function 정의는 어려움으로, 다양한 Evaluator model 을 탐구한다.
- reasoning task : 생성된 output 이 expected solution 과 밀접하게 align 하기를 보장하는 exact match (EM) grading 에 기반한 reward function 탐구
- decision-making task : evaluation criteria 를 명시하기 위해 맞춤형의 pre-defined heuristic function 사용
- decision-making 및 programming task 에 대한 reward 생성하는 Evaluator 로서 LLM 의 다른 인스턴스를 사용하여 실험
위의 multi-faceted 접근법으로 생성된 output 에 대한 다양한 scoring 전략을 조사하여, 다양한 task 에 대한 효과성과 적합성에 대한 통찰력을 제공한다.
Self-reflection
LLM 인 Self-Reflection model 은 future trials 에 대한 valuable feedback 을 제공하기 위해 verbal self-reflections 를 생성하는, Relfexion framework 에서 중요한 역할을 한다.
binary success status (success/fail) 같은 reward signal, current trajectory 및 persistent memory 이 주어지면, self-reflection model 은 세부적이며 구체적인 feedback 을 생성한다.
이 feedback 은 scalar rewards 보다 많은 정보를 주며, 이는 agent 의 에 저장된다.
예로 multi-step decision-making 에서,
- agent 가 failure signal 을 받았을 때
- 특정 동작 가 이후의 잘못된 action 와 으로 이어질 수 있음을 추론
- 그럼 agent 는 다른 action 을 취했어야 하며, 이는 와 를 발생할 것임을 말함
- 위의 경험을 memory 에 저장
- 이후의 trial 에서 agent 는 과거 경험을 통해 time 에서의 decision-making approach 개선을 위해 action 을 선택
이런 trial, error, self-reflection 및 persisting memory 과정을 통해 agent 는 정보성 있는 feedback signal 을 활용하여 다양한 환경에서 decision-making 능력을 빠르게 향상
Memory
Reflexion 과정의 핵심 컴포넌트는 short-term 과 long-term memory 개념.
inference time 에, Actor 는 short 와 long-term moemory 에 의존하여 결정 내린다.
이는 인간이 최근 세부사항은 기억하며 장기 기억에서 중요한 경험을 회상하는 것과 유사하다.
RL 설졍에선, trajectory history 가 short-term memory 에 작용하며, Self-Reflection model 의 output 은 long-term memory 에 저장된다.
이 두 memory components 특정 context 제공을 위해 함께 작동하지만, 여러 trial 에서 얻는 교훈에 영향을 받는다. 이는 Reflexion agent 가 다른 LLM action choice works 에 비해 주요한 이점을 가지고 있다는 것이다.
The Reflexion process
- first trial 에서, Actor 는 환경과 상호작용하여 trajectory 을 생성
- Evaluator 는 으로 계산되는 score 을 생성
- 는 trial 에 대한 scalar reward 으로, task-specific performance 가 향상됨에 따라 개선됨
- first trial 후, LLM 으로 인한 개선을 사용할 수 있는 feedback 형식으로 을 강화하기 위해 Self-Reflection model 이 집합을 분석하여 summary 을 생성하고 에 저장
- 는 trial 에 대한 verbal experience feedback
- Actor, Evaluator 및 Self-Reflection model 은 루프를 통해 협력하여 작동하며, Evaluator deems 가 올바른 것으로 판단할 때까지 반복
- memory 파트에서 언급했듯, Reflexion 의 memory component 는 효과성에 중요하다. 각 trial 이후 는 에 추가된다.
- 실제론 최대 경험 저장 수 (보통 1-3)를 제한하여 max context LLM 제한을 준수
4 Experiments
4.1 Sequential decision making: ALFWorld

4.2 Reasoning: HotpotQA
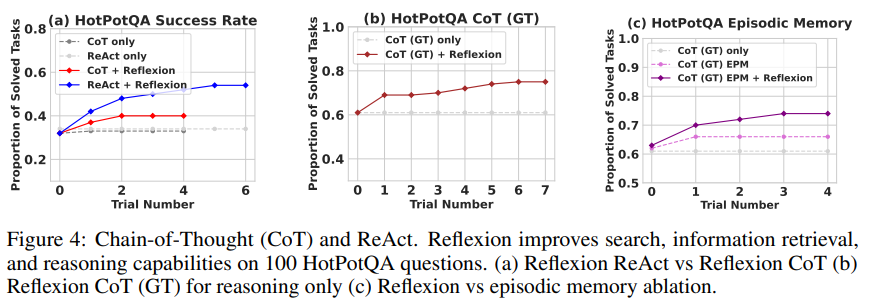
4.3 Programming
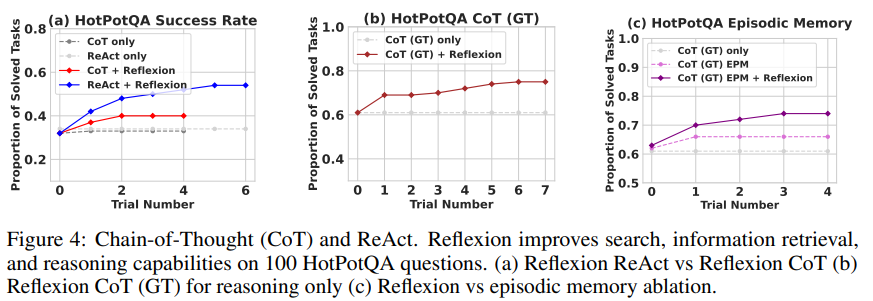
Ablation study

5 Limitations
Reflxion 은 NL 로 policy optimization 하는 최적화 기법이다. policy optimization 은 경험을 통한 action choice 개선에 강력하지만, non-optimal local minima 에 빠질 수 있다.
본 연구는 long-term memory 를 maximum capacity 로된 sliding window 로 제한했지만, 향후 연구에선 vector embedding databases 또는 전통적인 SQL database 같은 고급 구조로 Reflexion 의 memory component 를 확장하는 것을 권장한다.
code generation 에 특정하면, non-deterministic generator function, API 와 상호작용하는 impure function, 하드웨어 사양에 따라 output 이 다른 function, 병렬 또는 동시 동작을 호출하는 함수 등과 같은 정확한 input-output 매핑을 지정하는 데 많은 실질적 제한 사항이 있을 수 있다.
